0. Short Summary
- encoder-decoder block 사용하면서도 recurrence, convolution 없이 attention만 사용함으로써 병렬처리가 가능해지고, 빠른 연산이 가능해짐
I. Introduction
- RNN, LSTM, Gated RNN are SOTA models in language modeling and machine translation
- RNN, LSTM etc. factor computation along positions of input and output sequences
- drawback: 병렬연산(parallelization) 불가능
- critical at longer sequence lengths -> memory constraints limit batching across examples(long term dependency issue)
- factorization tricks, conditional computation adopted, but fundamental constraints of sequential structure remain - Attention mechanism allows modeling without regard to distance issues, used with recurrent networks
- this study suggests Transformer, architecture without recurrent network, solely on Attention mechanism, drawing global dependencies
- more parallelization and SOTA of translation quality
II. Background
Drawback of Recurrence
- Extended Neural GPU, ByteNet, ConvS2S to evade sequential computing: use CNN
- enabled parallelization
- failed at learning dependencies between distant positions
- computation increases linearly(ConvS2S) or logarithmically(ByteNet) - Transformer model operates at a constant number
- costs reducing effective resolution, by averaging attention-weighted positions(Multi-head Attention) - Self-Attention(intra-Attention): relating different positions of a single sequence to compute a representation of the sequence
