REALM: Retrieval-Augmented Language Model Pre-Training (ICML, 2020)
2nd semester 2022 NLP study
0. Abstract
- Pretrained LM이 "world knowledge"를 잘 포착해냄으로써 NLP task에서 굉장히 좋은 퍼포먼스를 보이는 것은 사실임
- 그러나 위와 같은 "world knowledge"는 모델 내부에(implicitly) NN의 파라미터로서 저장되어 있고, 더 많은 "facts"를 포착하려면 NN도 끊임없이 커져야만 함
- knowledge를 modular하고 interpretable하게 포착하기 위해, 본 논문은 LM pretraining에 "latent knowledge retriever"를 추가하였음
- 본 모델은 pretraining, fine-tuning, inference 과정에서 Wikipedia와 같은 큰 코퍼스에서 document를 retrieve하고 attend함
- 말이 어려운데, retrieval module을 pretraining, finetuning, inference 등 모델 전반적으로 사용하고 있다는 의미 - "knowledge retriever"를 masked language modeling을 이용한 비지도 학습방법으로 어떻게 pretrain하는지 제시할 것
- MLM은 learning signal과 backpropagating(document retrieval step)으로 사용됨 - Retrieval-Augmented Language model pre-training (REALM)을 Open-QA에 fine-tuning한 결과를 제시함
- Open QA SoTA 결과(implicit & explicit knowledge storage)와 비교하였을 때, previous model을 4~16%의 absolute margin으로 outperform 하는 동시에, interpretability와 modularity 또한 겸비함을 확인
- 개인적 소감:
retriever까지 포함하는 LM pipeline이 한 번에 통으로 backpropagation까지 되는 거 너무 좋아!
interpretability 너무 좋아: expertise 많은 분야에서 사용 가능할 듯? 잘 이해한다는 걸 보여주려고 Open-QA에 fine-tuning했지만 어디엔가 더 쓸 수 있을듯
e.g. 특가법상 수뢰(금액 따라 형량이 크게 달라짐)
그런데 retrieval는 corpus가 충분히 크지 않으면 힘들겠다
huggingface realm 왜 업데이트 안해주냐.. 개빡치네..
1. Introduction
* LM pretraining이라 함은 LM을 pretraining하는 framework를 말함(not model itself)
BERT, RoBERTa, T5 등 LM pretraining은 (Petroni et al., 2019)에서 제시한 대로 많은 양의 corpora를 pre-training에 사용함으로써 엄청난 양의 world knowledge를 저장할 수 있게 되었음. 여기서 "world knowledge"라 함은 실제 세계에서 통용되는 지식 e.g. "pound"는 영국의 화폐단위 따위와 같은 것을 일컬음.
- LM pretraining 내의 world knowledge의 한계
그러나, 위와 같은 world knowledge는 NN안에 parameter로써 implicit하게 저장되어 있다는 것이 문제임. 때문에 '어떤' knowledge가 '어디에' 저장되어 있는지 판단하기가 어려움. 게다가 모델의 크기에 따라 knowledge storage 크기가 결정되므로 더 많은 world knowledge를 저장하고 싶다면 모델이 커질 수밖에 없고, 이는 필연적으로 더 많은 비용과 시간을 야기함.
- REALM의 소개
knowledge를 interpretable하고 modular하게 포착하기 위해, 본 연구진은 Retrieval-Augmented Language Model (REALM) pre-training이라는 새로운 framework를 제시함. REALM은 LM pre-training algorithm에 learned textual knowledge retriever라는 모듈을 부착하는 것임.
