Learning Transferable Visual Models From Natural Language Supervision (ICML, 2021)
0. Contribution
- NLP에서의 pretraining idea를 CV에 적극 도입하였음
- pretraining하기 위한 대규모의 web-scraped dataset
- CV에 NLP를 더한 pretraining이 task-specific model보다 더 나은 성능을 낼 수 있음을 보임
1. Motivations
1.1 Why Pretraining?
- NLP에서의 pretraining 굉장히 성공적: BERT, GPT etc.
- 대조적으로, CV에서 NLP와 pretraining을 엮은 시도는 20세기 말부터 있긴 했지만, 성과가 좋다고 말할 수는 없었음(Li et al., 2017)

Learning Visual N-Grams from Web Data
YFCC100M dataset에 대해 user comment-img를 묶어서 n-gram(uni, bi, tri, four, five on dictionary) 단위로 학습시킴
- pretraining이 필요한 이유: data의 문제, zero-shot transfer가 가능해지므로
data의 문제: task-specific dataset 구축 비용 너무 큼
zero-shot transfer: 효율성의 문제
1.2 New Dataset
- 이전 dataset의 문제
보통 3가지 dataset을 사용: MS-COCO, VIsual Genome, YFCC100M
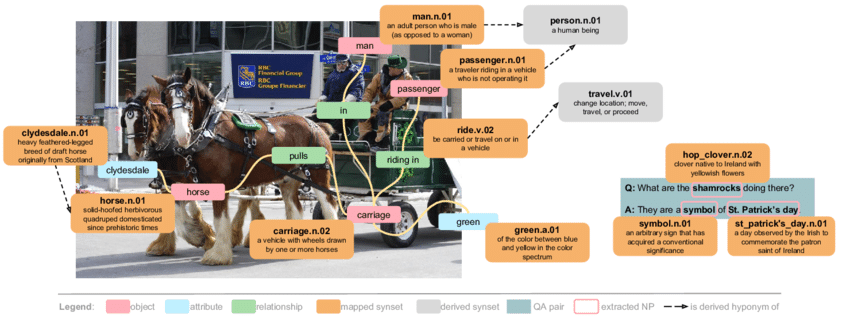
위 사진은 VIsual Genome dataset sample. VIsual Genome은 video의 object detection에 쓰이고, MS-COCO나 YFCC100M은 비슷한 image classification dataset임
MS-COCO, VIsual Genome: high quality crowd-labeled dataset(비싸다), 100,000 규모(작다)
YFCC100M: metadata 아주 조악, 해석 가능한 text가 있는 img로 줄이면 100mln에서 15mln으로 축소(ImageNet과 비슷), 결국 scale 작음
- 그래서 새로운 dataset 구축: WebImageText (WIT)
(img, raw text)의 쌍으로 훈련할 수 있도록 dataset 구축. 인터넷에서 싹싹 긁어모아서 400mln pair 구성. text의 종류(query)는 500k, 각 query마다 최대 20k image 들어가게끔