- used in reading comprehension, abstractive summarization, textual entailment, learning task-independent sentence representations - Recurrent attention mechanism(not sequence aligned recurrence) showed performance on simple-language QA, language modeling
- Transformer model relies entirely on self-attention, no sequence-aligned RNNs neither CNNs
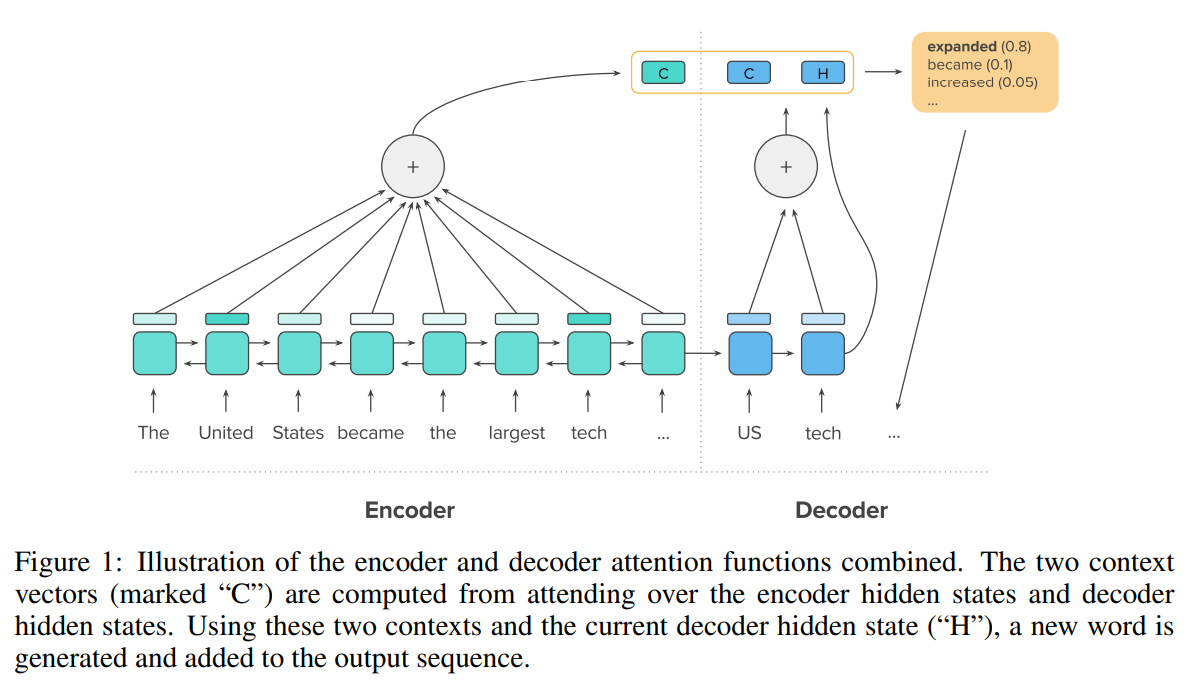
from A DEEP REINFORCED MODEL FOR ABSTRACTIVE
SUMMARIZATION(2018)
- 종전에는 encoder에 RNN, LSTM을 적용하여 사용하거나, encoder-decoder 간 계산에 attention이 사용되었음(위 논문에서 Key, Value는 context vector(C), Query는 current decoder hidden state(H)로 표현됨)
Attention
- Original Attention
from Neural Machine Translation by Jointly Learning to Align and Translate(2014)
- decoder의 특정 sequence()가 encoder의 모든 sequence 중 어떤 sequence()와 가장 연관있는가
- Self-Attention(Intra-Attention)
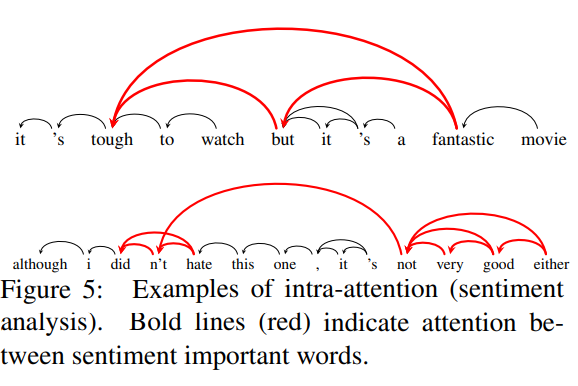
from Long Short-Term Memory-Networks for Machine Reading(2016)
- 종래에는 encoder-decoder 관계에서 각 단어의 대응관계를 찾을 수 있었음
- Query, Key, Value를 모두 같은 문장에서 추출함으로써, 하나의 문장 내에서 특정 단어가 어떠한 단어를 지칭하는지 찾을 수 있게 되었음
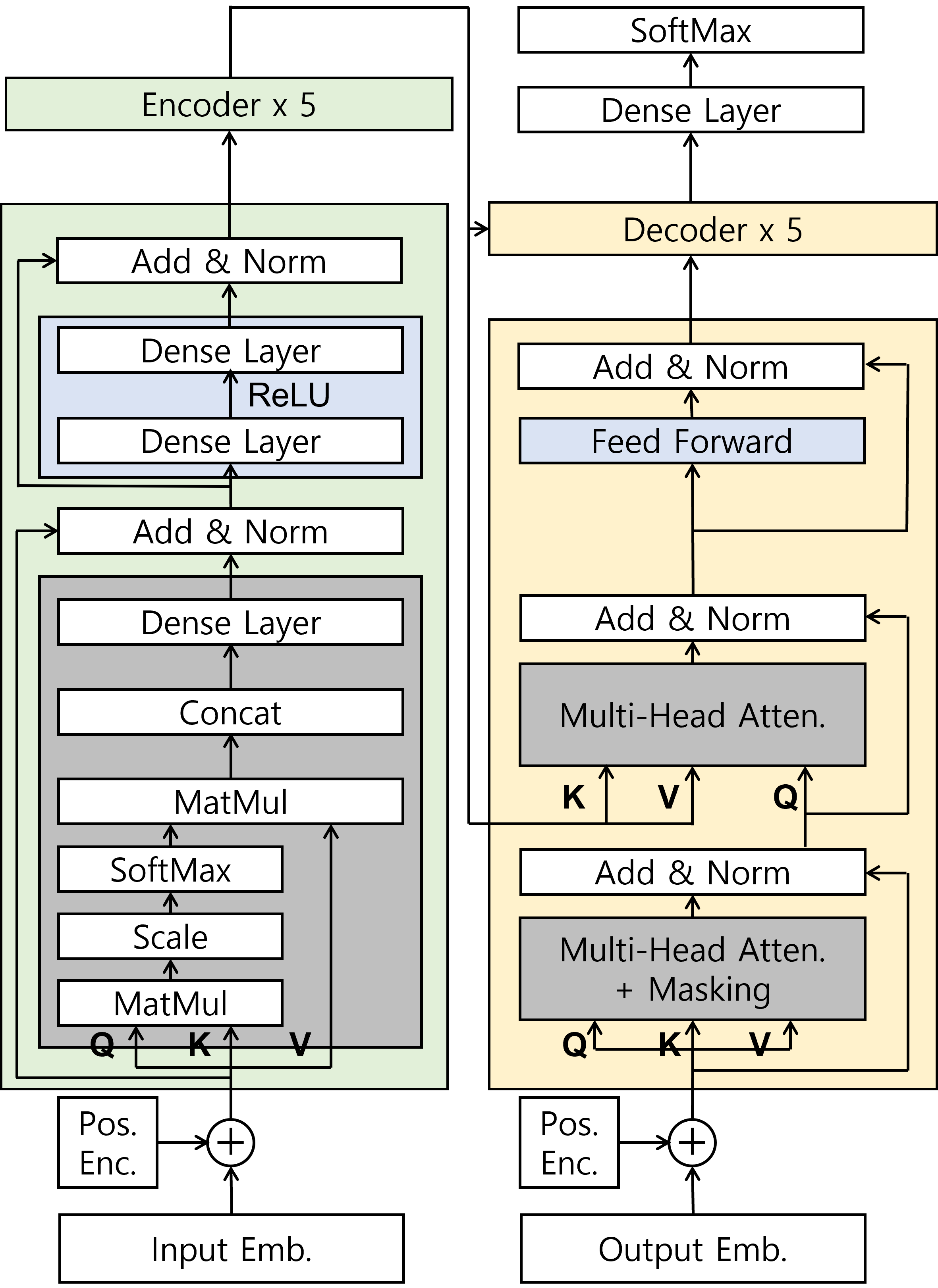
III. Architecture
Main Architecture
Positional Encoding
- recurrence, convolution 없으므로 토큰의 position(relative or absolute) 정보 부착해서 sequential order를 부여하여야 함
- positional encodings는 embeddings과 dimension 같아() positional encodings+embeddings 연산이 가능하게끔 함
- 위에서 pos는 position index를, i는 dimension index를 의미
- 왜 sinusoid인가?