LM pretraining과는 다르게 REALM은 모델에게 "inference 과정에 어떤 knowledge를 retrieve할 건데?"라고 물어봄으로써 world knowledge를 explicit하게 이용함. Prediction 과정에서는 retriever가 Wikipedia같은 large corpus에서 document(passage랑 같은 말임)을 retrieve 해와서 attend한 게 prediction 과정에서 사용됨. 본 framework에서는 end-to-end learning의 backpropagation에서 retrieval step이 사용되고, 이 retrieval step은 textual knowledge 전체 corpus에서 검색하도록 되어있음
- REALM의 소개: retriever 학습 요령
REALM의 key intuition은 unsupervised text로부터 나온 performance-based signal(perplexity)을 사용해 retriever를 학습시키는 것. model perplexity를 향상시키는 retrieval은 helpful한 것으로 간주되어 rewarded되고, uninformative retrieval은 penalized됨. 이와 같은 학습방식은 retrieve-then-predict approach(latent variable LM & optimizing marginal likelihood)를 통해 구현됨
LM pretraining에 위에서 설명한 large scale neural retrieval module을 부착하는 것은 엄청난 컴퓨팅 자원을 요구하는데, pre-training 때마다 retriever가 mln 단위의 candidate document를 consider하고, backpropagation까지 해야 하기 때문. 그래서 본 연구진은 Maximum Inner Product Search (MIPS)라는 것을 고안해서 retriever가 각 document에 진행한 계산을 cache하고 asynchronously update해서 best document를 선택할 수 있도록 함
말이 좀 어려운데, 컴퓨팅 자원 절약 위해서 그냥 트릭 좀 썼다 이 말임
- 선행연구와 REALM의 차이
NN에 retrieval step을 붙인 이전 연구들은 많았는데, LM pre-training 단에서, 그리고 non-learned retriever를 사용해서 large scale document collection 처리한 연구는 없었음. 선행연구 중에서는 kNN LM (2019)이 비슷하게 memorization을 향상시키는 모델이었으나, target task를 위해 labeled된 example만 사용할 수있었음. 반면, REALM retriever는 다른 task에도 적용할 수 있고, retrieval 결과물이 text이지 labeled example이 아니라는 점에서 차이 있음
- REALM evaluation
REALM으로 pretrain한 모델을 Open-QA task에 fine tuned한 결과를 제시함. 3 popular Open-QA bechmarks (NaturalQuestions-Open, WeQuestions, CuratedTrec)에 비교하고, SoTA Open-QA 모델과 비교하는데, SoTA Open-QA 모델은 T5 같은 large NN, knowledge retriever를 사용한 모델(다만, implement retrieval은 heuristic한)을 포함함. 그 결과는, REALM이 3개 benchmark test에서 SoTA 모델을 모두 4-16%p 차이로 SoTA 갱신함. 또한, REALM은 interpretability와 modularity를 모두 확보한 것을 확인할 수 있음
2. Background
Language model pre-training
LM pre-training의 goal은 unlabeled text corpora에서 representation을 뽑아내는 것. pre-trained model은 fine-tuned돼서 downstream task에 사용될 수 있는데, 보통 target task를 목적으로 처음부터 학습된 모델보다 좋은 성능을 기대할 수 있음
본 연구진은 BERT pretraining에 사용된 MLM에 집중하였음. MLM은 input text passage에서 구멍 뚫린 missing token을 predict하도록 학습됨. 모델은 input text passage의 representation을 이용해 missing token을 predict함. 잘 학습된 MLM은 semantic, syntactic information과 함께 world knowledge를 잘 encode할 수 있어야 함
e.g. "The [MASK] is the currency [MASK] the UK"
-> 앞의 [MASK]는 "pound", world knowledge이고, 뒤의 [MASK]는 "of", syntactic & semantic information임
Open-domain question answering (Open-QA)
모델이 world knowledge를 잘 학습했는지 판단할 수 있는 downstream task는 여러 가지가 있지만, Open-QA는 knowledge가 가장 중요하게 사용되는 task이므로 선정하게 되었음. Open-QA는 다음과 같음:
Q: "What is the currency of the UK?"
A: "pound"
Open-QA의 "open"은 모델이 answer가 있는 pre-identified document를 받지 않는다는 것을 뜻함. answer가 포함된 pre-identified document를 받는 것은 Reading Comprehension(RC)에 해당됨(e.g. SQuAD). RC model은 하나의 문서를 읽지만, Open-QA는 mln 단위의 document를 읽고 정보를 추출해 갖고 있어야 함
Notation
: query(question)
: text corpus(knowledge source)
: query 에 대해 relevant document
: relevant document 내 answer
많은 Open-QA system은 knowledge source로 textual knowledge corpus 를 사용함. 많은 Open-QA system은 retrieval-based approach를 사용하는데, retrieval-based approach란 다음과 같음: question 가 주어졌을 때, corpus 로부터 relevant document 를 retrieve하고, relevant document 로부터 answer 를 retrieve하는 것. REALM은 위와 같은 retrieval-based approach에서 아이디어를 가져와 LM pre-training에 접목했음. 한편, generation-based system을 사용해서, token-by-token generatin하는 모델도 있는데, 본 논문의 모델과 비교할 것임
3. Approach
- 본 단락의 구성
3.1에서 retrieve-then-predict generative process, 즉 REALM의 pre-training & fine-tuning task를 설명할 것임
3.2에서 각 process의 구성요소를 설명할 것임
3.3에서 REALM pre-training과 fin-tuning을 어떻게 접목할 것인지, likelihood of REALM's generative process를 maximize하는 방식으로 설명할 것임. 그 와중에 컴퓨팅 파워 측면에서의 challenge, why training works, strategies for injecting useful inductive biases에 대해 논의함.