query list는 english Wikipedia에서 적어도 100번 이상 등장하는 모든 단어이며, 일정 분량 이상 되는 문서의 제목 및 high pointwise mutual information(PMI) for the pair와의 i-grams로 augmentation됨
기존 dataset과 최대한 안 겹치게 하려고 했고, 35개 dataset을 대상으로 비교한 결과, 9개 dataset은 아예 공통 data 없고, 나머지의 median overlap 2.2%, average overlap 3.2%에 불과하였으므로 안심하시라
2. Approach
- objective 첫 시도: predictive ojective, 너무 비쌈
처음에는, VirTex처럼 image CNN을 text transformer와 함께 처음부터 학습시켜서 image caption prediction을 objective로 가져가려고 했음. 그런데 data 크기를 키우니까 문제가 발생: ResNet50 image encoder보다 parameter가 2배(63 mln) 많아서 2016년에 같은 text로 BoW로 했던 모델보다 이미 3배 느림
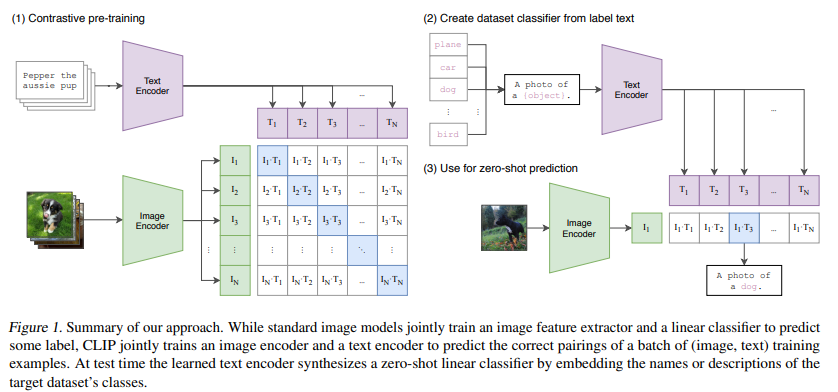
- objective 두 번째 시도: contrastive learning
text의 한 단어가 아니라 text 전체 덩어리가 어떤 img와 묶일지에 대해 학습하게 됨. predictive objective와 비교해서 ImageNet에 zero-shot transfer했을 때 4배 efficiency
N batch의 (image, text) pair가 주어졌을 때, CLIP은 N × N possible pairing 중에서 실제 pair를 predict하도록 훈련됨. 이 궁극적인 목적을 위해서, CLIP은 text embedding과 image embedding의 cosine similarity를 N개의 정답에 대해서는 maximize, N-N개의 오답에 대해서는 minimize하도록 학습됨. similarity score에 대해 symmetric cross entropy loss 사용
contrastive learning이 다른 모듈을 사용하고 그런 줄 알았는데, loss를 잘 쓰면 되는듯?
- image encoder: ResNet50, Vision Transformer(ViT)를 각각 사용해봄.
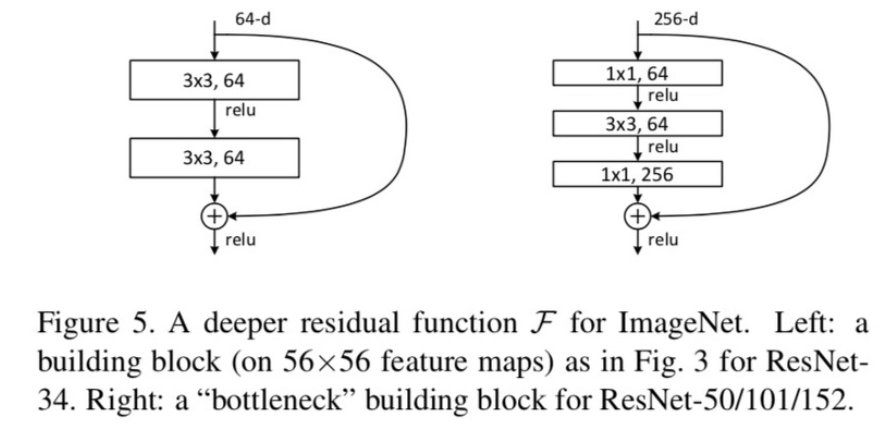
ResNet50(He et al., 2016): 위(오른쪽)와 같은 residual bock(bottle-neck architecture)이 몇 개씩 직렬연결돼서 layer가 50개가 되는 model
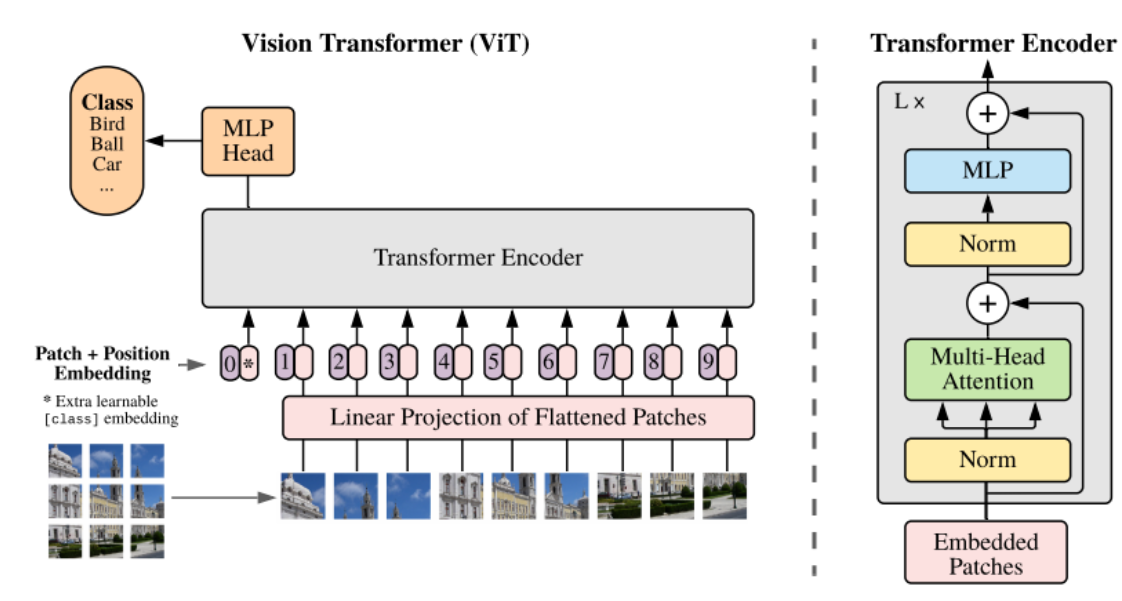
Visual Transformer: CNN을 사용하지 않고, patch로 나눠 self attention 준 것. attention 주기 전에 class token concat, position embeding을 더해줌(모두 learnable)
