SimCSE: Simple Contrastive Learning of Sentence Embeddings (EMNLP 2021)
- dropout 통과하는 거 code 추가
Abstract
- SimCSE: sentence embedding을 advance하는 simple한 contrastive learning framework
- 이전에 있었던 것들: SBERT (Reimers and Gurevych, 2019) 등
- unsupervised approach: input sentence에서 자신 with noise을 predict함 contrastive objective + standard dropout as a noise
- supervised learning하고 비슷한 성능
- dropout이 마치 data augmentation처럼 작동하고, dropout이 없으면 representation 학습이 잘 되지 않음
- supervised approach: Natural Language Inference dataset을 cl framework에 포함시킴 ("entailment"를 positive pair로, "contradiction" pair는 hard negative pair로)
- STS dataset에서 BERT-base를 이용해 실험한 결과, SoTA 갱신
- CL objective가 pretrained embeddings의 anisotropic space를 좀 더 uniform하게 만들고, supervised signal이 있다면 positive pair를 좀 더 잘 align할 수 있음
- "anisotropic space를 uniform하게 만든다" == feature distribution이 원래는 고깔 모양이었던 것을 구 형태로 잘 펼쳐준다
- 내맘대로 Contribution:
- simple한 semi supervised approach: next sentence prediciton보다도 더 simple한데도 더 효과적임!
- sentence embedding evaluation 기준 정의: 이후 diffCSE 등에서도 요긴하게 쓰이는 criteria가 됨
1 Introduction
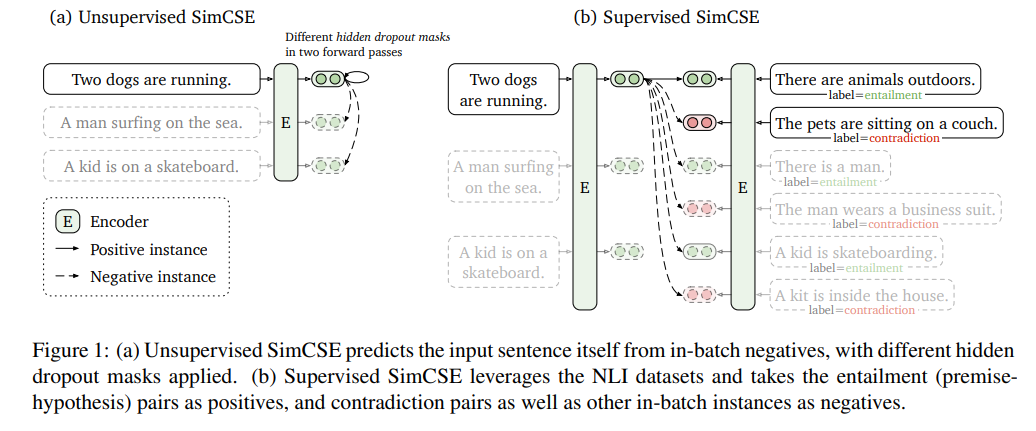
- universal sentence embeddings 방안 매우 중요, 여기에서는 PLM + contrastive learning으로 SoTA sentence embedding method 만들 수 있다는 것을 보여줌
- unsupervised approach: 엄청나게 simple한 approach
- positive pair: 같은 문장에 한 번씩 standard dropout을 거친 2개의 문장
- negative pair는 같은 mini-batch 안의 다른 문장들
- 이렇게 간단한 방법이 NSP나 discrete data augmentation (word deletion, word replacement etc.) 보다 나음
- dropout이 마치 data augmentation처럼 작동하고, dropout이 없으면 representation collapse가 일어남
- supervised approach:
- 원래는 3-label (entailment, neutral, contradiction)인 natural language inference dataset을 이용
- positive pair: entailment
- negative pair: contradiction
- NLI dataset 이용하는 게 특히 더 효과적임을 다른 dataset 통해서 보여줌
- analysis: alignment와 uniformity를 embeddings quality 측정에 사용
- positive pair 사이에서의 alignment
- whole representation space에서의 uniformity
- SimCSE는 dropout 통해 improves uniformity & avoids degenerated alignment -> improves expressiveness of representations
- NLI training improves alignment between positive pairs & produce better sentence embeddings
- antisotropy에 대한 얘기: CL objective flattens SVD of sentence embedding space -> improves uniformity
- evaluation
- semantic textual similarity (STS) task는 SoTA 갱신
- transfer task에섣는 competitive performance
- evaluation settings를 literature review하고 하나로 합침 (appendix 참조)
2 Background: Contrastive Learning & 8 Related Work
- Contrastive Learning이란?
