Ficket 프로젝트는 얼굴 인식 기반 티켓팅 프로젝트로, 공연 데이터를 실시간으로 관리하며 사용자들에게 빠르고 정확한 검색 환경을 제공하는 것을 목표로 하고 있습니다.
이 프로젝트는 MSA(Microservices Architecture) 기반으로 설계되어 이벤트 관리, 검색, 사용자 인증 등 각 서비스가 독립적으로 운영되면서도 서로 긴밀하게 협력하는 구조입니다. 이러한 구조 덕분에 확장성과 유연성은 확보할 수 있었지만, 데이터 일관성, 색인 작업 충돌 방지, 상태 관리와 같은 여러 과제를 해결해야 했습니다.
특히, 공연 데이터는 실시간으로 추가, 수정, 삭제되며, 이를 기반으로 검색 서비스가 다음과 같은 요구사항을 만족해야 했습니다.
- 실시간 데이터 반영: 이벤트 변경 사항을 빠르게 Elasticsearch에 반영해야 합니다.
- 대규모 데이터 처리: MySQL에 저장된 수백만 건의 공연 데이터를 매일 새벽 대량으로 색인해야 합니다.
- 분산 환경 상태 관리: Redis를 활용하여 색인 작업 상태를 관리하고 작업 간 충돌을 방지해야 합니다.
이와 같은 요구사항을 해결하기 위해 Spring Boot 기반의 색인 아키텍처를 설계하였으며, Spring Batch, Redis, Apache Kafka, Elasticsearch 등의 다양한 기술 스택을 활용해 색인 전략을 수립하였습니다. 지금부터 그 과정을 하나씩 자세히 설명드리겠습니다.
사용 기술 스택
본 프로젝트에서 사용한 주요 기술 스택은 다음과 같습니다.
- Spring Batch: 대량 데이터 처리를 관리하며, 단계별 실행과 병렬 처리를 지원합니다.
- Spring Quartz: 배치 작업을 특정 주기에 실행하도록 관리합니다.
- Elasticsearch: 공연 데이터를 색인하고 빠르게 검색할 수 있도록 지원합니다.
- Kibana: Elasticsearch 데이터를 시각화하고 모니터링합니다.
- MySQL: Event 관련 데이터를 저장합니다.
- Redis: 분산 락을 구현하고 색인 작업 상태를 관리합니다.
- MongoDB: 부분 색인 장애 시 데이터를 캐싱하고 복구하는 데 사용합니다.
- Object Storage: CSV 파일을 저장하는 데 사용됩니다(AWS S3, MinIO 등).
- Apache Kafka: Event 서버와 Search 서버 간 메시지를 전달하여 색인 요청을 관리합니다.
색인 전략
1. 부분 색인
부분 색인은 공연 데이터가 추가, 수정, 삭제되는 이벤트가 발생했을 때 Elasticsearch에 실시간으로 반영하는 것을 목표로 하고 있습니다.
부분 색인 특징
- MongoDB를 중간 캐싱 계층으로 활용합니다.
- 변경된 데이터만 Elasticsearch에 색인합니다.
- 전체 색인이 진행 중인 경우, 부분 색인은 대기열에서 처리됩니다.
부분 색인 프로세스
- Event 서버:
데이터 변경 이벤트가 발생하면 Kafka 메시지를 전송합니다. - Search 서버:
- Kafka 메시지를 수신합니다.
- Redis에서
Full_Indexing_Lock상태를 확인합니다. - 전체 색인이 진행 중이라면 대기열에 작업을 추가합니다.
- 전체 색인이 진행 중이 아니라면 즉시 부분 색인을 실행합니다.
부분 색인 시퀀스 다이어그램

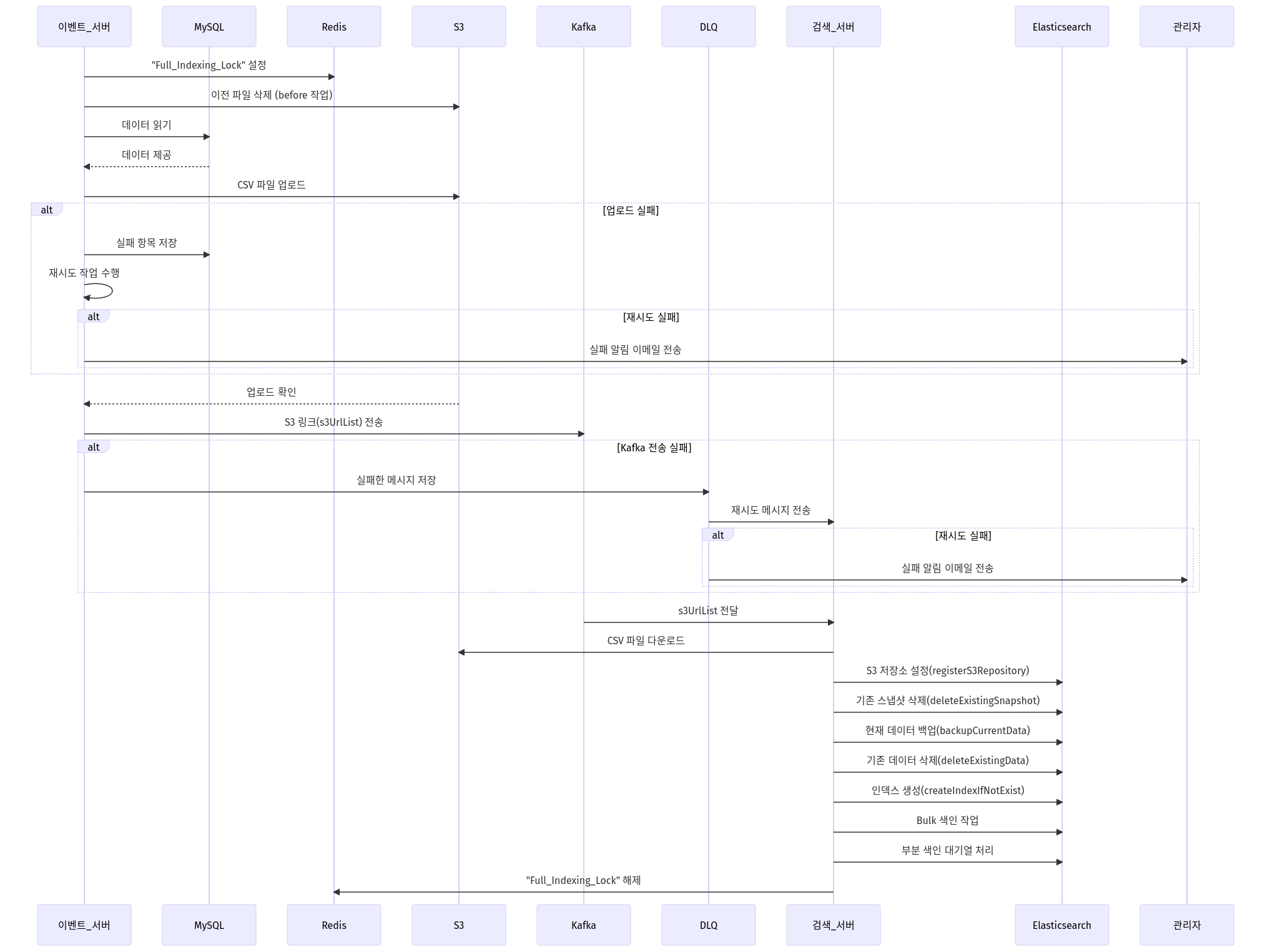
2. 전체 색인
