
2-2. TCP/IP 4계층 모델 & 2-3. 네트워크 기기에 대해
2장에서 계속해서 나오는 IP 주소와 HTTP 에 대해 좀 더 자세히 알아보겠습니다.
2-4. IP 주소
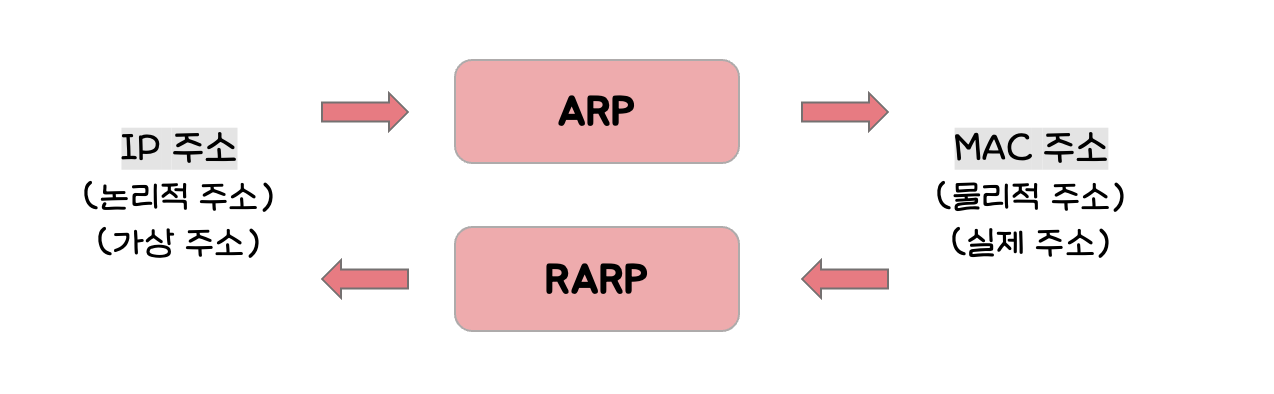
2-4-1. ARP(Address Resolution Protocol)
ARP란?
네트워크 상에서 IP주소를 물리적 네트워크 주소로 대응(bind)시키기 위해 사용되는 주소 결정 프로토콜
쉽게 말하자면, 컴퓨터와 컴퓨터 간의 통신은 IP주소에서 -> ARP 를 통해 -> MAC 주소를 기반으로 하는데, 여기서 ARP 는 논리적 주소인 IP 주소로부터 물리적 주소인 MAC 주소를 구하는 다리 역할, 매칭시키는 역할을 하는 프로토콜이다. 반대로, MAC 주소를 가지고 IP주소를 알아내는 프로토콜은 RARP 프로토콜이라고 하는데, 최근에는 거의 사용하지 않는 추세이다.
두 단말(PC와 PC, PC와 네트워크) 간 통신을 할 때에는 기본적으로 각각의 LAN(근거리 통신망) 카드에 할당돼잇는 고유한 실질적인 물리적 주소(MAC주소)를 통해 결국 데이터가 전달되게 된다. 그 이유는 MAC 주소가 시리얼 번호와 같이 전 세계에서 유일한 실제 목적지 주소이며, 이를 바탕으로 OSI 계층 또는 TCP/IP 4계층의 표준화된 모델에 따라 그렇게 통신을 하기로 약속했기 때문이다. OSI 계층 또는 TCP/IP 4계층이 궁금하다면? 클릭
2-4-2. 홉바이홉 통신
홉바이홉 통신이란?
통신 장치에 있는 '라우팅 테이블'의 IP를 통해 시작 주소부터 시작하여 다음 IP로 계속해서 이동하는 '라우팅' 과정을 거쳐 패킷이 최종 목적지까지 도달하는 통신
간단히 말해 IP 주소를 통해 통신하는 과정을 말한다.
