KAT: A Knowledge Augmented Transformer for Vision-and-Language (NAACL, 2022)
추가사항
- result figure의 KAT (ensemble) 이 무엇인지?
- KAT 모듈의 cross attention 설명 (코드 뜯어봐야 함)
- implicit knowledge extraction 단에서 image captioning model (OSCAR, ECCV 2020) 설명 달아놓기
Contribution
- knowledge extraction
- external knowledge extraction: knowledge graph, knowledge bases etc.
- extracted knowledge의 quality와 relevance를 높이는 method
implicit knowledge: GPT-3에서 잠정적인(tentative) answers & supporting evidence
explicit knowledge: contrastive learning method (CLIP)
- external knowledge extraction: knowledge graph, knowledge bases etc.
- reasoning in an encoder-decoder transformer
- OK-VQA benchmark에서 SoTA 갱신
Abstract
- 이전(~2022) 연구들의 reasoning 방향성: 모델에 information 최대한 잘(optimized, heavy amount) 쑤셔넣기
- 이번 연구의 방향성
- multimodal transformers가 explicit knowledge를 reasoning에 사용할 수 있을까?
- reasoning process에서 implicit & explicit knowledge를 어떻게 잘 합칠 수 있을까?
- Knowledge Augmented Transformer (KAT) 제안
- open domain multimodal task of OK-VQA에서 +6% 성능 향상 기록해 SoTA 갈아치움
- KAT의 구조
- knowledge extraction -> encoding -> reasoning module -> decoder module -> answer
- both knowledge sources(implicit, explicit)를 reasoning(answer generation) 할 때 사용
- implicit & explicit knowledge를 encoder-decoder architecture에서 integrate함
- explicit knowledge integration은 interpretability of model prediction의 향상에 기여하였음
1 Introduction
background

- "모델 키울 만큼 키웠다! 아무리 pretrained LM을 키워도 정확도 측면에서는 떨어지는 부분 있다!"
- 정확한 답이 필요한 분야, 전문학술분야 etc 에서는 external knowledge가 필요할 수밖에 없음
- autonomous AI agent같은 real-world applications에서 implicit knowledge (a.k.a. "commonsense") 와 explicit knowledge (e.g. from Wikipedia) 를 integrate해야 하는 필요성이 다대함
