P-Tuning v2: Prompt Tuning Can be Comparable to Finetuning Universally Across Scales and Tasks (ACL 2021)
Prompting
1줄 요약: 앗! prompt tuning, finetuning보다 낫다!
- 이해를 돕기 위한 PPT: Pre-trained Prompt Tuning for Few-shot Learning
Gu, Y., Han, X., Liu, Z., & Huang, M. (2021). Ppt: Pre-trained prompt tuning for few-shot learning. arXiv preprint arXiv:2109.04332.
Abstract
- Prompt Tuning의 장점: memory와 storage를 아낄 수 있음
- 이전까지 Prompt Tuning의 한계
- normal-sized pretrained model에서는 성능이 잘 안 나옴
- 어려운(hard) labeling task 잘 안 됨 (범용성 미비)
- 본 논문의 contribution
- "properly optimized prompt tuning" 해서 모델 크기와 task에 관계없이 범용적으로 finetuning과 비슷한 수준의 성능을 달성 + 0.1%-3% trainable parameter만으로!
1 Introduction & Background
- pretrained LM이 나온 후의 경량화 방안들:
- (1) PLM + layers, (2) in context learning (a.k.a. prompt designing, gpt-3, chatGPT 등), (3) parameter efficient tuning (prompt tuning)
- 본 논문은 parameter efficient tuning임
- prompting 이란 무엇이냐?
- 약간이나마 formal 한 정의: parameter를 freezes 하고 prompt가 LM에 query를 던져서 ouput 이끌어내는 것
- GPT-3나 chat-GPT처럼 task-specific tuning이 없어도 유저가 지시(instruction) + additional few examples만 줘서 LM에서 결과물 뽑아내는 것
- 그런데 그 이전에는, ELMo나 BERT같은 pretrained model (not only autoregressive, also autoencoding)에서도 prompting 하려 했던 시도들 있음
Mozart was born in ___.이라는 prompting은 Mozart의 DoB를 뽑아내기 위해 cloze question style로 치환한 것임!
- prompting이 finetuning에 대해 가져가는 장점은 무엇이냐?
- finetuning은 model parameter 전체를 update == parameter & optimizer state까지 몽땅 저장 → too heavy!
- finetuning은 task 때마다 모델 load 해야 하는데 그거 너무 무겁고 귀찮아서 어떻게 하냐?
- prompting은 training 전혀 필요 없고, LM 1개 parameter만 저장해놓으면 범용적으로 쓸 수 있음!
- prompt tuning이란?
- continuous prompts를 tuning하는 것:
하술할 Liu et al. (2021); Lester et al. (2021) 처럼 trainable prefix(또는 continuous embedding 마치 [CLS]과 같은)을 더하는 것 + 그 prefix나 embedding만 학습시킴
- continuous prompts를 tuning하는 것:
- 이전 prompt tuning method의 한계는? (Liu et al., 2021; Lester et al., 2021)
- model size가 10 billion보다 작을 때 (Lester et al., 2021에서는 BERT-large에서만 finetuning outperform) 는 finetuning보다 못함
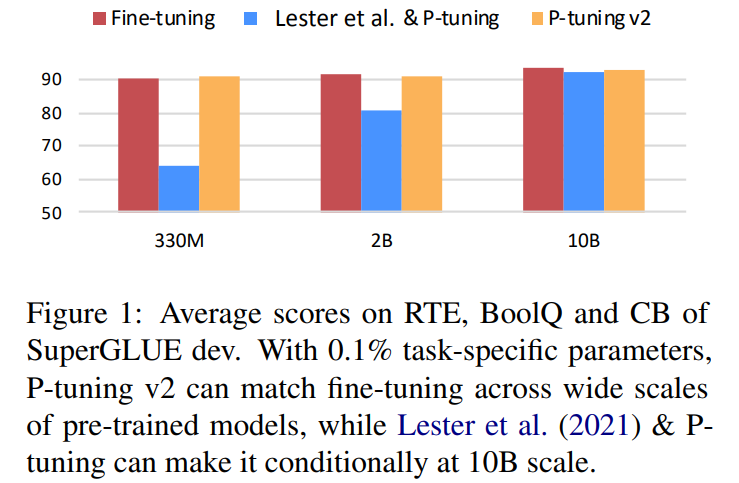
- '어려운(hard)' sequence labeling task (e.g. extractive question answering, NER) 에서는 성능 저조
- model size가 10 billion보다 작을 때 (Lester et al., 2021에서는 BERT-large에서만 finetuning outperform) 는 finetuning보다 못함
- Contribution
- properly optimized prompt tuning can beat finetuning universally across model scales & tasks
- 이전 연구의 prompt tuning을 좀 더 발전시켜서 적용: input sequence에만 prefix 넣었는데, 본 논문에서는 모든 layer에 prefix 들어감
- 이전 연구에서는 'small models'와 'easy tasks'에서 prompt tuning이 finetuning을 outperform함을 보여주었다면, 본 논문에서는 prompt tuning > finetuning이 universal할 수 있음을 보였음
Related Works
- AutoPrompt, discrete prompting (Schick and Schutze, 2020) 등
-
AutoPrompt
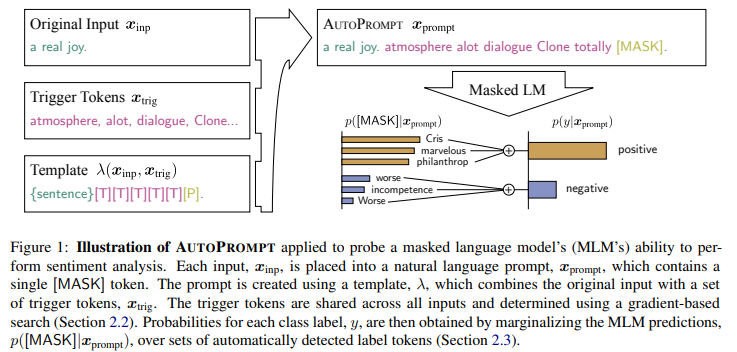
- 이건 continuous tokens (prefix 같은) 말고 discrete tokens (실제 단어 tokens) 를 나열함으로써 prompt engineering 시도
- discrete tokens는 paraphrasing, mining 등 manually 구축됨
- discrete tokens 사용의 단점:
- real language token의 뉘앙스 문제, continuous tokens 두는 게 문맥 파악 내지 문맥 안의 특정 단어들 강조 가능 등등..
__(x) performed until his death in __(y): 앞의 blank가 남자라면 ok이지만, 앞의 blank가 여자라면....?
- finetuning보다 오히려 부족한 성능
-
discrete prompting (iPET)
- input: X (some kind of context)
- prompt tokens:
It is [MASK]etc. - LM에 들어가는 input & output:
X. It is [MASK]에서[MASK]를 예측 - 여기서 고안된
verbalizer가 많이 사용되었음

- finetuning은 너무 heavy해!: task-specific해서 storage 너무 많이 잡아먹어!
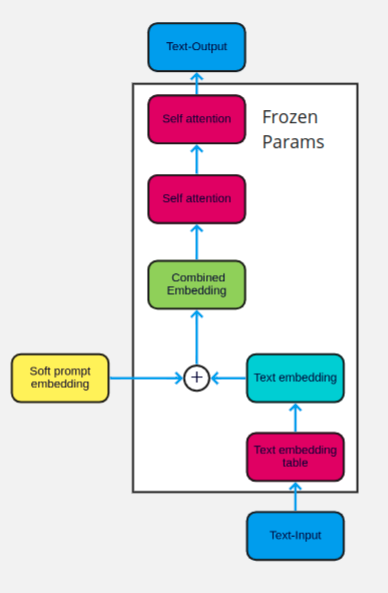
- lightweight alternative: prompt tuning하는데, 단, sequence 앞에 "prefix"라고 하는 token (마치 [CLS], [SEP]처럼)을 집어넣어서 걔만 학습시키자! ("prefix-tuning")
- finetuning에 비해 parameter 수가 1/1000 로 줄었음
- prefix tuning이란 건 prompting에서 영감받았다!
