Scientific Paper Recommendation Systems: a Literature Review of recent Publications (IJDL, 2022)
IJDL 2021 IF: 1.6
Abstract
- paper recommendation system의 필요성: paper recommendation system은 desired relevant publications를 retrieve하는 것
- 이전 review paper는 통시적으로 접근하고 몇몇 개를 highlight했는데, 본 review는 좀 더 짧은 시간에 집중하는 대신 좀 더 철저하게 분석함
- 본 review에서 다루는 논문들의 범위
- 시간: Jan. 2019 - Oct. 2021
- 항목: method, dataset, evaluation, challenge
- objective: complete overview of current paper recommendation systems
1 Introduction
- keyword based search options insufficient: initial knowledge about the field 필요, user's informations not specified enough
- paper recommendation system의 다양한 elements
- input: a paper(source), user(without source paper), query terms
- output: single paper, list of papers
- dataset: 갖고 있는 것들도 있고(present already), crawled from web
- 본 review paper에서 다루는 범위
- 시간: Jan. 2019 - Oct. 2021
- 항목: methods, datasets, evaluation measures, challenges
- 본 논문의 Contribution
- current paper recommendation approaches의 multidimensional characterisation을 보여줌
- dataset 정리
- evaluation measures 정리
- challenges,, problem 정리
2 Problem Statement
- input: initial paper(e.g. textual content representation), keywords, user(e.g. combination of features of papers a user interacted with), user & paper, complex info(e.g. user-constructed knowledge graphs)
- type of recommendation: a single paper, a set of papers(libraries show 6-10 where users want 5-6)
- point in time: mostly immediate, a few delayed suggestion(e.g. newsletter)
- goals: 열람될 만한 paper recommendation, 단순히 initial paper와 어떻게든 연관되는 paper recommendation 등
- target audiences: junior/senior researcher 등 다양, 대부분 1명의 user를 target으로 하나, 복수의 user를 target으로 하는 연구도 있었음
3 Literature Review
3.1 Scope
- 기간
본 논문 이전에는 2019, 2020년에 나온 literature review가 가장 최신이었으며, 2019년까지의 연구만 review되었음. 그래서 본 연구의 기간 scope는 Jan 2019 - Oct 2021
- 검색 방법
ACM, dblp, Google Scholar, Springer 등 digital libraries에서 검색했으며, 검색어는 'paper', 'article', 'publication' 중 한 단어나 'recommend'의 의미가 가진 단어가 들어갔음. 영문 논문만 찾았으며, 논문의 제목 및 abstract를 보고 연관성 판단하였으며, 해당 논문들의 reference까지 범위에 맞다면 포함시켰음. 가장 처음 출판된 날짜가 본 기간 scope 안에 들어오는 경우, 리뷰 대상에 포함시켰음. scientific paper recommendation이 아니면 제꼈음. PRISMA workflow는 아래 figure 참고
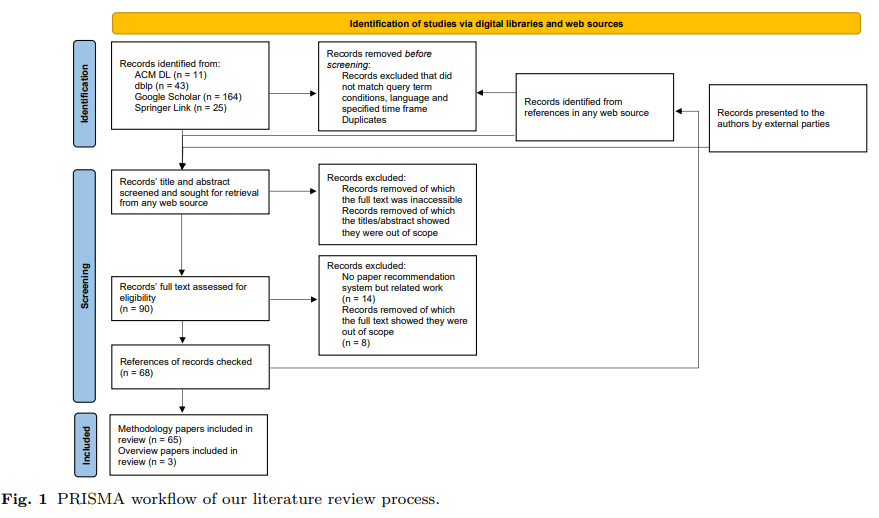
- 총 논문 갯수
총 82개 paper를 review했고, 그 중 3개는 review articles이며, 14개는 recommendation system을 제시하지는 않아 최종적으로 65개의 연구를 review하였음(3.2를 참고하면 최종 건수는 62건)