- 본 연구에서는 위와 같은 implicit + explicit knowledge integration 상황 (reasoning) 에서 어떻게 효과적으로 integrate할 수 있을지 제시 (via OK-VQA dataset)
- multimodal에서의 implicit knowledge와 explicit knowledge의 linkage: image content (implicity) + abstract explicit knowledge
기존 연구
- 기존 연구의 흐름: external knowledge source에서 external knowledge를 retrieve -> image content와 jointly reasoning -> predict answer
- 기존 연구의 한계
- image tag나 question에서 keywords 추출해서 external knowledge base에서 retrieve하면 too generic explicit knowlege: knowledge reasoning 단에서 noise나 irrelevant knowledge가 개입됨
- external knowledge가 대부분 encyclopedia articles나 knowledge graph: knowledge-based QA에는 부족함
- KAT 모델 제안: effectively integrates explicit knowledge and implicit knowledge
2 Related Works
Vision-Language Transformer
- pretrained models
VisualBERT, Unicoder-VL, NICE, VL-BERT: single-stream architecture for image & text
ViLBERT, LXMERT: two-stream architecture to process images and text independently & fuse in later stage
-> 위와 같은 implicitly learned knowledge는 knowledge-based questions에 부적합
- contrastive learning: no labeled images needed
CLIP, ALIGN aligns visual and language represenation by contrastive learning
Knowledge-based VQA
knowledge graphs, unstructured knowledge bases, neural-symbolic inference based knowledge 등
이후에 pretrained LM 사용되기도
PICa (AAAI, 2022)
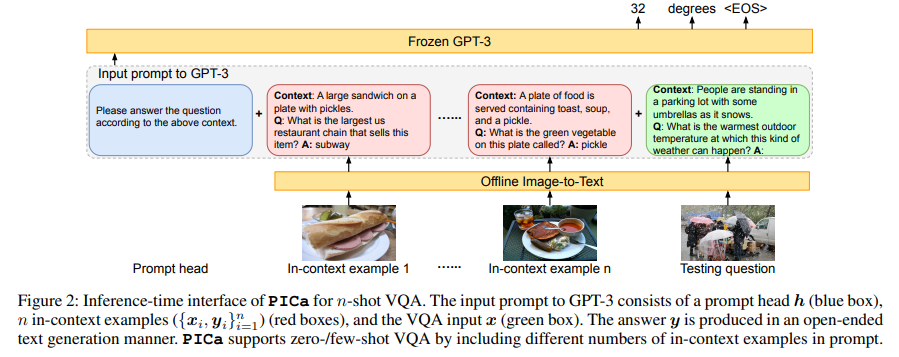
- GPT-3를 사용하자는 아이디어는 이 논문에서 차용
- PICa 논문과 본 논문은 방향이 다른데, PICa는 GPT-3를 이용해 few (zero)-shot VQA가 가능한지를 연구한 것이 방향의 차이 (본 연구는 OK-VQA의 성능 향상을 위해 encoder-decoder 구조 사용)
Vis-DPR (EMNLP, 2021)
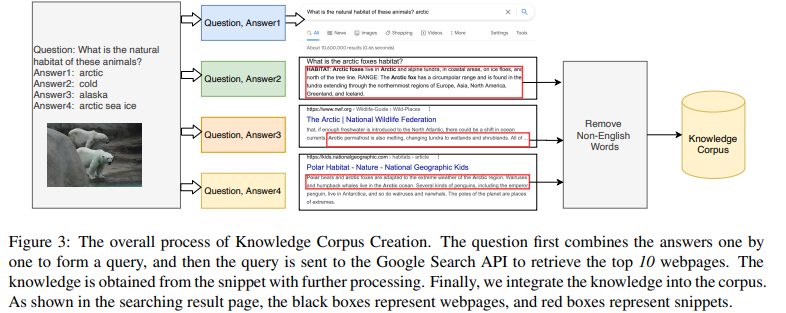
- external knowledge 사용하는 방식은 여기에서 많이 차용했다고 함
- Vis-DPR의 knowledge corpus는 training set의 keyword 내지 문장을 google search api 이용해 구축하였다는 점에서 본 논문과 차이 있음
