Get to the Point: Summarization with Pointer-Generation Networks (ACL, 2017) a.k.a. Pointer-Generator
2nd semester 2022 NLP study
Abstract
- 기존 abstractive summarization의 단점:
- factual details inaccurately(including OOV, fabrications(nonsense))
- repeat themselves
- 새로운 모델: seq2seq attentional model + pointer-generator + coverage
- hybrid pointer-generator network: pointing이라는 것을 이용해 원 텍스트에서 단어를 가져옴: factual accuracy를 높임(단점 1 극복)
generator이라는 것을 이용해 새로운 단어를 생성 - coverage를 이용해 어떤 내용이 이미 요약되었는지(단점 2 극복)
- hybrid pointer-generator network: pointing이라는 것을 이용해 원 텍스트에서 단어를 가져옴: factual accuracy를 높임(단점 1 극복)
- 모델의 결과: CNN/DailyMail summarization task에 적용했을 때 SoTA 모델에 비해 ROUGE 2 point 이상의 진전
- take home message: CNN/DailyMail dataset의 bias
1. Introduction
-
summarization의 종류:
- extractive summary: passage에 있는 것들(보통 문장)을 뽑아내서 summary 구성
- abstractive summary: 새로운 단어(novel, 원 텍스트에 있지 않은 단어)를 생성하여 summary 구성, 보통 사람한테 summary하라고 하면 나오는 유형
-
extractive summary가 보통 더 쉬움: 갖다 베끼는 게 문법이나 정확도나 어느 정도 수준으로 보장되기 때문
-
그러나 high quality summary를 위해서는 abstractive summary 필요: paraphrasing, generalization, real-world knowledge의 incorporation 등은 abstractive summary에서만 가능하기 때문
-
많은 summarization 논문은 그 어려움 때문에 abstractive summary에 치중되어 있었음
- extractive summary의 역사가 궁금하다면: Poibeau et al., (2013)
-
seq2seq의 등장 이래로 abstractive summarization이 불붙음
- 그래도 reproducing factual details이 부정확하고, OOV 문제, repeating themselves 등의 문제가 있음

-
예시에서 보이듯
(1) inaccurate factual description: "destabilize nigeria's economy"의 주체는 muhammadu buhari가 싸우려는 것인데, summary에서는 muhammadu buhari가 해당 phrase의 주체로 나옴(red),
(2) OOV 문제: "muhammadu buhari"(red),