홉(hop)이란 영어 뜻 자체로는 건너뛰는 모습을 의미하며 이는 통신망에서 각 패킷이 여러 개의 라우터를 건너가는 모습을 비유적으로 표현한 것이다. 각각의 라우터에 있는 라우팅 테이블의 IP를 기반으로 패킷을 전달하고 다시 전달해나간다.
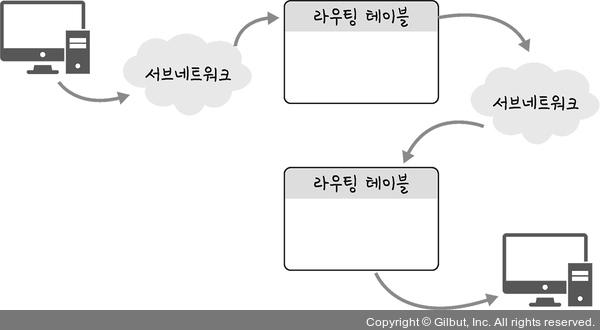
즉, 통신 장치에 있는 ‘라우팅 테이블’의 IP를 통해 시작 주소부터 시작하여 다음 IP로 계속해서 이동하는 ‘라우팅’ 과정을 거쳐 패킷이 최종 목적지까지 도달하는 통신을 말한다.
*라우팅 : IP주소를 찾아가는 과정
*라우팅 테이블(routing table) : 송신지에서 수신지까지 도달하기 위해 사용되며 라우터에 들어가 있는 목적지 정보들과 그 목적지로 가기 위한 방법이 들어 있는 리스트를 뜻함. 라우팅 테이블에는 게이트웨이와 모든 목적지에 대해 해당 목적지에 도달하기 위해 거쳐야 할 다음 라우터의 정보를 가지고 있다.
- 라우터의 로드맵과 같습니다. 여기에는 목적지 목록과 목적지에 도달하는 경로가 포함되어 있습니다.
- 각 대상에 대해 라우팅 테이블은 패킷을 '최종 목적지'으로 전달할 '다음 라우터' 또는 '게이트웨이'를 지정합니다.
*게이트웨이(gateway) : 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간의 통신을 가능하게 하는 관문 역할을 하는 컴퓨터나 소프트웨어를 두루 일컫는 용어
-
게이트웨이는 중개자 역할을 하는 컴퓨터 또는 소프트웨어로, 서로 다른 통신망, 프로토콜을 사용하는 네트워크 간에 통신을 가능하게 합니다.
-
인터넷에 액세스할 때, 우리는 종종 여러 게이트웨이를 통과하여 통신 프로토콜을 변환하고 서로 다른 네트워크 간의 원할한 연결을 촉진합니다.
📡 즉, 홉바이홉 통신은 최종 목적지에 도달할 때까지 한 홉에서 다른 홉으로 이동하면서 네트워크의 라우터를 통해 데이터 패킷을 전달하는 과정을 말한다. 이 때, 라우팅 테이블, 게이트웨이 및 적절한 경로 결정은 이 통신 프로세스를 가능하게 하는 데 중요한 역할을 한다.
2-4-3. IP 주소 체계
우리가 주로 말하는 IP 주소는 사실 IPv4, IPv6로 나눠져있다. 추세는 IPv6 로 가고 있지만 가장 많이 쓰이는 주소 체계는 IPv4이다.
IP주소는 32 자리 이진수로 구성되어 있고 이 주소는 십진수로 표현되는데 옥테드 당 ' . ' 을 찍어 구분한다. 또한, 하나의 네트워크안에 IP들은 네트워크 영역은 같아야하고, 호스트 IP는 서로 달라야 통신이 가능하다.