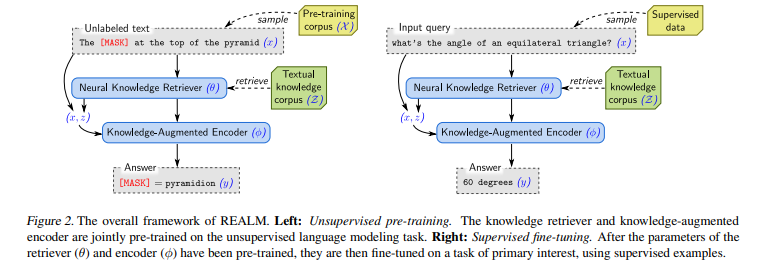
3.1 REALM's generative process
pre-training과 fine-tuning에서 공통적으로, REALM은 input 와 possible 에 대해 distribution 를 학습
pre-training 단에서 task는 MLM임. 는 pre-training corpus 에서 나온 masked sentence이며, 는 missing tokens임. fine-tuning 단에서 task는 Open-QA이며, 는 question, 는 answer임.
REALM은 distribtuion 를 2 step으로 나누는데, retrieve and then predict임. 먼저 knowledge corpus 에서 possibily helpful document 를 retrieve해서 를 만듦. 이후에 retrieved document 와 input sentence 를 output 의 조건으로 설정해 를 만듦. likelihood of generating 에서, 는 latent variable(잠재 변수)로 취급되고, all possible documents 에 대해 marginalize하여 다음과 같은 식을 만들 수 있음
REALM의 decomposition
는 retrieve, 는 predict
는 병시적으로 드러나지 않고(latent), 의 값에 따라 의 값이 변하므로 dependent variable로 취급하여 marginalize의 대상이 됨
3.2 Model architecture
neural knowledge retriever는 를 만들고, knowledge-augmented encoder는 를 만듦
고로, knowledge-augmented encoder neural knowledge retriever
Knowledge Retriever
retriever는 dense inner product model로 정의할 수 있으며, inner product(relevance score)가 클수록 relevant document를 retrieve했다고 판단
Notation
: 각각 와 를 -dimensional vector로 mapping하는 embedding function
: 와 간 relevance score, embedding vector 간 내적으로 계산됨
Function
embedding function은 BERT-style Transformer에 아래와 같이 사용됨(사실 BERT NSP 학습할 때와 거의 똑같이 생김)
[CLS] token은 pooled representation of sequence(notation: )에 해당하며, vector 차원축소 위해 projection matrix 를 아래와 같이 정의함
여기에서, 과 는 각각 document의 title과 body
retriever의 모든 parameter를 라 할 것임
Knowledge-Augmented Encoder
input 와 retrieved document 가 주어졌을 때, knowledge-augmented encoder는 상술했던 것처럼 임. 와 는 와 같은 식으로 만들어서 하나의 sequence로 만들고, retriever에서 사용된 것과는 별개의 Transformer로 보내버림. 이렇게 함으로써 얻을 수 있는 점은, 를 예측하기 전에 와 사이에서 rich cross-attention을 얻을 수 있다는 점
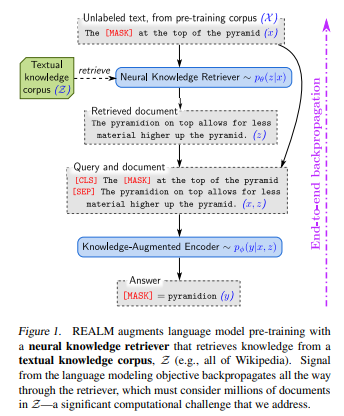
이 단계에서 pre-training과 fine-tuning이 약간 다름. 아래 수식이 조금 복잡하긴 한데, 쉽게 말하면 pre-training 때에는 MLM을 한 거고, fine-tuning 때는 answer의 start, end token에서 뽑을 수 있는 vector로 실제 정답과 유사한지 matching한 것
- pre-training (MLM)
MLM loss는 BERT와 똑같이 계산함
Notation
: masked token에 대한 transforemr output vector
: 에서의 total nr. of [MASK] tokens
: token 에 대한 word embedding
Function
- fine-tuning (for Open-QA)