- "pulling semantically close neighbors together and pushing apart non-neighbors"
- contrastive learning에 필요한 dataset D
, 와 는 semantically related pair - training objective
와 를 각각 와 의 representation이라고 하면, batch N에서의 training objective는 다음과 같음:
: temperature hyperparameter
: cosine similarity (본 논문에서는 BERT 또는 RoBERTa의 encoded representation을 cosine similarity에 사용
Positive instances
- image는 crop, flip, distortion, rotation 등으로 쉽게 transformation 가능
- 자연어는? 문맥 때문에 단어 바꿔치기 같은 transformation이 잘 되지 않음
- 이전 연구의 trend 1: positive pair ()를 보통 supervised dataset에서 구축하였음 (SBERT), LM finetuning
- 이전 연구의 trend 2: LM은 어쩔 수 없고, 거기서 나온 embedding을 잘 가공해보자! (BERT-Flow, BERT-Whitening)
Alignment and uniformity
- alignment와 uniformity는 contrastive learning의 key properties
- representation quality 계산을 위한 metric으로 사용될 수 있음
- alignment: positive pair 사이의 feature가 얼마나 가까운지
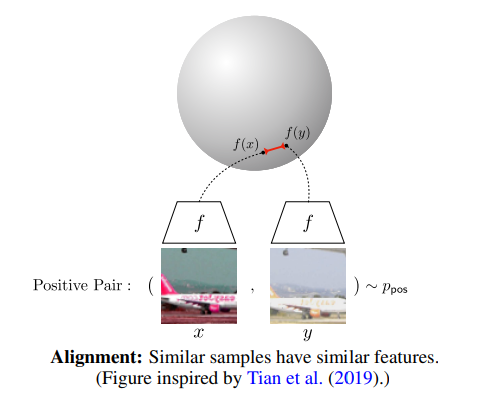
- uniformity: 공간(hyperspace)상에서의 feature distribution

- calculation
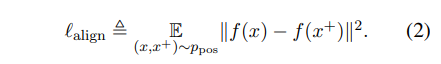
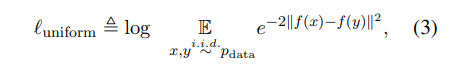
def lalign(x, y, alpha=2): # alignment
return (x - y).norm(dim=1).pow(alpha).mean()
def lunif(x, t=2): # uniformity
sq_pdist = torch.pdist(x, p=2).pow(2)
return sq_pdist.mul(-t).exp().mean().log()3 Unsupervised SimCSE
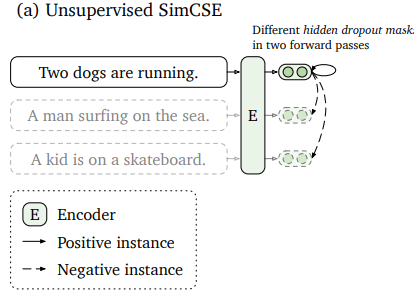
- positive pair ()의 구축: transformer 모듈의 dropout을 이용 (attention layer 거친 후 & FFN에도 있는 dropout)
() where is a random mask for dropout - 따라서, contrastive learning training objective는 다음과 같음:
Dropout noise as data augmentation
- 이러한 dropout은 data augmentation의 일종으로 볼 수도 있음
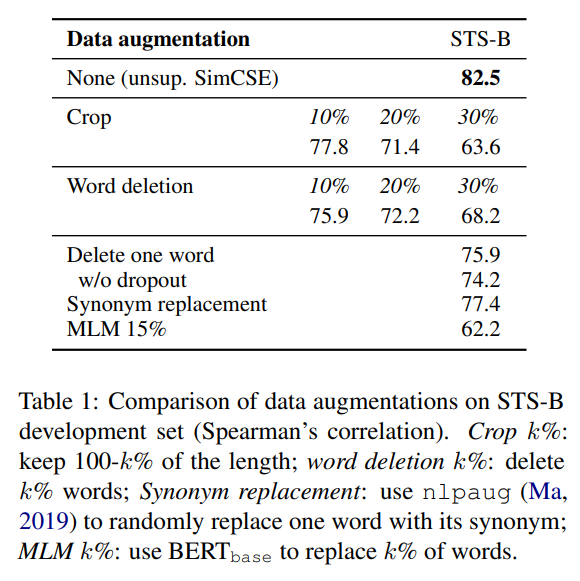
- unsupervised contrastive learning의 성능을 비교하기 위해 STS-B development set discrete augmentation (crop, word deletion, word replacement 등) 해서 BERT-base에 finetuning함
- 단, 실험의 dataset에는 STS-B가 들어가지 않음
- discrete augmentation보다 simple dropout 적용한 게 performance가 낫더라
- self-prediction training objective 측면에서 봤을 때, unsupervised contrastive learning이 NSP보다 낫더라
Why does it work?