3 Method
3.1 Problem Formulation
- apply KAT on OK-VQA
- training dataset
: i-th training image
: i-th question
: i-th corresponding answer
: model
: parameters of model
- training dataset
- KAT is basically encoder-decoder model
- 기존 모델이 OK-VQA task를 prediction으로 바꾸어 진행하였으나, 본 논문은 input으로 와 를 받아 answer 를 auto-regressively generate
- notation: 'entity == entry'
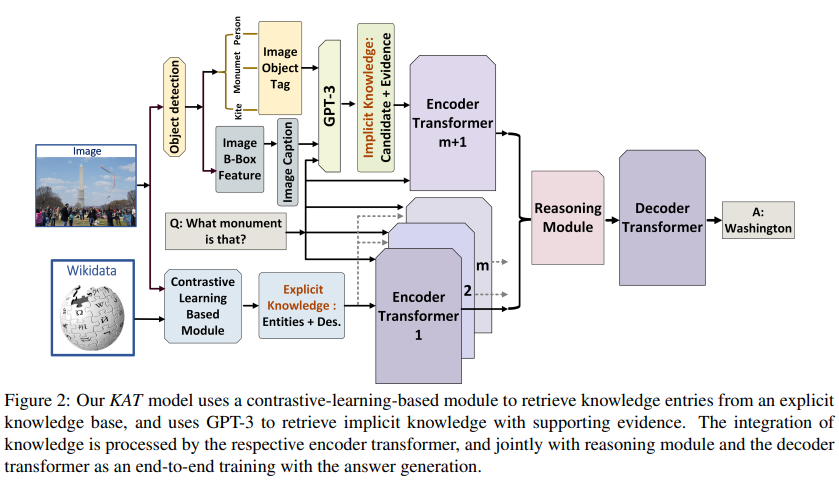
3.2 Explicit Knowledge Retrieval
3.2.2 Knowledge Base Construction
- English Wikidata from Sep. 20, 2021 사용했고, 이것저것 거르다보니 423,520개의 entity만 남음
example entity structure:<Q2813 (label), Coca-Cola (alias), carbonated brown colored soft drink (description)>
3.2.1 Explicit Knowledge Extration
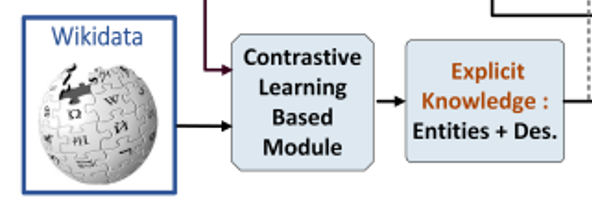

-
이 단에서는 image를 보고 fine-grained description을 생성
-
기존 연구에서는 object detectors 사용해 image tags 생성: too generic & limited vocabulary -> noise & irrelevant knowledge
-
본 연구에서는 대신 CLIP 사용했음 (CLIP, https://velog.io/@zvezda/Learning-Transferable-Visual-Models-From-Natural-Language-Supervision-ICML-2021)
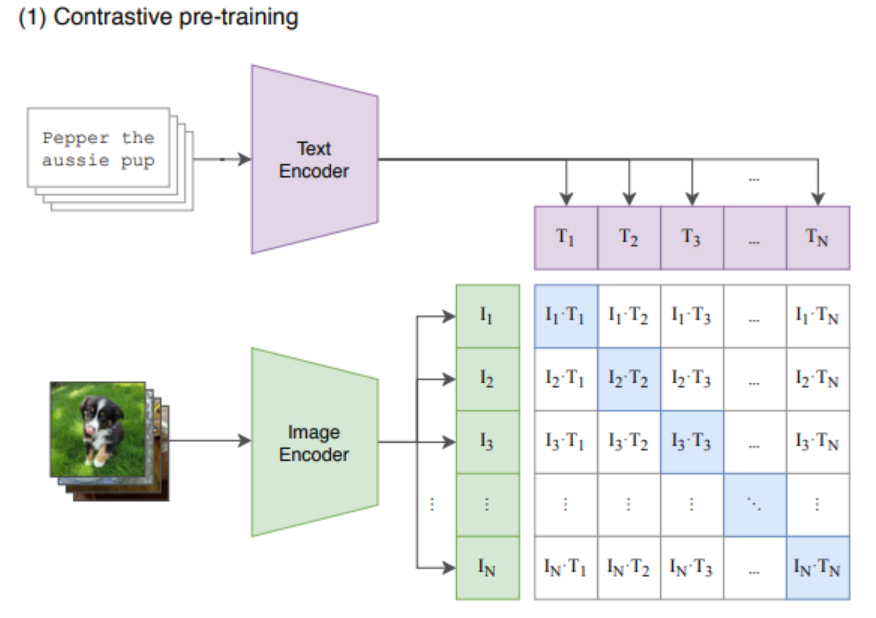
- 기존에는 (image, label)로 학습: label의 정보가 너무 적음
- CLIP은 (image, text)로 학습: image에 대한 label이 없으므로
- N개의 image와 N개의 text를 공통 space로 보내고, positive pair(N개)의 유사도를 최대화, negative pair(N^2 - N)의 유사도는 최소화하도록 학습
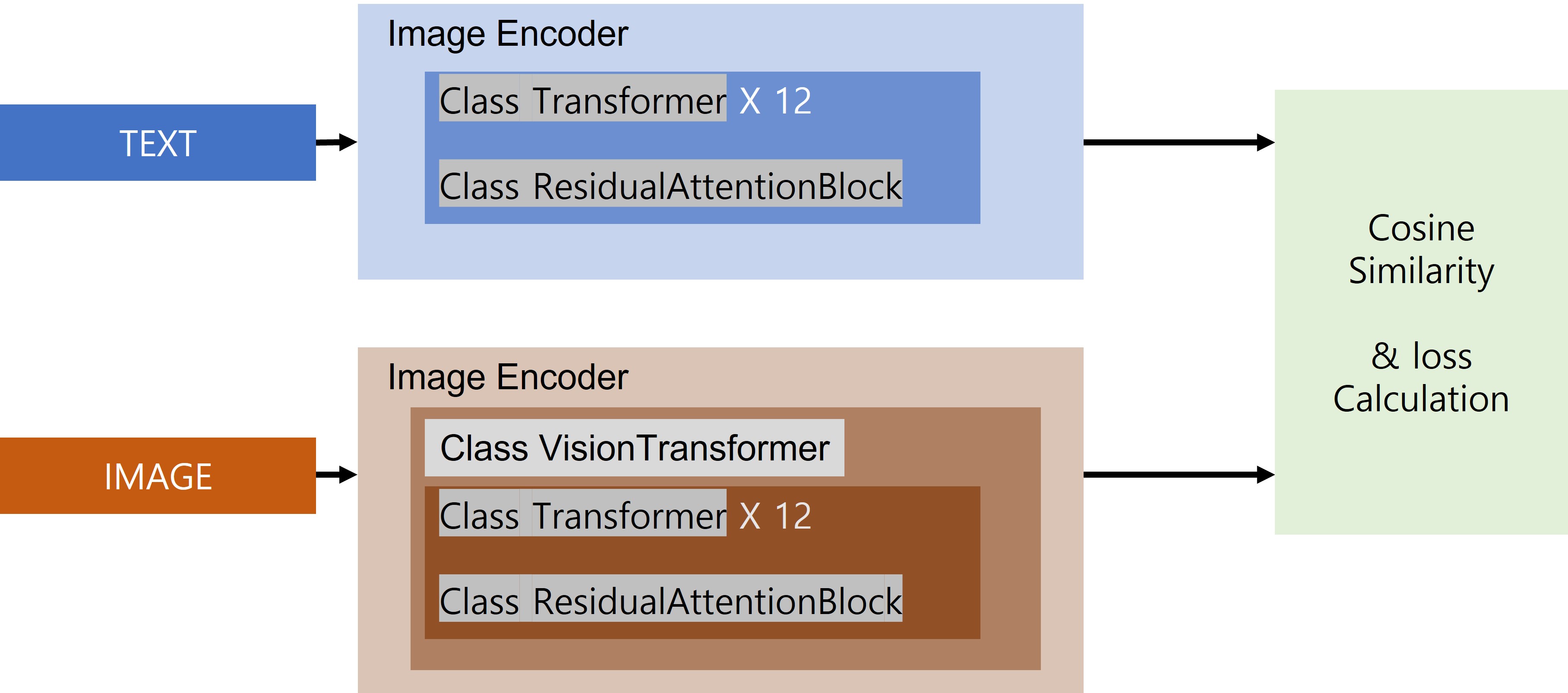

-
Wikidata 이용해서 explicit knowledge base () 구축하고, each knowledge entry () 를 로부터 구축:
e = concat[entity; description] -
explicit knowledge retriever 는 각 input image에 대해 top m knowledge entries를 retrieve함
-
image는 ViT 이용해서 개만큼의 patch로 나누고 encoding 진행 ()
-
각 patch마다 explicit knowledge entry를 k개만큼 retrieve함
similarity score: (simple inner product) -