Open-QA fine-tuning을 위해서는 answer string 를 만들어야 하는데, 이전 연구들을 참조해서, 가 안의 token sequence와 같다고 판단할 수 있음. 이 때, 를 document 와 그 안의 정답 span 의 set라고 표현할 수 있음. 이 때, 를 다음과 같이 표현할 수 있음
Notation
: span set 의 element 의 각각 start, end token의 transformer output vector
Function
knowledge-augmented encoder의 모든 parameter를 라 할 것임
3.3 Training
pre-trianing과 fine-tuning 모두에서 log-likelihood 를 maximizing하도록 훈련시킴. retriever, knowledge-augmented encoder 모두 미분가능해서 를 SGD로 최적화하였음
- IR에서의 끔찍한 연산량: 쿨하게 top-k로 제낌 & asynchronous refresh
계산 상의 challenge는 marginal probability 를 계산할 때 corpus 에 대해 모든 document 의 확률을 더해야 한다는 것. 본 연구진은 가 가장 높은 top k document의 확률만 더하는 것으로 갈음. top k 제외하고는 어차피 확률이 0에 수렴할 텐데 생략해버려도 큰 문제 없음
이렇게 한다 해도 top k를 뽑아내는 효율적인 방법이 필요함. 기준으로 정렬하는 것은 relevance score 와 같다는 것을 이용해서, Maximum Inner Product Search (MIPS) algorithm을 top k document 찾는 데에 사용할 것임. 이게 왜 효율적이냐면, document 숫자가 늘어나면, 시간과 저장공간은 선형적으로 늘어남(sub-linearly, 선형보다 더 낮게?)
MIPS를 적용하려면 를 먼저 계산해야 하는데, 만약 retriever의 parameter인 가 업데이트 되어버리면 고생해서 계산한 document embedding 값이 다 무슨 상관?
그래서 본 연구진은 index를 학습 몇백 스텝(several hundred training steps)마다 한 번씩만 re-embedding하였음(asynchronously re-embedding & re-indexing). MIPS index는 index update 사이에는 가장 최신을 반영한다고 할 수는 없지만, MIPS index의 수치가 중요한 게 아니라, top-k document를 뽑아내기 위한 것임을 기억해야 함. top-k document를 뽑아낸 다음에는 당연히 update된 parameter로 를 다시 계산함. 이런 식의 계산 간략화 덕분에 안정적으로 최적화가 가능했으며, 어차피 index update는 충분히 빈번하게 이루어졌다고 말할 수 있는 충분한 근거가 있음!
Implementing asynchronous MIPS refreshes
MIPS index 갱신은 두 가지 job을 병행해서 이루어짐:
(1) primary trainer job: parameter update
(2) index builder job: document embedding & indexing
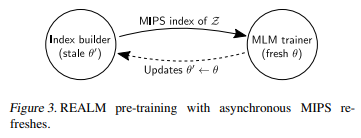
(1) trainer에서 parameter 열심히 굴려서 update 해서 그걸 (2) index builder한테 던져주면, (2) index builder는 document() embedding & indexing 계산하고, (2) index builder가 열심히 계산해서 index를 (1) trainer한테 넘겨주는 사이에 (1) trainer는 다시 parameter 열심히 계산하는 과정이 병렬적으로 이루어짐
위와 같은 asyncrhonous refresh(update)가 pretraining, fine-tuning에 모두 적용될 수 있지만, 본 연구에서는 pre-training에만 사용되었으며, fine-tuning 단에서는 MIPS index, 모두 한 번씩만 계산되었음. 어차피 fine-tuning 단에서 update하니까 크게 달라질 것은 없다고 판단
What does the retriever learn?