- experiment: GPT-2, BART 에서 진행, 특정 조건에서 finetuning을 comparable 내지 outperform
- 그런데 그 특정 조건의 task 라는 게..: table-to-text (gpt-3), summarization (bart)
- 데이터 다 썼을 때(full-data setting)에서는 table-to-text에서는 finetuning보다 조금 더 좋은 성능, summarization에서는 조금 못한 성능
- 데이터를 조금만 썼을 때(low data setting, 50~500 samples)에서는 finetuning보다 두 task 다 나은 성능
- unseen topic에 대해서는 둘 다 finetuning보다 나은 성능
- prompt tuning의 새로운 장을 열었음!
- 해당 연구진들이 말하는 "prompting"과의 차이점: prompting은 free parameters, do not correspond to real tokens (gpt-3도 [end] token 있지 않나?)
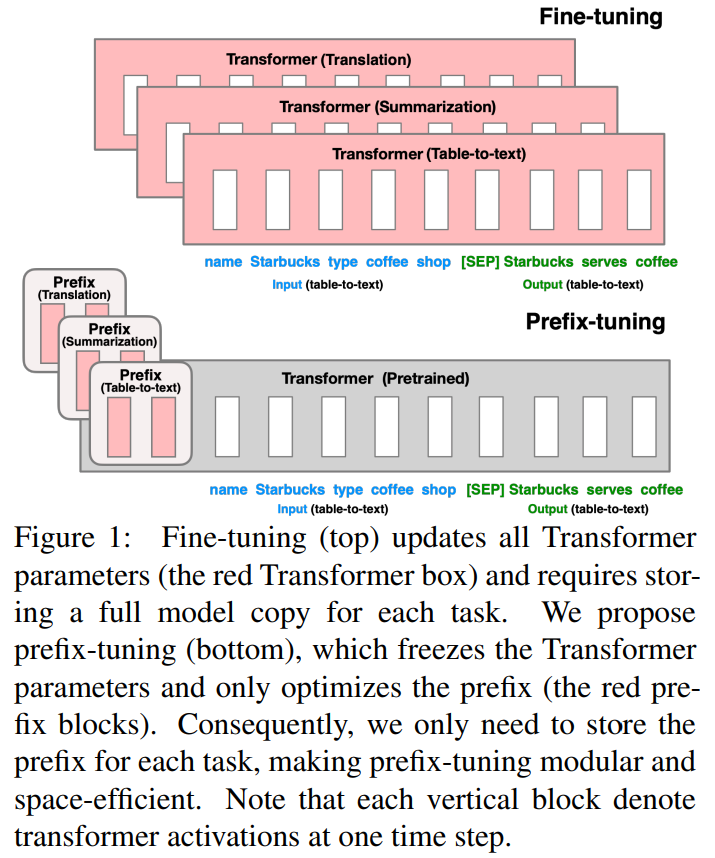
- (Li & Liang, 2021)과 대동소이
- BERT(base, large), BART, RoBERTa 사용, dataset은 T-REx, Google-RE, COnceptNet 사용
2 Preliminaries
- NLU tasks
- simple classification tasks: classification over label space, GLUE & SuperGLUE
- hard labeling tasks: classification over a sequence of tokens, NER & extractive question answering
- prompt tuning: 생략, 위에서 다 얘기했음
3 P-Tuning v2
3.1 Lack of Universality
- Lack of universality across scales
model size가 10B보다 크면 finetuning outperform하긴 하는데, 10B 밑의 모델만 해도 BERT family 다 해당되고, 범용적으로 쓰이는 LM들 다 들어가 있는데 prompt tuning이 large model에서 superiority를 가져간다 한들 대체 무슨 의미?