최종적으로 image 한 개 ()당 retrieve 되는 explicit knowledge는 개 만큼의 explicit knowledge가 나오는데, 여기에서 top m개만큼의 knowledge entry를 keep함
-
여기에서는 CLIP 사용했고, [CLS] token을 representation으로 사용
-
explicit knowledge의 similarity calculation에 FAISS가 사용됨
example explicit knowledge:
{'id': 'COCO_val2014_000000297147.jpg#2971475',
'question': 'What sport can you use this for?',
'entities': [('Benelli Adiva', 'motor scooter model'),
('Yamaha TMAX', 'scooter'),
('mofa', 'moped with a maximum speed of 20 to 25 km/h'),
('motorcycle based vehicle',
'motor vehicle with two or more wheels, based on cycle technology'),
('sport bike',
'motorcycle designed for sporty riding regardless of other characteristics'),
('motorcycle development rider',
'person who for their profession participates in tests to develop a motorcycle'),
('Bravo', 'Piaggio moped'),
('Suzuki X-90', 'motor vehicle'),
('Polaris Industries',
'Designs, engineers and manufactures powersports vehicles'),
('Monark', 'Bicycle, moped and motorcycle manufacturer'),
('Lifan Group', 'Chinese motorcycle and automobile manufacturer'),
('Atala Green', 'Moped produced by Atala'),
('motorcycle', 'two- or three-wheeled motor vehicle'),
('Dual-sport motorcycle', 'Motorcycle type'),
('Honda Jade', 'motor vehicle'),
('Piaggio LEADER', 'Motorcycle engine produced by Piaggio'),
('Suzuki SV1000', 'sport bike'),
('Honda Zoomer', 'motorcycle'),
('Scarabeo', 'scooter model produced by Aprilia'),
('motorcycle personal protective equipment',
'personal protective equipment for use when riding a motorcycle'),
('motorcycle sport', 'sporting aspects of motorcycling'),
('Honda SFX50', 'Honda motorcycle (moped)'),
('motorcycle saddle', 'the seat of a motorcycle'),