(3) repeating itself: "in the northeast part of nigeria"의 반복(green) 등의 문제가 있음 -
우리의 모델은 위 3가지 문제점을 해결한 multisentence abstractive summary를 개발코자 함
- 기존 연구는 headline generation 등 1~2문장의 짧은 summary를 많이 만들었는데, 실제로는 복문으로 된 summary가 더 힘들고(구문의 반복을 막아야 하므로), 더 유용하게 쓰일 수 있을 것
-
결과: CNN/DailyMail dataset에 모델을 적용한 결과, SoTA 모델에 비해 2 ROUGE point 가량 개선되었음
-
pointer-generator network: 모델 accuracy와 OOV 처리를 위한 pointing(Vinyals et al., 2015)과 새로운 단어 생성을 위한 generator로 이루어져 있음
-
본 모델은 extractive와 abstractive의 그 중간이라는 점에서 CopyNet와 Forced-Attention Sentence Compression과 비슷하다고 볼 수 있음
-
본 모델은 또한 Neural Machine Translation의 coverage vector를 차용함으로써 원 text를 track & control coverage할 수 있음; 이는 repetition을 제거하는 데에 아주 효과적이었음
2. Our Models
- baeline seq2seq model, pointer-generator model, coverage mechanism에 대한 설명, 이 중 coverage mechanism은 baseline과 pointer-generator와도 결합할 수 있음
<notation>
: encoder hidden state
: attention weight 적용된 encoder hidden state, a.k.a context vector
: decoder state
: softmax 이전의 attention weight
: 단어 를 생성할 확률
2.1 baseline: seq2seq attentional model
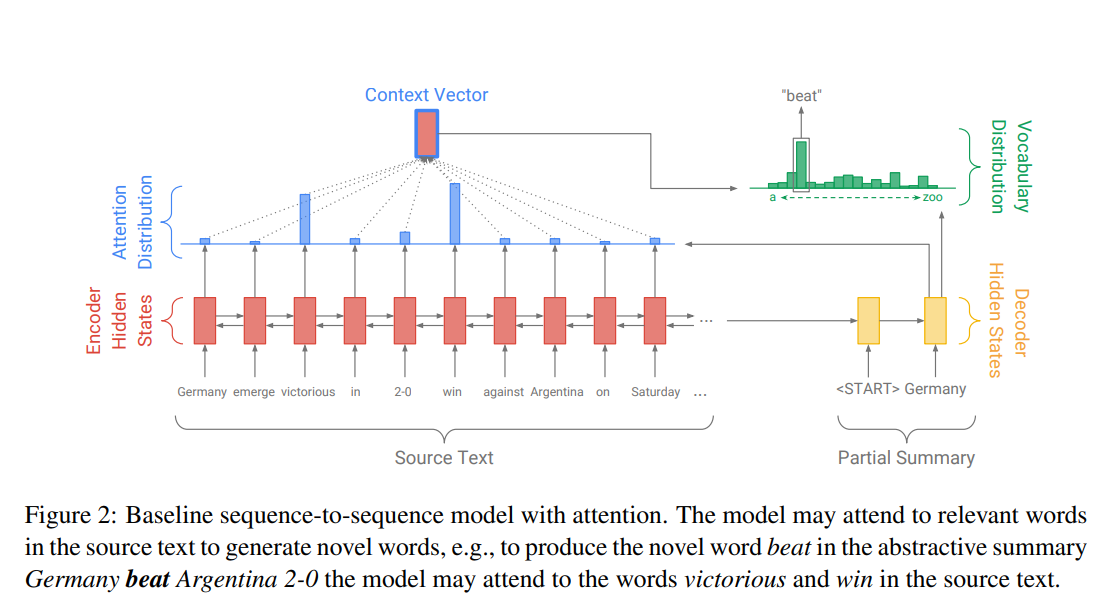
-
encoder:
- single-layer bi-LSTM
- input으로 를 받아먹어서 encoder hidden states 를 생성
-
decoder:
- single-layer uni-LSTM
- input으로 이전 word embedding 받아먹음
단, 훈련 시에는 reference가 되는 실제 summary의 단어를 사용하지만, test 시에는 모델이 추측한 단어를 사용한다는 차이가 있음
decoder state 를 생성
-
attention distribution : attention 좀 보려고 이것만 인용문 처리했음 하하
- 모두 trainable parameters
- attention distribution 를 이용해 encoder hidden states의 weighted sum, 다시 말해 context vector 를 구해줌
(이런 형태의 attention을 이용한 fixed vector 생성방법은 BiDAF(2017)에서 신나게 까였음)