- Lack of universality across tasks
sequence tagging 같은 건 iPet의 verbalizer같은 것으로는 해결이 매우 힘듦
3.2 Deep Prompt Tuning
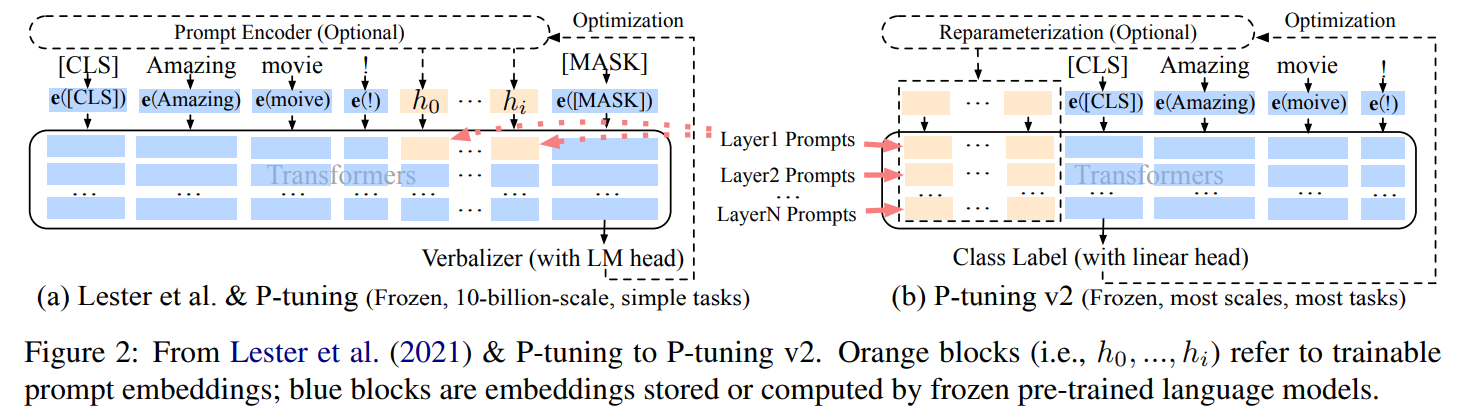
- 이전 논문의 prompting 모양새
- Lester et al. (2021); Liu et al. (2021) 에서 prompts가 input embedding에만 들어감
- challenges:
- tunable parameters 너무 적음
- model prediction layer까지 대체 거리가 얼마인데 input embedding에만 prompting 하면 그 역할이 다 희석돼버림
- 본 논문의 개량점
- Lester et al. (2021); Liu et al. (2021) 과 달리, 모든 layers에 prefixed tokens가 prompting됨
- 그래서 tunable parameter가 0.01%에서 0.1-3%까지 증가: capa는 늘고, parameter-efficiency는 유지
- deeper layer까지 prompting이 들어가서 model prediction에 더 직접적인 영향
3.3 Optimization and Implementation
- Reparameterization
prefix를 transformer에 통과시킨 이후 reparameterization encoder를 통과시켜서 model prediction하게 되는데, 이전에는 이게 보통 MLP였음: 그런데 task와 dataset에 따라서 들쭉날쭉한 성능을 보였음
- Prompt Length
prompt length에 따라서 task의 성능이 달라짐; simple classification task는 shorter prompt(20)에서, hard classification task는 longer prompt(100)에서 더 좋은 성능
- Multitask Learning
본 논문에서 시도되지는 않았지만, 가능은 할 듯
- Classification Head
Schick and Schutze. (2020) 에서 제시된 prediction y를 prompt에 맞게 재구성한 verbalizer의 사용은 지금까지 prompt tuning의 핵심이었음. 그런데 full-data setting에서는 필요없고, sequence labeling에서는 잘 작동 안 하더라.