('electric trike', 'An electric trike used for transporting goods'),
('Blood bike',
'motorcycle used to courier emergency medical items between hospitals and other healthcare facilities'),
('motorcycle rider',
'person who for their profession or a hobby participates in competitions with a motorcycle'),
('clip-on', 'Type of handle of a motorcycle'),
('Benelli G2', 'Moped produced by italian company Benelli')]}3.3 Implicit Knowledge Retrieval
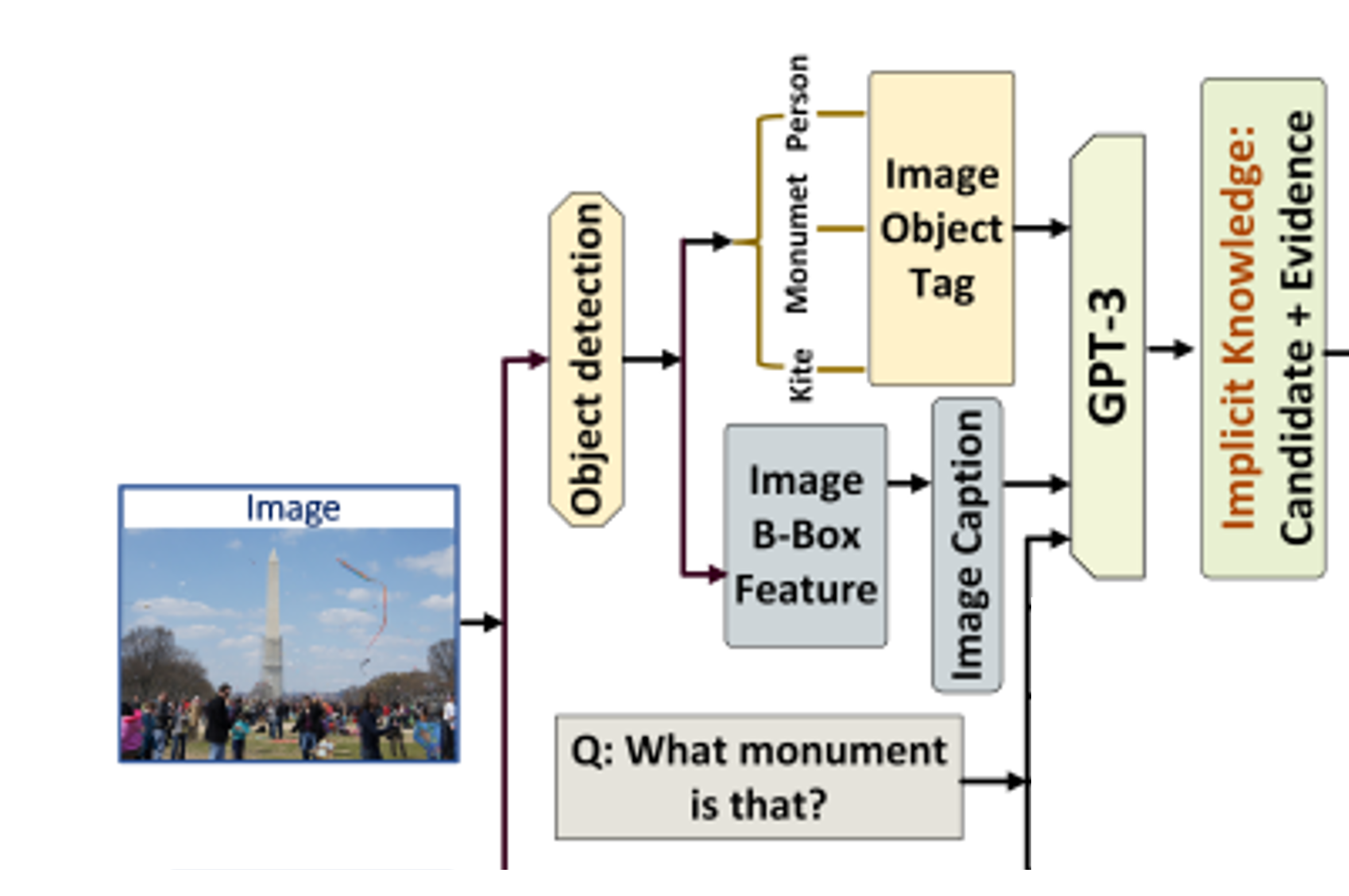
- explicit knowledge retriever는 image regions & knowledge entries의 semantic matching에 중점을 두었다면, implicit knowledge retriever는 'commonsense'에 중점
- common sense는 large-scale LM에 저장되어 있다는 점에 착안, prompting 사용해 supporting evidence까지 끌어냈음
answer candidate

- 먼저, image captioning model (OSCAR, ECCV 2020을 사용해 image 를 textual description 로 변환
- GPT-3에 넣을 'general instruction sentence', 'textual description ', 'question', 'context-qeustion answer triplets'을 이용해 prompt 구성
- 이 prompt를 GPT-3에 넣어 잠정적인 (tentative) answer candidate 만듦
supporting evidence

- 다른 query 만들어 GPT-3에서 supporting evidence 이끌어냄
- "question ? answer . This is because" 형식으로 query (prompt) 넣어 GPT-3로부터 supporting evidence를 끌어냄
- answer와 supporting evidence 모두 사용
example implicit knowledge (GPT-3):
{'id': 'COCO_val2014_000000297147.jpg#2971475',
'index': 0,
'question': 'question: What sport can you use this for?',
'target': 'race </s>',
'passages': ['title: Benelli Adiva context: Benelli Adiva is a motor scooter model']}3.4 KAT model
- (1) image & (2) explicit knowledge sources 이용해 explicit knowledge 뽑아오고,
- (3) question & (1) image 이용해 implicit knowledge 뽑아왔음
- 그런데 explicit knowledge가 (3) question과 관련 없을 지도 모르고, implicit knowledge의 supporting evidence가 too generic 또는 image와 less related 우려