예를 들어 203.240.100.1 에서 203.240.100 은 네트워크 영역이고 1 은 호스트 IP라는 사실을 알 수 있다. 여기서 어떻게 네트워크 주소와 호스트 주소를 구분할 수 있을까? 바로 클래스 때문이다. 203.240.100.1 IP가 C클래스 이기 때문에 203.240.100 은 네트워크 주소이고, 1은 호스트 주소란 사실을 알아낸 것이다. 이렇게 IP주소에는 클래스라는 개념이 있고 이 클래스의 개념을 알아야 어디까지가 네트워크 영역이고 호스트IP 영역인지 알 수 있다.
(1) 클래스 기반 할당 방식
즉, 다시말해 클래스는 하나의 IP주소에서 네트워크 영역과 호스트 영역을 나누는 방법이자, 약속이다.
이런 IP주소 클래스의 종류에는 총 5개가 있습니다. 여러 클래스로 나누는 이유는 네트워크 크기에 따른 구분이라 생각하면 쉽다. 하나의 네트워크에서 몇개의 호스트 IP까지 가질 수 있는가에 따라서 클래스를 나눌 수 있다. 하지만 보통 A, B, C 3개 정도만 알고있어도 충분하다. (나머지 D, E 클래스는 멀티캐스트용, 연구용으로 사용)
IP 클래스는 예전에 IPv4 를 사용했을 때 IP를 할당하는 방법이었다. 지금은 더 이상 사용되지 않고, 클래스 방식이 아닌 CIDR 방식으로 할당하도록 바뀌었는데 왜일까?
결론만 말하자면 클래스 IP 할당방식은 낭비되는 IP 주소가 많아서이다.
이를 해소하기 위해 DHCP, NAT, IPv6 가 나오게 된 것이다.
(2) DHCP
DHCP란?
IP 주소 및 기타 통신 매개변수를 자동으로 할당하기 위한 네트워크 관리 프로토콜
- 이 기술을 통해 네트워크 장치의 IP 주소를 수동으로 설정할 필요 없이 인터넷에 접속할 때마다 자동으로 IP 주소를 할당할 수 있다.
- 많은 라우터와 게이트웨이 장비에 DHCP 기능이 있으며 이를 통해 대부분의 가정용 네트워크에서 IP 주소를 할당한다.
(3) NAT
NAT란?
패킷이 라우팅 장치를 통해 전송되는 동안 패킷의 IP 주소 정보를 수정하여 IP 주소를 다른 주소로 매핑하는 방법
IPv4 주소 체계만으로는 많은 주소들을 모두 감당하지 못하는 단점이 있는데, 이를 해결하기 위해 NAT로 공인 IP와 사설 IP로 나눠서 많은 주소를 처리한다. NAT를 가능하게 하는 소프트웨어는 ICS, RRAS, Netfilter 등이 있다.
NAT를 쓰는 이유는 주로 여러 대의 호스트가 하나의 공인 IP 주소를 사용하여 인터넷에 접속하기 위함이다. 예를 들어 인터넷 회선 하나를 개통하고 인터넷 공유기를 달아서 여러 PC를 연결하여 사용할 수 있는데, 이것이 가능한 이유는 인터넷 공유기에 NAT 기능이 탑재되어 있기 때문이다.
NAT를 이용한 보안
NAT를 이용하면 내부 네트워크에서 사용하는 IP 주소와 외부에 드러나는 IP 주소를 다르게 유지할 수 있기 때문에 내부 네트워크에 대한 어느 정도의 보안이 가능해진다.
NAT의 단점
NAT는 여러 명이 동시에 인터넷을 접속하게 되므로 실제로 접속하는 호스트 숫자에 따라서 접속 속도가 느려질 수 있다는 단점이 있다.
2-5. HTTP
기본적으로 HTTP는 앞서 설명한 전송 계층 위에 있는 애플리케이션 계층으로서 웹 서비스 통신에 사용되며, 인터넷에서 주로 사용하는 데이터를 송수신하기 위한 프로토콜이다.
2-5-1. HTTP/1.0
HTTP는 원래 0.9v 부터 시작되었다고 하지만, 사실상 1.0버전이 상용화 되어 1996년부터 사용되기 시작했다. HTTP 1.0은 단순히 open/operation/close 방식을 취하고 있는 단순한 구조이다.