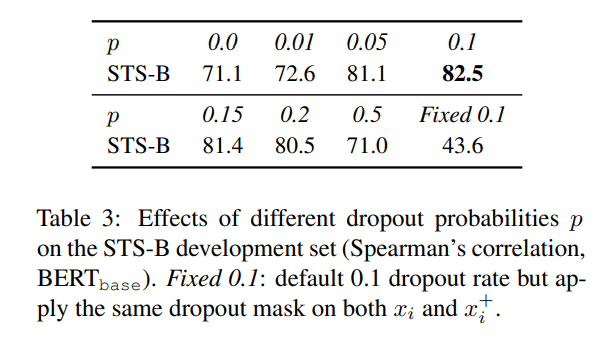
- dropout rate 다르게 줘서 실험해봤을 때, default인 p = 0.1이 제일 performance가 낫더라
- 재밌는 점은, p = 0 (no dropout), fixed p = 0.1 (dropout rate가 0.1인데, 2개 embedding에 "똑같은" dropout mask를 적용)은 본질적으로 같은데(encoded sentence embeddings 2개가 똑같다는 점에서), 후자에 performance degradation
- "왜?"가 없음.. 흑..
- 10 step마다 uniformity score를 계산했는데, 모든 strategy가 uniformity는 향상되지만, fixed 0.1과 no dropout은 alignment가 점점 박살남
- SimCSE는 alignment가 계속 향상되는데, dropout noise가 그 이유인 것으로 생각할 수 있음
- delete one word는 alignment 향상 있긴 했는데 uniformity는 조금 상승해서 결국 SimCSE에 비해 underperform
- 어쨌거나 pretrained model checkpoint가 중요: initial alignment를 정하기 때문에!
4 Supervised SimCSE
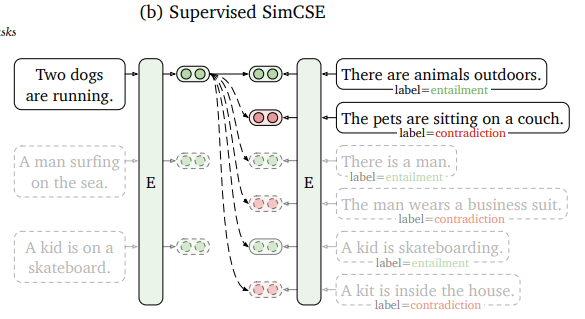
- 이미 존재하는 dataset을 한 번 사용해서 alignment를 향상해보자!