- encoder 써서 explicit, implicit knowledge encoding 해서 reasoning에 사용
Encoder: question-knowledge pair
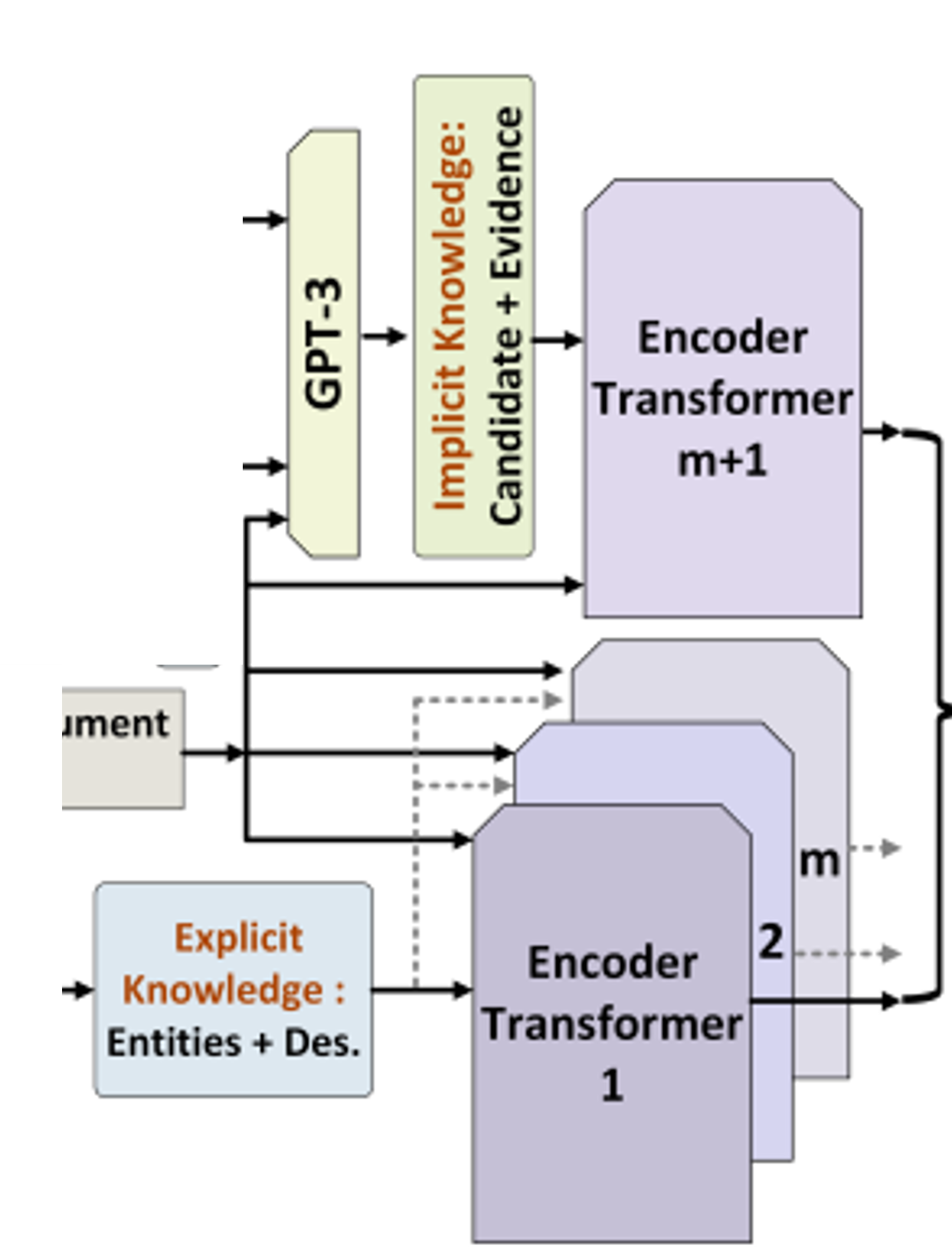
- explicit knowledge 가공 -> embedding & encoding layers
와 explicit knowledge를 concat with sentinel tokens:question: q_i, entity: e, desciption: d-> - implicit knowledge 가공 & 위와 비슷하게 concat with sentinel tokens
question: q_i, candidate answer: can_a, evidence: evid-> - for embedding dimension, for number of explicit knowledge, for implicit knowledge
Reasoning Module
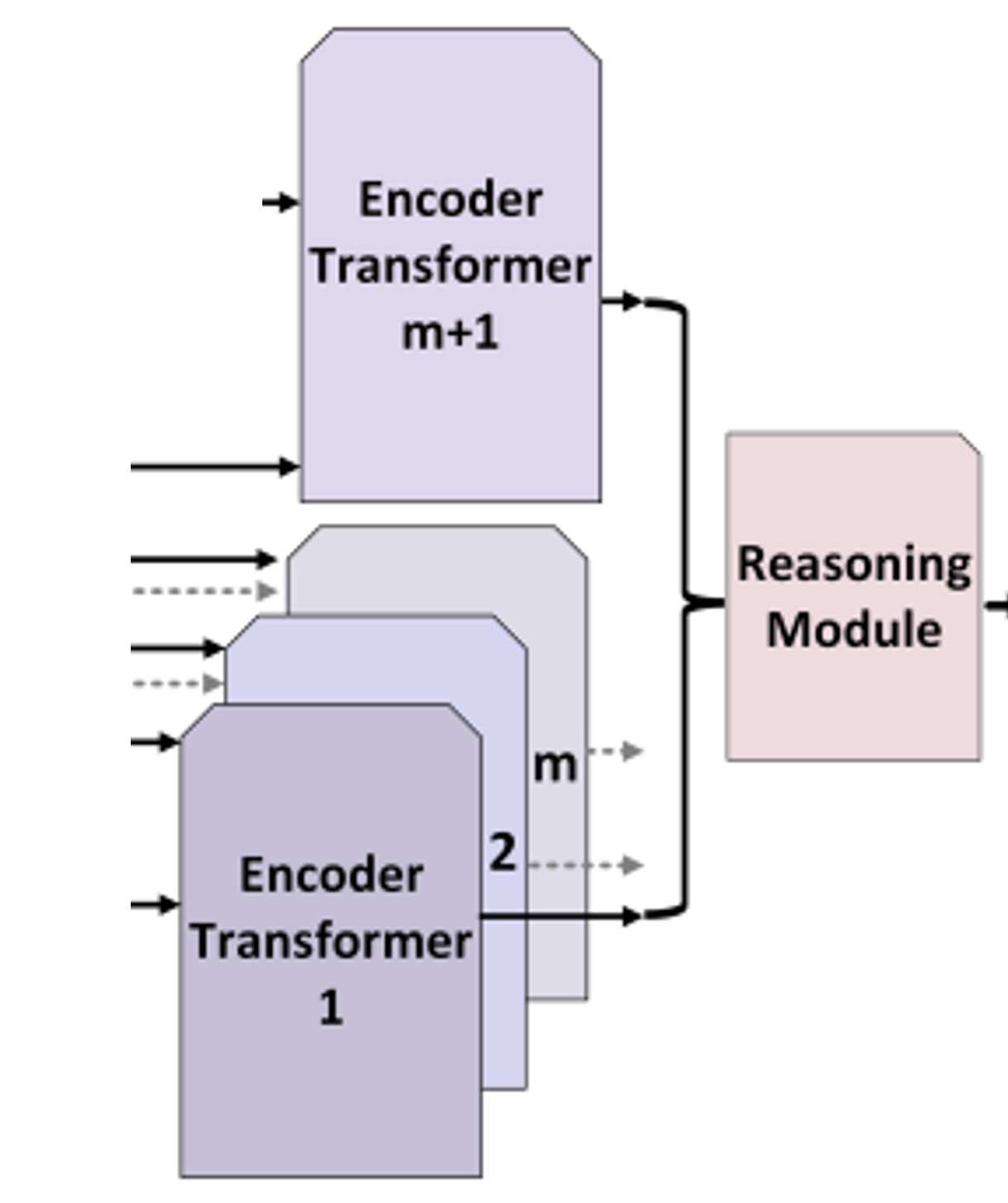
- 일단 위의 두 embedding을 concat
- cross attention을 거쳐서 output을 만듦
Decoder
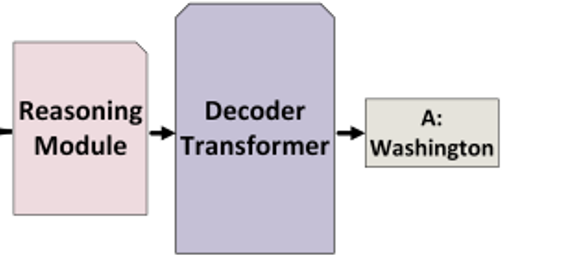
- 위의 attention layer을 decoder layers에 넣어 answer generation 만듦 (auto-regressively)
- loss function (cross entropy):
4 Experiment
4.1 Dataset: OK-VQA
- largest knowledge-based VQA dataset: q에 대한 correct a를 위해서는 'outside knwoledge'가 필요함 (image만 갖고는 correct a가 나올 수 없음)

- q's crowdsourced from AMTurk
- 14,031 images & 14,055 q's, variety of knowledge categories
- metric은 VQA에서 사용되는 standard evaluation metric 사용함
4.2 Implementation Details
- knowledge reasoning module: T5 (base / large) 사용
- finetuning on OK-VQA dataset
- AdamW, lr 3e-5, warm up for 2k iterations, training for 10k iterations
- retrieved entities limited to 40, batch size 32
- prediction에 대한 evaluation은 normalization(lowercasing, removing articles, punctuation, duplicated whitespace etc.) 이후에 이루어짐
- trained on 3 different random seed, results averaged for final submission
4.3 Comparison with Existing Approaches
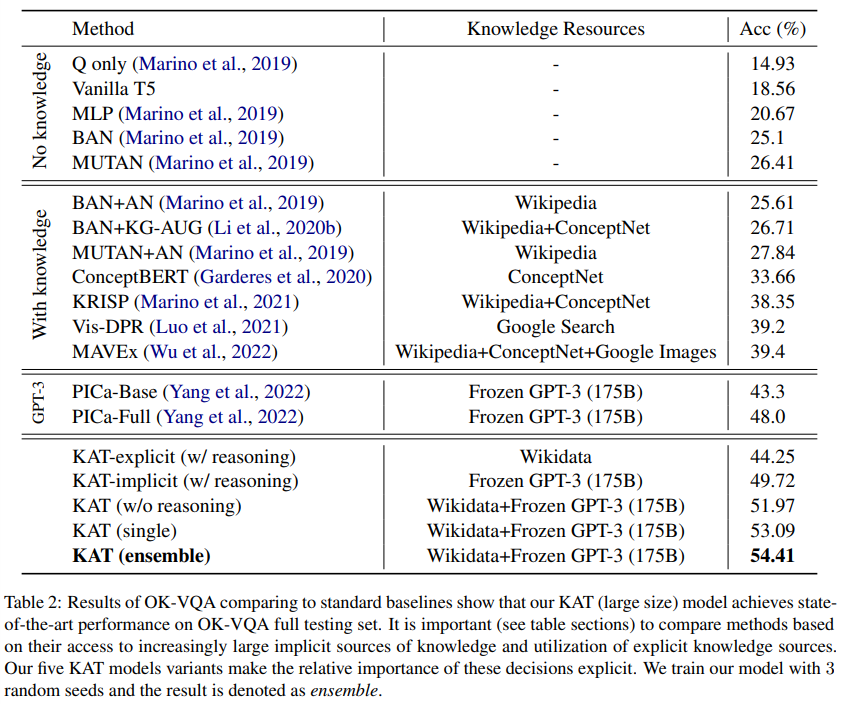
- SoTA 갱신
- explicit knowledge만 사용한 것들끼리 비교 (44.25 vs MAVEx, KRISP)