HTTP/1.0은 기본적으로 한 연결당 하나의 요청을 처리하도록 설계되었다. 이는 RTT 증가를 불러오게 되었다.
RTT란?
패킷이 목적지에 도달하고 나서 다시 출발지로 돌아오기까지 걸리는 시간이며 패킷 왕복 시간
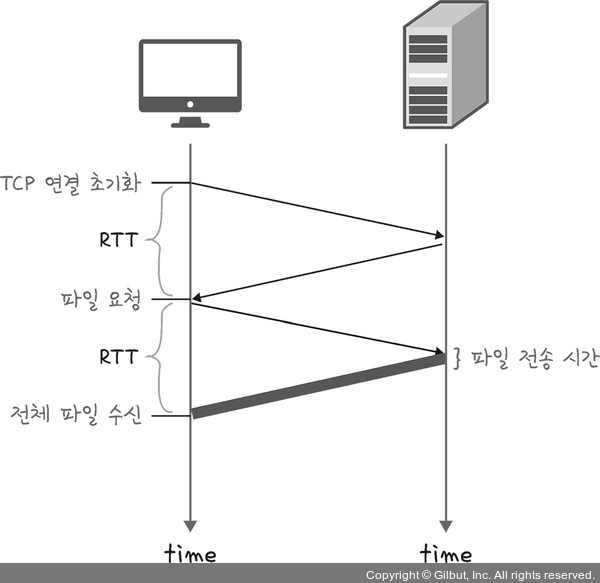
RTT의 증가를 해결하기 위한 방법
매번 연결할 때마다 RTT가 증가하니 서버에 부담이 많이 가고 사용자 응답 시간이 길어졌다. 이를 해결하기 위해 이미지 스플리팅, 코드 압축, 이미지 Base64 인코딩을 사용하곤 했다.
1. 이미지 스플리팅
많은 이미지를 다운로드받게 되면 과부하가 걸리기 때문에 많은 이미지가 합쳐 있는 하나의 이미지를 다운로드받고, 이를 기반으로 background-image의 position을 이용하여 이미지를 표기하는 방법이다.
#icons>li>a {
background-image: url("icons.png");
width: 25px;
display: inline-block;
height: 25px;
repeat: no-repeat;
}
#icons>li:nth-child(1)>a {
background-position: 2px -8px;
}
#icons>li:nth-child(2)>a {
background-position: -29px -8px;
}📷 하나의 이미지 background-image: url("icons.png");, background-position 등을 기반으로 이미지를 설정할 수 있다.
2. 코드 압축
코드 압축은 코드를 압축해서 개행 문자, 빈칸을 없애서 코드의 크기를 최소화하는 방법이다. 코드가 압축되면 코드 용량이 줄어든다.
3. 이미지 Base64 인코딩
- 이미지 파일을 64진법으로 이루어진 문자열로 인코딩하는 방법이다.
- 이 방법을 사용하면 서버와의 연결을 열고 이미지에 대해 서버에 HTTP 요청을 할 필요가 없다는 장점이 있다.
- 하지만 Base64 문자열로 변환할 경우 37% 정도 크기가 더 커지는 단점이 있다.
*인코딩 : 정보의 형태나 형식을 표준화, 보안, 처리 속도 향상, 저장 공간 절약 등을 위해 다른 형태나 형식으로 변환하는 처리 방식
HTTP 1.0의 단점
TCP Connection당 하나의 URL만 fetch하며, 매번 request/response가 끝나면 연결이 끊기므로 필요할 때마다 다시 연결해야하는 단점이 있어 속도가 현저히 느리다.
URL의 크기가 작고 한번에 가져올 수 있는 데이터의 양이 제한되어 있다.
HTTP 1.0에서는 open/close를 위한 flow의 제한으로 대역폭이 적게 할당되어 연결되는데, 이로 인해 congestion information이 자주 발생하고 disconnect가 반복적으로 나타나게 된다.