- Natural Language Inference datasets 써서 (entailment, neutral, contradiction) label 이용해 positive & negative pair 구성
Choices of labeled data
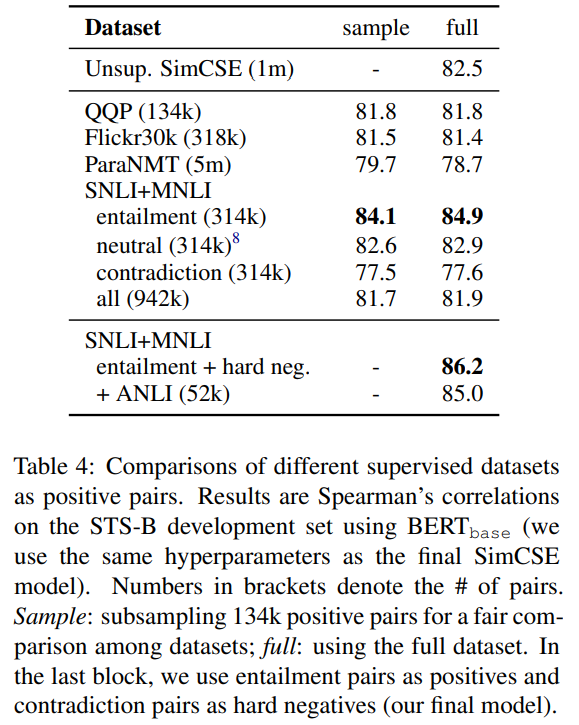
- 데이터셋 여러 개 (QQP, Flickr30k, ParaNMT, SNLI+MNLI) 실험해봤는데, SNLI+MNLI의 NLI entailment pairs가 performs best
- 왜냐면 두 문장의 overlap이 적어야 많이 배우는데, SNLI+MNLI (entailment pairs)는 overlap이 39%밖에 안 되는데, 다른 것들은 50~60%가량
Contradiction as hard negatives
- NLI에서는 contradiction 있으므로 unsupervised와는 달리 "명백하게" negative pair 구축 가능
( pair 에서 triple로 확장 - 따라서 training objective 도 다음과 같이 변형됨
- hard negative를 추가해줘서 성능 향상 있었음
- 다른 NLI 데이터셋을 추가하려는 노력이나 unsupervised SimCSE와 합치려는 노력 있었는데 잘 되진 않았음
- 왠지 supervised SimCSE에 unsupervised SimCSE를 통합하려고 했었던 것 같은데 성능 잘 안 나오니까 다른 chapter로 구성한 느낌 + 성능이 어떻게 나왔는지까지 첨부했으면 좋았을텐데
5 Connection to Anisotropy
-
anisotropy란? <-> isotropy
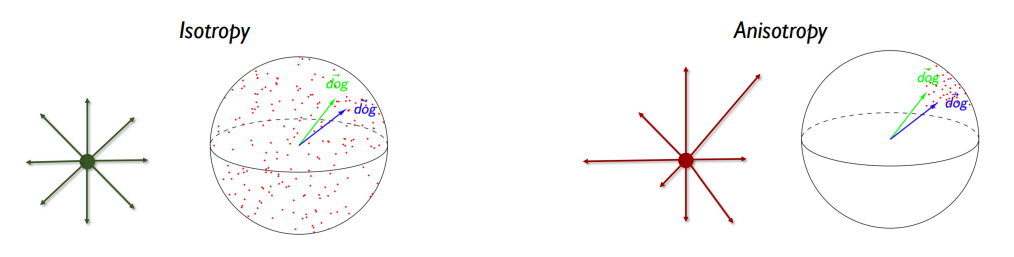
각 단어가 잘 구별되려면 isotropic해야 (공간 상에서 각 방향으로 uniform하게 분포) 하는데, 사실상 anisotropic함 (cone 모양으로 모임)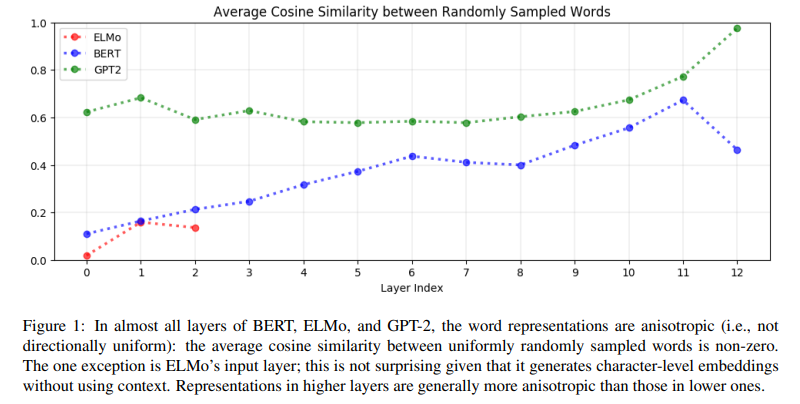
Ethayarajh (2019) 에서는 random words의 word embeddings가 cosine similarity 높아도 contextualized meaning이 있으니 괜찮다고 함. 여기에서는 word embedding의 similarity가 아니라 sentence embedding의 similarity 관점에서 접근 -