knowledge retrieval 자체가 잠재적(latent)이다보니, training 과정에서 meaningful retrieval이 이루어지는지 명확히 확인하기가 힘듦. 여기에서는 retrieval이 prediction accuracy 향상에 어떻게 도움을 주는지 서술할 것
query 와 document 가 주어졌을 때, 가 relevance score라는 것을 떠올리면서, 다음 gradient 식을 한 번 보자
document 에 대해, gradient는 retriever가 score 를 에 따라 바꾸게 하는데, 가 양수이면 가 증가할 것이고, 가 음수이면 는 감소할 것임. 이면 가 양수일 필요충분조건(둘 중 밑의 식을 참고)임. 는 document 를 사용해서 정답 를 예측할 확률임. 는 에서 document를 random sampling 했을 때 의 기댓값임. 따라서, document 는 기대보다 outperform할 때 positive update를 받게 됨
-> 이해 잘 안 되네.. 뭐 어쨌거나 informative retrieval에 positive feedback이 가고, uninformative retrieval에 negative feedback이 간다고 이해하면 될 듯
3.4 Injecting inductive biases into pre-training
REALM 만드는 과정에서 retrieval 향상시킬 수 있는 strategy를 아래에 정리했음
Salient span masking
요약: context 말고 world knowledge 필요한 곳에 masking
REALM의 목적은 world knowledge를 학습하는 것인데, local context만으로 MLM 해결할 수 있는 경우도 있어서, salient(중요한) masking을 진행: dPzjseo "UK", "July 1969" 등에 mask하는 것. CoNLL-2003에 학습된 BERT-based tagger를 사용해서 named entities, date를 뽑아냈으며, sentence마다 이런 salient masking을 진행했음
Null document
salient span masking을 해도 모든 masked token 예측에 world knowledge가 필요한 것은 아님. 그런 경우에는 top-k에 null document(그냥 empty)를 배치해서 retrieval이 필요없음을 나타냈음
Prohibiting trivial retrievals
요약: predict에 너무 많은 정보를 주는 case는 제거
pre-training corpus 와 knowledge corpus 가 같으면, '너무 informative'한 trivial candidate 가 있을 수밖에 없는데, 이런 trivial candidate 때문에 graident가 너무 큰 폭으로 뛰어버리고, trivial candidate case가 너무 자주 있으면 model은 결국 와 사이의 'exact match'만 확인하고, relevance 포착은 실패할 것임. 이 때문에 우리는 trivial cnadidate를 pre-trianing 동안은 제거하였음
Initialization
요약: cold start 방지하기 위해 Inverse Cloze Task로 warm start
학습 초기에 와 가 시원찮으면 document 는 question 와 실제로 relevance가 없을 가능성이 있음. 이러면 augmented encoder가 retrieval을 무시해버리는, 잘못된 학습을 할 가능성이 있음. 이런 일이 생기면, gradient update가 미미하고, 모델이 학습을 못하고, 다시 gradient update가 미미하고... 하는 악순환이 생겨버림. 이런 학습을 'cold-start'라고 하는데, 본 연구진은 'warm-start'를 사용해서, 첫 embedding들은 Inverse Cloze Task(ICT)에서 학습하도록 함. ICT는 sentence를 출처가 되는 document와 함께 학습하도록 하는 것임
4. Experiments
본 section은 benchhmark에 대해 설명하고, 본 모델과 비교할 approach에 대해 설명함
4.1 Open-QA Benchmarks
finetuning 얘기임! pretraining 에서는 Wikipedia 또는 CC-News가 사용됐음!(table 1 참조)
질문자조차도 답을 모르는 질문이 있어야 더욱 사실적이고, 질문자-bias가 없는 결과물이 나올 수 있음. 모든 case에 대해 예상 답안은 exact match(EM)으로 평가하고, 그 외의 reference answer는 사용하지 아니하였음
NaturalQuestions-Open
NaturalQuestions dataset은 Google queries-answers dataset임. 각 answer마다 answer type이 있는데, 본 연구에서는 5 token을 넘지 않는 short answer type만을 사용하였음. 또한, 본 dataset은 reference answer로 참고할 만한 Wikipedia document가 있는데, 위에서도 언급했듯 이는 사용하지 아니하였음
WebQuestions
WebQuestions dataset은 Google Suggest API에서 수집됐는데, seed Q를 1개 주고 연관된 Q들로 확장되는 형식임
CuratedTree
CuratedTree dataset은 MSNSearch와 AskJeeves에서 QA pair를 가져온 것으로, 진짜 사람이 질답한 내용임. 복수의 정답이나 철자가 다른 점 때문에 정답이 정규표현식으로 되어 있다는 것이 특징임. Generation-based model에서 이런 데이터셋으로 어떻게 학습을 할지 불분명하기 때문에 이 데이터셋에 대해서는 evaluate하지 않을 것임
4.2 Approaches compared
Retreival-based Open-QA
현존하는 많은 open-QA system은 먼저 relevant documents를 knowledge corpus로부터 뽑아내고, document 단위로 reading comprehension system을 적용해 답을 찾아냄. 이 구조에서, knowledge는 corpus 내에 "explicit"하게 존재함.
