GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints (EMNLP 2023)
Background
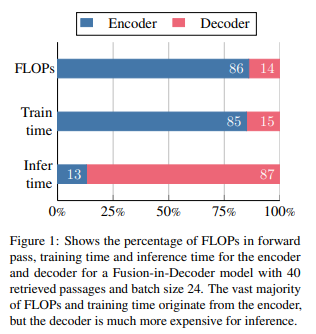
- decoder의 inference speed는 굉장히 떨어지므로, (FiDO, ACL Findings 2023) 이를 해결하기 위한 approach들이 제안되고 있음: 핵심 문제는 key & value cache라고 판단
- 이전 token의 key를 저장하고 있어야 다음 토큰을 생성할 수 있는데, generating sequence가 길어지면 cache가 점점 커짐

- what is caching?
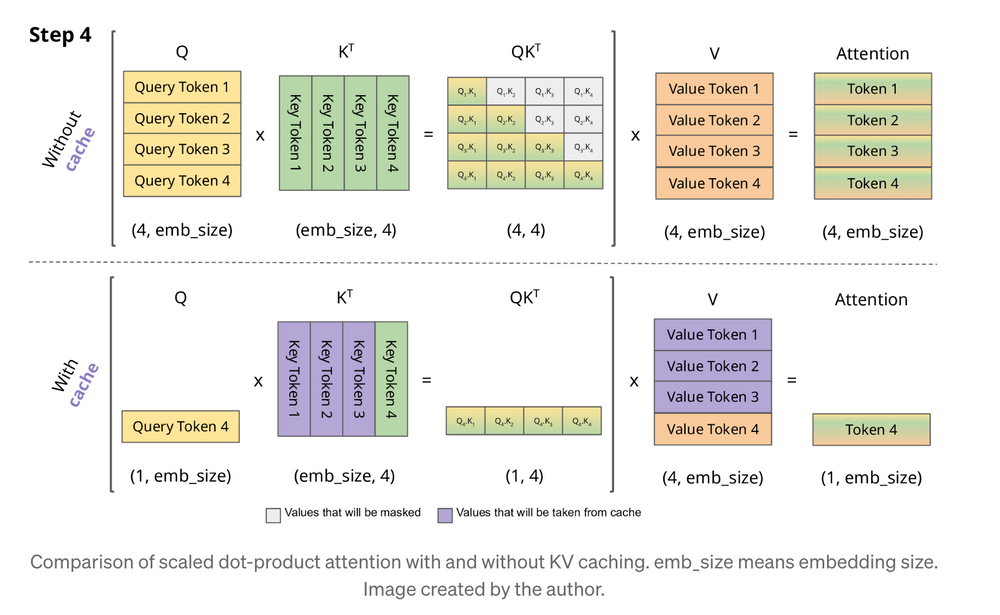
- 이전의 현재 step의 output token을 계산하기 위해 "원래는" 이전 token들의 attention을 다시 계산해야 함 (상단 figure의 query token 4의 attention을 계산하기 위해 query token 1, 2, 3의 attention을 계산하는 것)
- 하지만 key token 1, 2, 3과 value token 1, 2, 3을 저장해놨다면 반복되는 계산을 줄일 수 있고, k & v의 값을 저장함으로써 목표 token의 계산을 빠르게 하는 것이 caching
- 그러나 효율적 연산을 목표로 도입된 caching이 오히려 더 많은 메모리를 잡아먹는 대참사 발생 (아래 figure 참조)
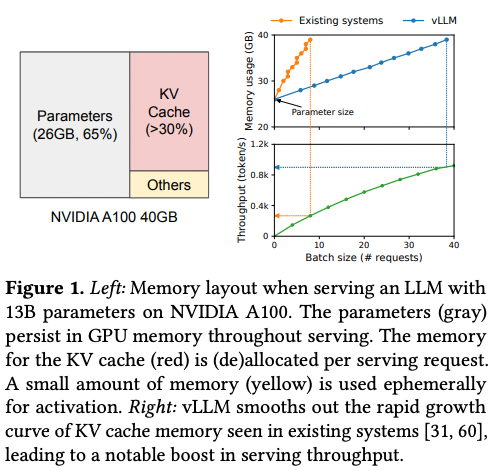
- 이전 token의 key를 저장하고 있어야 다음 토큰을 생성할 수 있는데, generating sequence가 길어지면 cache가 점점 커짐
- 이전 연구 Shazeer (2019) 에서는 Multi-Query Attention (MQA) 를 제안해 k, v 의 head를 하나로 통일함으로써 k와 v의 caching을 줄였음
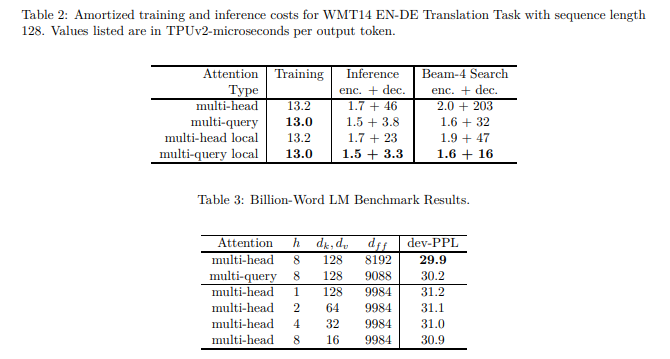
- decoder에서 inference speed가 매우 감소 (46 3.8 하였으나, 성능 하락이 있었음
- Grouped Query Attention (GQA) 는 decoder의 inference speed를 보존하면서 MQA의 성능 하락이라는 단점을 보완하기 위해 제시된 접근법임
Abstract
- single key-value head를 사용하는 MQA는 decoding inference의 속도를 높였음
- MQA의 quality degradation은 단점임
- (1) MQA를 이용한 uptraining 방법을 제시하여 원래의 pretraining computing 자원의 5%만 사용하는 방안
- (2) Grouped Query Attention (GQA) 를 제시함: MQA의 generalization으로, query head와 1개 사이의 중간 지점의 head를 key와 value의 head로 이용
- GQA를 uptraining에 이용할 경우, MHA와 quality를 비슷하면서도 속도는 MQA와 비슷한 점을 확인 가능함
Introduction
- autoregressive decoder inference 는 attention key & value 를 매번 load 해야 해서 매우매우 시간이 오래 걸림
- MQA를 이용해서 이를 해결하려 하였으나, quality degradation과 training instability 에서 한계를 보였음
- faster inference를 위해 다음과 같은 방안을 제시함
(1) MHA 로 학습된 checkpoint를 불러와서 MQA로 uptraining 하여 original training computation의 일부만을 사용해 MHA만큼의 quality와 MQA만큼의 inference speed를 확보할 수 있음
(2) grouped-query attention을 제시하여 MHA와 quality는 비슷하나 MQA만큼의 속도를 확보
Mehtod
Uptraining
MHA 모델에서 MQA 모델을 만드는 것은 다음과 같음: checkpoint를 convert additional pretraining을 진행해 새로운 structure에 적응시키는 것
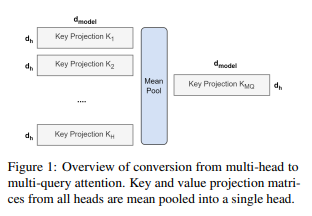
- Checkpoint Conversion: key, value projection matrices를 mean pooling해 single projection matrix로 만듦
- original projection matrices에서 random selection하는 것이나, key, value head를 initialize해서 처음부터 학습하는 것보다 효과적이었다고 함
- additional pretraining: original training step의 만큼만 추가로 pretraining (pretraining 시의 training setting과 동일하게 유지)