그래서 P-tuning v2에서는 [CLS] 토큰 앞에 randomly-initialized classification head를 붙였음.
4 Experiments
- NLU Tasks
SuperGLUE datasets + sequence labeling task (NER, extractive Question Answering, semantic role labeling)
- Pre-trained Models
BERT-large, RoBERTa-large, DeBERTa-xlarge, GLM-xlarge/xxlarge
model size ranges in (300M, 10B)
4.1 P-tuning v2: Across Scales

- small scales: BoolQ에서는 finetuning보다 못하기는 한데, 어쨌거나 많은 task에서 finetuning과 비교했을 때 comparable하기는 하고, outperform하는 것도 있었음
- large scales: 확실히 prompt tuning이 fine-tuning에 competitive해짐 with 0.1% of task specific parameters trained
4.2 P-tuning v2: Across Tasks

- SQuAD 2.0 에서 unanswerable questions가 추가됐는데, single-layer prompt tuning 한테는 좀 어려운 task였고, 그를 제외하면 prompt tuning이 comparable & outperform
- multi-task learning도 좋은 성능
4.3 Ablation Study
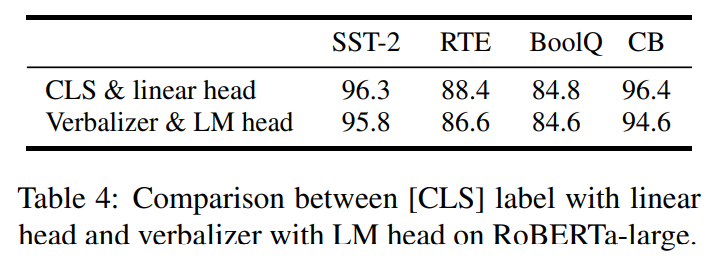