반복되는 disconnect 현상으로 인해 한 서버에 계속해서 접속을 시도하게 되면 과부하가 걸리고 성능이 떨어지게 되는 문제가 발생한다.
이런 문제를 해결하기 위해 HTTP 1.1이 등장한 것이다.
2-5-2. HTTP/1.1
매번 TCP 연결을 하는 것이 아니라 한 번 TCP 초기화를 한 이후에 keep-alive라는 옵션으로 여러 개의 파일을 송수신할 수 있게 바뀌었다. 참고로 HTTP/1.0에서도 keep-alive가 있었지만 표준화가 되어 있지 않았고 HTTP/1.1부터 표준화가 되어 기본 옵션으로 설정되었다.
HTTP/1.1의 요청-응답 쌍은 항상 순서를 유지하고 동기적으로 수행되어야 한다.
구체적으로 1개의 TCP 커넥션 상에서 3개의 이미지 (a.png, b.png, c.png)를 받는 경우, HTTP 리퀘스트는 다음과 같이 된다.
|---a.png---|
|---b.png---|
|---c.png---|✔️ 하나의 요청이 처리되고 응답을 받은 후에 다음 요청을 보낸다.
✔️ 이전의 요청이 처리되지 않았다면 그 다음 요청은 보낼 수 없다는 것이다.
✔️ 만약 a.png의 요청이 막혀버리게 되면 b,c가 아무리 빨리 처리될 수 있더라도 전체적으로 느려지게 된다.
|------------a.png------------|
|-b.png-|
|---c.png---|이것이 바로 HTTP/1.1의 HOL Blocking이다.
HTTP/1.1의 pipelining이라는 사양은 (조건부로) 요청만 먼저 보내버리는 것으로, 이 문제를 회피하는 것처럼 보인다. 그러나 응답을 보낸 순서대로 무조건 받아야 하므로 a.png가 막혔을 경우에 생각보다 큰 효과를 보기 어렵다.
HTTP 1.0 vs HTTP 1.1
1) Non-Persistent vs Persistent
HTTP 1.0과 HTTP 1.1의 가장 큰 차이점은 연결의 지속성이다. HTTP는 기본적으로 TCP를 이용하여 통신한다. 이때 HTTP 1.0은 TCP 세션을 유지하지 않고, 1.1은 TCP 세션을 유지한다는 큰 차이점이 발생한다. HTTP 1.0은 매번 데이터를 요청하고 수신할 때마다 새로운 TCP 세션을 맺어야 한다. 반면, HTTP 1.1은 한 번의 TCP 세션에 여러 개의 요청을 보내고 응답을 수신할 수 있다.
즉, HTTP 1.0은 Non-persistent HTTP, HTTP 1.1은 Persistent HTTP라고 할 수 있다. 따라서 HTTP 1.1은 TCP 세션 처리 부하를 줄이고 응답속도를 개선 할 수 있다.
2) 파이프라이닝(Pipelining)
HTTP 1.0은 파이프라이닝을 제공하지 않는다. 반면, HTTP 1.1은 파이프라이닝 기능을 제공한다.
즉, HTTP 1.0은 1번 요청을 보내고 1번 응답을 받아야지 2번 요청을 보내는 식으로 동작한다.
하지만 HTTP 1.1은 여러 개의 요청을 동시에 보낼 수 있다.
3) 호스트 헤더(Host Header)
HTTP 1.0은 하나의 IP 주소에 여러 개의 도메인을 운영 할 수 없었다. 따라서 도메인 별로 IP를 구분해서 준비해야 하기 때문에 서버의 개수가 늘어나야 했다. 하지만 HTTP 1.1은 가상 호스팅(Virtual Hosting)이 가능해졌기 때문에 하나의 IP 주소에 여러 개의 도메인을 적용시킬 수 있다.
