1. openai 연결 코드
from openai import OpenAI
import sys
import psycopg2
from dotenv import load_dotenv
load_dotenv()
STUDENT_NO = '47'
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
client = OpenAI(api_key=OPENAI_API_KEY)
# PostgresSQL 접속정보
DB_CONFIG = {
'host': os.getenv("HOST"),
'port': 5432,
'database': 'postgres',
'user' : 'postgres',
'password' : os.getenv("PASSWORD")
}
# 임베딩 함수
def get_embedding(text: str, model: str = "text-embedding-3-small") -> list:
response = client.embeddings.create(
input=text,
model=model
)
return response.data[0].embedding
# DB에 저장
def save_to_postgres(text: str, vector: list):
conn = psycopg2.connect(**DB_CONFIG)
cur = conn.cursor()
try:
sql = """
INSERT INTO test_vector (student_no, name, embedding)
VALUES (%s, %s, %s)
"""
cur.execute(sql, (STUDENT_NO, text, vector))
conn.commit()
print("데이터 저장 완료!")
except Exception as e:
print("DB 오류:", e)
conn.rollback()
finally:
cur.close()
conn.close()
# 메인 실행
if __name__ == "__main__":
input_text = input("임베딩할 문장을 입력하세요: ")
embedding_vector = get_embedding(input_text)
save_to_postgres(input_text, embedding_vector)2. vector 타입 DB insert
insert into product_embeddings (name, embedding) values
( 'son', '[0.1,0.2,0.3]'::vector )- vector(1536) 타입이 별도로 존재함
- 값은 리스트를 ‘’ 로 묶은 값을 넣어주면 됨 ( ‘’ 빼면 안됨)
- vector(1536) 같은 타입을 만들었다면 반드시 ::vector 로 캐스팅해야 됨
3. 오픈 AI는 추론모델(일반 gpt 요청처리모델) 이외에 임베딩 전용 모델이 존재한다.
"text-embedding-3-small"4. postgresSQL 벡터유사도 비교

5. LLM 모델마다 임베딩 알고리즘 모델이 다르다.
-
openai 모델로 벡터 임베딩을 했으면 수정,확인 등 작업도 같은 모델로 실시해야 한다. 예를들어 gpt+ deepseek 를 섞어서 쓰면 연산결과가 정확히 나오지 않는다. (모델이 다르기 때문에)
-
임베딩 공간이 다름 : OpenAI의 text-embedding-3-small 같은 모델은 1,536차원 벡터 공간을 사용함.
-
다른 모델(예: DeepSeek, Cohere, SentenceTransformers 등)은 차원 수, 학습 데이터, 토큰화 방식이 달라 임베딩 벡터의 분포 자체가 다름.
-
유사도 계산의 불일치
- PostgreSQL pgvector 같은 DB는 단순히 수치 벡터의 거리(cosine, euclidean, inner product)만 계산함.
- 모델이 다르면 같은 문장을 임베딩해도 벡터 좌표계가 다르기 때문에 직접 비교하면 무의미
-
실무 원칙
- 삽입(저장), 검색, 수정, 검증을 같은 임베딩 모델로 통일해야 일관성 있는 유사도 비교가 가능.
- 예를 들어 OpenAI 모델로 저장한 벡터를 DeepSeek 모델 벡터와 비교하면, DB 입장에서는 단순히 “두 숫자 벡터”라 연산은 되지만, 의미론적으로는 완전히 다른 기준이라 결과가 왜곡됨.
-
예외적으로 가능한 경우
- 서로 다른 모델의 벡터를 같은 임베딩 공간으로 정렬(align)하는 변환 모델 을 따로 학습시키면 교차 사용이 가능.
- 하지만 기본적으로는 동일 모델 일관 사용이 안전한 방법.
