[LLM study] 5. Instruction Tuning
from "A Survey of Large Langauge Models (2024)"
Where are We now?
LLM의 학습은 3단계로 이루어짐: (1) Pretraining (2) Instruction Tuning (3) Alignment Tuning
- Pretraining: LLM이 기초적인 language understanding & generation skill을 학습할 수 있음
- Instruction Tuning: task 및 goal에 도달하기 위한 finetuning
'instruction': '양파는 어떤 식물 부위인가요? 그리고 고구마는 뿌리인가요?',
'input': None
'output': '양파는 잎이 아닌 식물의 줄기 부분입니다. 고구마는 식물의 뿌리 부분입니다. \n\n식물의 부위의 구분에 대해 궁금해하는 분이라면 분명 이 질문에 대한 답을 찾고 있을 것입니다. 양파는 잎이 아닌 줄기 부분입니다. 고구마는 다른 질문과 답변에서 언급된 것과 같이 뿌리 부분입니다. 따라서, 양파는 식물의 줄기 부분이 되고, 고구마는 식물의 뿌리 부분입니다.\n\n 덧붙이는 답변: 고구마 줄기도 볶아먹을 수 있나요? \n\n고구마 줄기도 식용으로 볶아먹을 수 있습니다. 하지만 줄기 뿐만 아니라, 잎, 씨, 뿌리까지 모든 부위가 식용으로 활용되기도 합니다. 다만, 한국에서는 일반적으로 뿌리 부분인 고구마를 주로 먹습니다.',from KoAlpaca
- Alignment Tuning: human values & preference에 학습 (RLHF)
- instruction tuning 이란 무엇인가?
- LLM을 formatted instances에 finetuning하는 것
- supervised finetuning이나 multi-task prompted training과 유사하다고 볼 수 있음
- 왜 하나? unseen task에 대한 generalization ability를 획득하기 때문
Formatted Instance Construction
instruction의 다양성과 질이 가장 중요하며, instance의 개수는 상대적으로 중요도가 떨어짐
단, 고품질의 데이터가 부족할 경우 양으로 커버 가능
- instruction-formatted instance의 구성
- task description (a.k.a. instruction)
- input (optional)
- output
- demonstrations (optional)
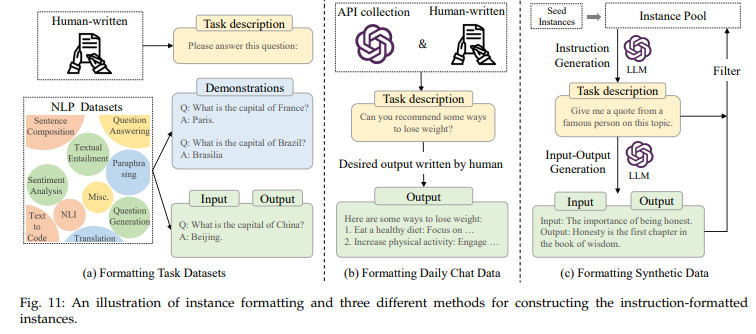
- Formatting NLP Task Datasets
- 전통적인 NLP task (요약, 분류, 번역 등) 에 task description을 붙여서 (human-written도 가능) instruction tuning dataset을 구축
- task description이 없으면 성능이 떨어진다는 것을 발견
- datasets: PromptSource
Example (SuperNI)
FT할 LLM의 Input으로 {Description} + {Input} 이 들어가고, Output을 예측하도록 학습됨 (Explanation은 optional)Description (Instruction): "You will be given a piece of text either about an everyday event, or a general statement. If the event seems a plausible event to you, or the general statement makes sense matches your commonsense, output 'True', otherwise output 'False'."
Input: "The glass fell of a three-story building, so it broke into pieces."
Output: "True"
Explanation (Optional): "Falling down from a considerable height causes glasses to break, so this is a true sentence."
- Formatting Daily Chat Data (InstructGPT)
- task instruction: 실제 유저들이 사용한 query를 task instruction으로 넣음 + brainstorming 등 task에는 human labeler가 description을 작성하기도
- output: 사람이 직접 작성
- ChatGPT의 경우, 위험한 query에는 답변을 거부하도록 QA pair를 작성하여 safety concern을 instruction tuning 단계에서 줄였음
- datasets: ShareGPT, Dolly, OpenAssistant
Example (Dolly v2)
category: brainstorming
Instruction (Description): Why mobile is bad for human?
Input (context): None
Output (response): We are always engaged one phone which is not good.
- Formatting Synthetic Data
- 사람이 직접 만드는 것이 아니라, 이미 존재하는 LM의 도움을 받아 dataset을 구성
- effective & economical, but too simple & lack of diversity
- approaches: Self-Instruct, Evolve-Instruct (WizardLM), Self-Align
- Key Factors for Instance Construction
- scaling
- task와 instruction의 특성 (길이, 난이도) 을 다양화해야
- 소수의 잘 짜여진 dataset으로도 instruction tuning이 충분하다는 연구도 있고 (LIMA: 1k instruction tuning dataset)
- 다수의 데이터가 무조건 좋다는 연구도 있음 (Orca: 3M 규모의 instruction tuning dataset)
- formatting design
- task instruction 외에 demonstration을 더할 수 있음
- 예시를 같이 제공할 수도 있음 (demonstration의 대체)
- CoT를 instruction dataset 안에 포함하는 것도 가능: CoT가 필요한 task와 필요없는 task 모두에서 성능 향상 있었음
- 이외 기피사항, 이유, 제안 등을 추가하는 것은 상대적으로 미미한 영향
- scaling
Instruction Tuning Strategies
pretraining 단계보다는 strategy나 hyperparameter에 신경을 덜 써도 되겠음
단, training 시 data curriculum에 신경을 써야
- Balancing the Data Distribution
- 다양한 task가 있으므로 data distribution에 신경 써야
- examples-proportional mixing strategy: 전체 데이터셋에서 instance를 고르게 뽑아서 학습시키는 것
- 단, 고품질 데이터의 비중을 높이면 성능 향상이 있다고 함
- 상기한 NLp task data, chat data, synthetic data를 모두 조화롭게 사용해야 model capability의 전반적인 상승이 있고, 한 종류만 사용하면 성능 향상이 제한적
- Combining Instruction Tuning and Pre-Training
- pretraining 시 사용했던 데이터를 일부 섞어 regularization을 진행하기도
- 일부 모델 (Galactica, GLM-130B) 은 pretraining 때 pretraining data와 instruction tuning data를 모두 학습시켜 2단계를 하나로 통합하기도 하였음
- multi-stage Instruction Tuning
- 첫 단계에서는 large-scale task-formatted instruction에 대해 학습
- 두 번째 단계에서 small-scale chat-style instruction에 학습 (task-formatted instruction data를 일부 섞어서 학습)
- 난이도, 복잡성에 따라 위와 같이 scheduling할 수도 있음
The Effect of Instruction Tuning
- Performance Improvement
- Task Generalization
- unseen task에 대해서도 결과물 도출 가능
- repetitive generation & simple completion of input 등 LLM의 단점을 보완 가능
- multilingual 환경에서도 task solving 능력을 보유
- Domain Specialization
- pretraining 단계에서는 domain-specific data의 학습이 적기 때문에 instruction tuning 단계에서 domain knowledge를 추가로 학습할 수 있음