2-5-3. HTTP/2
HTTP/2란?
SPDY 프로토콜에서 파생된 HTTP/1.x보다 지연 시간을 줄이고 응답 시간을 더 빠르게 할 수 있으며 멀티플렉싱, 헤더 압축, 서버 푸시, 요청의 우선순위 처리를 지원하는 프로토콜
(1) 멀티플렉싱 (Multiplexed Streams)
멀티플렉싱이란 여러 개의 스트림을 사용하여 송수신한다는 것이다. 이를 통해 특정 스트림의 패킷이 손실되었다고 하더라도 해당 스트림에만 영향을 미치고 나머지 스트림은 멀쩡하게 동작할 수 있다.
HTTP/2는 하나의 TCP 연결을 통해 여러 데이터 요청을 병렬로 전송할 수 있다. HTTP/2는 Multiplexed Streams를 이용하여 Connection 한 개로 동시에 여러 개의 메시지를 주고 받을 수 있으며 응답은 순서에 상관없이 Stream으로 주고 받는다. RTT 시간이 줄어들어 별도의 최적화 과정이나 도메인 샤딩없이 웹 사이트 로드 속도가 빨라진다.
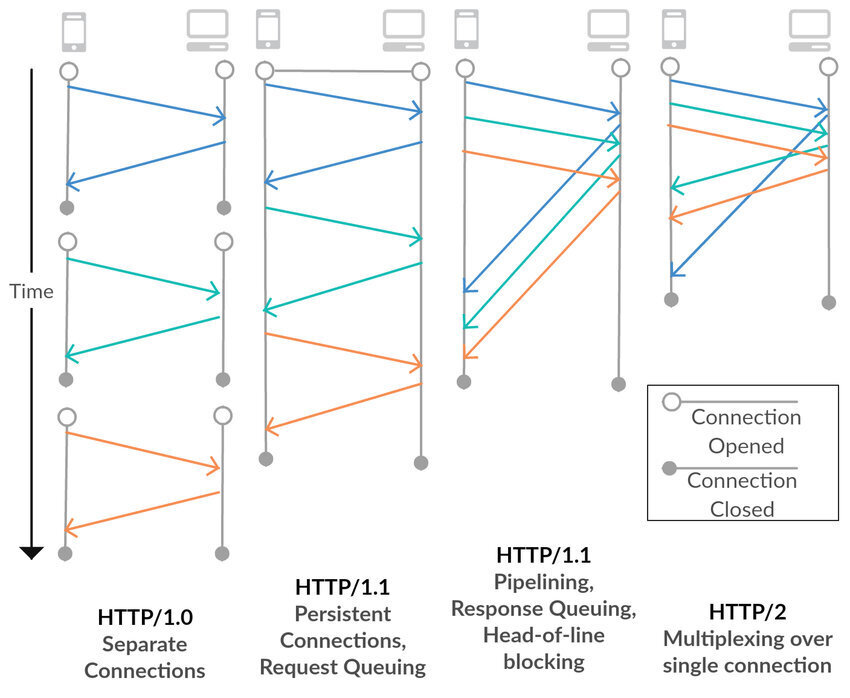
이를 통해 HTTP/1.1의 Connection Keep-Alive, Pipelining의 개선된 것을 알 수 있다. 또한, 단일 연결을 사용하여 병렬로 여러 요청을 받을 수 있고 응답을 줄 수 있어서 HTTP/1.x에서 발생하는 문제인 HOL Blocking을 해결할 수도 있다.
(2) 헤더 압축 (Header Compression)
HTTP/2는 중복 헤더 프레임을 압축해서 전송한다. HPACK 규격을 사용하는데 클라이언트와 서버에서 모두 이전 요청에 사용된 헤더 목록을 유지관리한다. HPACK은 서버로 전송되기 전에 각 헤더의 개별 값을 압축한 다음 이전에 전송된 헤더 값 목록에서 인코딩된 정보를 조회하여 전체 헤더 정보를 재구성한다.