전체 색인은 MySQL에 저장된 모든 공연 데이터를 Elasticsearch로 색인하는 작업입니다.
이 작업은 매일 새벽 2시에 실행되며, 대규모 데이터를 안정적으로 처리하기 위한 다양한 전략이 적용되었습니다.
전체 색인 특징
- Event 서버에서 MySQL 데이터를 읽어 CSV 파일을 생성 후 S3에 업로드합니다.
- Search 서버는 S3에 저장된 CSV 파일을 다운로드하여 Elasticsearch에 색인합니다.
- Redis를 통해 전체 색인 상태를 관리하며, 작업 간 충돌을 방지합니다.
- Elasticsearch Snapshot API를 활용하여 데이터 백업을 수행하며, 이전 인덱스는 하루 주기로 삭제합니다.
전체 색인 프로세스
- Event 서버:
- 매일 새벽 2시에 Spring Batch를 통해 작업이 시작됩니다.
- Redis에
Full_Indexing_Lock을 설정하여 전체 색인이 진행 중임을 표시합니다. - MySQL 데이터를 읽어 CSV 파일로 변환하고 이를 S3에 업로드합니다.
- 업로드가 완료되면 S3 링크 리스트를 Kafka 메시지로 전송합니다.
- Search 서버:
- Kafka 메시지를 수신하여 S3에서 CSV 파일을 다운로드합니다.
- Elasticsearch의 Bulk API를 사용하여 색인 작업을 수행합니다.
- 전체 색인이 완료되면 Redis의
Full_Indexing_Lock을 해제합니다. - 대기 중인 부분 색인 작업을 순차적으로 처리합니다.
전체 색인 시퀀스 다이어그램
3. Spring Batch 기반 전체 색인 설계
전체 색인은 Spring Batch를 활용해 설계되었습니다.
배치 작업은 크게 다음과 같은 단계로 구성됩니다.
Job 단계 구성
- 데이터 파티션 분할:
MySQL 데이터를 일정 범위로 나누어 병렬로 처리하여 색인 속도를 높입니다. - 데이터 읽기 및 처리:
MySQL에서 데이터를 읽어 필요한 형식으로 가공하고, 이를 CSV 파일로 변환합니다.
변환된 CSV 파일은 S3에 업로드됩니다. - 실패 항목 기록 및 복구:
작업 중 실패한 항목은 별도로 기록해 나중에 재처리할 수 있도록 설계하였습니다. - Kafka 메시지 전송:
S3에 업로드된 CSV 파일 경로를 Kafka를 통해 Search 서버로 전달합니다.
4. Redis를 활용한 락 관리
Redis는 색인 작업의 상태를 관리하고 작업 간 충돌을 방지하기 위해 사용되었습니다.
Redis 락 상태 정의
| 락 상태 | 실행 가능 작업 | 방지되는 충돌 |
|---|---|---|
Full_Indexing_Lock | 전체 색인 | 다른 전체 및 부분 색인 작업 실행 방지. |
Redis 락 관리 프로세스
- 전체 색인 시작 시:
Full_Indexing_Lock을 생성하여 색인 작업 상태를 점유합니다.
이 상태에서는 부분 색인 작업이 대기열에서 대기하게 됩니다. - 전체 색인 완료 시:
작업 완료 후 락을 해제하여 대기 중인 부분 색인이 실행될 수 있도록 합니다.
마무리하며
Ficket 프로젝트의 검색 시스템은 실시간으로 방대한 공연 데이터를 처리해야 하는 만큼, 각 기술 스택의 장점을 최대한 활용하여 효율적이고 안정적인 구조를 설계하였습니다. 특히 Redis를 활용한 락 관리와 Spring Batch 기반 병렬 처리는 데이터의 정확성과 성능을 모두 잡는 데 큰 도움이 되었습니다.
다음글에서는 구현에 대해 다뤄보겠습니다.
Reference