Grouped-query attention
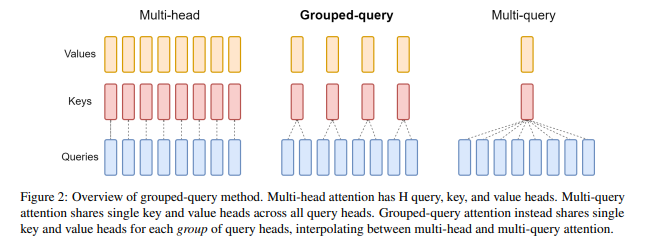
- GQA는 query head를 G개만큼의 group으로 나누고, group 내부에서는 key head와 value head를 공유한다는 점이 MHA와의 차이점임
- 따라서 group의 개수가 query head의 개수와 같다면 MHA와 완전히 동일
- group의 개수가 1개라면 MQA와 완전히 동일
- MHA checkpoint를 GQA checkpoint로 변경할 때, original key & value head를 group마다 mean pooling 하여 GQA의 group key & value head로 convert할 수 있음
Experiments
Experimental Setup
Configurations
- T5 large & T5 XXL 사용, Adafactor optimizer 사용 (hyperparameter는 original T5 학습과 같음)
- encoder self-attention에는 GQA를 사용하지 않았음
Uptraining
- key &value head는 mean-pooling으로 계산
- pretraining의 비율 는 0.05로 설정
Data
- evaluation dataset임
- summarization dataset (CNN/Daily Mail, arXiv, PubMed, MediaSum, Multi-News), translation dataset (WMT 2014 En-De), QA (TriviaQA) 사용 사용
- GLUE가 널리 쓰이는 벤치마크이기는 한데, autoregressive inference에는 부적절해서 제외하였음
Fine-tuning
- lr 0.001, batch size 128, dropout rate 0.1
- CNN/Daily Mail, WMT dataset은 input length 512, output length 256
- 다른 summ dataset은 input length 2048, output length 512로 설정
- Trivia QA는 input length 2048, output length 32로 설정
- greedy decoding 사용
Main Results
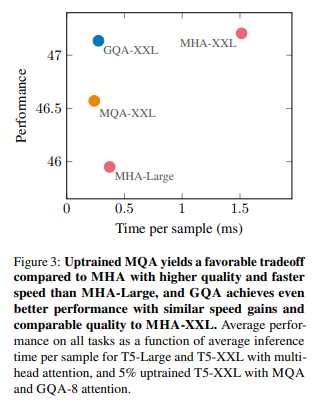
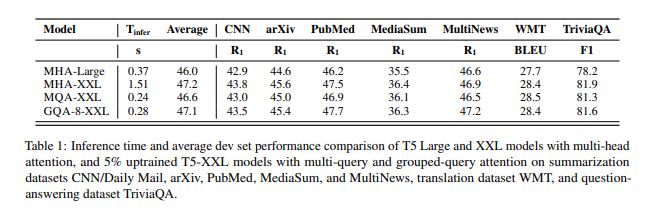
- MQA, GQA 모두 uptraining (), group은 8로 설정
- MQA-XXL에 비해 높은 quality gain (MHA-XXL과 필적), MHA-XXL과 비교해 높은 inference speed (MQA-XXL과 필적)
Ablations
Checkpoint Conversion

- MHA에서 GQA로 변환할 때, 각 group에 해당하는 head의 initialization을 어떻게 할지에 대한 실험
- group에 해당하는 original MHA head 중 하나를 random하는 것, first head를 선택하는 것보다 mean pooling이 낫다는 점을 보임
Uptraining Steps

- GQA는 head conversion이 이루어진 직후에도 상대적으로 높은 성능을 기록
- 0.1까지는 proportion을 높여도 성능 향상이 있지만, 0.1 이후로는 성능 하락이 관찰됐음
Number of groups
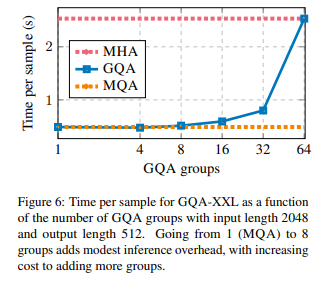
- key & value size는 head의 크기에 크게 영향을 받음
- MQA에서부터 head의 크기를 증가시키면 처음에는 time cost가 크게 늘어나지 않으나, MHA에 가까워질수록 가파르게 time cost가 늘어나는 것을 확인할 수 있음
GQA in Code
- PyTorch 공식 코드는 없음
- MHA와 GQA의 차이점을 query, key, value shape 차이에 집중하여 보면 좋을 것
- MHA는
q, k, v shape: [batch_size, seq_len, head_num, head_dimension] attn_weight shape: [batch_size, num_heads, seq_len, seq_len]- GQA는
q shape: [batch_size, seq_len, head_num (query), head_dimension] k, v shape: [batch_size, seq_len, head_num (key & value), head_dimension] attn_weight shape: [batch_size, query_head_num_per_group, group_num, seq_len, seq_len] query_head_num_per_group x group_num == head_num (query)
MHA (PyTorch)
def scaled_dot_product_attention(query, key, value, attn_mask=None, dropout_p=0.0, is_causal=False, scale=None) -> torch.Tensor:
# L for target sequence length, S for source sequence length -> MHA에서는 seq_len, seq_len
L, S = query.size(-2), key.size(-2)
scale_factor = 1 / math.sqrt(query.size(-1)) if scale is None else scale
attn_bias = torch.zeros(L, S, dtype=query.dtype)
# 미래 token에 대해 mask 씌우는 부분
if is_causal:
assert attn_mask is None
temp_mask = torch.ones(L, S, dtype=torch.bool).tril(diagonal=0)
attn_bias.masked_fill_(temp_mask.logical_not(), float("-inf"))
attn_bias.to(query.dtype)
if attn_mask is not None:
if attn_mask.dtype == torch.bool:
attn_bias.masked_fill_(attn_mask.logical_not(), float("-inf"))
else:
attn_bias += attn_mask
attn_weight = query @ key.transpose(-2, -1) * scale_factor # shape: [batch size, num_heads, seq_len, seq_len]
attn_weight += attn_bias
attn_weight = torch.softmax(attn_weight, dim=-1)
attn_weight = torch.dropout(attn_weight, dropout_p, train=True)
return attn_weight @ value # shape: [batch_size, num_heads, seq_len, head_dim]# [batch_size, seq_len, num_heads, head_dim]
query = torch.randn(1, 256, 8, 64)
key = torch.randn(1, 256, 8, 64)
value = torch.randn(1, 256, 8, 64)
# efficiency를 위해 보통 seq_len과 num_heads의 transpose를 진행
query = query.transpose(-3, -2) # [1, 8, 256, 64]
key = key.transpose(-3, -2)
value = value.transpose(-3, -2)# attention weight 계산
attn_weight = query_tmp @ key_tmp.transpose(-2, -1)
attn_weight.shape # [1, 8, 256, 256] -> [batch_size, num_heads, seq_len, seq_len]# output의 shape은 다시 초기 shape으로 돌아옴
output = attn_weight @ value
output.shape # [1, 8, 256, 64] -> [batch_size, num_heads, seq_len, head_dim]GQA (non-official)
- simplified version of https://github.com/fkodom/grouped-query-attention-pytorch/blob/main/grouped_query_attention_pytorch/attention.py
- 계산의 편의성을 위해 einops 이용
# shapes: (batch_size, seq_len, num_heads, head_dim), 실제로는 efficiency를 위해 num_heads와 seq_len (n, s)을 transpose
query = rearrange(query, "b n h d -> b h n d")
key = rearrange(key, "b s h d -> b h s d")
value = rearrange(value, "b s h d -> b h s d")
bq, hq, nq, dq = query.shape
bk, hk, nk, dk = key.shape
bv, hv, nv, dv = value.shape
# key, query value의 head 개수와 group 당 query head의 개수를 정의
num_head_groups = hq // hk
# query를 key와 value matrices에 맞도록 분할
# h: group 의 개수
# g: group 당 query head의 개수
query = rearrange(query, "b (h g) n d -> b g h n d", g = num_head_groups)
# MHA의 query @ key 에 해당 (attn_weight)
similarity = einsum(query, key, "b g h n d, b h s d -> b g h n s")