anisotropic problem 완화 방법
- post-processing (dominant principal components 제거, isotropic distribution으로 처리)
- 본 논문에서는 contrastive objective 또한 anisotropic problem을 줄일 수 있다고 밝힘
-
anisotropy problem: uniformity와 연관되어있는데, contrastive learning은 negative pair를 밀어내니까 uniformity가 증대됨
6 Experiment
6.1 Evaluation Setup
- 7 semantic textual similarity (STS) tasks: STS 2012-2016, STS Benchmark, SICK-Relatedness
- fully unsupervised, STS training set 사용 X
- supervised SimCSE의 경우에도 STS dataset 말고 다른 dataset 사용해서 학습하였음
Semantic textual similarity tasks
- unified setting in evaluating sentence embeddings 제시
Training details
- unsupervised SimCSE: English Wikipedia에서 뽑아온 10k개 sentences
supervised SimCSE: MNLI+SNLI datasets 314k samples
6.2 Main results
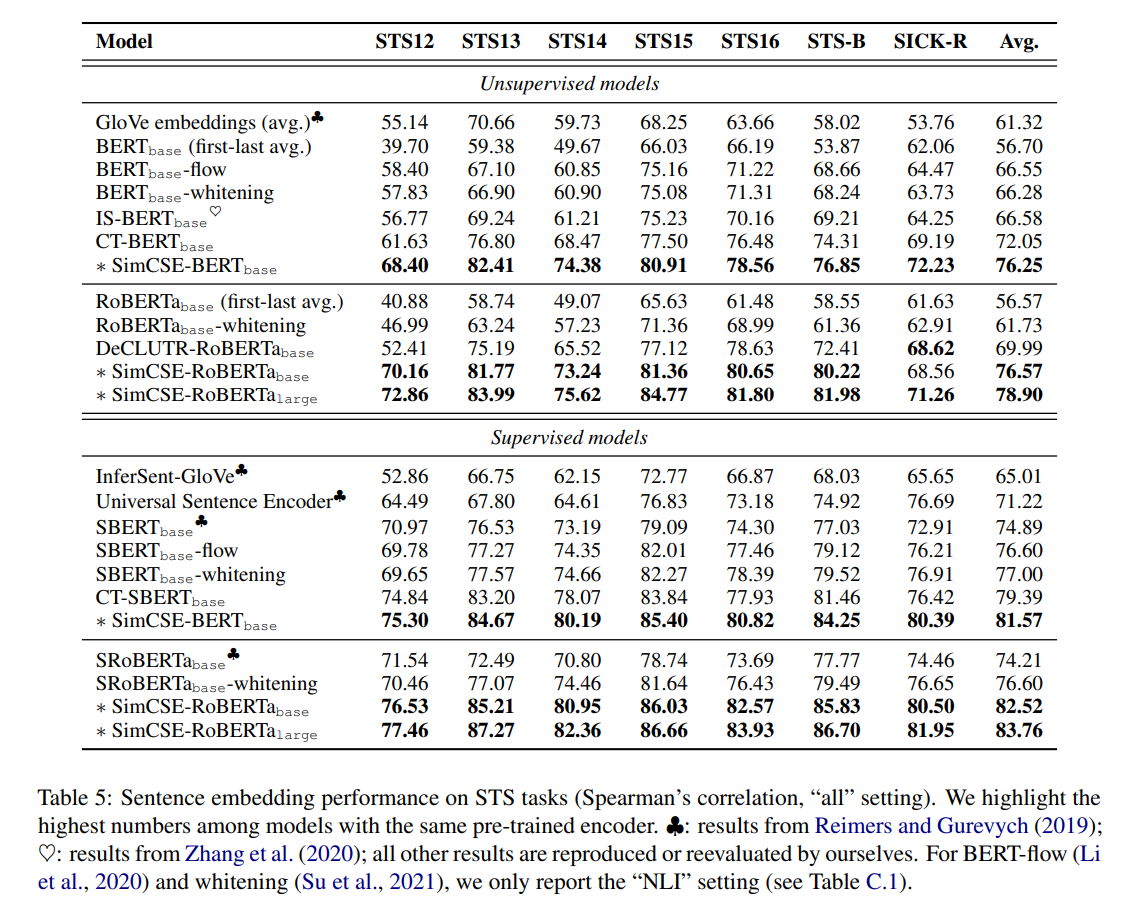
- Baselines
- BERT-flow, BERT-whitening: post-processing methods
- IS-BERT: contrastive learning utilizing Mutual Information Maximization
- DeCLUTR: 같은 문서에서 뽑아온 문장을 positive pairs로 간주
- CT: 같은 문장을 2개 encoder에 각각 통과시켜서 aligning 진행
