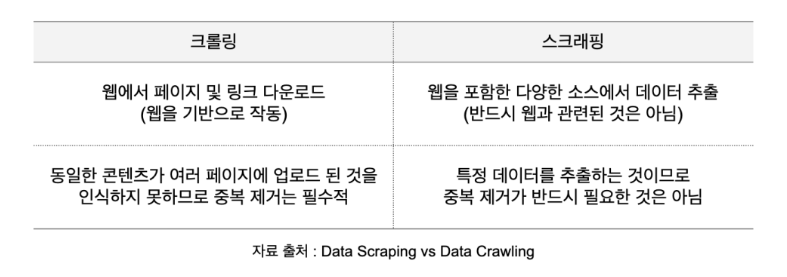
1. Scraping 이란 무엇인가?
- 왭에 있는 특정 정보를 추출하는 기술
- 원하는 정보를 추출하기 위해 봇이 특정 사이트에 콘텐츠를 다운로드하기 위한 HTTP GET 요청을 보냄
- 사이트가 이에 응답하면 HTML 문서를 분석하여 특정 패턴의 데이터를 추출
- 정확한 정보를 요구할 떄 쓰이는 스크래핑 기술
2. Crawling 이란 무엇인가?
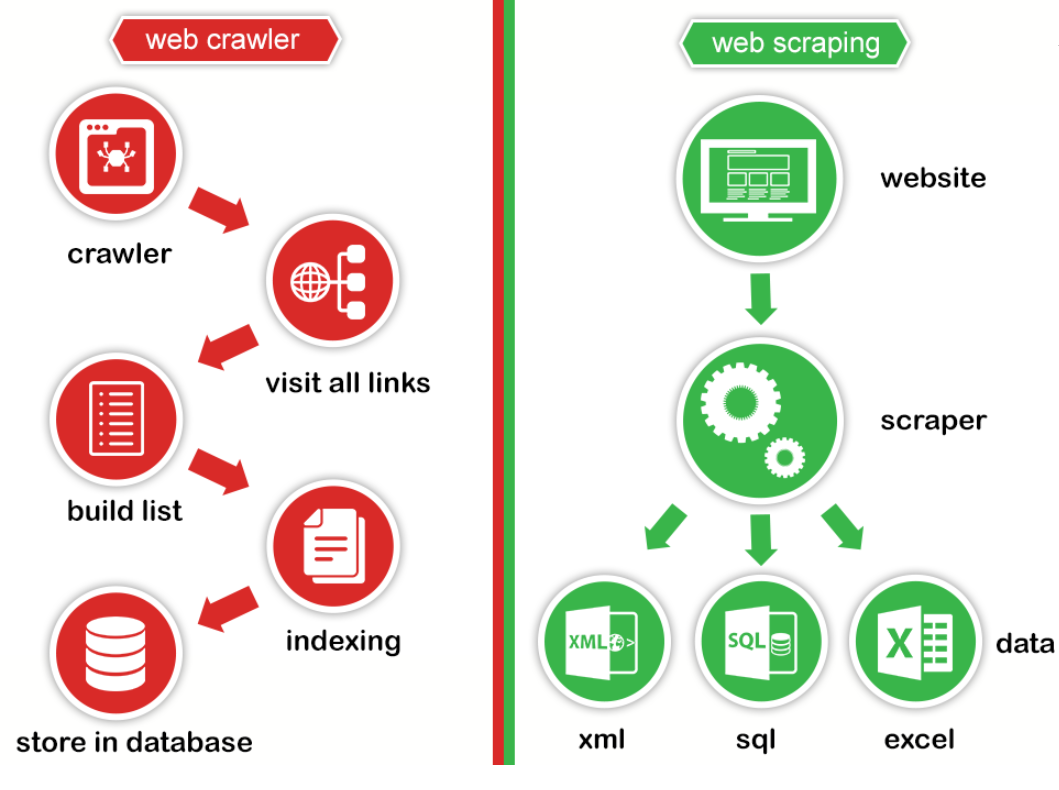
- 프로그램으로 왭을 정기적으로 돌며 정보를 추출하는 기술
- 규칙에 따라 자동으로 왭 문서를 탐색하는 프로그램
- 페이지의 내용과 링크의 복사본을 생성하여 다운로드하고 요약본 생성
- 심층 분석과 실시간 정보 제공에 유용
참조:
https://blog.naver.com/gomdol1551/222872778308
https://blog.naver.com/happy-ds/222335771358
https://blog.naver.com/codef_api/222721006534
(영문 해석)
What is the difference betweden Scraping & Crawling?
-
The short answer is that web scraping is about extracting the data from one or more websites. While crawling is about finding or discovering URLs or links on the web.
-
Usually, in web data extraction projects, you need to combine crawling and scraping. So you first crawl - or discover - the URLs, download the HTML files, and then scrape the data from those files. This means you extract data and do something with it, like storing it in a database or further processing it.
Different purposes
- In web scraping, it's all about the data. The data fields you want to extract from specific websites. And it's a big difference because with scraping you usually know the target websites, you may not know the specific page URLs, but you know the domains at least.
- With crawling, you probably don't know the specific URLs and you probably don't know the domains either. And this is the reason you crawl: you want to find the URLs. So that you can do something with them later. For example, search engines crawl the web so they can index pages and display them in the search results.
Source:
https://www.zyte.com/learn/difference-between-web-scraping-and-web-crawling/
https://brightdata.com/blog/leadership/web-crawling-vs-web-scraping