6. Germini api 사용코드
#!/Users/hyunjunson/Project/green-hat/backend/ml-pipline/yes/envs/langCh-env/bin/python
import openai
import sys
import os
from dotenv import load_dotenv
from openai import OpenAI
load_dotenv()
GEMINI_API_URL = "https://generativelanguage.googleapis.com/v1beta/openai"
GEMINI_API_KEY = os.getenv("GEMINI_API_KEY")
LLM_ID = "gemini-2.0-flash-lite"
client = OpenAI(
base_url=GEMINI_API_URL,
api_key=GEMINI_API_KEY
)
def ai_chat(messages: list):
# openai api package를 통해 gemini api를 호출합니다.
# print(f"GEMINI API 호출, MODEL={LLM_ID}")
response = client.chat.completions.create(
model=LLM_ID,
messages=messages,
)
return response
if __name__ == '__main__':
messages = []
if len(sys.argv) < 2:
print(f"Usage: {sys.argv[0]} '질문내용'")
sys.exit()
# 명령줄 인자 전체를 합쳐서 질문으로 사용
question = ' '.join(sys.argv[1:])
messages.append({'role': 'user', 'content': question})
response = ai_chat(messages=messages)
print(response.choices[0].message.content)
- jupyter로는 argv 넣기 애매하니까 py 파일로 바꿔서 실행
- 실행시 shebang으로 jupyter kernel 정보를 넣어 주어야 함
- 커널 정보 확인 방법 : (아래)
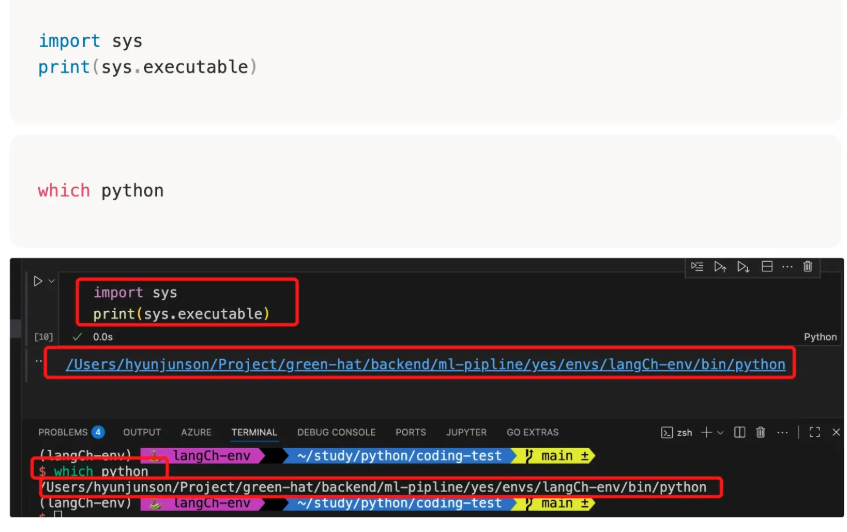
7. numpy vs tensor 의 차이점
👍 torch.Tensor와 numpy.ndarray는 비슷해 보여도 중요한 차이가 있습니다.
공통점
- 둘 다 다차원 배열을 표현.
- 슬라이싱, 브로드캐스팅, 연산 방식 등이 상당히 유사.
- .shape, .ndim 같은 속성이 거의 동일하게 동작.
차이점
1.연산 실행 위치
- NumPy → CPU에서만 동작.
- PyTorch → CPU/GPU 모두 지원 (.to('cuda') 로 GPU 연산 가능).
import torch
import numpy as np
a = np.ones((3,3))
b = torch.ones((3,3), device="cuda") # GPU에 올림2.자동 미분
- NumPy → 자동 미분 지원 없음.
- PyTorch → requires_grad=True 설정 시 autograd로 기울기 추적 가능.
x = torch.tensor(2.0, requires_grad=True)
y = x**2
y.backward()
print(x.grad) # 4.03.딥러닝 통합
- PyTorch 텐서는 신경망 모듈(torch.nn), 최적화(torch.optim), 손실 함수 등과 바로 연결됨.
- NumPy는 별도 프레임워크와 함께 써야 함 (예: TensorFlow/Keras, JAX 등).
4. 메모리 공유
- 호환성 있음: torch.from_numpy() → 같은 메모리를 공유.
- 반대도 가능: tensor.numpy().
- 단, GPU 텐서는 바로 numpy() 못 씀 → 먼저 CPU로 옮겨야 함.
n = np.array([1,2,3])
t = torch.from_numpy(n) # 메모리 공유
t[0] = 100
print(n) # [100 2 3]5. 함수 생태계
-
NumPy → 수치 해석/과학 계산에 특화 (선형대수, 푸리에 변환 등).