-
prediction
- context vector 는 decoder state 와 concatenate해서 linear layer 2개 통과해서 vocabulary (probability) distribution 생성
모두 learnable parameters이며, 은 vocab 집합 내 모든 단어를 대상으로 함 - 개개 단어 에 대한 probability는 로 나타낼 수 있음
- context vector 는 decoder state 와 concatenate해서 linear layer 2개 통과해서 vocabulary (probability) distribution 생성
-
loss
- time step 에서의 target word 의 loss는 다음과 같이 계산될 수 있음
또한, 전체 sequence의 loss는 다음과 같이 계산될 수 있음: 그냥 평균
- time step 에서의 target word 의 loss는 다음과 같이 계산될 수 있음
2.2 Pointer-generator network
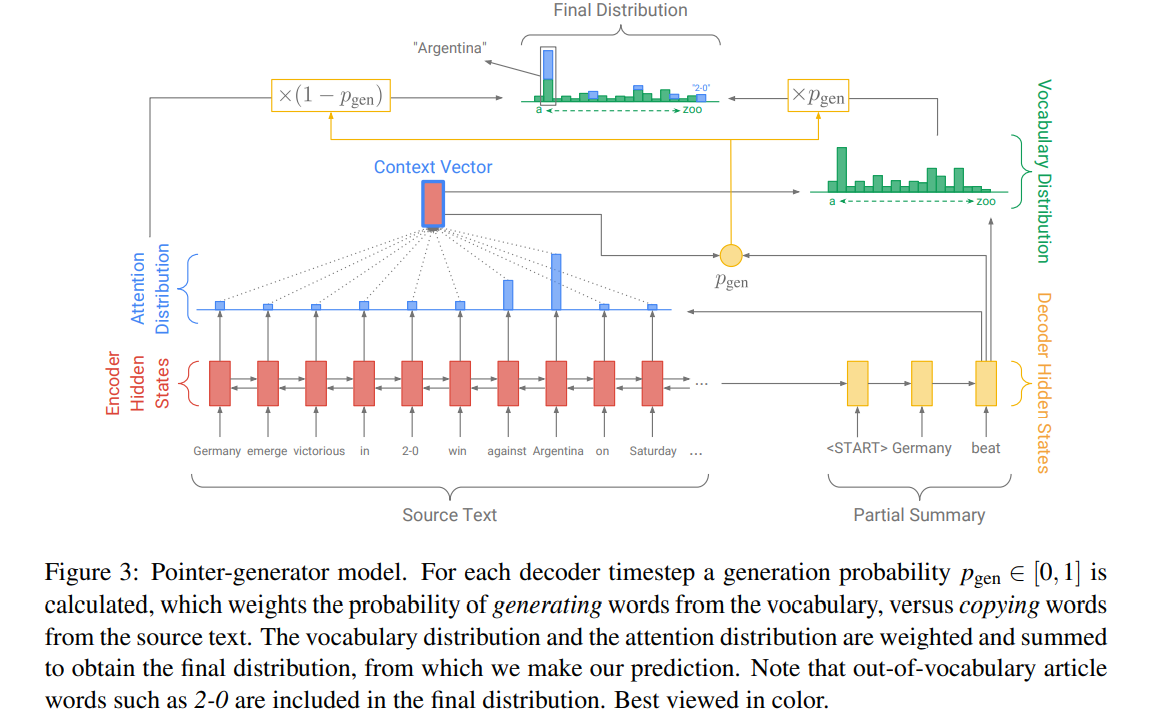
-
본 모델은 baseline인 seq2seq attention과 pointer network의 짬뽕이다. 어떤 점에서?
- pointing을 통해 단어를 생성하고, generating으로 vocab 내에서 단어를 생성함
-
attention
- attention distribution 와 attention distribution을 이용한 context vector 는 baseline seq2seq attention과 똑같이 계산됨
-
generation probability
-
time step 에 대한 generation probability
-
무슨 일을 하느냐?
은 에서 단어를 generate할 것인지, input sequence에서 나온 단어를 attention distribution 이용해 copy할 것인지 선택하는 분기(soft switch)로써 작동함 -
은 context vector , decoder state , decoder input 에서 다음과 같이 계산됨
-
는 learnable parameters, 는 sigmoid function
-
document마다 소위 'extended vocabulary'라는 것을 만드는데, 이는 source document에서 등장한 단어와 원래 있던 vocab 집합의 합이며, extended vocabulary에 대한 probability distribution은 다음과 같이 계산될 수 있음:
-
해설: 우리가 예측하고 싶은 단어 에 대해,
전항 는 기존의 단어집합에서 나타날 확률,
후항 는 source document에서 나타날 확률을 뜻함
는 i가 0부터 가 일 때까지를 뜻하는 듯? 많이 보이지 않은 notation.. -
가 OOV이면 일 것이고,
가 source document에서 등장하지 않는다면, 일 것임
baseline model같은 경우에는 vocab 집합에만 제한될 것임
-
-
loss: 계산이 달라진다는 것만 빼면 baseline과 같음
2.3 Coverage Mechanism
-
이전 2.2 pointer-generator에서는 OOV problem 해결했지?