많은 approach들은 non-leanred heuristic retrieval을 사용하는데, BoW matching이나 entity linking 등이 그것임. 이렇게 뽑힌 documents는 learned model로 re-rank되긴 하지만, 처음의 heuristic retrieval step의 한계 때문에 coverage가 작을 수밖에 없음. DrQA, HardEM, GraphRetriever, PathRetriever같은 게 그 종류
최근 approach같은 경우에는 MIPS index를 사용해 learnable retrieval을 접목하기도 함. ORQA는 REALM처럼 latent variable model을 사용하고, marginal likelihood를 maximize하는 것도 같음. 그러나, REALM은 pre-training step에 변주가 있고, MIPS index로 backpropagation한다는 게 차이(ORQA는 fixed index를 사용하는 듯함)
추가로, REALM pretraining과 ORQA는 모두 Inverse Cloze Task로 initialized(warm start)되었음
Generation-based Open-QA
Open-QA의 또 다른 approach는 sequence prediction task처럼 modeling하는 것임. Generation이라는 이름에 맞게, question을 encoding해서 token by token으로 decoding하는 것. GPT-2가 그 예시임. 그러나, fine-tuning의 부족 때문에 퍼포먼스가 낮음. T5의 경우에는 context가 주어졌을 때 explicit extraction 없이도 answer generation이 가능함을 보이긴 했지만, 이는 context document가 주어졌을 때에 한정된다는 한계가 있음. 어쨌거나 Open-QA에 fine-tuned된 T5를 사용하여 본 모델의 성능을 비교할 것임
4.3 Implementation Details
Fine-tuning
Knoweldge corpus: English Wikipedia, Dec.20. 2018 기준
Dataset Size: 문서를 288 tBERT wordpieces 단위로 잘라 13 mln retrieval candidate으로 만듦
inference: top-5 candidates
Pre-training
steps: 200k
batch size: 512
lr: 3e-5
document embedding step for MIPS index: parallelized over 16 TPUs
for each example, retriving and marginalizing over 8 candidate documents
pre-training corpus(: (1) Wikipedia(identical to the knowledge corpus ), (2) CC-News, corpus of English news
4.4 Main results
- main baseline: ORQA (lee et al., 2019)
REALM과 비슷하긴 하지만, pretraining 과정에서 MLM을 사용하지 않았고, Wikipedia에서 한 문장을 뽑아와 query로 간주하고 query-document matching 하는 형식으로 pre-training 하였다고 함
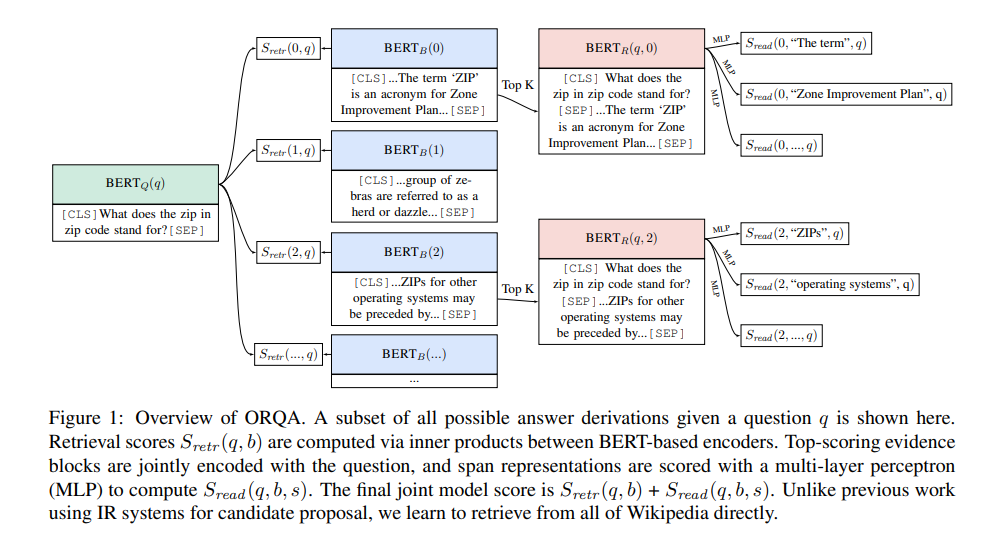
- Results
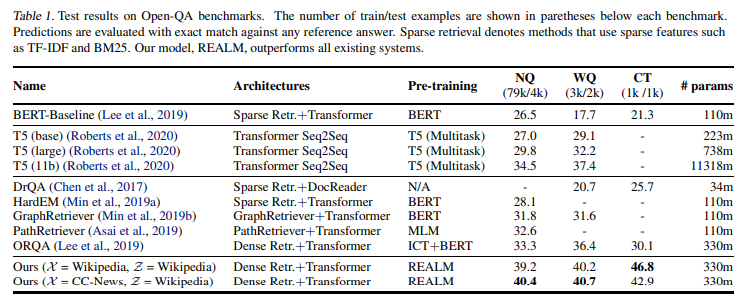
REALM이 previous model들을 significant margin으로 outperform.