- Verbalizer with LM head vs [CLS] label with linear head
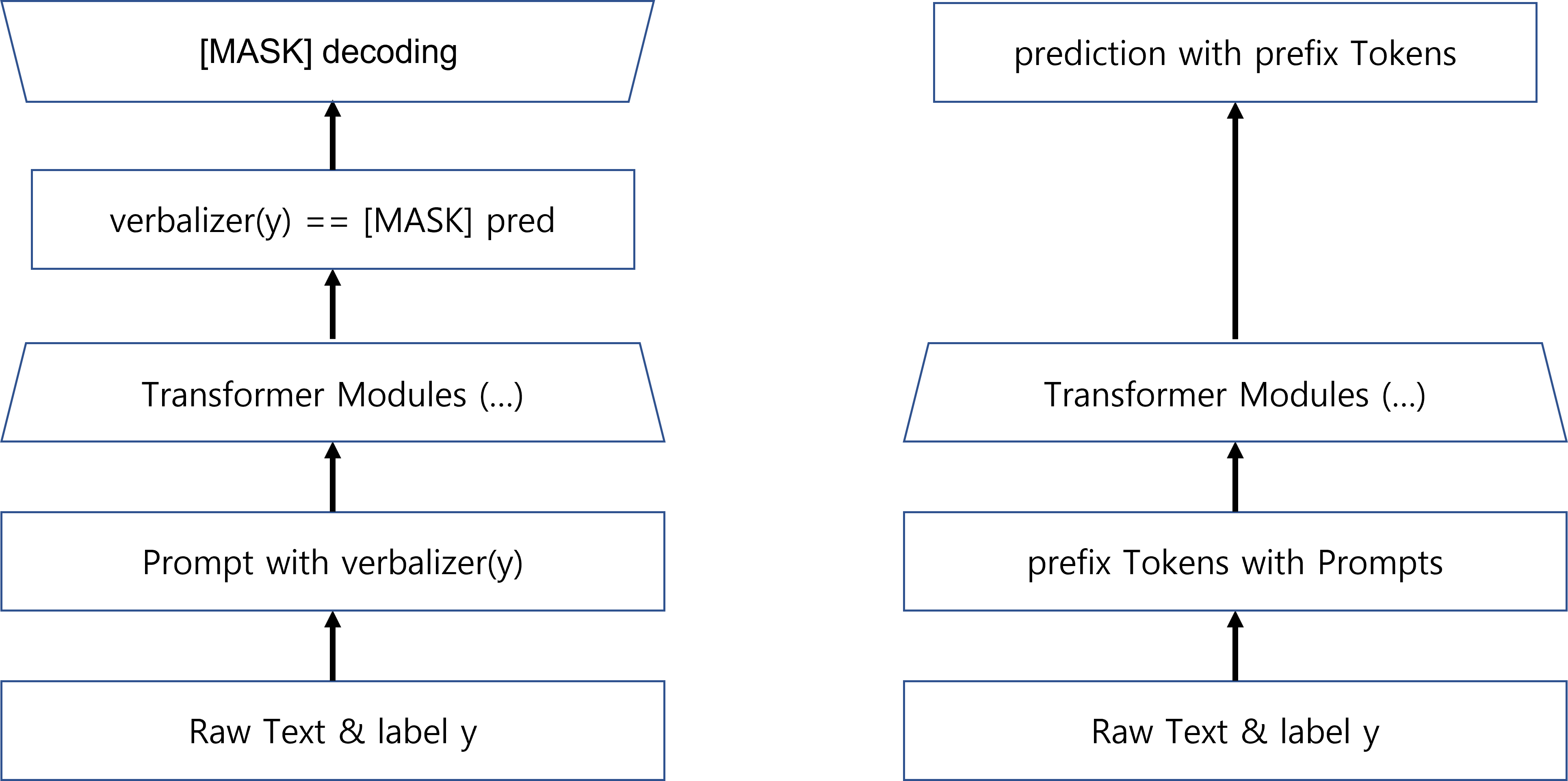
Verbalizer with LM head: [MASK]의 representation에 LM 하나 더 통과시켜서 나오는 것
[CLS] label with linear head: [CLS]의 representation에 linear layer 통과시켜서 나오는 것
Verbalizer with LM head (iPET 논문: Schick and Schutze, 2021) 가 이전까지는 많이 쓰였던 형식이었음. P-tuning v2에서는 대신 linear head를 사용
결과만 놓고 보면 큰 차이는 없음: 그래서 쓰기도 귀찮고 어려운 verbalizer를 굳이 사용할 필요 없다
- prompt depth
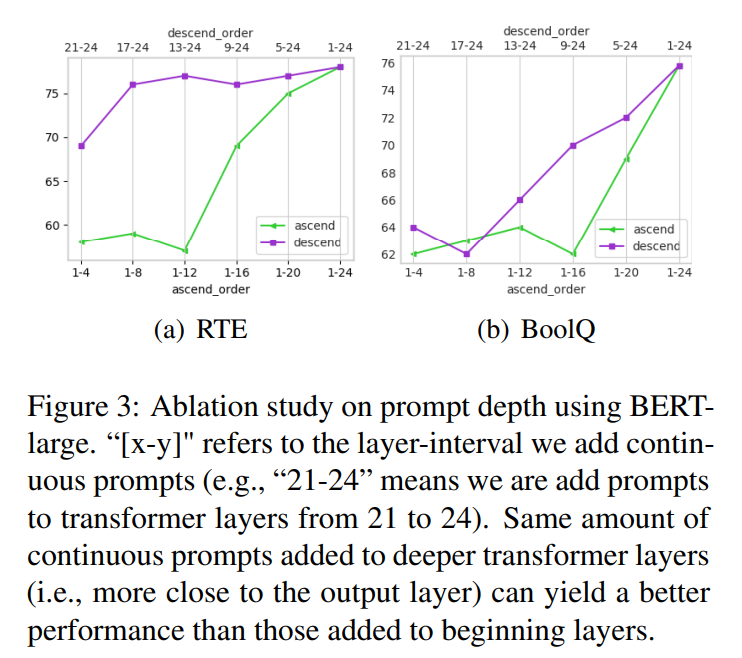
이전 연구와의 또다른 차이점은 중간 layers에도 prompting이 들어간다는 것. 그래서 embedding에 가까운 layer 몇 개(ascending order), 마지막에 가까운 layer 몇 개(descending order)에다가 prompts 넣어서 실험 돌림
결과는, 마지막 몇 개 layer에 prompting하는 게 전체 layer에 prompting하는 것과 흡사한 결과를 낸다는 것
Conclusion
- prompt tuning can be comparable to fine-tuning, universally across model size & tasks
결언
-
왜 p-tuning v2냐?