여기 2.3 coverage mechanism에서는 repetition 문제 해결하는 거임 -
repetiton은 seq2seq model에서 꽤 흔하게 발견되는 문제인데, multi-sentence text generation에서 더 흔하게 발견됨
-
우리는 Tu et al. (2016)의 coverage model을 가져와서 repetition 문제를 해결해보려고 시도했음
-
coverage vector
- 무슨 역할을 하는데?
현재 time step 에서 attention이 이전 attention들을 고려(이전 attention 정보는 로 요약되어 있음)하도록 함
이는 같은 위치(단어)에 반복적으로 attention 주는 것을 피하게 함으로써 자연스럽게 repetition을 피하게 됨 - 이전의 모든 time step의 decoder의 sum of attention distributions인 coverage vector 를 정의
- 해설: 이전의 attention vector(vector element를 모두 더하면 1임)를 모두 더함
- : time step 이전까지 단어들이 attention 받은 정도(coverage)를 나타내는 것
- 위의 coverage vector는 attention mechanism의 또다른 input으로 들어감
<coverage vector 가 포함된 attention 계산식(본 논문)>
<baseline seq2seq의 attention 계산식의 일부>
- 는 learnabel parameter로, 와 똑같은 dimension 가짐
- 무슨 역할을 하는데?
-
loss
- coverage vector 때문에 loss 하나 더 추가!
attention weight()의 -th element인 의 값은 무조건 1보다 작으므로, 임
현재 시점의 attention과 지금까지의(so far) attention distribution의 overlapping을 방지하기 위함
-
따라서 전체 loss 식은 다음과 같이 수정됨
<까지 고려했을 때 time step 의 loss>
<baseline seq2seq의 time step 의 loss>
여기서 는 hyperparameter
- coverage vector 때문에 loss 하나 더 추가!
3. Related Work
Neural abstractive summarization
2015년에 시작(Rush et al., 2015)되기는 했는데, 2016년 CNN/DailyMail dataset이 등장하기 전까지는 dataset이 너무 작아서 의미가 없었고, Nallapati et al. (2016)의 CNN/DailyMail dataset이 나옴으로써 abstractive baseline이 생길 수 있었음. 정작 Nallapati 선생님은 hierarchical RNN을 이용한 extractive summary로 논문 쓰심(2017). abstractive summarizing의 초창기라 ROUGE score를 따지면 위의 extractive summary가 더 높게 나옴
Pointer-generator networks
본 논문에서 으로 사용된 pointer-generator networks는 Vinyals et al., 2015에서 모티브를 따왔음. 원래는 NMT에서 사용된 건데, LM에도 쓰이고, summarization에도 쓰이고 널리널리 쓰이게 됨. 본 논문의 pointer-generator network는 이전의 pointer와는 다른데, 이라는 a.k.a. switch를 explicitly하게 정의하고, attention distribution을 살짝 조정해 을 정의했음(한 가지 더 있는데 그건 sum attention 얘기라 패쓰). 또한, 기존의 pointer가 OOV와 NE 처리를 위해 사용됐다면, 우리는 copy-generation의 조화를 위해 사용했다는 점.
Coverage
NMT에서 coverage가 처음 사용됐다고 함
4. Dataset
- CNN/DailyMail dataset 사용
- 이전 BiDAF 논문에서도 나왔지?
- 781 tokens/article, 3.75 sentences/article, 56 tokens/sentence
- 287,226 training pairs, 13,368 validation pairs, 11,490 test pairs
- 이전 BiDAF 논문에서는 entity에 anonymizing을 한다는 것처럼 나왔는데, CNN/DailyMail dataset 중 이미 익명화 처리가 끝난 게 있다고 하네(2016년 dataset 논문은 익명화 처리한 데이터를 사용했다고)
그런데 이 논문은 익명화 처리를 하지 않은 CNN/DailyMail dataset를 사용했다고 함
-> 논문 뒷편의 result를 본다면.. 차라리 익명화 처리 하고 한 번 실험 돌리는 게 나았을 텐데..