-
text encoder: transformer(12 layer, 8 heads) 사용, tokenizing은 lower-cased BPE, 양 끝에 [SOS], [EOS] token 박았음. 가장 마지막 layer의 [EOS]가 feature representation임(BERT의 [CLS] token 생각하면 될 듯)
-
여러 가지 ResNet, ViT 사용했는데, 가장 좋은 게 ViT-L/14였다고 하며, 이를 CLIP의 표준모델로 삼음
3. Analysis
3.1 Initial Comparison to Visual N-Grams
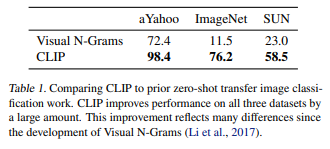
- 2016년 Visual N-Grams의 zero-shot과 비교했을 때 큰 발전
Visual N-Grams가 처음으로 비슷한 방법을 통해 zero-shot transfer 시도하였음. ImageNet의 경우, 11.5%에서 76.2%로 상승했는데, ResNet50의 결과와 비슷한 수준(ResNet50은 1.28mln crowd-labeled data 사용). 그래서 CLIP을 이거하고 비교하였음. 이전의 zero-shot transfer 모델에서의 큰 발전임
3.2 Zero-Shot Performance
- zero-shot?
보통은 훈련과정에서 등장하지 않은 object category에 대한 classification으로 정의(generalization)할 수 있으나, 여기에서는 좀 더 넓혀서 훈련과정에 있지 않은 dataset에 대한 일반화로 정의하였음
본 연구진은 zero-shot transfer를 task learning capability로써 사용하였음. task learning이 잘 되면 zero-shot도 잘 된다는 거겠지?
- CLIP(zero-shot) vs ResNet50
일단 baseline을 ResNet50으로 사용해서, 27개 dataset에 대해서 그 결과를 비교: 27개 dataset 중 16개 dataset은 baseline보다 더 높음
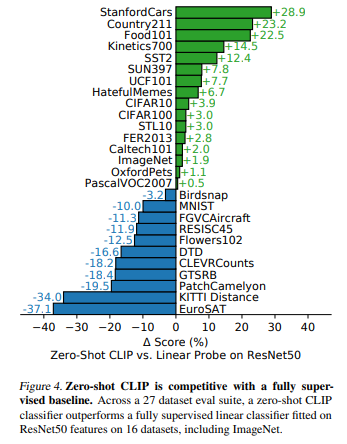
- CLIP zero-shot: outperform
특히, STL10은 ResNet50보다 약 30%p가량(내 추측임..) 높아서 99.3% accuracy 기록. 이건 내 추정인데, figure 4가 잘못된 것 같음. STL10이 +3.0이라 되어있는데, 실제로는 +30인 것 같음. https://deep-learning-study.tistory.com/534 등을 확인하면 ResNet50은 STL10에 대해 60%대 후반-70% 정도의 accuracy를 기록하였음. STL10은 CIFAR10이랑 비슷한데, labeled된 case가 더 적어서 unsupervised learning을 좀 더 겨냥한 dataset임
Stanford Cars, Food101에서는 CLIP이 ResNet50에 비해 약 20%p 가량 더 높은 결과