# attn_weight @ value 계산
out = einsum(similarity, value, "b g h n s, b h s d -> b g h n d")
# query shape에 맞도록 재조정
out = rearrange(out, "b g h n d -> b n (h g) d")# [batch_size, seq_len, num_heads, head_dim]
query = torch.randn(1, 256, 8, 64)
key = torch.randn(1, 256, 2, 64)
value = torch.randn(1, 256, 2, 64)
# [batch_size, num_heads, seq_len, head_dim] 으로 reshape
query = rearrange(query, "b n h d -> b h n d")
key = rearrange(key, "b s h d -> b h s d")
value = rearrange(value, "b s h d -> b h s d")
bq, hq, nq, dq = query.shape
bk, hk, nk, dk = key.shape
bv, hv, nv, dv = value.shape# key, query value의 head 개수와 group 당 query head의 개수를 정의
num_head_groups = hq // hk # 8 // 2 = 4
# 2는 key와 value의 group 개수, 4는 group 하나에 포함되는 query head의 개수# MHA의 query @ key 에 해당 (attn_weight)
similarity = einsum(query, key, "b g h n d, b h s d -> b g h n s")
similarity.shape
# [1, 4, 2, 256, 256]
# [batch_size, qhead_per_group, group_num, seq_len, seq_len]# attn_weight @ value 계산
out = einsum(similarity, value, "b g h n s, b h s d -> b g h n d")
out.shape
# [1, 4, 2, 256, 64]
# [batch_size, qhead_per_group, group_num, seq_len, head_dim]# query shape에 맞도록 재조정해 다음 module에 들어갈 수 있도록
out = rearrange(out, "b g h n d -> b n (h g) d")
out.shape
# [1, 256, 8, 64]: qhead_per_group, group_num을 합쳐주는 과정
# query의 원래 shape과 일치하는 것을 확인GQA in LLaMA2
- MHA와 GQA 간 호환성을 높인 코드 (repeat_kv를 이용)
def repeat_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor:
"""
This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch,
num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim)
"""
batch, num_key_value_heads, slen, head_dim = hidden_states.shape
if n_rep == 1:
return hidden_states
hidden_states = hidden_states[:, :, None, :, :].expand(batch, num_key_value_heads, n_rep, slen, head_dim)
return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
class LlamaAttention(nn.Module):
"""Multi-headed attention with grouped-query mechanism"""
def __init__(self, config, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = self.hidden_size // self.num_heads
self.num_key_value_heads = config.num_key_value_heads
self.num_key_value_groups = self.num_heads // self.num_key_value_heads
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.is_causal = True
if (self.head_dim * self.num_heads) != self.hidden_size:
raise ValueError(
f"hidden_size must be divisible by num_heads (got `hidden_size`: {self.hidden_size} "
f"and `num_heads`: {self.num_heads})."