T5 기반의 generative Open-QA system이 powerful하고, 모델이 커질수록 performance 상승이 있긴 하지만, 가성비가 떨어짐: T5-large에서 T5-11B으로 넘어가면 파라미터는 50배 증가하지만, accuracy는 고작 5pt 상승
반면, REALM은 T5-11B의 1/30밖에 안 되면서도 성능은 더 뛰어남. 게다가, T5가 pretraining 과정에서 SQuAD dataset을 학습했다는 것까지 고려한다면... 그리고 REALM은 SQuAD dataset은 학습 안 했다는 점을 고려하면......
REALM과 가장 직접적으로 비교할 수 있는 것은 ORQA인데, fine-tuning setup, hyperparameters, training data가 모두 동일하기 때문. REALM이 ORQA보다 더 좋은 성능을 낼 수 있었던 것은 순전히 pre-training의 차이 덕분이라고밖에는 말할 수 없음. ORQA와의 비교로 보았을 때, 본 연구의 pre-training 방식은 single corpus setting( = Wikipedia, = Wikipedia), separate corpus setting( = CC-News, = Wikipedia) 모두에 적용할 수 있음을 알 수 있음
다른 retrieval-based system과 비교하면, 여타 retrieval-based system이 20~80개 document를 retrieval하고, REALM은 5개 document만을 retrieval함에도 performance는 더 좋다는 점을 확인할 수 있음
4.5 Analysis
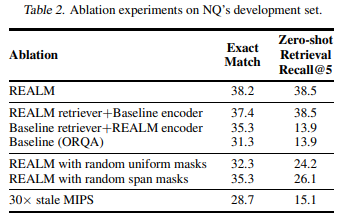
zero-shot retrieval recall @ 5 metric은 retriever가 pre-training에서 얼마나 중요하게 쓰였는지를 보여줌
Encoder or Retriever
요약: REALM pre-training은 retriever, encoder 모두 다 향상시켰음
REALM pre-training이 retriever를 향상시켰나, 아니면 encoder를 향상시켰나, 아니면 둘 다 향상시켰나? 확인해보기 위해 retriever 또는 encoder를 pre-training 전의 initial state로 돌려두고 fine-tuning을 진행할 수 있는데, 둘 중 어느 것을 initial state로 돌려도 baseline으로 설정한 ORQA 수준으로 퇴보했음. 결국 REALM training으로 retriever나 encoder나 다 향상되었음
Masking scheme
요약: salient span masking 중요
salient span masking의 성능을 확인하기 위해서 (1) random token masking, (2) random span making(from spanBERT)를 시도했는데, 이러한 salient span masking이 BERT training에는 도움이 되지 않았지만 REALM에는 중요했음. 생각해보면 latent variable learning이 retrieval utility에 의존하기 때문에 learning signal이 consistent해야함
MIPS index refresh rate
요약: 어쨌건 갱신주기가 길어지면 성능하락
training - embedding & indexing parallel process를 구축해서 MIPS index를 만들었는데, 약 500 step마다 index가 갱신됐음. 갱신주기가 늘어지면 성능 하락 있었음
Examples of retrieved documents

답이 'Fermat'인 query에서 REALM이 BET보다 더 높은 probability를 줬음. (b)를 보면 Corpus에서 딱 맞는 document 들고 와서 그런 건데, 그게 아니더라도 (c)를 보면 unsupervised text에서 훈련시켜도 REALM이 잘 작동하는 것을 볼 수 있음
5. Discussion and Related Work
6. Future Work
향후 가능할 연구방향:
(1) structured knowledge(?)