- 여기에서는 Spearman correlation 사용: Pearson은 선형관계를 측정하고, Spearman은 단순 관계만 측정(값이 0이라 하더라도 의미 있는 관계 있을 수 있음)
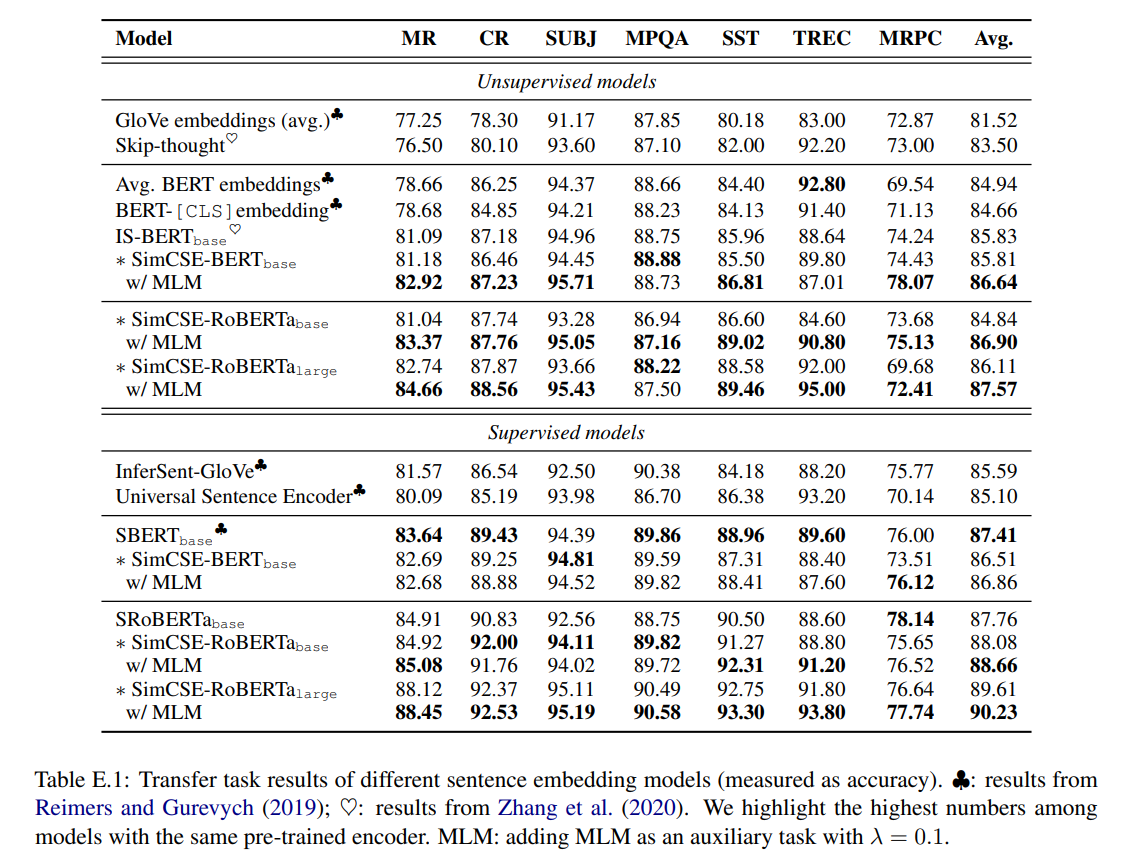
- unsupervised든 supervised든 성능 비약적 향상
- table 5에서는 BERT, RoBERTa에 SimCSE 적용한 것만 보여주지만, 여기에 MLM task 추가하면 성능 더 향상 가능: MLM을 auxiliary task로 한 번 더 자근자근 밟아주면서 catastrophic forgetting을 방지할 수 있음
6.3 Ablation Studies
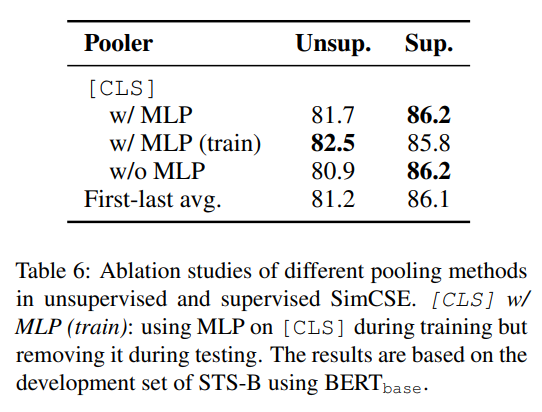
Pooling methods
- 이전 연구에서는
[CLS]token 사용하는 것보다 1st, last layer의 average embeddings 사용하는 게 더 낫다고 밝힘. 그런데 여기서는 아니네?
Hard negatives
- soft negatives와 hard negatives에 다른 weight을 주어서 실험해봤는데, soft negatives와 hard negatives의 weight이 같을 때 가장 좋은 성능
- neutral hypotheses도 hard negatives에 같이 넣어서 실험해봤는데 그닥
7 Analysis
Uniformity and alignment
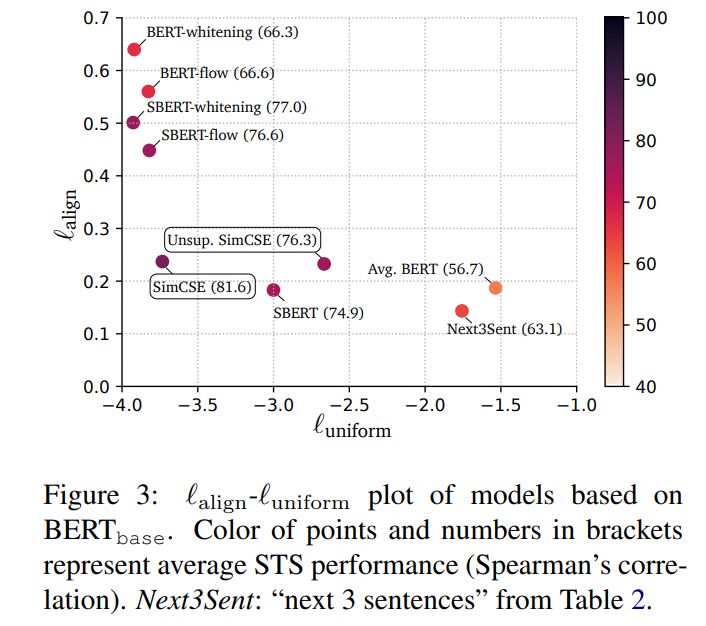
- alignment, uniformity 낮을수록 better performance
- (1) pretrained embedding은 good alignment, bad uniformity == embeddings highly anistropic
- (2) BERT-flow, BERT-whitening같은 post-processing이 uniformity 향상, alignment degeneration
- (3) unsupervised SimCSE는 pretrained embeddings의 uniformity 향상 + good alignment
- (4) supervised SimCSE는 alignment 향상
