자료구조
- 메모리를 효율적으로 사용하며 빠르고 안정적으로 데이터를 처리하는 것이다.
- 다수의 data 를 담기 위한 구조이고 데이터의 수가 많아질수록 효율적인 자료구조가 필요하다.
- 상황에 따라 유용하게 사용될 수 있도록
특정 구조를 이루고 있다. - 상황에 따라 올바른 자료구조을 선택할 수 있어야 한다.

자료구조의 종류
- 3개의 구조로 나눈다.
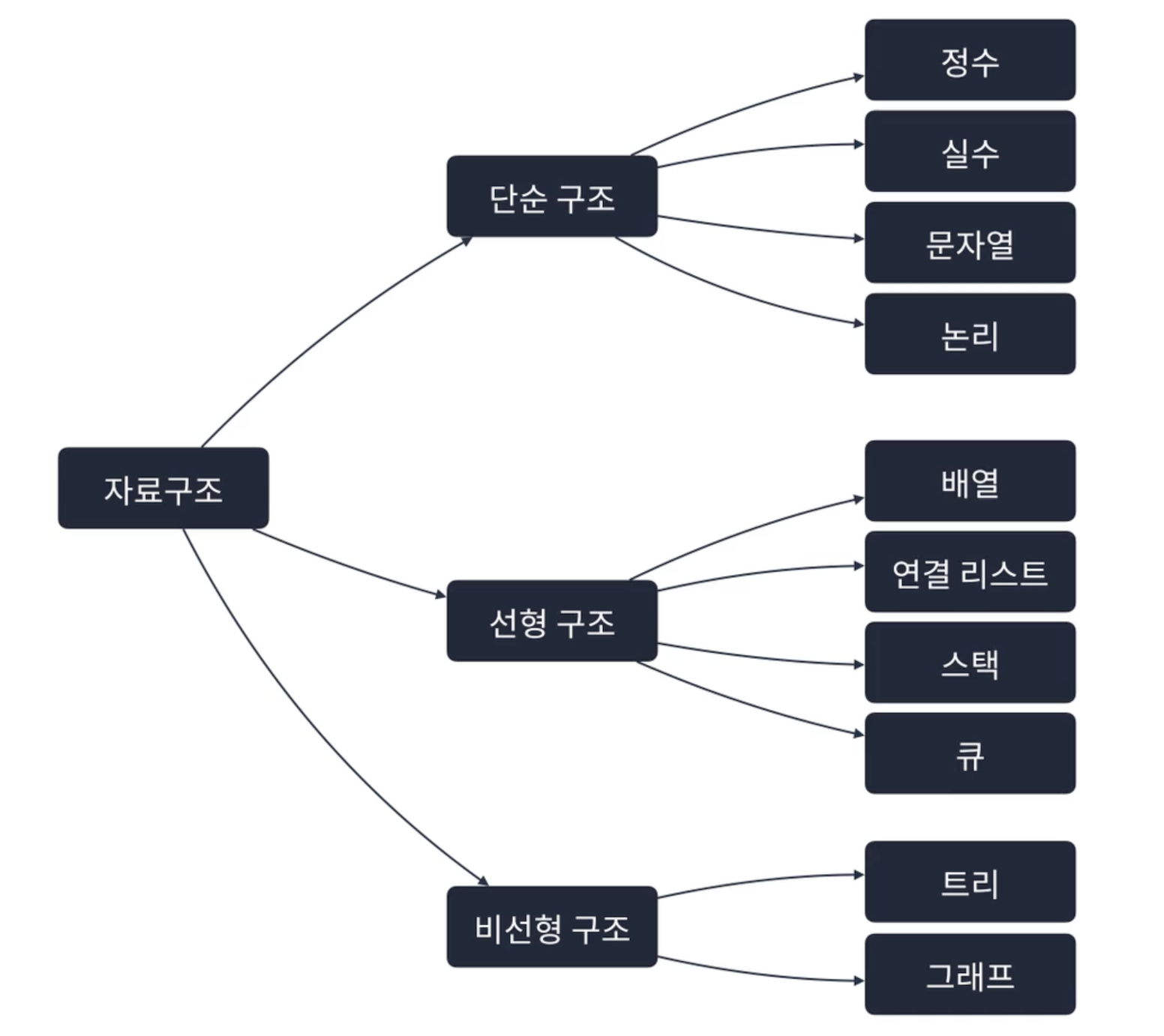
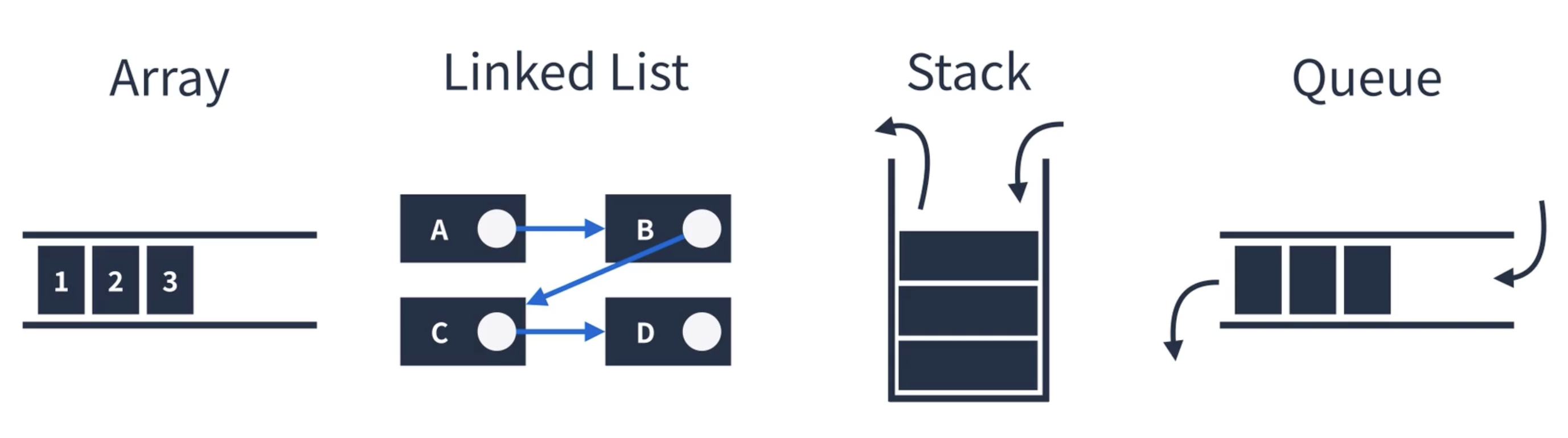
1. 선형 구조(Linear Data Structure)
- 한 원소 뒤에 하나의 원소 만이 존재하는 형태로 자료들이 선형으로 나열되있는 구조를 갖는다.
- 하나의 데이터 뒤에 다른 데이터가 하나 존재하는 자료구조이다
- 데이터가 일렬로 연속적으로(순차적으로) 연결되어 있다.
