ExpandR: Teaching Dense Retrievers Beyond Queries with LLM Guidance (arXiv 2025)
TL;DR
- Background: retriever-generator 구조에서 retriever와 generator가 따로 학습되어 generator와 ranker가 align되지 않는다는 문제
- 저자가 원한 흐름은 다음과 같음:
- conventional DPR LLM을 이용해 query expansion (prompting): 어라 retriever랑 align되지 않아 문제가 생기네?
LLM과 retriever를 같이 학습: 어라 retriever가 너무 작아서 학습에 한계가 있네?
그러면 LLM을 학습시키되, retriever랑 비슷한 reward 추가해서 optimize하자!
- conventional DPR LLM을 이용해 query expansion (prompting): 어라 retriever랑 align되지 않아 문제가 생기네?
- 저자가 원한 흐름은 다음과 같음:
- Approach: LLM과 retriever를 jointly optimize하는 ExpandR 제안
- Method:
- LLM은 query expansion (with semantically rich information) 해서 retriever training에 사용
- 또한, LLM은 retriever reward와 generation consistency reward를 결합하여 DPO로 학습
- 그럼으로써 informative & well-suited for retrieval한 query expansion하는 LLM으로 재탄생
- Experiment & Result: ExpandR이 retrieaval performance 5% outperform
- github code
- 인상
- domain specific retriever랑 엮으면 좋을 것 같은 느낌
- modality가 다른 데이터에 학습된 embedding model에도 적용할 수 있을까??
- BEIR benchmark는 오히려 좋은 실험이 아니라고 생각: 너무 general함
- previous studies에서 열심히 finetuing/prompting query expansion 말해놓고 실험에서는 없다는 게 짜치고, baseline도 너무 outdated: Appendix에 더 많은 baseline들이 있는데, 이게 본문에서는 언급이 안 된다는게 문제임
- notation에서 약간의 혼동이 있고, experiment section에서 똑같은 backbone 두 번 설명했다는 사소한 찐빠가 있음
Background
-
DPR이 효과적이긴 하나, query가 제대로 작성되었을 경우에 한함
-
LLM이 나온 이후로 query augmentation method가 많이 발표되었는데, 두 갈래로 나뉨
(0) (태초의 w/o query expansion) bottleneck이 발생해서 query often underspecified, ambiguous, semantically incomplete
(1) (학습) LLM-generated reformulation을 retrieval model의 학습 데이터로 넣고, contrastive learning이나 ranking probability distillation으로 학습하는 경우 (Replug, Syntriever). 그런데 이는 retriever 자체가 작아서 문제임- query synthesis에 집중해서 original query의 semantic expresiveness가 부족한 경우는 간과할 뿐더러, retriever의 capacity 한계에 봉착
- 그 외에는 retrieval, generator를 따로 학습시키거나, 이 둘을 align하더라도 별도의 reranker를 사용하는 등 indirect training signal 이용
(2) (비학습) 따로 학습하지는 않고, LLM을 zero/few-shot 써서 query rewriter로 사용하는 경우(augmenting dense retrievers by prompting LLMs to generate additional terms at inference time; Query2Doc, Generative Relevance Feedback). 이는 lexical overlap을 늘려서 query & document의 semantic gap을 메우가 위함임. 그럼에도 LLM이 retriever와 같은 objective로 학습되지 않았다보니 (따로 학습을 안 하고 prompting으로 퉁치다보니), LLM이 retriever와 misalign될 수 있음
