Efficient Estimation of Word Representations in Vector Space (2013) a.k.a. Word2Vec
2nd semester 2022 NLP study
목록 보기
2/8
I. Introduction
- 당시의 많은 NLP task approach는 vocabulary 내의 word를 가장 기초적(atomic)인 단위로 간주
- simplicity, robustness, 간단한 모델 & 많은 데이터만 있으면 적은 데이터 & 복잡한 모델보다 outperform
- no idea of 'similarity' between words
- a.k.a statistical language modeling e.g. N-gram
- 참고: 차원의저주 - domain-relevant & huge data 구하기 힘듦: limitation of statistical language approach
- advanced technique suggested therefore: distributed representations of words + neural network language model
- Goal of the Paper: (1) 'billion 단위의 dataset'에서 (2) 'million 단위의 vocabulary'에 대한 (3) high-quality word vector 구축
- 선행연구에서 50-100 dimension의, million 단위 word vector는 train한 바가 없다고 함
1.2 Previous Work
- NNLM 제시: Y. Bengio, R. Ducharme, P. Vincent. A neural probabilistic language model. Journal of Machine Learning Research, 3:1137-1155, 2003.
- NNLM 발전: T. Mikolov. Language Modeling for Speech Recognition in Czech, Masters thesis, Brno University of Technology, 2007., T. Mikolov, J. Kopecky, L. Burget, O. Glembek and J. ´ Cernock ˇ y. Neural network based language models for higly inflective languages, In: Proc. ICASSP 2009.
II. Model Architectures
Why Distributed Representations of Words?
- 많은 논문들에서 Latent Semantic Analysis(LSA), Latent Dirichlet Allocation(LDA)가 사용되었으나, neural network에서 학습된 distributed representations of words가 낫다는 결과가 많으므로 distributed representations of words를 구현하는 것에 초점을 두도록 함
- 더 나은 performance의 이유: linear regularities 가능
- LDA는 LSA보다 expensive on large data sets
- LSA는 DTM을 truncated SVD를 통해 dimension reduction 실행하여 설명력 높은 정보만 남김으로써 '잠재된 의미(latent semantics)'를 드러냄