3.2 Meta analysis
article이 published된 issue의 year를 article year로 삼았음
- 총 65편 중 21건은 2019년, 23건은 2020년, 21건은 2021년에 출판
- 평균 4.05명의 authors, 12.3 pages
- 35건은 conference paper, 27건은 journal, 2건은 preprint였음
- 1건은 석사학위논문
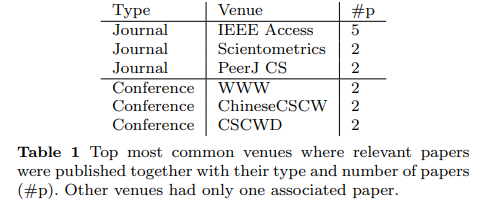
- top venues는 아래 table 참고
- 몇 건의 논문은 같은 approach, 같은 method 사용, 이런 것들을 걸러서 62건의 연구를 남겨놓음
3.3 Categorisation
3.3.1 Former Categorisation
- 이전 review literatures의 categorisation
- Beel et al. (2016): recommendation principle을 stereotyping, content-based filtering, collaborative filtering, co-occuerence, graph-based, global relevance, hybrid models로 나눔- Bai et al. (2019): content-based filtering, collaborative filtering, co-occurrence, graph-based methods, hybrid methods, others로 나눔
- Li and Zou (2019): content-based recommendation, hybrid recommendation, graph-based recommendation, deep learning based recommendation
- Shahid et al. (): content, metadata, collaborative filtering, citations로 나눔
위와 같은 결과를 고려하면, content-based filtering, collaborative filtering, graph-based, hybrid systems 가장 많이 등장한 분류체계일 것임.
- 이전 연구 분류체계의 4가지 종류
- Content-based filtering (CBF): user가 이전에 봤던 것들을 기반으로 user interest를 추론하여 사용함. Recommnedation은 paper와 user의 feature를 observe하여 만들어짐
- collaborative filtering (CF): user preferences와 비슷한 users preferences를 검토해 paper를 retrieve함. 현재 유저의 past interaction이 비슷한 유저들의 past interaction과 비슷해야 함
- hybrid: 여러 가지 recommendation를 섞은 것
- graph based: 특징을 명확하게 구분짓기는 힘듦. 좁은 정의로는 link prediction 또는 random walk를 사용하는 기법이며, 좀 더 넓게 보면 paper & author network를 구축해서 graph algorithm을 적용한 기법으로 볼 수 있음. 또는 random walk with restart/bibliographic coupling/co-citation inverse document frequency같은 graph metric을 사용한 기법으로 볼 수도 있음. 이전 연구들에서는 그냥 graph network 구축하면 graph based 사용했다고 퉁치기도 했음
- 이전 연구 분류체계의 문제점
- 연구자들이 스스로 라벨링한 technique은 부정확한 경우 있었음
- 광의의 graph based technique의 정의를 사용하면 최근 연구의 대부분은 hybrid로 들어갈 수밖에 없음
위와 같은 문제점들을 고려하면 이전의 분류체계는 적절하지 않다고 판단할 수 있어 다른 방식으로 접근함
3.3.2 Current Categorisation
20개 dimension으로 나누었는데, general information (G), 이미 있는 data (D), 새로 구축한 data (M)
-
(G) Personalisation: 개인화된 recommendation 제공, personalisation이 고려되지 않으면, recommendation은 input keyword나 input paper를 기반으로 이루어짐
-
(G) Input: paper (p), keywords (k), user (u), advanced type of input (o) 등 특정 form을 input으로 받음. 또는 input이 특정되지 않은 경우도 있어 (?)로 표기
-
(D) Title, (D) Abstract (abs.), (D) Keywords (key.), (D) Text, (D) Citation (cit.), (D) Historic interaction (inter.)