Approach
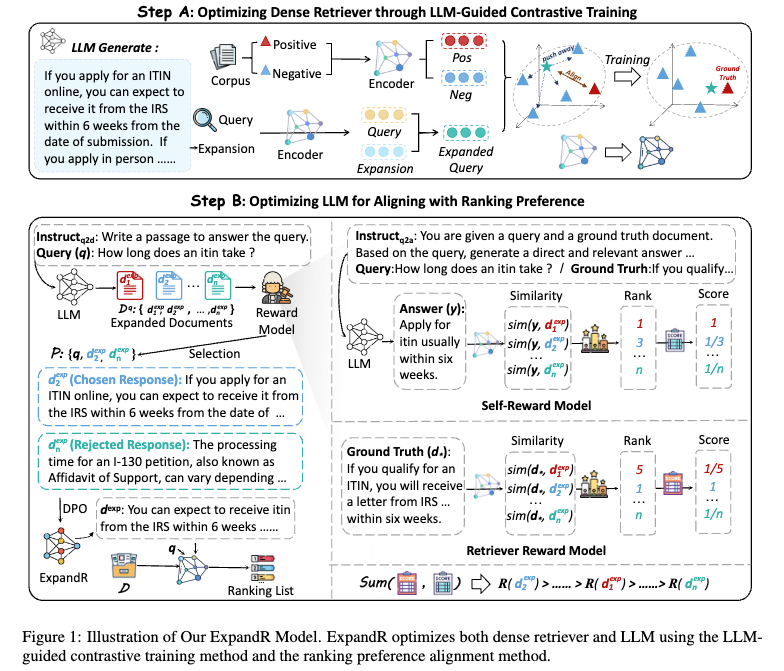
- ExpandR 제안: unified LLM-augmented dense retrieval framework that jointly optimizes both the LLM and the dense retriever
- retriever와 generator를 별개의 모듈로 보지 않고 training objective를 통합해서 ground-truth document에 higher rank를 줄 수 있도록 함
(1) LLM prompting으로 풍부한 정보를 담고 있는 query expansion (query representation 향상)
(2) expanded query는 retriever가 ranking 결과물을 향상시킴
Method
- retriever와 LLM을 모두 학습 (단, separately)
- retriever는 contrastive learning으로, LLM은 self-consistency & retrieval-based reward 이용한 DPO로 학습
- 이렇게 하면 expansion과 retrieval perforamnce를 mutually reinforce할 수 있다고 함
Notation & 수학적 근거
- traditional retriever
: query, : document
, 어라 왜 BERT_q랑 BERT_d를 따로 놨지? 원래 모델 같게 해서 동일 embedding space에 놓는데
relevance score , similarity score는 dot production 썼다고
이후에 KNN 써서 top-ranked document retrieve
- ExpandR: 내가 보기에 원문의 는 라고 써야 하나,
3.2에서 가 나오는 관계로 다르게 쓴 듯함
expanded query
는 query expansion을 위한 prompt

chain rule:
: golden truth retrieved document
: parameter of retriever
: parameter of LLM
- 곧 objective는 retriever()와 LLM()을 함께 optimize하는 것임 (log likelihood maximize)
Training Retriever
- retriever parameter가 이므로 후항 는 fix하고 전항 만 argmax로 optimize하면 됨
- 는 original query 와 expanded query 를 incorporate (averaged vector) 한 결과물
- 가 최종 expanded query이고, candidate document와 query의 similarity는 로 계산
Training Loss: Contrastive Loss
trainign loss
- 는 in-batch negative document samples
Training LLM
Back to equation
- retriever parameter 를 고정하고 LLM parater 를 optimize해야함
- 그런데 를 업데이트한다는 것은 당연히 후항 에 영향을 미치지만, 전항 에서도 expanded query 를 생성하는 데에 간접적으로 영향을 미칠 수밖에 없음
- 따라서, optimization은 아래와 같음 (retriever parameter optimization 에 항 추가된 형태)
- 가 잘 생성되면 당연히 후항 의 log likelihood를 증가시킬 것이고, 전항 에서도 간접적으로 retrieval performance를 향상 (golden truth retrieved document의 log likelihood 상승) 시킨다는 것을 의미 저자들이 말했던 LLM한테 retrieval-friendly optimization이 가능 & 효과있다는 근거
- 원 논문에서는 빠져있지만, expanded query 가 discrete distribution (plain text) 이므로 backpropagation을 이용한 학습이 힘들어 일반적인 loss function & backprop 대신 reward modeling 을 사용할 수밖에 없음 (내 개인적인 견해이지만, 사용하지 않고, 어떻게든 이 가능하다면 backprop이 가능하지 않을까..