- 다만, LSA는 word representation 간 algebraic operation의 성능이 떨어짐
- 또한, LSA는 새로운 데이터가 추가되면 처음부터 다시 계산되어야 하므로 새로운 정보에 대한 업데이트가 어렵고, 이는 NNLM 및 Word2Vec이 주목받는 이유가 됨
- 출처: 위키독스
Computational Complexity (# of parameters)
- where is # of training epochs, is # of words in training set, is model-relevant variable
- 보통, from 3 to 50, up to 1 bln
- SGD & back propagation used
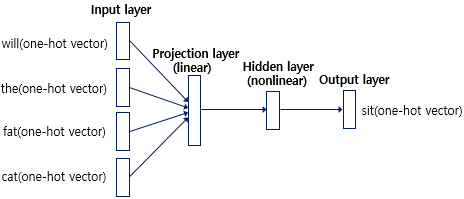
2.1 Feedforward Neural Net Language Model (NNLM)
- computational complexity of
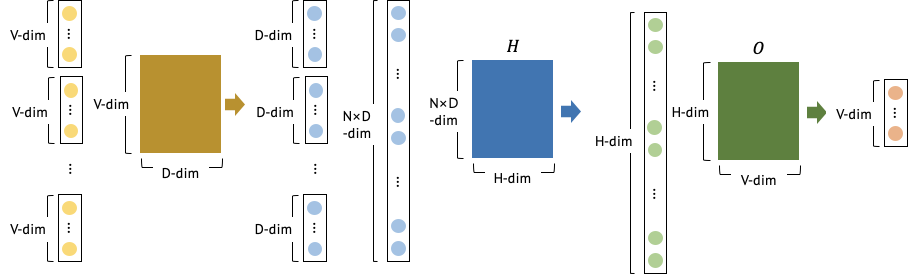
: # of previous words
: dimensionality
: hidden layer size(# of hidden layer nodes)
: size of vocabulary
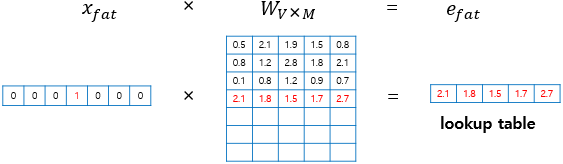
- : input과 projection layer 사이의 연산 및 projection layer()의 dimensionality, 에 속하는 word의 one-hot encoding()이 word embedding()에서 look-up되는 연산
- : projection layer과 hidden layer 사이의 연산, projection layer의 결과물()에 hidden layer nodes fully connecting 연산()
- : hidden layer의 결과물에 softmax 통과시켜서 나온 vocabulary에서의 output
- common choice: = 10, size of projection layer()= 500~2000, = 500~1000
- 가장 연산이 많은 부분은 이지만, hierarchical softmax를 이용해 로 축소할 수 있음
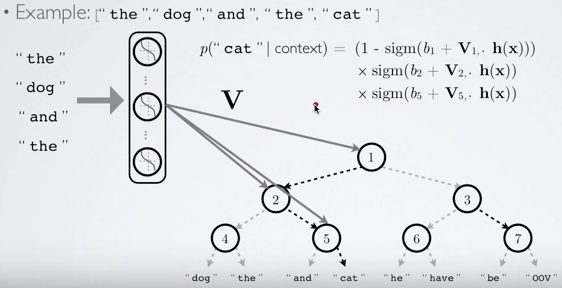
- output을 softmax 대신 binary tree를 이용해 값을 얻는 방법, terminal node가 각 단어, root부터 terminal node까지의 path가 확률에 대응됨
- softmax 대신 sigmoid를 사용하므로 연산량이 줄어듦
- 출처: [NLP | TIL] Negative Sampling과 Hierarchical Softmax, Distributed Representation 그리고 n-gram - 따라서 가장 큰 연산을 차지하는 부분은
2.2 Recurrent Neural Net Language Model (RNNLM)
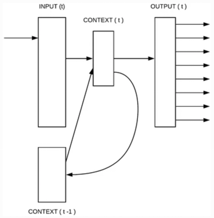
- recurrence based model은 상술한 을 정의할 필요가 없으며, shallow NN보다 representing complex patterns에 강점