예) 배열(array), 연결 리스트(linked list), 스택(stack), 큐(queue)
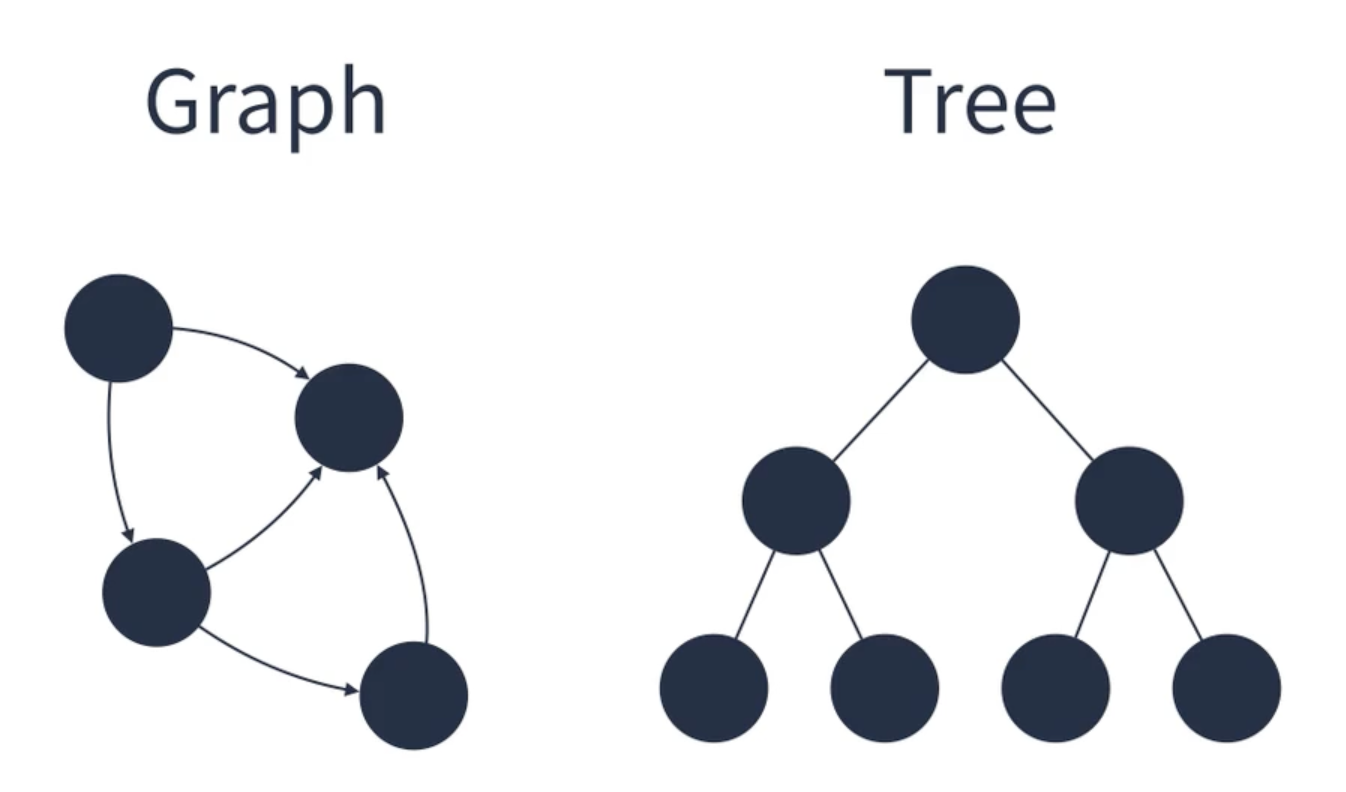
2. 비선형 구조(Non-linear Data Structure)
- 원소 간 다대다 관계를 가지는 구조이다.
- 하나의 데이터 뒤에 다른 데이터가 여러 개 올 수 있는 자료구조이다.
- 데이터가 일렬로 연결되어있지 않고 하나의 데이터 뒤에 두개, 세게 이상의 데이터가 오는구조가 존재할 수 있다.(계층적 구조나 망형 구조)
- 데이터가 일직선상으로 연결되어 있지 않아도 된다.
예) 트리(tree), 그래프(graph)
공간 복잡도(space complexity)
- 알고리즘에 사용되는
메모리의 양을 측정한다. - 공간을 많이 사용하는 대신 시간을 단축하는 방법이 흔히 사용된다.
- 메모리의 크기를 나타낼 때는
일반적으로 MB 단위로 표기한다.