- 부드러운 함수에서 추출되며, position끼리 가까우면 내적이 크고, 멀면 내적이 작아져서 내적으로부터 거리관계를 대략 유추 가능하며, max length가 다양한 dataset에도 적용 가능
- 다만, 요즘은nn.Embedding(max_length, embed_size)와 같은 embedding 방식을 이용한다는 듯
Encoder
- 6 layers of (multi-head self_attention + feed-forward network)
- 각 sublayer에는 residual connection과 layer normalization이 적용됨
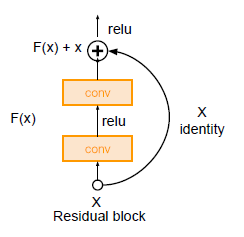
- residual connection: introduced in ResNet(2015), transfers former layer features(already learned features, ), minimizing new features to learn(from conv layers, )
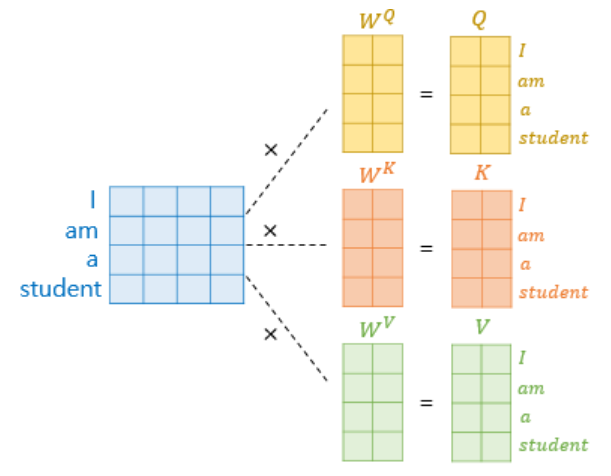
Scaled Dot-Product Attention
- : embedding size(512) x embedding size/num of head(512/8 = 64)
: seq length x embedding size(512)
Thus, shape of : seq length x embedding size/num of head
- 는 유사도 계산(attention score)을 의미
shape은 seq length x seq length: 단어 사이의 관계 표현 가능
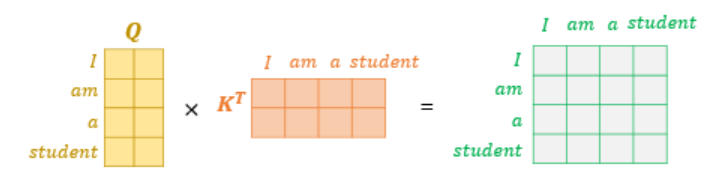
- 는 attention value
- 는 'temperature'로 기술됨: temperature가 없을 시 값이 너무 커지거나 작아지는 것을 막아 softmax가 원활히 동작할 수 있게 함
Multi-Head Attention
- linearly project queries, keys, values head(h) times respectively
- perform attention function in parallel
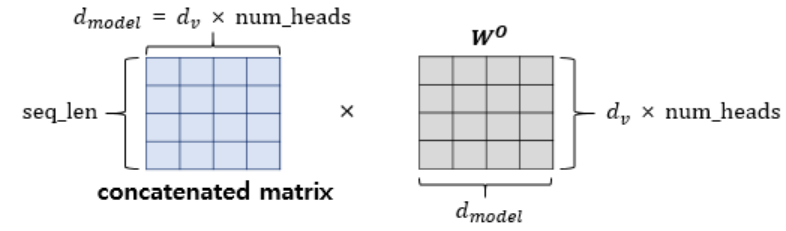
- 위의 결과를 concat하고, fc layer에 통과시킴: 다시 shape이 seq_len x dimension(512) 되어서 다음 block으로 넘어갈 수 있게 됨
- 왜 Multi-head Attention을 사용하는가?