- contrastive-learning-based model (CLIP)
- leaving headroom by incorporating supervised pretrained models (e.g. pretrained object detectors)
- implicit knowledge from GPT-3 for additional input
- KAT outperforms PICa-Full
5 Ablation Study
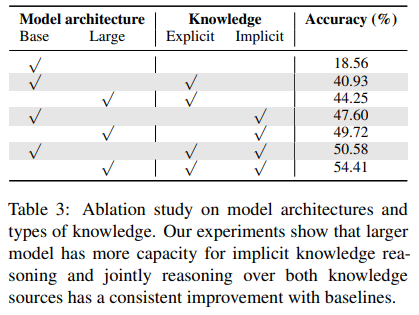
- KAT-large (T5 large for reasoning module) 은 implicit knowledge reasoning에 더 큰 capacity
- implicit + explicit knowledge integration이 상호보완적인 역할함 (둘을 모두 사용했을 때 4%p까지 performance 향상)
5.1 Effectiveness of Knowledge Reasoning

- KAT without reasoning module (KAT w/o reasoning): (reasoning module 대신)
- 위와 같은 simple concatenation of knowledge sources는 KAT보다 2.43%p underperform
- KAT w/o reasoning이 encoding 과정에서 noise (irrelevant knowledge) 에 대한 적절한 제거가 없었음을 의미함
5.2 Extracting Explicit Knowledge
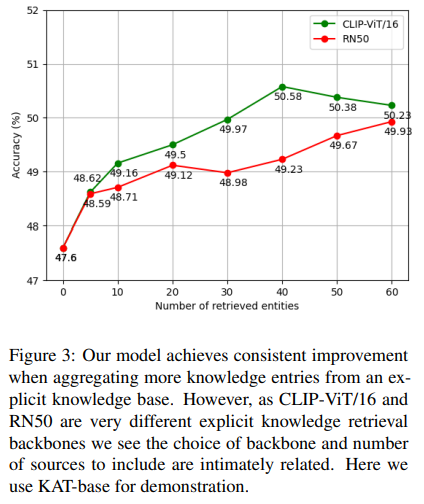
- explicit knowledge retrieving size에 따라 performance가 차이남
- retrieved entity가 0 (considering only implicit knowledge) 일 때는 PICa-Full baseline보다 못함: model 고도화가 능사는 아님, performance improvement 위해서는 explicit knowledge가 필요
- entity retrieval size가 커질수록 performance가 나아짐: retrieval size 커지면 distracting (irrelevant) knowledge가 포함될 확률이 높아지기는 하지만, retrieved set 사이에서 visually든 semantically든 similar knowledge를 공유하고 있을 가능성이 높아서 search space & spurious ambiguity reduction
- backbone을 ViT/16과 ResNet-50으로 달리하였을 때, 큰 차이(?)가 있지는 않았음, 어쨌거나 추세는 같음
5.3 Category Results on OK-VQA
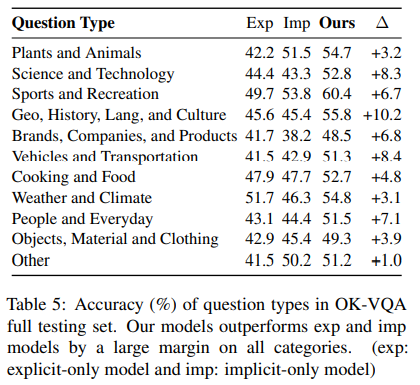
- OK-VQA의 카테고리는 11개
- 각 카테고리별로 implicit 또는 explicit만 사용해서, 그리고 implicit + explicit 모두를 사용한 모델을 학습시켜 결과 제공
- 대부분 카테고리에서 explicit만 사용한 모델이 implicit만 사용한 모델보다 못함
- implicit knowledge: SoTA object detection, image captioning models, supporting evidence from GPT-3