5. Experiments
- hyperparameters
hidden dimension: 256
embedding dimension: 128
source & target vocab size: 50k
batch size: 16(train)
at test, beam search with beam size 4
optimizer: Adagrad
learning rate: 0.15
initial accumulator value: 0.1
gradient clipping: max graident norm 2
- vocab size
pointer network 사용해서 OOV 문제 해결 가능하므로 baseline 모델(Nallapati et al. (2016))에서 사용했던 150k source & 60k target vocab보다 훨씬 더 작게 가져가는 게 가능했음. pointer와 coverage가 parameter 수를 각각 1,153, 512만큼만 늘렸다는 걸 생각하면(전체 model의 parameter는 거의 21.5mln) 확실히 남는 장사임.
- word embedding
baseline model에서는 pretrained word embedding을 사용했지만, 본 모델에서는 word embedding을 처음부터 학습하게끔 하였음
- optimizer, learning rate
Optimizer 및 learning rate의 경우, SGD, Adadelta, Momdentum, Adam, RMSProp 써봤는데 저게 제일 낫더라라고 함. regularization 없음. validation set loss로 early stopping 적용
- truncation(max token length)
source article의 max token length는 400으로, target summary의 train 시 max token length는 100으로, test 시 max token length는 120으로 truncation 진행. 다만, 실제로 test 시에 summary length가 120 찍는 경우는 그다지 많이 없었는데, beam search algorithm이 스스로 중단(self-stopping)을 했기 때문(왜 test에서만 max token length를 120으로 설정했는지는 결국 나오지 않음..). 원래 truncation한 이유는 (당연히) 빠른 학습이었지만, 잘라서 학습시켜보니 performance가 향상되는 현상을 목도할 수 있었음. training 처음에는 많이 자른(highly-truncated) sequences를 대상으로 학습시키다가 convergence 일어나면 max token length를 늘리는 방식으로 진행하는 게 효율적이라고 하더라.
- 학습소요 시간
본 논문의 baseline model 학습에 33 epochs(600,000 iterations) 소요되었음. vocab size 50k일 때는 학습에 4d 14h, vocab size 150k일 때는 8d 21h 소요되었음. pointer-generator model은 학습이 더 빨라서 12.8 epoch(230,000 iterations, 3d 4h)만에 끝났다고 함.
- coverage loss etc.
coverage loss까지 붙여본 결과는 다음과 같음. 본 모델을 학습시키고, 추가로 로 설정하고, 3,000 iterations 정도 더 학습시켰을 때(약 2시간 소요), coverage loss가 처음에는 0.5였는데 0.2로 converge하였음. 일 때는 coverage loss가 더 줄었으나, primary loss가 증가한 관계로 사용하지는 않음.
coverage loss는 없는 coverage model을 학습시켰을 때, repetition 문제를 알아서 해결하지 않을까? 하는 실낱같은 희망이 있었지만 효과가 없었음.
coverage 학습시킬 때 원래는 phase 나눠서 학습을 시켰는데, 처음부터 coverage 붙여서 학습시켰을 때는 오히려 coverage가 main objective를 방해하면서 오히려 퍼포먼스가 하락했음.
6. Results
6.1 Preliminaries
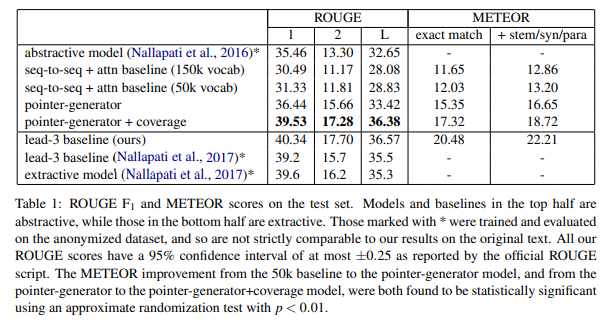
- metrics
standard ROUGE metric을 사용해, ROUGE-1(unigram overlap), ROUGE-2(bigram overlap)의 F1-score, ROUGE-L(predicted summary와 reference summary 사이에서 공통되는 가장 긴 sequence)을 pyrouge 모듈 이용해 계산
METEOR metric도 사용했는데, match mode(단어 사이에 정확히 일치할 때만 점수 획득), full mode(단어 뿐만 아니라 어간(stem), 동의어, paraphrase에 대해서도 점수 획득)을 적용하였음
- 비교군
본 모델 뿐 아니라 lead-3 baseline도 사용하였는데, 당시 현존하였던 '유일한' abstractive model(Nallapati et al., 2017)과 extractive model도 가져와서 비교하였음
- dataset 익명화 여부에 따른 ROUGE score 차이에 관한 장광설+결론
다만, 본 모델은 plain-text summary를 만들지만(왜냐하면 dataset이 anonymized 되지 않았으니까!) 상술한 abstractive model의 summary는 anonymized되어있으므로(왜냐하면 dataset이 anonymized 되었으니까!) ROUGE score를 엄밀하게 비교하기는 힘듦. 실제로 dataset의 anonymization 여부에 따라 ROUGE score가 차이 있는데, anonymized dataset의 lead-3 ROUGE score가 plain(unanonymized) dataset의 lead-3 ROUGE score보다 낮음. 위와 같은 결과는 복수의 언어로 이루어진 entity(e.g. United States of America)가 n-gram overlap을 높이기 때문으로 설명할 수 있음.