- input, hidden, output layer
- recurrent matrix가 hidden layer와 recurrent matrix itself 연결하므로 short term memory를 구성할 수 있음 - computational complexity of in case of RNN
- words representation()이 hidden layer()와 같은 dimensionality 보유한다고 가정할 때
- hierarchical softmax를 사용한다면 로 축소 가능
- 가장 연산량 많은 부분은
III. New Log-Linear Model
- 가장 연산량 많은 부분은 non-linear layer(NNLM: , RNN: )
- 위 part를 제거하면 정확도는 떨어질 수 있으나 efficiency는 상승할 것임
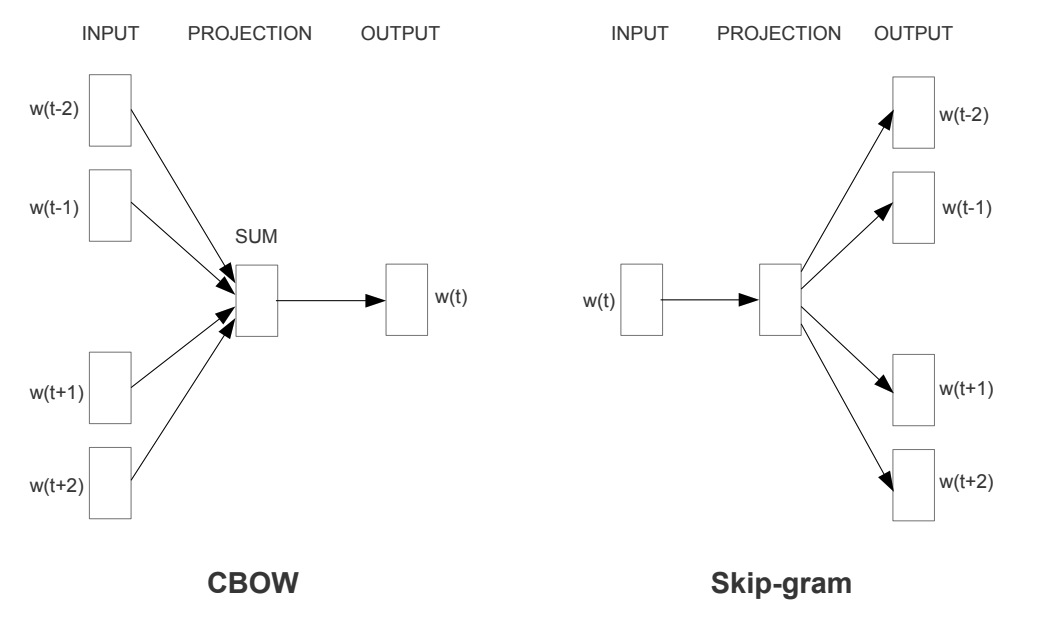
3.1 Continuous Bag-of-Words Model
- feedforward NNLM과 비슷하지만, hidden layer(non-linear layer)가 삭제됨
- 예측하고자 하는 단어 앞뒤로 4개씩 총 8개의 단어(context)를 이용해 해당 자리의 단어를 classifying함
- non-linear layer가 없으므로 CBOW에서는 word vector의 합을 단순히 평균함
- 단순합 -> 평균이므로 단어의 순서가 영향을 주지 않음
- computational complexity:
3.2 Continuous Skip-gram Model
- 단어를 제시하고 해당 단어와 같은 문장에서 선후에 등장한 단어의 등장을 예상하는 것
- window size 커질수록 quality 향상되지만 complexity도 증가함
- computational complexity:
where is the maximum distance of the words
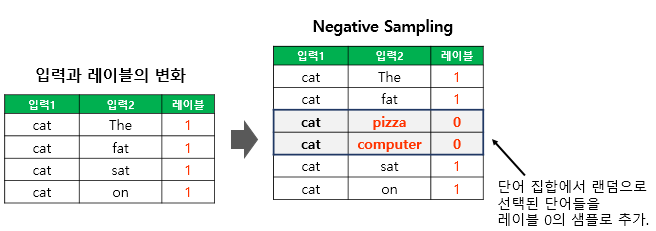
Misc. Negative Sampling
-
중심 단어가 주어졌을 때 그 주변 단어의 출현 예측이었던 skip-gram과 다르게, skip-gram with negative sampling은 중심단어와 window 내의 단어들이 같이 등장할 확률을 구함
-
실제로 중심단어와 함께 등장한 단어는 label 1, 중심단어와 함께 등장하지 않은 단어를 random으로 뽑아서 label 0를 부여하여 binary classification으로 만듦
-
vocabulary size가 클 때 사용될 수 있음
IV. Result
- 선행 연구에서 word vector의 성능을 논할 때 예시 단어와 가장 비슷한 단어들로 이루어진 표를 제시하여 본능적 내지 감각적(intuitively)으로 이해하도록 하였음
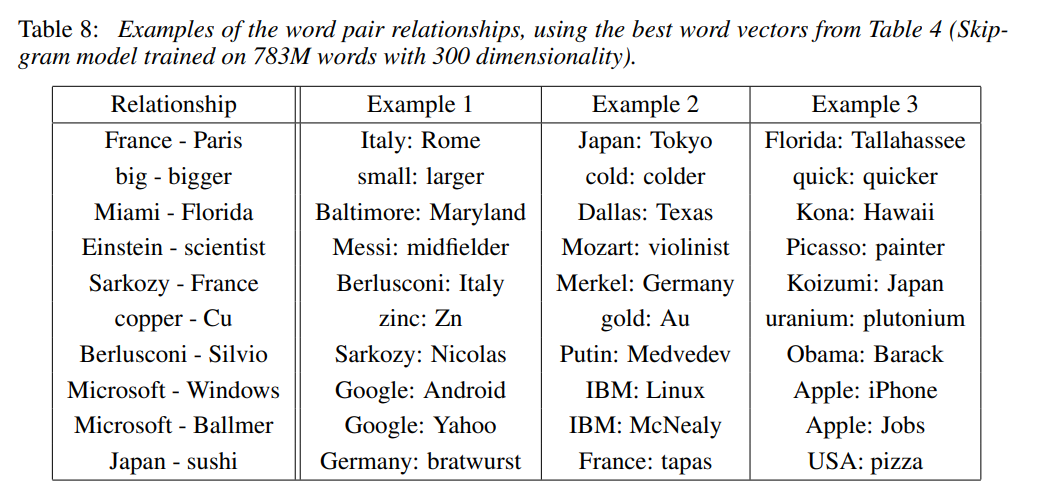
- 그러나 위와 같은 방법은 다양한 similarities(e.g. small-smallest, big-bigger)를 제대로 포착하지 못함 - 본 논문의 word vectors quality compare의 핵심: "What is the word that is similar to small in the same sense as biggest is similar to big?"