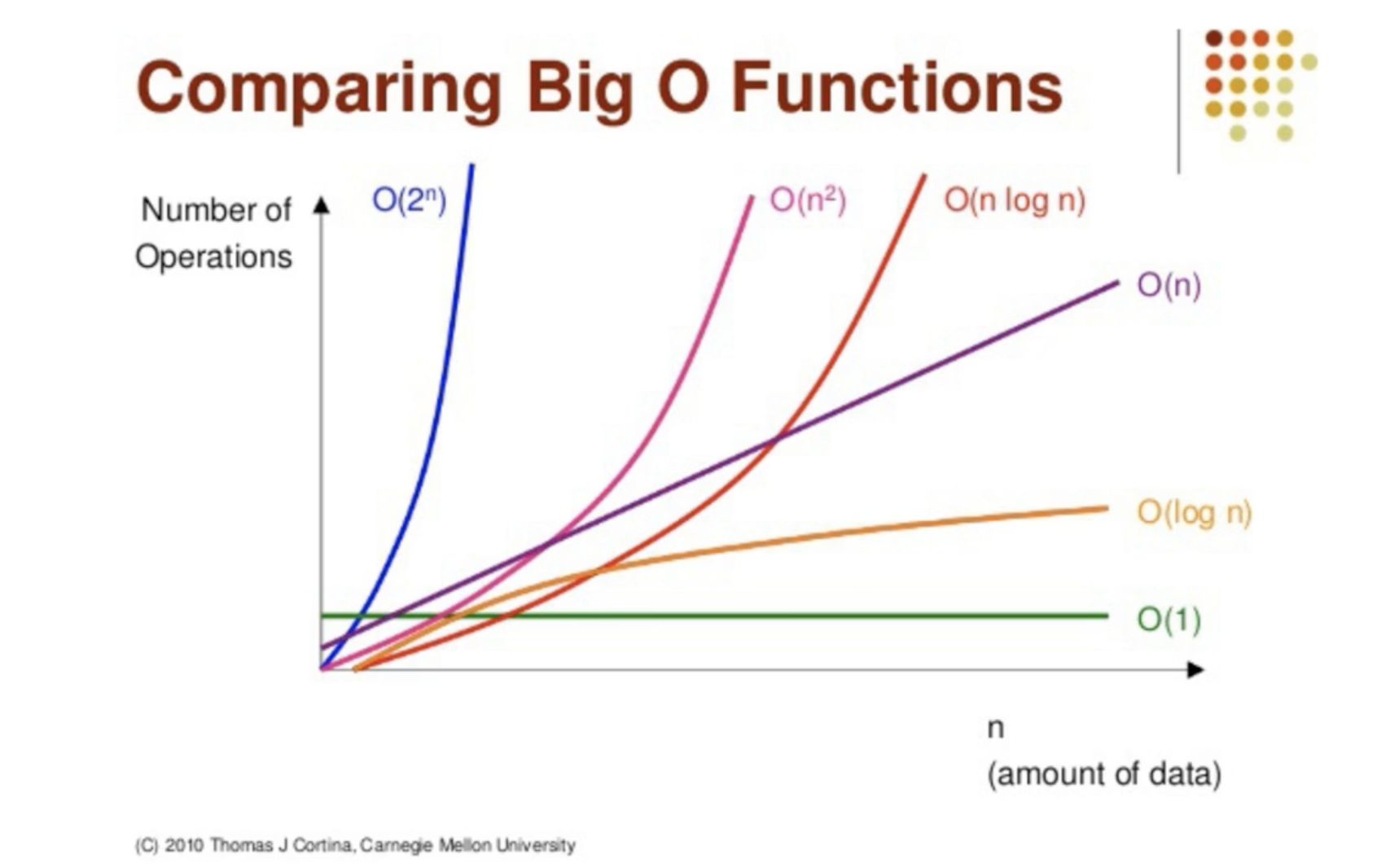
시간 복잡도(time complexity)
-
알고리즘에 사용되는
연산 횟수를 측정한다. -
0(1) 상수 시간 < 0(log n) 로그 시간 < 0(n) 선형 시간 < 0(nlogn) 선형로그 시간 < 0(n²) 2차시간 < 0(2ⁿ) 지수 시간 < 0(n!) 팩토리얼 시간 -
프로그램을 작성할 때는 자료구조를 적절히 활용하여 시간 복잡도를 최소화
해야한다.
0(1) (상수 시간 복잡도)
- 입력 크기에 관계없이 항상 일정한 실행 시간을 가진다.
function exampleConstant(n) {
console.log("Hello, World!");
}- 입력의 크기 n과 관계없이 항상 동일한 실행 시간을 가진다.
- console.log("Hello, World!"); 구문은 단 한 번 실행되기 때문에 실행 시간이 일정하게 유지된다.