ImageNet, CIFAR10, PascalVOC2007(위 sample)같은 general한 object classification에서는 CLIP이 조금이나마 더 나은 모습

Kinetics700(위 sample), UCF101은 video인데, 여기에서 CLIP은 ResNet50보다 각 14.5%p, 7.7%p outperform: NL 도입해서 verb도 사용한 게 ImageNet에서의 noun 중심 학습보다 나았던 결과이지 않을까 추정
- CLIP zero-shot: underperform
Flower102, FGVCAircraft에서는 CLIP이 10%p 가량 underperform: WIT(본 연구의 데이터셋)과 ImageNet의 훈련 빈도 차이로 추정(너무 specific함)
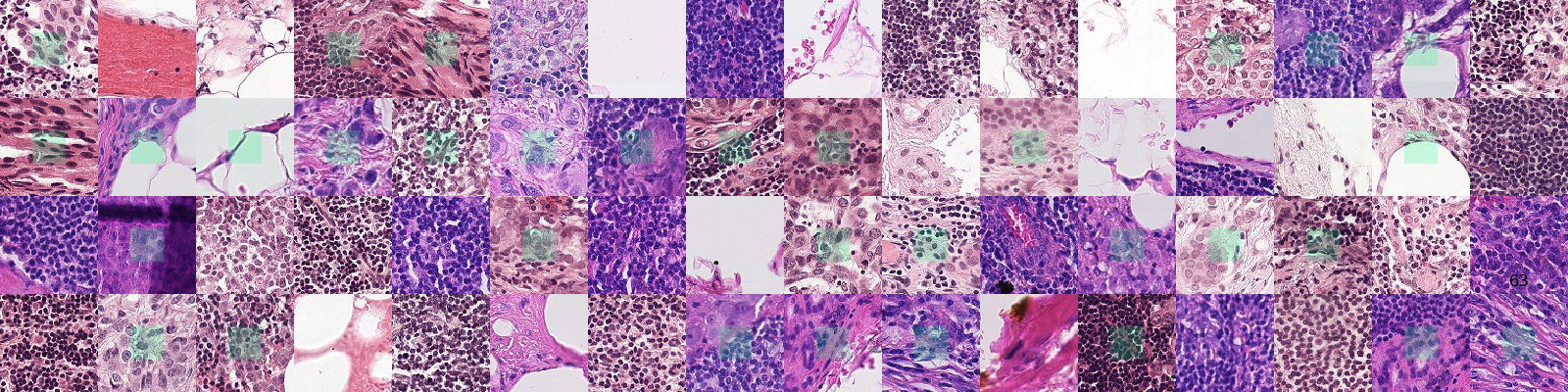
반면, specialized, complex, abstract task에서는 CLIP이 underperform: EuroSAT, RESISC45(satelite image), PatchCamelyon(lymph node tumor detection, 위 sample사진), CLEVRCounts(counting objects in synthetic scenes), GTSRB(traffic sign recognition), KITTI Distance(distance to the nearest car). 이런 부분에 있어서는 개선 필요하긴 한데, 이런 complex하고 abstract한 task에서 zero-shot learning이 few-shot learning보다 유의미할지는 미지수라는 평
- CLIP(few-shot) vs few-shot models
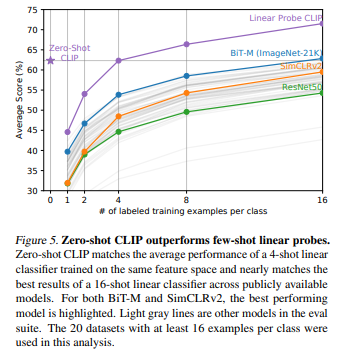
zero-shot CLIP의 성능이 4-shot CLIP과 비슷한 이유: img 하나에서도 여러 가지 concept 뽑아낼 수 있기 때문에 shot 적을수록 모델이 이상한 쪽으로 발전할 가능성이 큼
zero-shot CLIP의 성능은 ImageNet-21K에서 학습한 BiT-M의 16-shot과 비슷
3.3 Representation Learning
representation learning의 성능을 확인하기 위해 linear probe evaluation protocol 사용
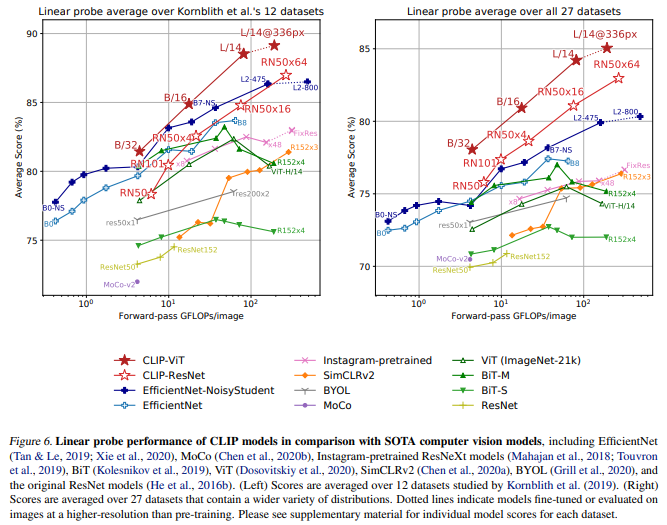
Kornblith et al. (2019)의 12개 datset 평균에 대해서는, ResNet을 사용한 CLIP이 SoTA 모델을 근소하게나마 outperform하고, ViT을 사용한 CLIP은 확실하게 outperform하면서도 ResNet-CLIP에 비해 더 efficient함
위 dataset은 character recognition, facial emotion recogniton, action recognition, geo-localization 등이 부족하기 때문에 그를 보완한 27개 dataset에 대해 evaluation한 결과, 모든 CLIP 모델이 다른 모델들을 outperform함
3.4 Robustness to Natural Distribution Shift