- explicit knowledge: image와 knowledge base entities 사이의 semantic matching이 끝 -> richer but distracting knowledge
- 단, 'Brands, Companies, and Products" & "Weather and Climate"의 경우 그 반대인데, recognizing objects with fine-grained description from image가 중요함
5.4 Qualitative Analysis

- 좌: explicit knowledge from knowledge base가 reasoning에 필요한 정보들은 포함하고 있으나, bench와 Coca Cola logos 사이의 relation 포착에 실패해서 최종적으로 올바른 답을 도출하지 못함
GPT-3에서 나온 implicit knowledge는 bench가 붉은색인 것만 포착하고 Coca Cola logo를 포착하지 못함
explicit knowledge + implicit knowledge여야 비로소 정답 도출
6 Conclusion
- implicit knowledge (from large models) 와 explicit knowledge (from structured knowledge bases) 의 상호보완적인 관계에 초점을 맞춤
- VQA task 통해 improving retrieval과 reasoning의 relationship을 명징하게 제시함 + SoTA 갱신까지
- future work: image regions aligning, integrating multiple knowledge bases etc.
7 Misc
- 장점
이미 나와있는 것들을 잘 조합했다(GPT-3 prompting + external knowledge usage + CLIP)
plain language, ablation study - 단점
코드 전체가 공개되어있지는 않다는 점(그래도 training/validation set은 공개되어 있음), 그러나 그를 보완하기 위한 appendix

4개의 댓글


[밤알바] -One of the obvious part-time job advantages for students is having a steady income.meet new people and (most importantly) earn some extra cash.
https://www.9alba.com-Best Sites to Find a Part-Time Job
Community. People work to be part of and contribute to their communities. This means that jobs exist not only for your benefit, but jobs also let you help others. For example, let’s say I have a job in an office delivering the mail. I’m helping the whole office save time and get stuff done.
제 연구에서 image captioning이 필요한데 여기서 나온 방법들을 적용해봐도 정말 좋을 것 같습니다!!! gpt-3안의 common sense와 explicit knowledge를 결합하는 부분이 인상적이었습니다!!! 좋은 설명 감사합니다~