- word vector 간의 algebraic operation으로 답변 가능함
- vector 가 구해진 이후, cosine distance를 이용해 와 가장 가까운 word를 도출할 수 있음 - high dimensional word vectors의 경우 subtle semantic relationships까지도 포착 가능(e.g. France-Paris, Germany-Berlin)
- 기계번역, 정보검색(information retrieval), QA etc.에 대해 성능 향상을 노려볼 수 있음
4.1 Task Description
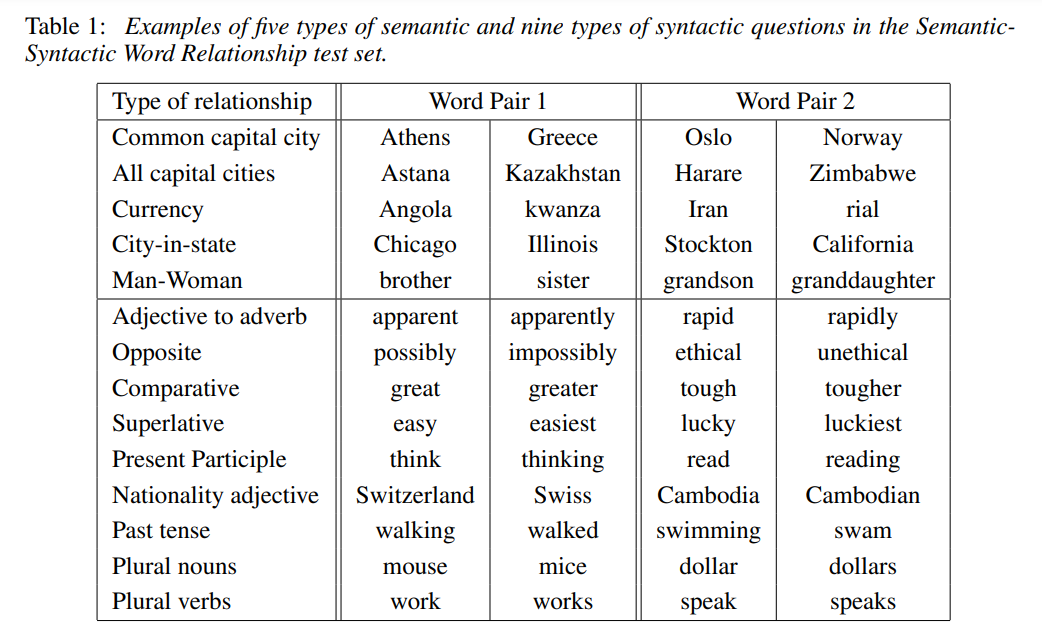
- 5 types of 8,869 semantic Q's, 9 types of 10,675 syntactic Q's: 비슷한 단어들을 manually grouping, connecting pairs afterwards
- 상술한 방법으로 Q-A 쌍이 정확하게 일치할 경우만 적절한 Q-A pair로 인정하였으므로 synonym은 정답으로 인정 않음
4.2 Maximization of Accuracy
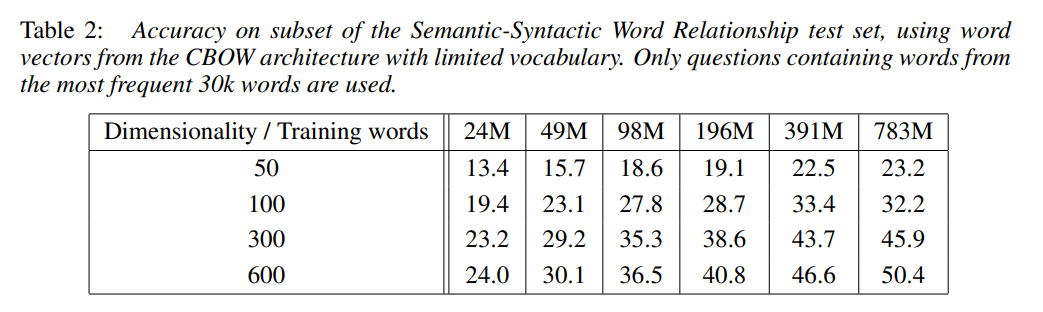
- training corpus: Google News (6 bln tokens), vocabulary size: 1 mln
- training data 혹은 dimensionality 중 하나만 증가시키는 것은 성능증가가 체감함
당시 많은 연구가 단순히 large amount of data에 의존하려 했으나, training data와 dimensionality 모두의 증가가 없으면 성능 향상이 불가능함
