RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback (2023)
Summary
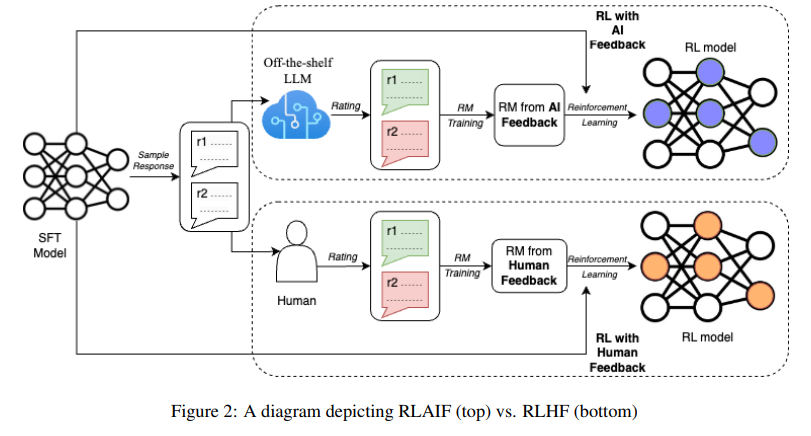
Reinforcement Learning from Human Feedback (RLHF) 의 장점과 한계
- 장점: 이전의 supervised fine-tuning (SFT) 로 적용이 힘들었던 human preference에 LM을 aligning하는 게 가능해짐 (Stiennon et al., NeurIPS 2020; Ouyang et al., NeurIPS 2022)
- ChatGPT, Bard 등 LLM 개발에 핵심적인 역할을 함
- 한계: RLHF를 하기 위해서는 고품질의 human preference label이 필요함
Previous Studies
- 이전 연구 (ConstitutionalAI, 2022) 의 경우, RLHF에서 human feedback 대신 AI feedback으로 바꾸면서 conversational model을 구축할 때 RLAIF를 사용하는 것의 가능성을 보여줌
- 그러나 RLAIF와 RLHF 와의 직접 비교가 없다는 것이 가장 큰 한계
Experiments
- 3개의 text eneration task (summarization, helpful dialogue generation, harmless dialogue generation) 에서 RLAIF와 RLHF를 비교
- 결과
- SFT보다 RLHF, RLAIF를 선호하는 것을 확인
- RLAIF와 RLHF의 차이는 통계적으로 유의미하지 않았으며, 유사한 win rate을 보임
- 그러나, harmlessness dialogue generation에서는 RLAIF가 RLHF를 outperform 하였음
- 따라서, RLAIF는 RLHF의 대안이 될 수 있겠음: human annotation이 필요없으면서도, 데이터셋의 크기를 키울 수 있음
Ablation Study
- RLAIF의 RM을 키웠을 때, 성능이 개선될 수 있었음
- AI의 feedback을 이용해 RM을 학습하는 (distilled RLAIF) 방법 말고, AI의 feedback을 직접 강화학습의 보상점수에 사용하는 방안 (direct RLAIF) 에서 SFT를 outperform
- human preference에 더 잘 align할 수 있는 technique 제시: CoT는 항상 좋았고, detailed preamble & FS prompting은 성능 향상이 제한적이었음
Contributions
- RLAIF가 summarization, helpful dialogue generation, harmless dialogue generation에서 RLHF와 유사하거나 더 높은 성능을 기록
- LLM을 직접 prompting 하여 reward score를 뽑아내 RL하는 것이 LLM preference를 학습한 RM을 사용하는 것보다 나음
- AI label 생성 테크닉과 RLAIF를 위한 optimal setting을 제시
Methodology
Preference Labeling with LLMs


- prompt 구성
- preamble: instroduction, instruction of task
- few-shot exemplars (optional): input context example, responses pair, CoT raionale (optional), preference label
- sample to annotate: input context, pair of responses
- ending: ending text to prompt LLM (e.g. "Preferred Response=")
- preference 구하는 과정
- response pair 중 어떤 것 ('1' or '2') 을 고를지, token 의 log probability를 구하고 softmax를 취해 preference distribution을 계산
- free-text format을 generate하는 것보다 straightforward 하기에 선택
Addressing Position Bias
- position bias (선택지의 순서가 바뀌어도 앞/뒤 선택지 중 하나를 일관되게 선택하는 bias) 가 발견됨