- "GPT Understands, too (2021)"에서 p-tuning이 제안됨: 단, prompt 앞뒤로 discrete tokens를 두어 input prompt를 만들었기 때문에 본 논문의 continuous prompt와는 다름
-
BERT, roBERTa 죄다 base 말고 large로 해놓고 "universally on model scale"이라고 뻔뻔하게 얘기할 수 있나?
-
후속 연구:
- Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M., & Raffel, C. (2022). Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. arXiv preprint arXiv:2205.05638. (NeurIPS 2022): in-context learning보다 prompt tuning같은 Parameter-efficient fine-tuning이 더 낫다
- Hambardzumyan, K., Khachatrian, H., & May, J. (2021). Warp: Word-level adversarial reprogramming. arXiv preprint arXiv:2101.00121. (ACL 2022): 아 LM head에 decoder 필요 없고 거기서 나온 representation에서 가장 가까운 word embedding 사용하면 된다고ㅋㅋ
- [Jia, M., Tang, L., Chen, B. C., Cardie, C., Belongie, S., Hariharan, B., & Lim, S. N. (2022, November). Visual prompt tuning. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIII (pp. 709-727). Cham: Springer Nature Switzerland.](Jia, M., Tang, L., Chen, B. C., Cardie, C., Belongie, S., Hariharan, B., & Lim, S. N. (2022, November). Visual prompt tuning. In Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part XXXIII (pp. 709-727). Cham: Springer Nature Switzerland.) (ECCV 2022): CV에 DPT 적용
- Tang, Z., Wang, B., & Yao, T. (2022). DPTDR: Deep Prompt Tuning for Dense Passage Retrieval. arXiv preprint arXiv:2208.11503. (COLING 2022): P-Tuning같은 Deep prompt tuning을 이용해 dense passage retrieval 수행 (DPTDR)
- Zhao, Q., Gao, T., & Guo, N. Legal Judgment Prediction Via Legal Knowledge Fusion and Prompt Learning. Available at SSRN 4341600.: DPT를 legal judgement prediction에 접목
-
Li, J., Cotterell, R., & Sachan, M. (2022). Probing via Prompting. arXiv preprint arXiv:2207.01736. (NASCL 2022)
Code
prefix_encoder.py
import torch
class PrefixEncoder(torch.nn.Module):
r'''
The torch.nn model to encode the prefix
Input shape: (batch-size, prefix-length)
Output shape: (batch-size, prefix-length, 2*layers*hidden)
'''
def __init__(self, config):
super().__init__()
self.prefix_projection = config.prefix_projection
if self.prefix_projection:
# Use a two-layer MLP to encode the prefix
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.hidden_size)
self.trans = torch.nn.Sequential(
torch.nn.Linear(config.hidden_size, config.prefix_hidden_size),
torch.nn.Tanh(),
torch.nn.Linear(config.prefix_hidden_size, config.num_hidden_layers * 2 * config.hidden_size)
)
else:
self.embedding = torch.nn.Embedding(config.pre_seq_len, config.num_hidden_layers * 2 * config.hidden_size)
def forward(self, prefix: torch.Tensor):
if self.prefix_projection:
prefix_tokens = self.embedding(prefix)
past_key_values = self.trans(prefix_tokens)
else:
past_key_values = self.embedding(prefix)
return past_key_values- models(중
sequence_classification.py)
class BertPromptForSequenceClassification(BertPreTrainedModel):
def __init__(self, config):
super().__init__(config)
self.num_labels = config.num_labels
self.bert = BertModel(config)
self.embeddings = self.bert.embeddings
self.dropout = torch.nn.Dropout(config.hidden_dropout_prob)