4.3 Comparison of Model Architectures
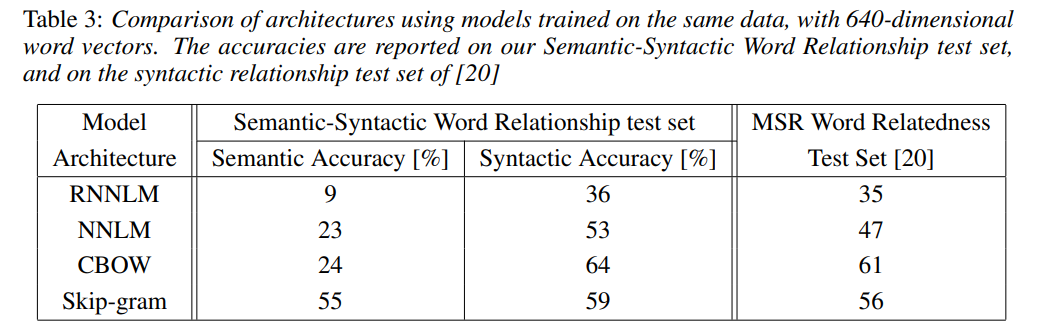
- RNNLM이 가장 낮은 성능(다만, syntactic task에 well performance)을, NNLM이 그보다 나은 성능을, CBOW와 Skip-gram이 RNNLM, NNLM보다 나은 성능을 보여주었음
- skip-gram은 semantic, CBOW는 syntactic 분야에서 더 높은 성능을 보임
4.4 Large Scale Parallel Training of Models
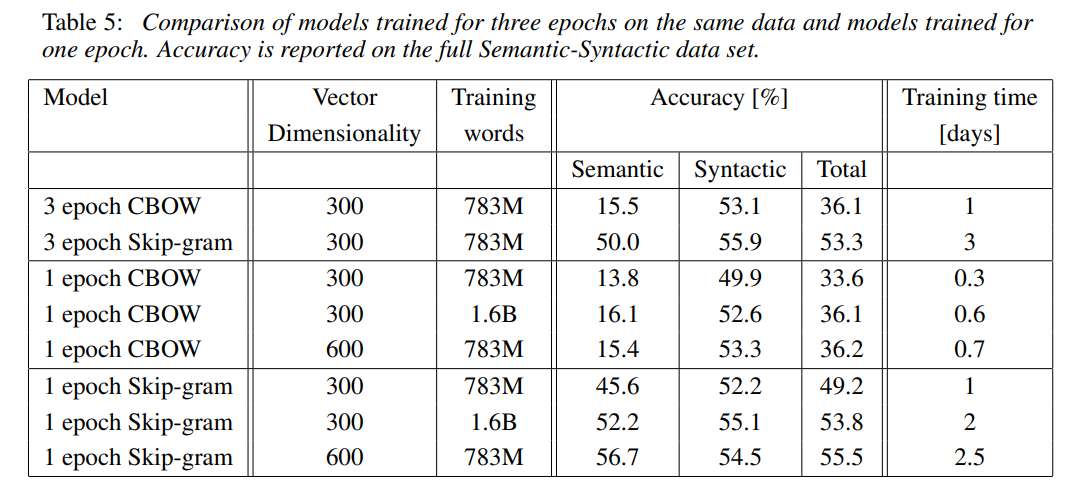
- 병렬처리 위해 DistBelief 사용
- NNLM보다 CBOW, Skip-gram이 training time이 적게 걸림
4.5 Microsoft Research Sentence Completion Challenge
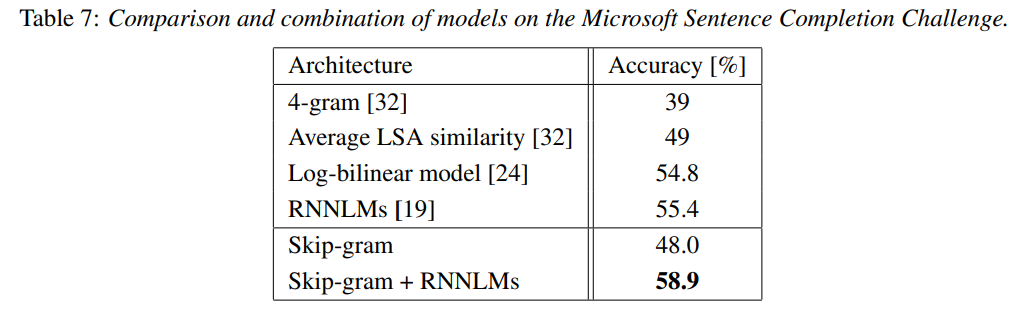
- 1,040개의 각 sentence에서 누락된 word를 예측(선택지 5개)하는 task
- skip-gram 단독으로는 SoTA 달성 못했으나, RNNLM과 같이 사용되었을 때 SoTA 달성
V. Example
VI. Conclusion
- simple model architecture(RNNLM, NNLM과 비교하여)에서 high quality word vectors training
- lower computational complexity: possible to compute accurate high dimensional word vectors from larger dataset

multidisciplinary