- 따라서 하나의 response pair 마다 순서를 바꿔서 2번씩 테스트했고, inference result (token probability) 를 average 해서 final preference distribution을 구함
Chain-of-Thought Reasoning
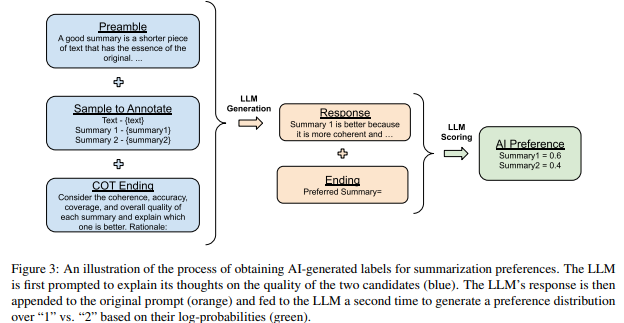
- (step 1)
Preferred Summary=로 끝나는 ending을 thought & explanation을 제시하도록 바꿈 (e.g.Consider the coherence, accuracy, coverage, and overall quality of each summary and explain which one is better. Rationale:) - (step 2) 바뀐 ending에서 decode한 결과물 (response) 를 원래의 ending (
Preferred Summary=) 로 바꾼 뒤 AI preference 추출


- 각각 ZS, 1-shot CoT prompting 예시
Reinforcement Learning from AI Feedback
Distilled RLAIF
-
token probability (e.g.
[0.6, 0.4]) 에 cross entropy loss 를 적용해서 RM을 학습 -
기존의 방법과 같고, distillation의 아이디어와 일맥상통
-
RM의 학습 과정 (REINFORCE, PPO의 변형)
- , 는 SFT model
- 위를 이용해 를 구성
- RM 는 아래 loss를 minimize하도록 학습
- 좋은 출력 () 에 대해 높은 보상을, 낮은 출력 () 에 대해 낮은 보상을 주도록 학습
- RL의 식:
- 은 SFT의 weight이고, RL로 학습하고자 하는 parameter
- RL 식은 (1) 보상 최대화 (2) penalty term으로 이루어짐
- (1) 보상 최대화 (): RM이 계산한 보상을 최대화하여 높은 reward를 받는 출력을 생성하도록 유도
- (2) penalty term (): KL은 RL 과정에서 SFT policy에서 답이 너무 멀어지지 않도록 하는 penalty term (reward hacking을 피함)
-
예시
"A를 70%, B를 30% 선호한다"->[0.7, 0.3]을 RM이 학습 -> 다른 response pair가 들어왔을 때 RM이 보상점수[2.5, 1.0]를 도출 ->[0.82, 0.18]로 변환 (softmax) -> RL으로 학습
Direct RLAIF
- LLM의 preference를 RM에 학습시키는 것이 아니고, 바로 RL의 reward signal로 사용하는 것
- 과정
- 점수를 1-10 사이로 내도록 prompting
- 1-10 점수의 token generation probability를 계산
- token probability distribution을 이용해 weighted score 를 계산
- [-1, 1] 사이로 정규화:
- 예시
- LLM output
"A는 8점, B는 4점"->[0.67, 0.33]로 변환 (softmax) -> RL으로 학습
- LLM output
Evaluation
- metrics: AI Labeler Alignment, Win Rate, Harmless Rate
- AI Labeler Alignment
- probability 로 표현 되었던 representation (soft AI preference matrix) 을 binary representation으로 바꾸고 ((e.g.
[0.6, 0.4] -> [1, 0]), human preference와 일치하면 1을, 일치하지 않으면 0을 부여 - alignment accuracy
- : preference dataset size
- : soft AI preference matrix
- : human preference vector ([0, 1, 1, 0, 0, ...] 로 표현: 0번째 답변을 선호하는지, 1번째 답변을 선호하는지 기재)
- : 선호하는 답변의 j-th index
- probability 로 표현 되었던 representation (soft AI preference matrix) 을 binary representation으로 바꾸고 ((e.g.