내맘대로 Conclusion
-
transformer가 등장하고 나서 NLP+img multimodal system이 많이 발전할 수 있었음을 확인할 수 있었음
-
장점: img에 text 달아준 거 좀 신박하다(PMI?), predictive objective가 안 되면 contrastive objective로 바꿀 수 있구나!
-
단점: figure4 잘못되어 있는 것 같아(STL10)! 그리고 masking(text, image)이 원래 코드에는 들어가있는데, 이거에 대한 효과같은 것을 언급하지 않아 아쉬웠음

-
생각해볼 만한 점: celebA dataset(위 sample)을 예로 들면서 privacy에 더 많은 침해가 가해질 수도 있다는 것.. 이는 GPT도 마찬가지의 진통을 겪고 있으며, pretrained model의 양면이라고 생각
-
Misc: dataset contribution 부럽다.. 근데 CV dataset 왜이렇게 많음..?
Misc
Italian CLIP(+BERT)
https://towardsdatascience.com/how-to-train-your-clip-45a451dcd303
https://github.com/clip-italian/clip-italian/tree/master/hybrid_clip
https://huggingface.co/spaces/clip-italian/clip-italian-demo
Korean CLIP
https://github.com/jaketae/koclip

4개의 댓글


- CLIP은 open AI에서 개발하면서 유명한 논문인데, 쉽게 설명해주셔서 감사합니다~ 이미지 분야에서 zero shot 모델 개발하는 과정을 알 수 있어서 좋았습니다. 모델 개발과 동시에 발생할 수 있는 우려점도 같이 언급해 주셔서 새로운 insight를 얻을 수 있었습니다~
- 배경지식이 부족해서 중간중간 놓치는 부분이 있었는데 다음번에 그런것도 설명해주시면 더 좋을 것 같습니다~ 쿄쿄쿄

재밌어요 ! 앞으로도 많은 활동 부탁드립니다