Legal Search in Case Law and Statute Law (JURIX, 2019)
Frontiers of Artificial Intelligence and Applications(FAIA)의 International Conference on Legal Knowledge-based Systems(JURIX)임. IF는 검색해도 안 나옴
가져갈 message
- 뭐 대단한 걸 바란 건 아니고, 생짜 BERT를 어떻게 legal-IR에다가 써먹었는지 보려고 한 거라 써먹을 것은 별로 없음
- legal-IR에서 BERT 실제로 어떻게 사용했는가(specific application) with library names
- evaluation metrics
1. Introduction
https://doras.dcu.ie/22806/에서 지적한 것과 같이, legal document collections는 professional knowledge가 필요한 수준이 일반 collection과는 궤를 달리함. 그래서 limited & specialzied될 수밖에 없고, narrow field(lease contracts, financial products, court decision 등)만을 cover할 수밖에 없음.
본 연구에서는 generalized LM이 legal information task handling에 적합한지를 보고 그 한계를 논할 것임. legal document에서 공통적으로 등장하는 specific feature(긴 문장들, 일상적으로 사용되는 단어와 추상적인 concept의 혼합, relevance의 모호한 정의 등)가 부정적으로 작용하는 것을 확인했음
본 연구진은 Legal Information Retrieval을 pairwise relevance score problem으로 치환하여 generalized LM의 finetuning으로 해결하고자 하였음. 긴 문장은 summarizing으로 해결
rq1 summary encoding을 long documents의 dense representation으로 사용할 수 있는가?
rq2 LM의 pretraining과 finetuning을 legal language 학습에 사용할 수 있는가?
2. Methods
본 연구진은 ranking problem을 pairwise relevance classification problem으로 재구성하였음. query case와 candidate case의 pair에서 candidate case가 relevant한지, irrelevant한지 classify. 각 query에 대해 query & candidate pair가 positive인지 probability를 계산하고 probability(score)에 따라 ranking함
2.1. Pairwise Embeddings
[CLS] token의 embedding 사용
2.2. Fine-Tuning of Pre-Trained Language Model
fc layer 얹어서 true classification 수행, loss는 Cross Entropy
2.3. In-Domain Additional Pre-Training of Language Model
legal language는 unusual vocabulary(rare words, latin words etc), semantic(casual meaning과 legal meaning이 다름), syntactic feature 등에서 casual language와는 다름
그래서 본 연구진은 legal domain text에 대해 pretraining 더 진행함(?)
2.4 Summarization of Long Documents
extractive summarization using TextRank, word limit은 180 words로 해서 wordpiece tokenizer 적용해도 512 tokens 넘지 않도록 하였음
3. Legal Retrieval Tasks
COLIEE2019 dataset 사용
3.1. Case Law Retrieval
case law == common law인데 좀 다르게 쓰인듯?
- dataset from Federal Court of Canada case law
- each query has 200 potential supporting(candidate) cases, 285 query cases
3.2. Statute Law Retrieval
- dataset from Japanese Civil Code, from Japanese Bar Exams
- training dataset 651 queries & test dataset 69 queries
- querie in short snippet(avg. 40 words max. 120 words)
- law articles avg 60 words, 98% under 200 words
3.3. Evaluation Metrics
- 원래 COLIEE에서는 F1, F2 score를 사용하나, 여기서는 다르게 사용할 것임
- end user를 판사 오피스의 staff로 가정하고, query case를 software에 넣었을 때 return되는 ranked list의 "Precision at R, P@R(R은 totla num. of relevant documents)", "Recall and Precision at k, R@k, P@k"와 "Mean Average Precision(MAP)" 사용(이 때 macro average 사용)
4. Case Law Retrieval
4.1. Experimental Setup
case를 summarize해서 (query text, candidate text, relevance judgement)의 triplet으로 만들고, BERT finetuning(binary classification) 진행, relevance judgement가 relevance label 되겠음(namely FineTuned)
또한, in-domain pre-training하고, 여기에 fine-tuning도 진행(namely PreTrained). entire corpus of court decisions(18,000 documents, 45mln tokens)를 pre-training으로 사용
4.2 Baselines
BM25 2개: 하나는 full text로 pairwise 비교, 하나는 summary로 pairwise 비교
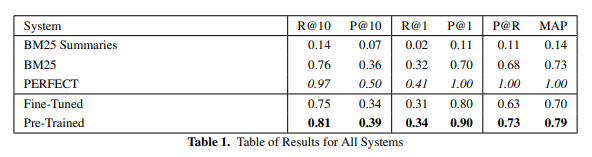
4.3. Results and Analysis
5. Statute Law Retrieval
생략. COLIEE2018 task 2 SoTA model(UB3)보다 FineTuned가 나았음