-
PyTorch → ML/DL에 최적화 (GPU, autograd, 신경망 계층).
-
단순 계산/과학 연산 → NumPy
-
딥러닝/자동미분/GPU → PyTorch
8. @app.teardown_appcontext
- Flask의 애플리케이션 컨텍스트가 종료될 때 실행할 함수를 등록하는 데코레이터.
from flask import Flask, g
app = Flask(__name__)
def get_db():
if "db" not in g:
g.db = connect_db() # DB 연결 생성
return g.db
@app.teardown_appcontext
def close_db(exception):
db = g.pop("db", None)
if db is not None:
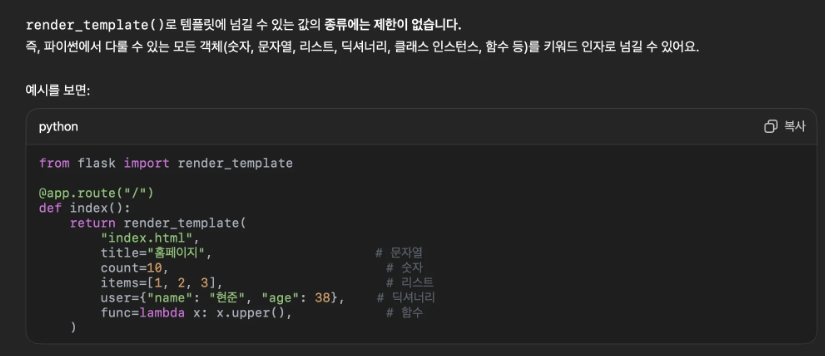
db.close() 9. render_template으로 넘길수 있는 값의 종류
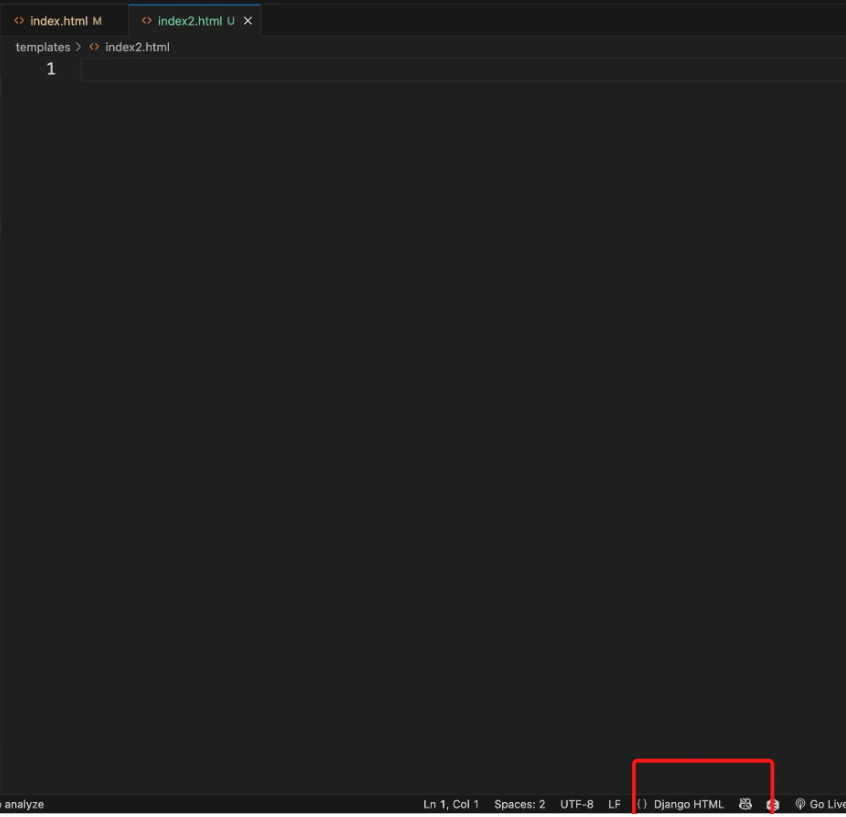
10. emmet이 작동하지 않으면 하단의 저부분을 체크해보면 됨

즐겁게 공부하고 사람들에게 도움을 주는 개발자가 되고 싶습니다.