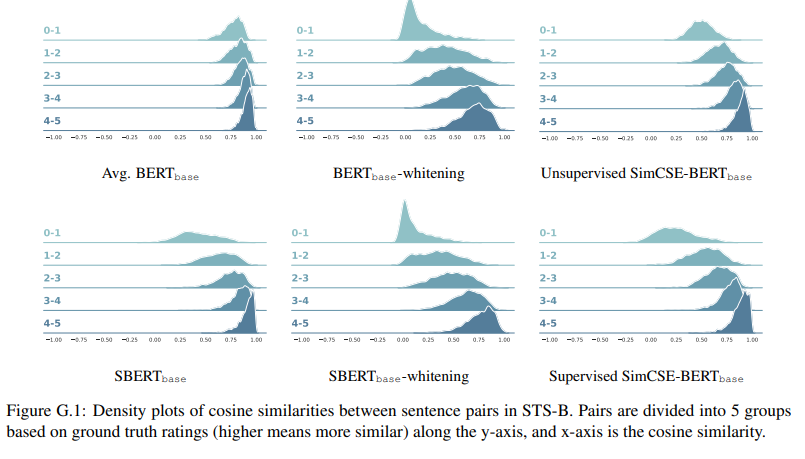
- appendix G: PLM vanilla보다 cosine similarity의 확연한 차이 & 기존 contrastive learning (BERT-whitening) 보다는 lower variance
Qualitative comparison
- Flickr30k dataset에서 random sentence를 query로 넣어서 비슷한 문장 retrieve하는 task 했을 때, SBERT보다 SimCSE가 나았음
감상
- 장점: 아 analysis 진짜 잘 됐다, evaluation(이라기보다는 다른 모델과의 비교)이 진짜 힘들었겠다
- 아쉬운 점: dropout = 0과 fixed dropout을 재미있다고 얘기했는데 그것에 대한 설명이 아예 없다는 점
CL loss in NLP
# MultipleNegativesRankingLoss from SBERT
def __init__(self, model: SentenceTransformer, scale: float = 20.0, similarity_fct = util.cos_sim):
"""
:param model: SentenceTransformer model
:param scale: Output of similarity function is multiplied by scale value
:param similarity_fct: similarity function between sentence embeddings. By default, cos_sim. Can also be set to dot product (and then set scale to 1)
"""
super(MultipleNegativesRankingLoss, self).__init__()
self.model = model
self.scale = scale
self.similarity_fct = similarity_fct
self.cross_entropy_loss = nn.CrossEntropyLoss()
def forward(self, sentence_features: Iterable[Dict[str, Tensor]], labels: Tensor):