0(log n) (로그 시간 복잡도)
- 입력 크기에 따라 실행 시간이 로그의 형태로 증가하는 알고리즘이다.
- 입력의 크기가 매우 커져도 실행 시간이 크게 증가하지 않는 효율적인 알고리즘을 나타내는데 활용된다.
- 주로
이진 검색 알고리즘이나 크기가 n인 정렬된 배열에서특정 값을 찾는 경우의 문제에서 용이하다.
* 로그 함수: 입력의 증가 속도에 따라 실행 시간이 증가하는 속도가 느리게 변하는 특징이 있다.
예) n이 8일 때 실행 시간 : 1초, n이 16일 때 실행 시간 : 2초, n이 32일 때 실행 시간 : 3초
function exampleLogarithmic(n) {
let i = 1;
while (i < n) {
console.log(i);
i *= 2;
}
}- 입력 n에 대해 i 값을 2배씩 증가시키면서 출력하는 반복문이 실행된다.
반복문의 실행 횟수는 i 값이 n을 넘지 않을 때까지 반복 되므로, i 값은
지수적으로 증가한다.
0(n) (선형 시간 복잡도)
- 입력 크기에 비례하여 실행 시간이 증가하는 알고리즘이다.
입력의 모든 요소를 한 번씩 순회하거나 탐색해야 할 때 해당된다.- 주로
배열의 모든 원소를 출력하는 경우가 이에 해당합니다.
function exampleLinear(n) {
for (let i = 0; i < n; i++) {
console.log(i);
}
}- for 반복문을 사용하여 i를 0부터 n-1까지 증가시키면서 출력한다.
입력의 크기 n에 비례하여 n번 반복되므로, 실행 시간도 입력 크기에 선형적으로 증가한다.
0(nlogn) (선형 로그 시간 복잡도)
- 입력 크기에 따라 실행 시간이 선형 로그의 형태로 증가하는 알고리즘이다.
-정렬 알고리즘에서 병합 정렬(merge sort)이 해당한다.
function mergeSort(arr) {
if (arr.length <= 1) {
console.log(arr)
return arr;
}
const mid = Math.floor(arr.length / 2);
const left = mergeSort(arr.slice(0, mid));
const right = mergeSort(arr.slice(mid));
return merge(left, right);
}
function merge(left, right) {
let merged = [];
while (left.length && right.length) {
if (left[0] < right[0]) {
merged.push(left.shift());
} else {
merged.push(right.shift());
}
}
return merged.concat(left, right);
}
const arr = [4, 2, 1, 6, 8, 5, 3, 7];
const sorted = mergeSort(arr);
console.log(sorted);- 병합 정렬의 예시 코드로 배열을 절반으로 분할하고, 각 분할된 부분 배열을 정렬한 후 병합하는 과정을 반복하여 정렬을 수행한다. 이 때, 분할 단계에서 배열을 절반으로 나누는 작업이 log(n) 시간이 소요되고, 각 분할된 배열을 병합하는 과정에서 배열의 크기 n에 비례하는 시간이 소요된다.
0(n²) (이차 시간 복잡도)
- 입력 크기의 제곱에 비례하여 실행 시간이 증가하는 알고리즘입니다.
-정렬 알고리즘인 선택 정렬(selection sort)이 해당한다. - 입력의 크기가 증가할수록 실행 시간이 급격하게 증가한다.
function bubbleSort(arr) {
const len = arr.length;
for (let i = 0; i < len - 1; i++) {
for (let j = 0; j < len - i - 1; j++) {
if (arr[j] > arr[j + 1]) {
// 구조 분해 할당
[arr[j], arr[j + 1]] = [arr[j + 1], arr[j]];
}
}
}
return arr;
}
const arr = [4, 2, 1, 6, 8, 5, 3, 7];
const sorted = bubbleSort(arr);
console.log(sorted);- 버블 정렬의 예시로 이 알고리즘은 배열을 순회하면서 인접한 두 요소를
비교하고 필요에 따라 위치를 교환한다. 이 과정을 배열의 크기 n에 비례하는
반복이 두 번 중첩되므로 시간 복잡도는 O(n²)이다.