(2) multi-lingual setting e.g. retrieving knowledge in a high-resource language to better reprsent text in a low-resource language
(3) multi-modal setting e.g. image/video를 retrieve하기
Misc
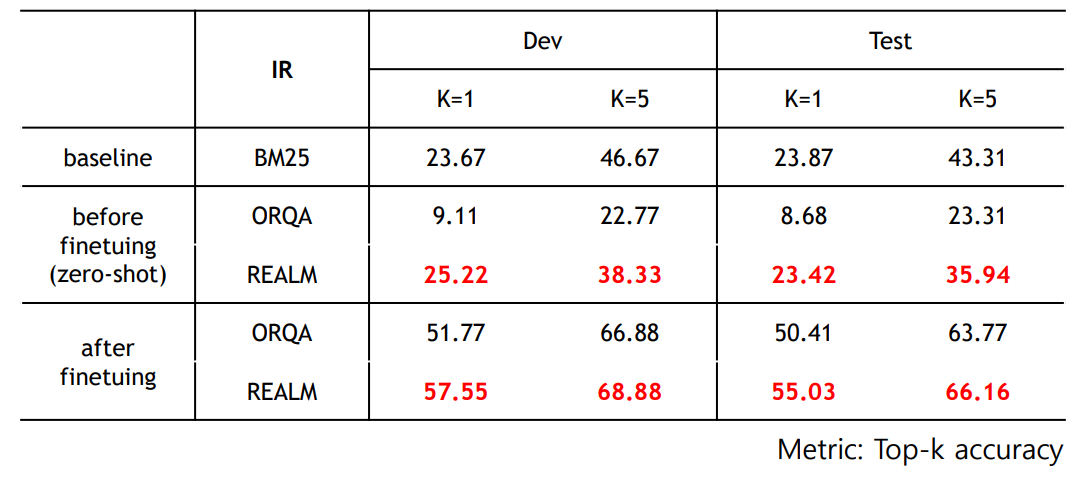
2020년에 REALM 이용한 한국어 Open-QA 구축 시도가 있었음!
https://nlp.jbnu.ac.kr/papers/hclt2020_realm.pdf
- model, retriever, reader를 다르게 했을 때
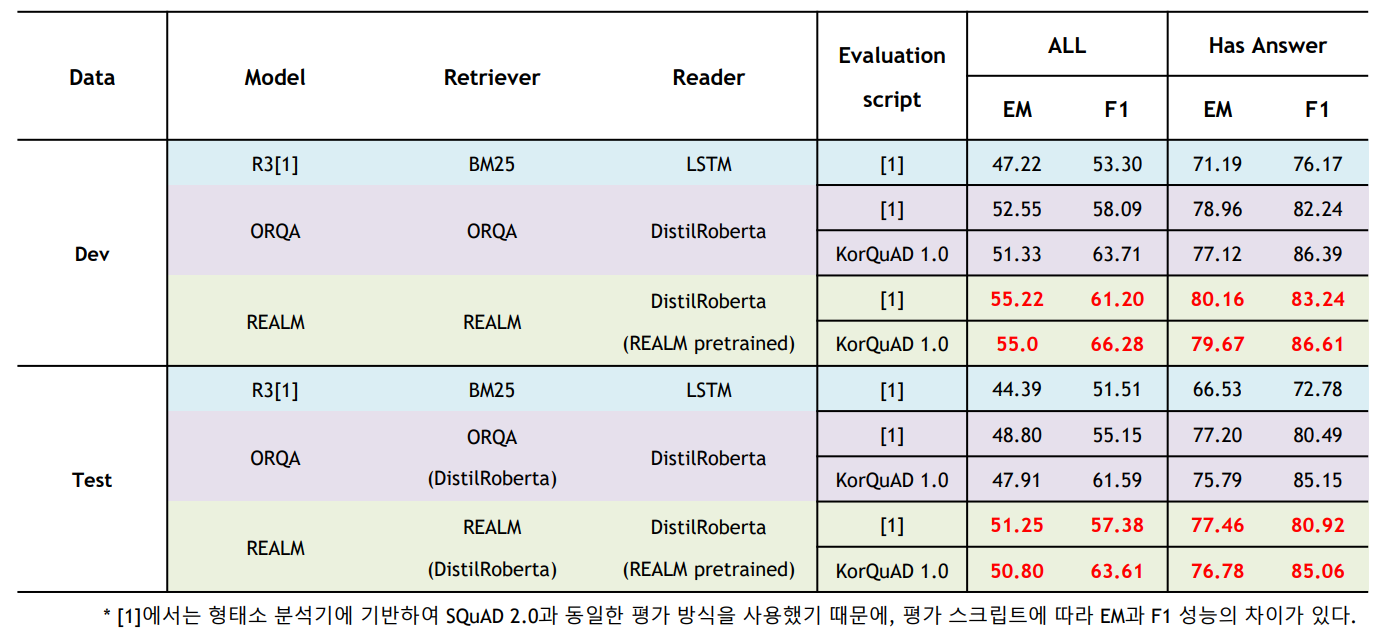
- baseline(BM25)와의 비교