✨ 모바일과 같이 업로드 대역폭이 상대적으로 작은 경우에는 이런 HTTP 헤더 압축 방법이 특히 유용한데, 오늘날의 HTTP 헤더는 평균 2KB 가량이고, 점점 더 커지는 추세이기 때문에 HTTP 헤더 압축의 가치는 앞으로는 더 커질 것이라고 한다.
(3) 서버 푸시 (Server Push)
HTTP/1.1에서는 클라이언트가 서버에 요청을 해야 파일을 다운로드받을 수 있었다. 하지만 HTTP/2에서는 서버는 요청되지 않았지만 향후 요청에서 예상되는 추가 정보를 클라이언트에 전송할 수 있다. 예를 들어, 클라이언트가 리소스 X에 대해 요청하고 리소스 Y가 요청된 X 파일에서 참조되는 경우, 서버는 클라이언트 요청을 기다리는 대신 X와 함께 Y를 푸시하도록 선택할 수 있다.
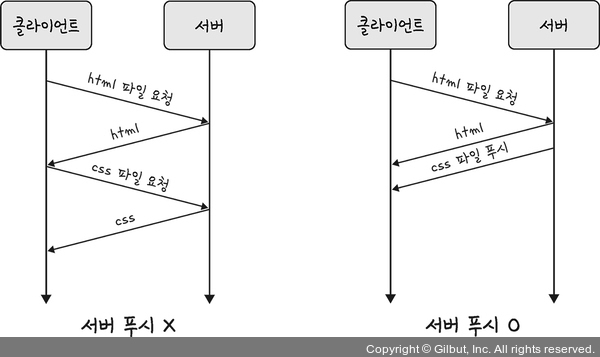
👆🏻 html에는 css나 js 파일이 포함되기 마련인데 html을 읽으면서 그 안에 들어 있던 css 파일을 서버에서 푸시하여 클라이언트에 먼저 줄 수 있다.
2-5-4. HTTPS
HTTPS란?
인터넷을 통한 보안 통신을 위한 프로토콜 ➡️ 통신을 암호화!
표준 HTTP 프로토콜과 SSL/TLS 암호화 프로토콜의 조합으로 사용자의 브라우저와 웹사이트 간에 전송되는 데이터가 암호화되어 도청이나 변조로부터 보호된다. S가 보안을 의미한다.
(1) SSL/TLS 핸드셰이크
SSL(SecureSockets Layer)/TLS 핸드셰이크는 웹 브라우저와 서버가 보안 연결을 설정하는 프로세스이다. SSL/TLS 핸드셰이크 중에 웹 브라우저와 서버는 정보를 교환하여 세션에 대한 암호화 및 인증 매개변수를 설정한다. SSL/TLS 핸드셰이크에는 다음 단계가 포함된다.
- 클라이언트 안녕하세요: 웹 브라우저가 서버에 보안 연결을 요청하는 메시지를 보냅니다.
- 서버 안녕하세요: 서버는 세션에 대한 SSL/TLS 인증서 및 암호화 매개변수가 포함된 메시지로 응답합니다.
- 인증서 확인: 웹 브라우저는 SSL/TLS 인증서가 신뢰할 수 있는 인증 기관에서 발급되었는지, 웹 사이트 소유자의 신원이 확인되었는지 확인합니다.
- 키 교환: 웹 브라우저와 서버는 세션에 사용할 암호화 키를 교환합니다.
- 세션 암호화: 웹 브라우저와 서버는 암호화 키를 사용하여 세션 중에 전송되는 데이터를 암호화 및 복호화합니다.
📡 요약하면 HTTPS는 암호화, SSL/TLS 인증서 및 SSL/TLS 핸드셰이크 프로세스의 조합을 사용하여 웹 브라우저와 서버 간에 전송되는 데이터를 암호화하여 작동한다. 이렇게 하면 두 당사자 간에 전송되는 데이터가 안전하고 권한이 없는 당사자가 가로챌 수 없다.