-
(M) User profile (user), (M) Popularity (popul.), (K) Key phrase (KP), (M) Embedding (emb.), (M) Topic model (TM), (M) Knowledge graph (KG), (M) Graph, (M) meta-path (path), (M) Random Walk (with Restart) (RW), (M) Advanced machine learning (AML), (M) Crawling (crawl.), (M) Cosine similarity (cosine)
-
6개는 general approach를 domain에 적용만 해본 것이었으며, 2개는 user information needs를 만족하는 모든 publication을 retireve하는 recommendation, 2개는 multiple papers를, 이외에는 k single papers를 recommend하는 approach임
-
2개 approach만 user groups를 대상으로 하는 recommendation system이었음
-
1개 approach만 subscription-based recommendation이었음
3.4 Comparison of Paper Recommendation Systems in different Categories
3.4.1 User Profile
- 32개 연구는 explicit user profile 구축
- 대부분의 user profile은 user의 actual interaction(historical interaction)으로부터 구축됨
- 일부 연구는 user profile을 user의 저작으로부터 구축
3.4.2 Popularity
- 13개 연구가 popularity measure를 사용: author, venues, paper 등
3.4.3 Key Phrase
- 4개 연구만 key phrase를 사용
3.4.4 Embedding
- paper에 대한 embedding 구축이 가장 흔히 볼 수 있는 유형: Word2Vec(+LDA top words), Doc2vec(+ word pairs), BERT, SBERT 등
- embedding input으로 사용한 것들: titles, abstracts, bodies, keywords, paper etc
- 몇몇 approach는 embedding model을 새로 만들어 사용: heterogeneous information network, 2-layer NN, scientific social reference network, TransE, node embedding, paper+author+venue embedding, user+item embedding, GRU+, GCN, LSTM 등
3.4.5 Topic Model
- 8개 approach가 TM 사용: 모두 LDA나 LDA+ 사용
3.4.6 Knowledge Graph
- 6개 paper가 knowledge graph 사용
- 1건은 predefined one(Watson for Genomics knowledge graph) 사용, 4건은 knowledge graph를 직접 구축하고, 한 건은 유저에게 knowledge graph 구축하도록 요청+연구진이 만든 knowledge graph 모두 사용
3.4.7 Graph
- 33건이 graph structure 사용
3.4.8 Meta-Path
- 4건이 meta-path 사용
3.4.9 Random Walk (with Restart)
- 12건이 random walk 사용
3.4.10 Advanced Machine Learning
- 29건이 advanced machine learning 사용
- multi armed bandits, LSTM, MLP, (bi-)GRU, matrix factorisation, gradient ascent/descent, simple NN, GNN, autoencoder, neural collaborative filtering, learning methods, DTW 등
- 3건은 paper ranking, 2건은 topic modeling으로 접근
3.4.11 Crawling
- 9건이 crawling step을 사용
- CiteSeer나 CiteSeerX의 PDF, Wikipedia, ACM, IEEE, EI 등에서 crawling
- 몇몇 건은 co-citation 밝히기 위해 citation information extraction을 위해 crawling 사용
3.4.12 Cosine Similarity
- 31건에서 cosine similarity 사용: paper 간, user 간, 또는 user와 paper 간 사용 등
3.5 Paper Recommendation Systems
65건의 논문에 대한 간략한 설명. 생략.