self.classifier = torch.nn.Linear(config.hidden_size, config.num_labels)
for param in self.bert.parameters():
param.requires_grad = False
self.pre_seq_len = config.pre_seq_len
self.n_layer = config.num_hidden_layers
self.n_head = config.num_attention_heads
self.n_embd = config.hidden_size // config.num_attention_heads
self.prefix_tokens = torch.arange(self.pre_seq_len).long()
self.prefix_encoder = torch.nn.Embedding(self.pre_seq_len, config.hidden_size)
def get_prompt(self, batch_size):
prefix_tokens = self.prefix_tokens.unsqueeze(0).expand(batch_size, -1).to(self.bert.device)
prompts = self.prefix_encoder(prefix_tokens)
return prompts
def forward(
self,
input_ids=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
labels=None,
output_attentions=None,
output_hidden_states=None,
return_dict=None,
):
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
batch_size = input_ids.shape[0]
raw_embedding = self.embeddings(
input_ids=input_ids,
position_ids=position_ids,
token_type_ids=token_type_ids,
)
prompts = self.get_prompt(batch_size=batch_size)
inputs_embeds = torch.cat((prompts, raw_embedding), dim=1)
prefix_attention_mask = torch.ones(batch_size, self.pre_seq_len).to(self.bert.device)
attention_mask = torch.cat((prefix_attention_mask, attention_mask), dim=1)
outputs = self.bert(
# input_ids,
attention_mask=attention_mask,
# token_type_ids=token_type_ids,
# position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
# past_key_values=past_key_values,
)
# pooled_output = outputs[1]
sequence_output = outputs[0]
sequence_output = sequence_output[:, self.pre_seq_len:, :].contiguous()
first_token_tensor = sequence_output[:, 0]
pooled_output = self.bert.pooler.dense(first_token_tensor)
pooled_output = self.bert.pooler.activation(pooled_output)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
loss = None
if labels is not None:
if self.config.problem_type is None:
if self.num_labels == 1:
self.config.problem_type = "regression"
elif self.num_labels > 1 and (labels.dtype == torch.long or labels.dtype == torch.int):
self.config.problem_type = "single_label_classification"
else:
self.config.problem_type = "multi_label_classification"
if self.config.problem_type == "regression":
loss_fct = MSELoss()
if self.num_labels == 1:
loss = loss_fct(logits.squeeze(), labels.squeeze())
else:
loss = loss_fct(logits, labels)
elif self.config.problem_type == "single_label_classification":
loss_fct = CrossEntropyLoss()
loss = loss_fct(logits.view(-1, self.num_labels), labels.view(-1))
elif self.config.problem_type == "multi_label_classification":
loss_fct = BCEWithLogitsLoss()
loss = loss_fct(logits, labels)
if not return_dict:
output = (logits,) + outputs[2:]
return ((loss,) + output) if loss is not None else output
return SequenceClassifierOutput(
loss=loss,
logits=logits,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)
4개의 댓글


제가 prompting에 대해 공부가 많이 필요했다는 걸 깨닫게 된 시간이었습니다!!! 얕게만 알고 있었는데, 이렇게 설명해주시니까 제가 어느 부분이 부족한지 알게 되었어요! 공부하고... (언제가 될지 모르ㄱ지만) 질문 폭격갑니다!!

저도 얼마 전에 prefix tuning를 사용하는 논문을 읽었는데, 이 논문을 접하니 좀 더 원론적인 이해가 잘 되었습니다 ^00^