-> 이럴거면 데이터 학습할 때 왜 plain text로 학습했냐? 성능 비교하기 쉽게 anonymized dataset으로 학습하지..
매우매우 안타깝게도, ROUGE score만이 모델들 간의 성능을 측정하는 척도로 사용될 수밖에 없는데, dataset의 anonymization 여부에서 발생하는 ROUGE score 격차를 감안해도, 본 모델이 Nallapati et al. (2016)의 abstractive summarizing 모델보다 더 성능이 좋다고 판단할 수 있음.
<dataset 익명화 여부에 따른 ROUGE score 차이>
anonymized dataset보다 plain dataset의 점수가 더 높음
+1.1 ROUGE-1, +2.0 ROUGE-2, +1.1 ROUGE-L<abstractive summarizing model(Nallapati et al., 2016)과 본 모델의 ROUGE score 차이>
본 모델의 ROUGE score가 더 높음
+4.07 ROUGE-1, +3.98 ROUGE-2, +3.73 ROUGE-L
Observations
- baseline models에 대한 신랄한 비판
본 논문의 seq2seq+attention baseline(150K vocab), seq2seq+attention baseline(50k vocab) 모두 ROUGE score, METEOR 결과가 그다지 좋지 않았음. vocab size를 50k에서 150k로 늘린 게 그다지 효과적이지는 않았던 듯함. factual detail이 엄청나게 틀려있고, OOV가 아닌데도 자주 등장하지 않는 단어는 더 자주 등장하는 단어로 바꿔버림.
seq2seq+attention baseline은 'thwart'라는 단어의 등장 빈도가 낮아서 'destabilize'로 바꿨고, 결국 'destabilize nigeria's economy'라는 문구에까지 집어넣어서 호응관계가 완전 어색해짐. 원래는 'thwart'하는 주체가 'criminals'였는데, 'destabilize nigeria's economy'의 주체는 'president'임.
3번째 문장을 보면 단어의 반복과 비문이 동시에 등장하는 꼴을 볼 수 있고, OOV(Muhammadu Buhari)는 아예 가져오지 못함. 더 많은 사례들은 appendix에 있음
- pointer-generator model에 대한 진단
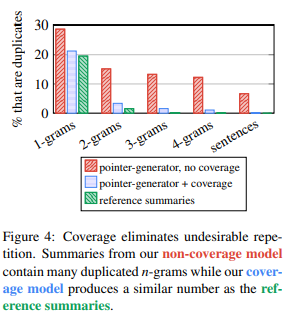
pointer-generator model은 조금만 학습시켜도 ROUGE와 METEOR score 모두 종전의 (유일한) abstractive summarizing model의 성능을 뛰어넘음. OOV 문제도 해결되고, factual detail도 정확하게 가져오고, fabrication(non-sense라고 생각하면 됨)도 해결됐는데, 문제는 repetiton임(fig1의 초록색 참조).
- pointer-generator model + coverage에 대한 진단
coverage를 붙인 pointer-generator model은 ROUGE와 METEOR score를 더욱 더 높이고, 전체 훈련 시간의 1%도 차지하지 않는 coverage를 더함으로써 repetition issue가 거의 완전히 해결되었음을 알 수 있음.