- Win Rate
- 2개의 policy에 대해 human annotator가 더 선호하는 쪽 선택
- Harmless Rate
- response 중 human evaluator에게 harmless하다고 여겨진 비율
Experimental Details
Datasets
- summarization: Reddit TL;DL
- helpful dialogue generation: OpenAI's Human Preferences (Reddit TL;DL dataset에서 response pair와 human preference를 추가한 데이터)
- harmless dialogue generation: Anthropic Helpful and Harmless Human Preferences (human annotator가 label한 preferred & non-preferred responses pair dataset)
LLM Labeling
- 속도를 위해 preference dataset을 downsampling하여 사용: high confidence (1, 2, 8, 9) 를 가진 examples (task 당 3-4k 가량) 만 사용
- LLM labeling preference에 PaLM2 사용: instruction tuning은 되었지만 RL은 진행되지 않음
Model Training
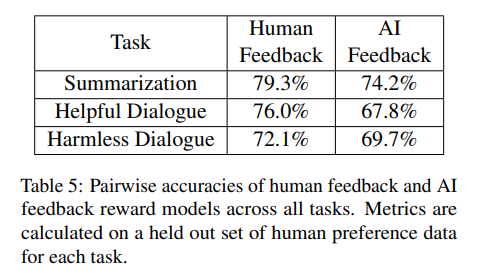
- SFT 모델은 PaLM 2 XS 를 사용
- RM 또한 PaLM 2 XS를 이용하였으며, RLAIF 모델에 사용된 RM 의 정확도는 아래와 같음
Human Evaluation
- RLAIF, RLHF, SFT의 output을 ranking하도록 human evaluation을 진행
- ranking에서 각 policy에 대한 win rate을 계산
Results
RLAIF vs RLHF
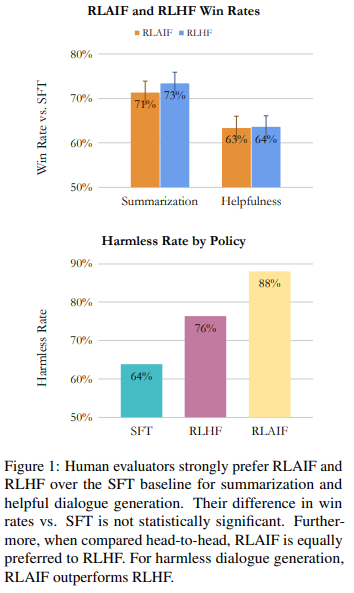
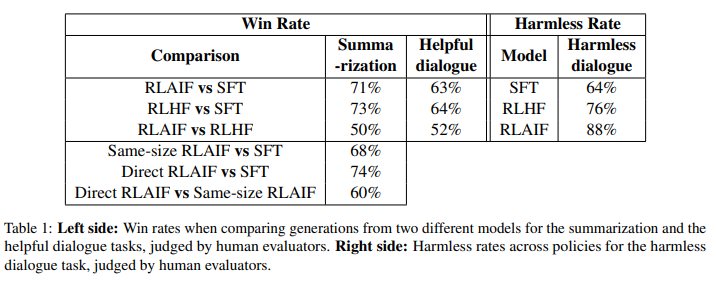
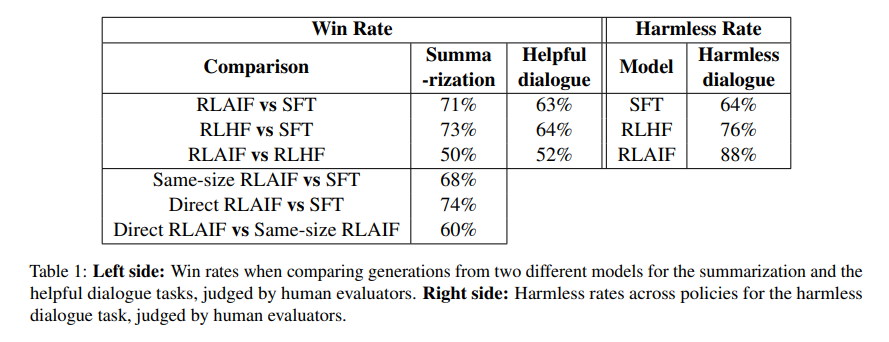
- RLAIF는 3개 task (summarization, helful dialogue generation, harmless dialogue generation) 모두에 대해 RLHF와 유사한 성능
- SFT에 비해 RLHF와 RLAIF 모두 outperform
- summarization과 helpful dialogue에서는 RLHF와 RLAIF의 유의미한 차이가 없음
- harmless dialogue에서는 RLAIF가 RLHF를 outperform (88% vs 76%)

- RLAIF와 RLHF는 SFT보다 더 긴 summary를 생성하며, win rate에 영향을 미쳤을 수 있음