(2) HTTPS 와 SEO
SEO(Search Engine Optimization)란?
검색엔진 최적화를 뜻하며 사용자들이 구글, 네이버 같은 검색엔진으로 웹 사이트를 검색했을 때 그 결과를 페이지 상단에 노출시켜 많은 사람이 볼 수 있도록 최적화하는 방법
서비스를 운영한다면 SEO 관리는 필수이다. 이를 위한 방법으로 캐노니컬 설정, 페이지 속도 개선, 사이트맵 관리 등이 있는데 이러한 방법으로 내가 만든 사이트에 많은 사람이 유입되게 하는 것이다. 하지만 SEO 에서 또 하나 중요한 부분은 보안문제이다.
SSL 이 올바르게 구현될 경우 사용자의 브라우저와 웹 사이트 서버 간에 전송되는 사용자 데이터를 보호하는 데 필수적이다. HTTPS 가 안전하다는 말은 거짓은 아니지만 사실도 아니다.
2014년 구글이 SSL화를 검색 순위 결정에 포함한다고 발표한 바 있다. SSL화를 하지 않는 것이 SEO에 영향을 미치는 것은 확실하지만 항상 사이트의 경합 상황 등 검색순위는 항상 변동하기 때문에 단순히 SSL화만이 검색순위에 구체적으로 어떻게 영향을 미치고 있는지는 모른다.
그러나, SSL화가 검색 순위 평가기준에 영향을 미친다라는 것을 알고 있는 이상, SSL화는 필수항목 중 하나이다. 유저에게 있어서도 안전하게 사이트를 이용할 수 있으며, 마케팅에 대해서도 계속적인 이점을 얻을 수 있을 것이다.
❗️ 정보보호를 중시하는 현 세상의 흐름에서 HTTPS화(SSL화)는 필수라고 할 수 있다. SEO의 영향에서도 구글이 평가요소에 포함하고 있는 이상, 절대 잊어버리지 말고 대응하자
2-5-5. HTTP/3
TCP 위에서 돌아가는 HTTP/2와는 달리 HTTP/3 은 QUIC 이라는 계층 위에서 돌아가며, TCP 기반이 아닌 UDP 기반으로 돌아간다.
QUIC은 구글 엔지니어인 Jim Roskind를 주축으로 한 구글 팀에서 2013년에 공식 발표한 프로토콜이다. 초창기의 QUIC 은 "Quick UDP Internet Connections"를 의미하였다. QUIC은 TCP 기반으로 연결하는 TCP의 성능을 개선하고자 시작된 프로젝트에서 UDP를 채택한 기술로 전달 속도의 개선과 더불어 클라이언트와 서버의 연결수를 최소화하고, 대역폭(bandwidth)를 예상하여 패킷 혼잡을 피하는 것이 주요 특징이다.
QUIC과 HTTP/3는 대부분 구글 서비스에 한정되어 있고, 업계에서는 아직도 HTTP1.1을 여전히 사용하는 서비스들도 아직까진 상당히 많다.
HTTP/3가 세상에 발표된 지 얼마 안되었기에 지금은 과도기라 볼 수 있지만, 다양한 레퍼런스와 오픈 소스가 속속 진행되고 있음을 봤을 때, 앞으로 HTTP/3가 더욱 활성화될 것이다.
📍 출처
주홍철, [면접을 위한 CS 전공지식 노트]
ARP 쉽게 이해하기
https://limkydev.tistory.com/168
https://code-lab1.tistory.com/196
https://velog.io/@dnr6054/HOL-Blocking
📍 참고하면 좋을 사이트
[이해하기] ARP 프로토콜
https://velog.io/@sehyunny/everthing-you-need-to-know-about-http3
https://eun-jeong.tistory.com/27
https://www.youtube.com/watch?v=H6lpFRpyl14
SSL화란?