자세한 사례를 확인하려면 fig1을 보면 되고, 양적 결과는 fig4를 확인하면 알겠지만, pointer-generator에 coverage가 없을 때(붉은색)의 경우에는 bi-, tri-, quadra-gram, 심지어 문장 단위에서도 repetition이 넘쳐나는데, coverage를 추가하자(푸른색) repetition이 굉장히 많이 줄어드는 것을 볼 수 있음.
그럼에도, lead-3 baseline의 ROUGE score, SoTA extractive model을 뛰어넘지는 못했음. 다음 장에서 좀 더 얘기해보자
7. Discussion
7.1 Comparison with extractive systems
extractive system이 ROUGE score에 있어서 abstractive system보다 더 앞서고, lead-3 baseline는 심지어 extractive system을 근소한 차이로 앞섬. 이와 같은 현상에는 2가지 정도로 변명할 수 있음
- lead-3, extractive system보다 뒤처지는 현상에 대한 구구절절한 변명
첫 번째로, 학습 데이터가 신문기사이기 때문에 보통 두괄식으로 이루어지고, 이 때문에 lead-3의 성능이 짱짱한 것일 거임. 더 실험해봤는데, 기사의 첫 400 token(대강 20문장)을 학습데이터로 사용했을 때가 800 token을 학습데이터로 사용했을 때보다 ROUGE score가 훨씬 더 높았음
두 번째로, task의 본질에 대해 생각해봐야 함. reference summary에 predicted summary를 갖다대는 건데, reference summary라는 게 상당히 주관적이란 말이지. 어떤 경우에는 완벽한(self-contained) summary이지만, 어떤 경우에는 기사에서 사실을 설명하는 몇몇 문장을 빼낸 것일 수도 있음.
게다가, 기사 하나가 39개 문장으로 이루어져 있고, 이걸 3~4문장으로 줄이려면 충분히 많은 요약의 경우의 수가 발생할 수 있고, abstraction까지 끼얹으면 더더욱 많은 summary 경우의 수가 나올텐데, 그러면 당연히 predicted summary와의 strict한 유사도는 떨어질 수밖에 없음.
figure 5를 보자. "smugglers profit from desperate migrants"는 "smugglers lure arab and african migrants by offering discounts to get onto overcrowded ships if people bring more potential passengers"하고 의미상으로는 거의 완벽하게 같은 문장이지만 ROUGE score를 구해보면 0점임. 이런 ROUGE score의 경직성은 reference summary가 오직 하나일 때 더더욱 악화되는데, 그나마 reference summary가 복수 갯수이면 조금 낫다(shown to lower ROUGE's reliability).
가능한 답안은 엄청 많은데 정작 정답은 하나밖에 없는 이 아이러니한 상황에서 ROUGE가 높은 점수를 주는 답안은 처음으로 등장하는 것들이나 원 문장을 그대로 따오는 것들 등 소위 '안전빵'에 가까운 것들임. 구축된 reference summary가 가끔 저런 '안전빵'에서 벗어나기도 하지만, ROUGE가 저런 메커니즘으로 점수 주는 걸 극복할 수 있는 정도는 아닌 것으로 보임.
위에서 구구절절 적은 이유 때문에, extractive system이나 lead-3에 ROUGE가 높은 점수를 주었을 수 있다 이것임
- ROUGE를 METEOR에 비교
METEOR는 단어의 완벽한 일치(exact word matches) 뿐만 아니라 stem(어간), synonym, paraphases(다만, predefined list가 있긴 함)의 일치까지 확인함. 본 모델에 METEOR를 적용해보면, stem, synonyms, paraphases를 다 계산해보면 1 METEOR point 정도의 상승이 있는데, 이게 abstraction이 일어나는 증거라고 생각하면 됨.