- 다만, character length를 160자 정도로 제한해도 win rate이 높았다고 함 (Appendix J)
- 따라서, RLAIF는 RLHF의 대안이 될 수 있겠음
Direct RLAIF
- 앞에서는 AI Feedback을 RM에 학습하였으나, PaLM 2XS (instruction-tuned) 를 reward model로 바로 사용
- Direct RLAIF (no RM) 은 RM 을 학습한 뒤 적용한 RLAIF 를 outperform (60%)
- distillation 과정에서 정보가 누락될 수 있는데, off-the-shelf LLM을 prompt engineering으로 바로 RM으로 사용함으로써 정보 손실이 없어졌다는 것이 추정
Prompting Techniques
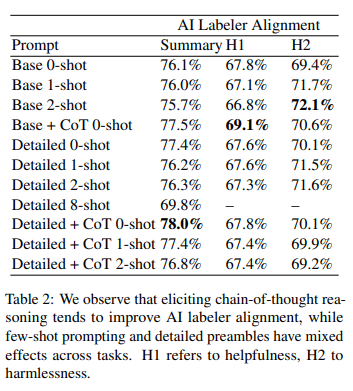
- preamble specificity, CoT reasoning, ICL (FS)
- CoT가 전반적으로 alignment 능력을 향상시킴
- preamble specificity & ICL은 task마다 효과가 다양함
- preamble specificity: summarization에서는 좋지만, helpful & harmless에서는 복합적인 결과, summarization에서는 상세한 지시가 좋다는 가정
- ICL (FS): 이미 잘 하는 task이기 때문에 distracted되었다는 추정이 있음
Size of LLM Labeler
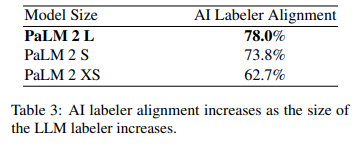
- LLM size와 alignment 사이에 강한 관계가 있음
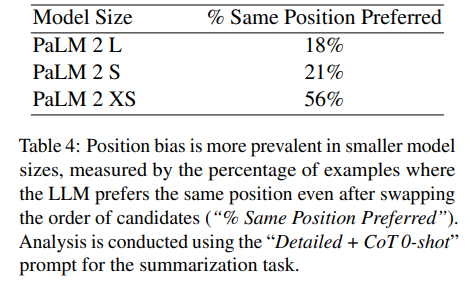
- general capability 외에도 sLLM에서는 position bias가있음
Qualitative Observations

- RLHF, RLAIF 모두 비슷한 output을 내뱉도록 이용되지만, 차이점이 몇 가지 있었음: (1) hallucinations & (2) less coherent & gramatical summary
Conclusion & Limitations
- 이전 연구에서는 RLHF 대신 RLAIF를 사용하려는 시도가 있었으나, RLHF와 RLAIF의 직접적인 비교가 부재하였음
- 본 연구에서는 RLHF와 RLAIF의 실험 결과를 비교하고, 그 둘의 성능이 유의미한 차이가 없었음을 확인하였음
- 따라서, RLHF의 대안으로 RLAIF가 제시될 수 있겠음
limitations & future works
- 한정된 데이터와 한정된 모델: ICLR 2024 reject 의 가장 큰 이유
- RM 없는 alignment tuning의 가능성 제시 (with DPO)

multidisciplinary
좋은 논문 소개해주셔서 감사합니다~! 항상 RLHF에 대해서 어려웠었는데, LLM과 연관지어서 설명해주시니 쉽게 이해되었습니다!!