)
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.head_dim, bias=config.attention_bias)
self.k_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.v_proj = nn.Linear(self.hidden_size, self.num_key_value_heads * self.head_dim, bias=config.attention_bias)
self.o_proj = nn.Linear(self.hidden_size, self.hidden_size, bias=config.attention_bias)
# rotary_embedding: LLaMA는 매 block마다 position embedding이 들어감
self.rotary_emb = LlamaRotaryEmbedding(config=self.config)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Cache] = None,
output_attentions: bool = False,
use_cache: bool = False,
cache_position: Optional[torch.LongTensor] = None,
position_embeddings: Optional[Tuple[torch.Tensor, torch.Tensor]] = None,
**kwargs,
) -> Tuple[torch.Tensor, Optional[torch.Tensor], Optional[Tuple[torch.Tensor]]]:
bsz, q_len, _ = hidden_states.size()
# 아래 projection을 거치면 [batch_size, seq_len, hidden_dim] -> [batch_size, seq_len, num_heads * head_dim]으로 proj
query_states = self.q_proj(hidden_states) # hidden dimmension -> num_heads * head_dim 으로 proj
key_states = self.k_proj(hidden_states) # hidden_size -> kv_heads * head_dim 으로 proj
value_states = self.v_proj(hidden_states) # hidden_size -> kv_heads * head_dim 으로 proj
# [batch, head_num x head_dimension, seq_length]를
# [batch, head_num, seq_length, head_dimension]으로 변환
# t 후 [batch, head_num, seq_len, head_dimension]이 됨
query_states = query_states.view(bsz, q_len, self.num_heads, self.head_dim).transpose(1, 2)
key_states = key_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
value_states = value_states.view(bsz, q_len, self.num_key_value_heads, self.head_dim).transpose(1, 2)
if position_embeddings is None:
cos, sin = self.rotary_emb(value_states, position_ids)
else:
cos, sin = position_embeddings
query_states, key_states = apply_rotary_pos_emb(query_states, key_states, cos, sin)
if past_key_value is not None:
cache_kwargs = {"sin": sin, "cos": cos, "cache_position": cache_position}
key_states, value_states = past_key_value.update(key_states, value_states, self.layer_idx, cache_kwargs)
# group의 개수만큼 k와 v를 repeat: (1) 위의 einops를 피하면서 효율적으로 계산 (2) MHA를 사용하는 경우에도 호환 가능
key_states = repeat_kv(key_states, self.num_key_value_groups)
value_states = repeat_kv(value_states, self.num_key_value_groups)
# query_state (더 많은 head 개수) 와 key (더 적은 head 개수를 갖고 있으나 repeat으로 복사) 의 attn_weight 계산
# query_state: [batch, head_num, seq_len, head_dimension] x key_states.t: [batch, head_num, seq_len, head_dimension]
# attn_weights.shape: [batch_size, headnum, seq_len, seq_len]
attn_weights = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
if attention_mask is not None:
causal_mask = attention_mask[:, :, :, : key_states.shape[-2]]
attn_weights = attn_weights + causal_mask
attn_weights = nn.functional.softmax(attn_weights, dim=-1, dtype=torch.float32).to(query_states.dtype)
attn_weights = nn.functional.dropout(attn_weights, p=self.attention_dropout, training=self.training)
# attn_weights: [batch, head_num, seq_len, seq_len] x value_states: [batch, head_num (위에서 repeat), seq_len, head_dim]
# attn_output.shape: [batch, head_num, seq_len, head_dim]
attn_output = torch.matmul(attn_weights, value_states)
# attn_output.shape: [batch, seq_len, head_num, head_dim]
attn_output = attn_output.transpose(1, 2).contiguous()
# 다시 hidden_dim으로 reshape: [batch, seq_len, hidden_dim]
attn_output = attn_output.reshape(bsz, q_len, -1)
attn_output = self.o_proj(attn_output)
if not output_attentions:
attn_weights = None
return attn_output, attn_weights, past_key_value
multidisciplinary