그럼에도 우리 모델이 lead-3는 뛰어넘지 못했는데, 그만큼 기사에서 두괄식이 엄청나게 잘 지켜지는 것으로 생각하면 될 듯. 이러한 dataset에 대한 문제는 future work로 떠넘기겠음
7.2 How abstractive is our model?
pointer mechanism은 전술하였듯 abstractive system을 더욱 쓸만하고, factual detail이 더욱 자주 갖다 쓰이도록 함. 반대로 생각해보면, factual detail을 잘 갖다 쓴다는 건 '덜 abstractive'하다는 것 아닐까?
- baseline model보다 '덜 novel'하다고 보이는 이유
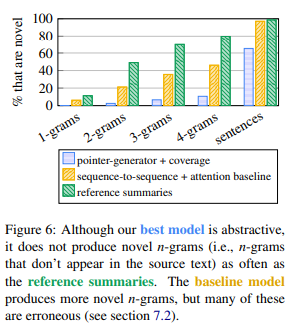
fig6를 보면, 본 모델의 summary가 reference summary보다 원 텍스트에서 등장하지 않는 새로운 n-gram을 덜 포함한다는 점을 확인할 수 있음. 심지어 baseline seq2seq+attention model보다도 novel sequence가 등장하는 빈도가 낮음. 다시 말해 abstraction 수준이 낮는 것. 하지만 baseline seq2seq+attention model의 novelty에는 허수가 끼어있음. baseline seq2seq+attention model이 새로운 n-gram을 더욱 자주 만들어내기는 하지만, 이것은 잘못 사용된 단어들(incorretly copied words), UNK tokens, non-sense(fabrication)를 모두 다 셈했기 때문.
(본 모델은 전체 기사 문장의 35%를 copy한 반면, reference sentence는 1.3%만을 copy하였음. 나머지 65%는 abstraction이라는 의미이므로 큰 진전이라고 할 수 있음. 기사 문장들은 truncated 되었고, 새로운 문장들은 기존 문장들의 일부를 잘라붙이는 식으로 구성됨. 불필요한 감탄사, 절, 괄호 안의 문구들은 무시되었음.
-> 뭔 소리 하는지 도저히 모르겠음. figure 6 보라고 하는데 눈 씻고 쳐다봐도 supporting fact를 찾을 수 없음)
fig 7을 보면 스포츠 경기에서 누가 누구를 이길 때 사용되는 단어인 'beat'와 'defeat'가 적절히 사용되었음을 확인할 수 있음. 그러나 이게 일반적이라고 하기는 좀 그럼.
generation probability 는 abstractiveness를 모델에 더하는 수단이 됨. 은 처음에 0.30에서 시작해 증가하다가, 0.53 정도로 끝남. 해석해보자면, 처음에는 베껴쓰다가 결국 절반 정도는 generate하는 법을 배운다고 생각할 수 있음. 반면, test에서는 이 copying에 심각하게 치우쳐져 있음(0.17). 이러한 갭은 훈련 시 reference summary와 같은 템플릿 안에서 모델이 단어 단위로 지도학습을 진행하지만 test 시에는 그러지 않기 때문으로 생각해볼 수 있음. 그래도 generator는 모델이 그저 베껴쓸 때만이라도 유용하게 사용될 수 있음. 은 문장 맨 앞, 원 문장들의 조각들을 연결할 때, 베껴쓰는 문장을 truncate하면서 문장부호를 찍을 때 등 불확실성이 가장 높은 순간에 그 값이 가장 높음. 본 모델은 베껴쓰면서도 이를 가공하는 것을 잘 함. 향후 pointer-generator model이 accuracy advantage를 가져가면서도 더욱 abstractively summarizing하도록 발전시키는 것은 향후 연구로 떠넘기겠음
8. Conclusion
- 본 논문의 모델
hybrid pointer-generator architecture with coverage
- improvements
inaccuacies & repetition reduced
- evaluation
on challenging long text dataset, outperformed SoTA abstractive system
- misc
우리가 만든 거 abstractive abilities가 대단하긴 한데, abstraction을 올릴 여지는 있는 거 같다
소감
- 식을 정말정말정말 친절하게 설명해줘서 좋았다: 입문용으로 사용해도 좋을 듯한 논문
- copying과 generating을 어떻게 할지 간단하면서도 직관적으로 이해되는 식!