3.6 Other relevant Works
novel approach를 제시하지는 않지만 어쨌거나 범위 안에 들어있는 것들. 생략
4. Datasets
- evaluation이 없거나 actual paper recommendation에 대해 evaluate하지 않는 dataset(e.g. initial paper와의 cosine similarity 계산 etc)은 제외
- data source는 명시되었지만 size나 composition이 언급되지 않았거나, actual number를 알 수 없는 dataset 제외
- publicly available dataset을 중심으로 전개할 것임
4.1 dblp based datasets
- dblp computer science bibliograph (dblp): authors, papers, venues metadata 제공하는 digital library
- dblp+Citations v11 dataset은 4.1 mln paper, 245 mln authors, 16k venues, 36.6 mln citations 포함
- supervised label 없으며 (unlabeled), citation info가 interaction data로 사용될 수 있음
4.2 SPRD based datasets
- Scholarly Paper Recommendation Dataset (SPRD): 2000부터 2006년까지 dblp에 수록된 cs 분야들의 50명 저자들의 저작 정보
- ACM Digital Library에서 가져온 100k candidate papers와 함께 citations, references 포함됨
- paper의 relevance assessment도 포함되어 있음 (labeld)
- senior researcher만의 데이터인 SPRD_Senior도 있음
4.3 이후는 추후
5. Evaluation
는 추후
6. Changes compared to 2016
는 추후
7. Open Challenges and Objectives
7.1 Challenges Highlighted in Previous Works
7.1.1 Neglect of User Modelling
- input: keyword specification(recommendation system이 search engine에 더 가까워짐)과 utilising user profile 사이의 trade-off
7.1.2 Focus on Accuracy
- users' satisfaction이 accuracy와 같은가?
- 1/4 정도만 accuracy 뿐만 아니라 MMR을 넣어서 diversity에 대한 검증 하고 있음
7.1.3 Translating Research into Practice
- 연구가 실제 서비스까지 이어지지 않음
7.1.4 Persistence and Authority
- 연구가 실제 서비스까지 이어지지 않은 이유 중 하나는 persistence and authority
- persistence는 잘 모르겠고, authority의 경우, 가장 많은 multiple paper publish한 research group의 paper 갯수는 3개에 불과하여 authority 부족하다는 평
7.1.5 Cooperation
- 선행연구를 뭔가 참고하고 거기서 쌓아올리는 일이 적었음
- 다른 research group 간의 협업도 적었음
7.1.6 Information Scarcity
- 연구자들이 information 충분히 안 내놔서 reproducibility에 문제가 생김
- 단 한건의 논문도 paper code(e.g. GitHub) 내놓지 않음(We did not find a single paper’s code e.g. provided as a link to GitHub.)
이게 말이 되냐ㅋㅋㅋㅋㅋㅋㅋㅋ 얼탱이가 빠져서 헛웃음이 나오네ㅋㅋㅋㅋ
7.1.7 Cold Start
- 새로운 유저의 정보가 없어서 cold start 문제가 생기고, relevant recommendation이 힘들어짐
- DL 사용한 system이 극복할 수 있을 것으로 보임
7.1.8 Sparsity or Reduce Coverage
- user-paper matrix같은 sparse matrix는 infrequently rated paper의 relevancy 학습을 어렵게 함
- 이 문제 역시 DL 사용으로 커버할 수 있을 거라고 함
7.1.9 Scalability
- 1 mln 규모에서 학습한 모델들은 있지만 real world는 그보다 훨씬 더 규모가 큼. 이런 scalability와 후행하는 computational cost에 대해 다룬 논문 적음
7.1.10 Privacy
- personalised paper recommendation, collaborative filtering approach에서 발생할 수 있음
7.1.11 Serendipity
- collaborative filtering에서 등장할 수 있는데, 완전 relevant하지 않은 것들도 섞어주면 recommendation system에 대한 평가가 올라감
- clearly relevant : serendipitous의 비율이 중요
7.1.12 Unified Scholarly Data Standards
- dataset 생김새가 중구난방이라 다같이 쓰면 문제 생기는데, data preparation 언급한 거 거의 없음
7.1.13 Synonymy
- 동음이의어 문제는 Doc2Vec이나 BERT같은 embedding method로 해결가능
7.1.14 Gray Sheep
- user가 reference recommendation 결과에 대해 일관된 반응이 없는 것
7.1.15 Black Sheep
- 어떤 reference recommendation에 대해서도 agree/disagree 하지 않는 것
7.1.16 Shilling attack
- collaborative filtering approach에서 일어날 수 있는 일로, user가 authored paper를 rating하고, 다른 recommendations는 negatively rating하면서 manually enhance visibility할 수 있는 위험성
- 뭐 더 이상 중요한 problem같지는 않다고 함
7.2 Emerging Challenges
8. Conclusion
