Toward Better Storylines with Sentence-Level Language Models (2020)
summer 2022 Story Generation
목록 보기
1/2
Short Summary
- word-level generation이 아니라 sentence prediction을 시도함
- token-level fluency를 BERT embeddings를 이용함으로써 회피하고, sentence sequence의 coherence에만 집중
- Story Cloze task의 SOTA는 달성하지 못했으나, 유사한 모델들 중에서는 성능이 가장 좋았음
Introduction & Background
- Story Generation Task의 단계:
(1) generation of fluent natural language(not in this study)
(2) generation of a coherent storyline - 이전 연구에서는 조건을 부여함으로써 coherency 달성하려 노력
collaboration between model & human writer, commonsense graph relevant to story plot, images, character roles etc. - 개개의 단어 단위에 집중하지 않음으로써 얻을 수 있는 이점
(1) no capacity to learn fluency
(2) consider more candidates
token-level representation: 000's
sentence-level representation: 0,000's
(3) compact model architectures(using BERT for sentence embeddings)
Model
- Objective: 계산
- 의 candidate은 finite but large set of N valid, fluent sentences - input: sentences are represented by 768 dimension from Bert embeddings
- universal sentence encoder embeddings, weighted mean of BERT using idf weighting 등 사용하였으나 모델 향상에 도움되지 않음
- concat input sentences into one vector()
- resMLP with skip connection() 사용: recurrent, self-attention 모두 더 나은 성능 보여주지 못함 - output: softmax 사용해 번째 sentence(embedding 로 표현)가 다음 문장일 확률 계산
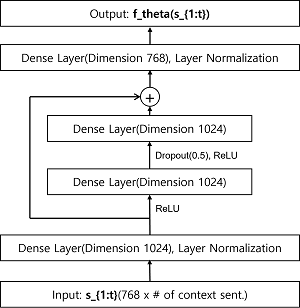
- training: 1개의 정답과 N-1개의 오답으로 만든 set 사용, 오답은 batch안에 있거나, batch 밖에 있는 문장 포함
- CSLoss: context의 sentence()가 고득점 얻는 문제가 발견되어 context sentence에만 부여되는 보조 loss 도입(code에는 'small_context_loss_weight'으로 표현)
Experiments
ROC Stories
- Commonsense & Everyday life stories
- training set: 98k stories, 5 sentences each
validation set: 1.8k stories, (4+1) sentences each, last sentence with 2 options(correct/distractor)

- used for Story Cloze Test
 from https://cs.rochester.edu/nlp/rocstories/
from https://cs.rochester.edu/nlp/rocstories/
ROC Stories Model
- MLP, resMLP(1 residual block) 사용: recurrent, attention이 더 좋은 성능을 보이지는 않았음
- model을 통과한 input과 candidate sentence의 dot product 결과값이 가장 큰 candidate이 next sentence로 결정됨
- candidates while training: 96k 5th sentences - Story Cloze task에서 MLP, resMLP 모두 비슷한 validation accuracy 기록했으나, 선택지 많아진 경우 resMLP가 더 좋은 성능 기록, converge가 더 빠름
Toronto Book Corpus
- long, explanatory, flowery 45 mln sentences including dialogues from 7,000 books
- ROC Stories보다 문장이 짧은 경우 많아 context로 8 sentences 부여
 from https://huggingface.co/datasets/bookcorpus
from https://huggingface.co/datasets/bookcorpus
Toronto Book Corpus Model
- resMLP(2 residual blocks)와 함께 Transformer 모델 사용(4 self-attention layers, 768 hidden size, 2048 filter size, 8 attention heads)
- resMLP는 8 sentence-context를 부여하고 9th sentence를 예측하는 task, Transformer는 이전 문장에서 다음 문장 예측하되(sequence 10 sentence) 9th sentence의 prediction만 evaluation으로 사용
- candidates while training: random 2k from training set
Results
- Story Cloze Task, Ranking on ROC Stories, Ranking on Toronto Book Corpus
Story Cloze Task

- unsupervised alternatives보다 좋은 성능, CSLoss가 성능 높이는 데에 역할을 하였음: task-specific architecture 없이도 높은 성능을 보였음
- word-level language model(GPT-2)보다 좋은 성능
- Story Cloze Task의 SOTA accuracy는 90% 이상이나, 이는 semi-supervised model이고, 본 연구는 unsupervised approach이므로 동일선상에서 비교할 수 없음
- 본 연구는 ROC dataset만을 training에 사용하였고, SOTA 달성한 연구는 Story Cloze Task Dataset 또한 학습에 사용하였다고 밝힘
Ranking Many Sentences on ROC Stories
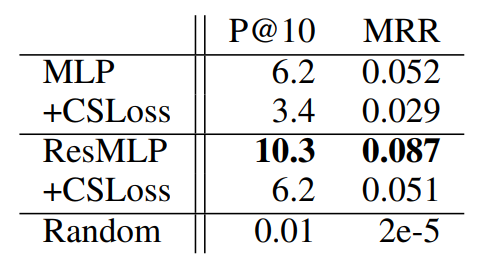
- roughly 100k distractors
- highest Precision @ 10 with resMLP+CSLoss: 10.3%
- CSLoss가 해당 task에는 오히려 성능을 하락시킴
- pretrained embedding(BERT)을 사용함으로써 name, sports 등의 embedding이 유사하게 나타나고, failed to distinguish
Ranking Many Sentences on Toronto Book Corpus
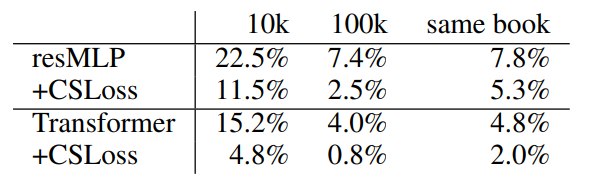
- roughly 100k distractors
- highest Precision @ 10 with resMLP: 7.4%
- 높은 순위에 많이 위치한 문장들은 short & generic
e.g. "he said.", "Yes" - Transformer가 저조한 이유는 잘 모르겠음
Conclusion
- token-level fluency를 BERT embeddings를 이용함으로써 회피하고, sentence sequence의 coherence에만 집중
- future work: two-step generation(selecting a sentence from large set-> refine to fit the context)
Opinion
- 결국 generation이 아니라 sentence selection이 핵심: 10k, 혹은 100k의 candidates는 충분할까?
- ranking의 결과물이 좋은 편인지 좋지 않은 편인지 잘 모르겠다: 다른 모델의 결과도 있다면 좋았을 것
- 계륵 아닌가
- Open Domain에서는 BERT embedding의 한계 때문에 사용하기 힘들고,
- Domain-Specific Model로 사용하기에는 학습 데이터(문장)를 구하기가 힘들 것 같음
학습 데이터가 충분하다면, domain-specific & cost efficient model로 사용할 수 있지 않을까 - word level을 무시했다고 했지만, future work 보면 결국 무시할 수는 없는 듯

multidisciplinary