reps = [self.model(sentence_feature)['sentence_embedding'] for sentence_feature in sentence_features]
embeddings_a = reps[0]
embeddings_b = torch.cat(reps[1:])
scores = self.similarity_fct(embeddings_a, embeddings_b) * self.scale
labels = torch.tensor(range(len(scores)), dtype=torch.long, device=scores.device) # Example a[i] should match with b[i]
return self.cross_entropy_loss(scores, labels)
#### or simply, ####
from sentence_transformers import SentenceTransformer, losses, InputExample
train_loss = losses.MultipleNegativesRankingLoss(model=model)
4개의 댓글

contrastive learning가 cv에 적용되는 방법은 알았는데, dropout을 통해 nlp에 쉽게 적용하는 방법을 알게 되어 흥미로웠고 한번 실행해보고 싶은 생각이 들었습니다 ~~ 감사합니다 ! 😊

dropout을 이용해서 contrastive 학습을 한 게 아이디어가 신선했습니다. NLP 쪽에서 augmentation하는 게 한정적이었는데, 저도 사용해봐야겠네요..!! 그리고 논문이 analysis가 풍부하게 있어서 정말 좋습니다.

저는 현재 multilingual 쪽으로 연구를 해보고자 하는데, 거기에서도 각 언어별로 동일한 임베딩 공간에 위치시키는 다양한 시도들이 있었습니다. 저도 그런 쪽으로 연구 중인데 이를 해결하기 위해 contrastive learning을 적용해봐야겠다는 생각을 하게 됐습니다. 좋은 논문 발표 감사합니다 !
intro까지 보았을때는 unsupervised와 supervised를 구분해서 연구를 진행한 이유에 대한 의문점이 해소되지 않았었는데 해당 부분에 대해서 본 발표를 통해 알 수 있어서 유익한 시간이었습니다 ! 좋은 발표 감사합니다