0(2ⁿ) (지수 시간 복잡도)
- 입력 크기에 따라 실행 시간이 지수적으로 증가하는 알고리즘이다.
- 모든
부분집합을 생성하는 경우가 이에 해당한다. - 입력 크기가 조금만 커져도 실행 시간이 기하급수적으로 증가한다.
function fibonacci(n) {
if (n <= 1) {
return n;
}
return fibonacci(n - 1) + fibonacci(n - 2);
}
const result = fibonacci(5);
console.log(result);- 피보나치 수열을 구하는 예시로 피보나치 수열은 이전 두 항을 더하여 다음
항을 만들어가는 규칙을 가지고 있다. 재귀적으로 피보나치 함수를 호출하는 과정에서 중복된 계산이 발생하며, 호출 횟수는 입력 크기 n에 따라 2의 n승으로 증가한다.
0(n!) (팩토리얼 시간 복잡도)
- 입력 크기의 계승에 비례하여 실행 시간이 증가하는 알고리즘이다.
- 모든
순열을 생성하는 경우가 이에 해당한다. - 입력 크기가 작아도 실행 시간이 급격하게 증가하여 사용하기 어렵다.
function exampleFactorial(n) {
function factorial(n) {
if (n === 0 || n === 1) {
return 1;
}
return n * factorial(n - 1);
}
for (let i = 0; i < factorial(n); i++) {
console.log(i);
}
}- 팩토리얼 함수를 사용하여 n의 팩토리얼 값을 계산하고, 그 값을 이용하여 for 반복문을 실행한다. 팩토리얼 함수는 재귀적으로 자기 자신을 호출하면서
계산을 수행하므로, 실행 시간은 입력 n의 팩토리얼 값에 비례합니다. 입력이
증가함에 따라 실행 시간이 급격히 증가하는 지수적인 형태를 가진다.
Big-O 표기법
- 시간 복잡도를 표현할 때
가장 큰 항만을 고려하는 표기법이다. - 특정 알고리즘이 얼마나 효율적인지 수치적으로 표현할 수 있다.
- 가장 큰 항에 붙어 있는
계수는 제거한다.
Big-O 표기법의 4가지 법칙
계수법칙
- 상수 k가 0보다 클 때 f(n) = O(g(n))이면 kf(n) = O(g(n)) 이다.
- n이 무한에 가까울 수록 k의 크기는 의미가 없기 때문이다.빅오 표기번엔 생락하여 표현한다.
합의법칙
- f(n) = O(h(n))이고 g(n) = O(p(n))이면 f(n) + g(n) = O(h(n)) + O(p(n))이다.
- 빅오끼리는 더해질 수 있다.
곱의법칙
- f(n) = O(h(n))이고 g(n) = O(p(n))이면 f(n) g(n) = O(h(n)) O(p(n))이다.
- 빅오끼리는 곱해질 수 있다.
- 0(nlogn) 선형로그 시간, 0(n²) 2차시간 시간 복잡도는 곱의 법칙을 통해 나왔다.
다항법칙
- f(n)이 k차 다항식이면 f(n)은 O(nᴷ)이다.
- 다항식일 때 표기하는 방법이다.
표기할 때는 기억할 것
- 상수항 무시
- 알고리즘의 실행 시간이나 연산 횟수에 곱해지는 상수는 중요하지 않다.
- O(3n)과 O(n)은 동일한 시간 복잡도를 나타낸다. 상수인 3은 입력 크기에 비해 미미한 영향을 주기 때문에 무시된다.
- 가장 큰 항 외엔 무시
- 입력 크기가 클 경우 알고리즘의 실행 시간에 영향을 주는 항은 가장 큰 항이다. 가장 큰 항을 중심으로 알고리즘의 성능을 분석한다.
- O(n^2 + n)은 O(n^2)로 표기된다. n이 충분히 크다면 n에 비해 n^2가 지배적인 영향을 미치기 때문에 무시된다.
성능 측정 방법
- Data 객체를 이용하는 방법
console.log("start")
const start = new Data().getTime();
//
const end = new Data().getTime();
console.log(end - start)
console.log("end")
어제보다 나은 나의 코딩지식