- 모델이 different representation subspaces와 different position으로부터 정보 접근할 수 있음
- 다만, # of head(h = 8)로 dimension이 나누어져 병렬연산되므로 computational benefit은 없음 - 본 논문에서는 8 attention layers() 적용,
- Encoder 내부의 attention은 self-attention이므로, Q, K, V 모두 이전 layer output에서 도출
Feed-Forward Layer
- dense_layer-ReLU-dense_layer, position wise, different parameters
Decoder
- 6 layers of (multi-head attention + encoder-decoder layer + feed-forward network)
- multi-head attention sublayer에 masking() 넣어 대상 단어 이후의 단어가 연산에 고려되지 않도록 함(illegal connection)
- encoder-decoder layer에서 K, V는 encoder에서, Q는 decoder에서 도출됨
IV. Why Self-Attention

- Complexity per Layer: shape 모두 seq_len x embedding size/head 이므로
- Sequential Operations: 병렬화 가능여부
- Maximum Path Length: long-term dependency와 관련, 단어 사이 거리가 멀어도 query-key 관계 설정하므로 상수 시간복잡도
- 이외에도, model이 interpretable하게 됨: attention head의 역할(syntactic, semantic or task-oriented) 확인 가능
V. Training
- English-German: WMT 2014 English-German dataset(4.5 mln sentences)
- BPE 이용해 encoding tokenize: token num 37,000 - English-French: WMT 2014 English-French dataset(36 mln sentences)
- token num 32,000 - training batch는 source-target 모두 token num 25,000 가량 되도록 batch 설정
- Adam optimizer 사용
- regularization:
- sub-layer output에 dropout(0.1) 적용
- embedding sum, positional encoding(encoder, decoder both)에 dropout(0.1) 적용
- training 시 label smoothing(0.1) 적용: perplexity 개선에 지장을 주나, accuracy와 BLEU score 개선에 도움을 줌
label smoothing: hard label(1 or 0)에서 soft label(label이 0과 1 사이의 값으로 구성됨)
where equals class number, is smoothing parameter(hyperparameter)
VI. Result
-
BLEU score: 기계 번역의 성능을 측정하는 지표, n-gram을 이용해 사람의 번역결과와 비교
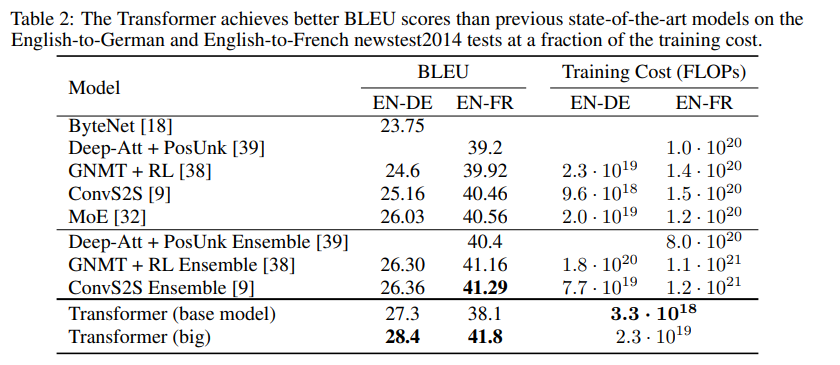
-
big transformer model은 English-French, English-German 모두 SoTA BLEU 경신
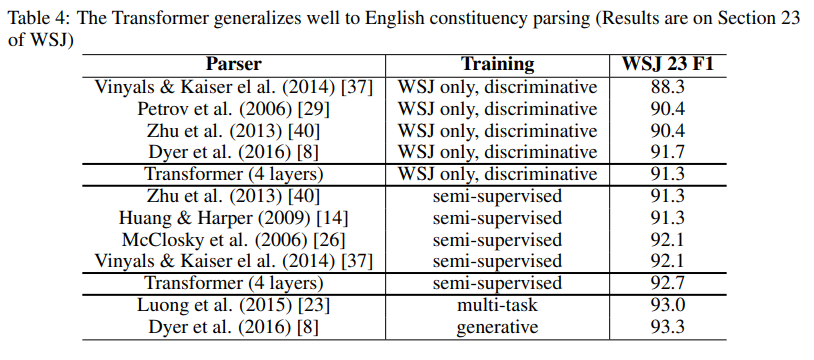
-
generalized model인지 확인 위해 English constituency parsing 진행, task specific tuning 없이도 SoTA 경신
- Penn Treebank의 WSJ 40k sentences에 대해 학습(16k tokens) & BerkleyParser corpora 17 mln sentences(semi-supervised learning, 32k tokens)
VII. Conclusion
- 1st model entirely on attention, recurrence based model과 encoder-decoder architecture를 multi-headed self-attention으로 대체 가능
- translation task에 대하여, recurrent/convolutional model보다 더 빠르게 학습 가능, SoTA 경신
- text뿐 아니라 image, audio, video에 대해서도 적용 가능할 것으로 예상

multidisciplinary