- 여하든 그래서 2개 항을 모두 포괄할 수 있는 reward modeling 사용
Reward Modeling
reward function
: self-reward
: retriever reward
self-reward
- 의 likelihood 늘리기 위함임
: query 에 대해 answer 를 생성하게끔 하는 guide

- 위를 통해 만들어진 answer 를 query로 간주하고, expansion candidates 집합 를 rank 해서 self-reward score를 아래와 같이 계산함 (논문에는 안 나오는데, Reciprocal Rank랑 같은 것 같음)
는 를 이용해 계산 (rank면 float가 아니라 discrete 아닌가..?)
- rank가 높다는 것은 semantic similarity가 높다는 뜻이기도 하며, 이는 다시 말해 와 사이의 consistency가 높다는 의미이기도 함
retriever reward
- self-reward는 답변 생성을 잘 했는지 판단할 뿐 (의 semantic plausibility 판단), retrieval의 usefulness를 판단할 수는 없음 ( )
- 이를 보완하기 위해 MRR 기반의 reward 사용 (candidate 집합 에 대한 MRR)
- notation은 self-reward와 대동소이하나, ground truth document 를 pseudo-query로 사용하여 expanded query 와의 유사성을 계산한다는 차이가 있음
LLM Optimiation
- LLM finetuning에 기본적으로 DPO 사용 (실제로 코드 까보면
trllibrary에서DPOTrainer불러와서 땡친다..) - steps
(1) LLM+prompt로 temperature 다르게 설정해서 query expansion candidates set 생성 (실제 실험 세팅에서는 semantically similar하지 않은 query candidates는 날림)
(2) 상기한 reward model 이용해 training tripes set 구축 (where )
(3) DPO로 학습: DPO 수식과 다른 것 없고, 원래의 DPO에서는 human label 통해 , 를 구별하지만, 이 논문에서는 위의 reward 식을 이용해 를 만들어 동일하게 사용.
: sigmoid function
: scaling hyperparameter
: frozen reference model (LLM 과 같은데, 학습의 대상은 아닌 스냅샷)
: reward score에 따라 만들어진 preference pairs
Experiment Setting
- BEIR benchmark 사용: MSMARCO, HotpotQA, TREC-COVID 등 heterogeneous IR dataset 모아놓은 benchmark임
- dataset: dataset 별로 train/test를 분리: E5는 train/valid 용으로, MSMARCO, BEIR는 test용으로 사용
- metric: nDCG@10 사용, permutation test 진행 (p < 0.05)
- baseline: BM25, DPR, CoCondenser, ANCE (너무 outdated되지 않았나)
- backbone model: retriever로 BERT, Contriever, AnchorDR 바꿔가면서 사용, LLM으로는 LLaMA-3-8B-Instruct + LoRA (Appendix에 Qwen2.5-7B에 대한 실험결과도 있음)
Result
- supervised dense retrieval에서 5.8% improvement
- ExpandR을 이용한 query expansion이 relevant documents와 better aligned
- self-consistency와 retrieval-based reward를 이용했을 때 semantically rich & retriever-aligned expansion 가능함 확인 (LLM이 relevant & retriever-friendly 하게 학습됨)
- self-consistency reward는 ground-truth document와 semantically close하게 학습
- retrieval-based rewardsms retriever의 ranking behaviour를 따라함
Overall Result
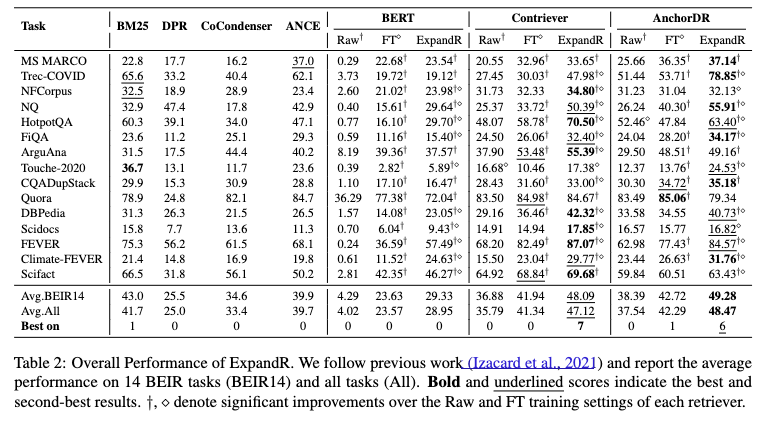
- BERT로는 어떻게 해도 성능이 후진 거 보면 retrieving task에 pretrained된 embedding 모델이 확실히 필요하긴 함

- case study
Ablation study
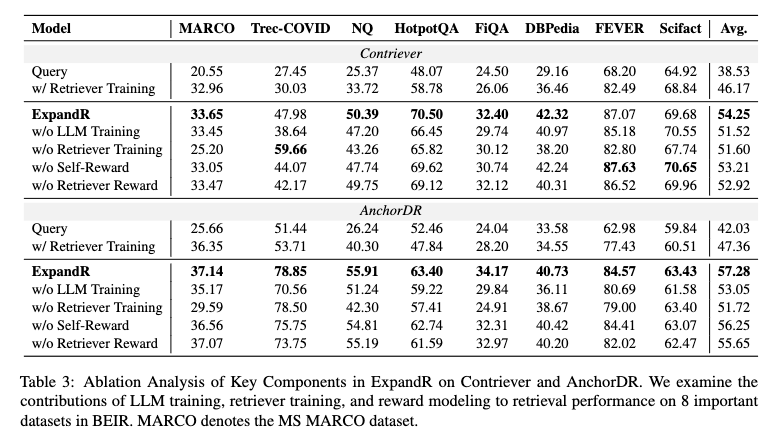
- 'query' column:raw queries, without training
Visualization of Alignment in the Semantic Embedding Space
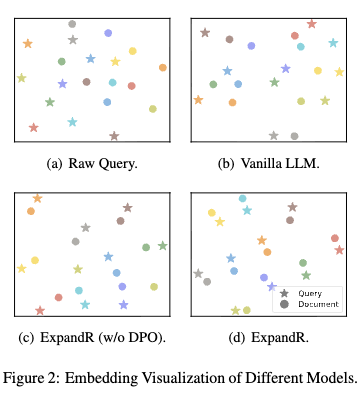
- star는 query, circle은 document
- 믿을 수가 없다. 너무 그림이 예뻐. 솔직히 w/o DPO랑 w/ DPO랑 차이를 figure로는 잘 모르겠음
Effectiveness of Reward Modeling in Optimizing ExpandR
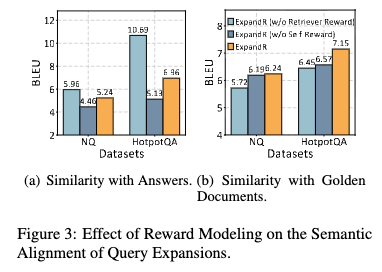
- 3(a)는 답변과 얼마나 align되는지, 3(b)는 golden truth retrieved documents와 얼마나 align되는지 보이는 것
- w/o retriever reward가 '정답 텍스트'와는 제일 잘 align되지만 golden documents와는 잘 align되지 않음
- (Appendix A.8) 특이하게도, self-consistency reward가 없으면 말이 너무 길어지고, DPO의 고질병인 verbose bias가 있음
- over-generating과 hallucination 억제에 효과가 있더라..
- 생각해봤을 때, human preference를 학습하는 일반적인 DPO에서는 verbose bias가 당연히 일어날 수밖에 없는데, self-reward에서는 consistency를 기준으로 training set이 마련되어있으므로 verbose bias에서 자유로워진 것 아닐까...

구매완료