오랜만에 친구랑 스벅에서 모각공하며 기분 전환 •ᴗ• 경찰 공무원 준비 중인 친구는 여러 시험을 보며 자신은 이해가 돼야 암기든 응용이든 된다고 한다. 한국사 시험을 예로 들면, 인조반정이 시험에 나오는 것은 극히 일부분이지만 자신은 인조반정이 일어난 이유와 계기, 사람들 간의 관계 등 세부적인 부분이 전부 이해가 돼야 외울 수 있고 시험에서 응용할 수 있다는 것이다. 친구는 끼리끼리라고 하나 ㅎㅎ 내 모습을 보는 것 같았다. 그 안의 내부적인 구조를 이해해야 겉에 시스템이 왜 이렇게 돌아가는지 와닿고, 그래야 사용하고 응용하게 된다. 이것이 OS 공부를 놓지 못하게 하는 매력인 거 같다.
Virtual memory management 목적
왜 가상 메모리를 알아야 하고, 관리할 수 있어야 할까?
가상 메모리 시스템을 관리함으로써 성능을 최적화하는 것에 목적이 있다. 한국인 특) 빠르고 효율적인 것을 좋아한다. 물론 나도 그렇다. 프로그램의 전체적 성능 향상을 위해 가상 메모리의 성능 관리도 필요할 뿐이다.
성능을 최적화하기 위해서는 기준이 필요하다. 이 기준에 미달하면 성능이 좋지 못해서 향상이 필요하고 기준 이상이면 다른 곳에 집중해도 된다는 그러한 기준 말이다. 그 기준으로 Cost model을 사용한다.
대표적인 Cost Model로는, Page fault frequency(발생 빈도에 따른 비용 모델), Page fault rate(발생률에 따른 비용 모델)가 있다. 이것을 기준으로 page fault rate를 최소화할 수 있는 전략을 설계해나야 한다. 이전에 말했듯 page fault로 인한 context switch는 비용이 많이 들기 때문이다. 해서 context switch로 인한 kernel의 개입을 최소화하여 overhead를 줄이고, 시스템 성능을 향상시키는 전략이 필요하다.
H/W Components
Vitual memory 관리에는 H/W component와 S/W component가 필요하다.
먼저, 필요한 H/W 장치로는
- Address translation device (주소 변환 장치)
주소 변환을 효율적으로 수행하기 위해 사용하는 장치로 TLB, Cache memories, page-table 전용 register 등이 있다. - Bit Vectors
page 사용 상황에 대한 정보를 기록하는 비트들로, page frame이 참조되면 1로 바뀌는 reference bits와 page frame 안의 data가 갱신되면 1로 바뀌는 update bits가 있다.- reference bits vector
메모리에 적재된 각 page가 최근에 참조 되었는지를 표시하고, 주기적으로 모든 reference bit를 0으로 초기화한다. 이는 지역성을 활용한 것이다. - update bits vector
page가 메모리에 적재된 후, 프로세스에 의해 수정되었는지를 표시하고, 주기적 초기화가 아닌 해당 page가 memory에서 나올 때 갱신된 내용을 swap device에 Write-back해줌으로써 데이터의 무결성을 보장한다.
- reference bits vector
가 있다.
S/W Components
가상 메모리 성능 향상을 위한 S/W적 관리 기법들은 굉장히 많다.
-
Allocation strategies (할당 기법)
각 프로세스에 메모리를 얼마만큼 줄 것인가?
프로세스의 실행 동안 고정된 크기의 메모리를 할당하는 Fixed allocation (고정 할당) 기법과 할당하는 메모리의 크기가 유동적인 Variable allocation (가변 할당) 기법 중에 고를 수 있다. 기법을 선택할 때 너무 큰 메모리 할당으로 인한 낭비가 없도록, 반대로 너무 적은 메모리 할당으로 인한 page fault rate 향상으로 시스템 성능이 저하되는 일이 없도록 적당한 메모리 양을 예측하는 것이 관건이다. -
Fetch strategies
특정 page를 메모리에 언제 적재할 것인가?
프로세스가 참조하는 페이지들만 적재하는 Demand fetch 기법과 참조될 가능이 높은 page를 예측하여 가까운 미래에 참조될 가능성이 높은 page를 미리 적재하는 Anticipatory fetch(pre-paging) 기법이 있다.
Demand fetch 기법은 필요할 때 적재함으로 page fault로 인한 overhead가 크다.
Anticipatory fetch(pre-paging) 기법은 예측 성공 시, page fault overhead가 없다는 장점이 있으나 예상이 얼마나 맞냐를 나타내는 Hit ratio에 민감하여 잘못된 예측 시 자원의 낭비가 크다.
실제로 대부분의 시스템은 일반적으로 준수한 성능을 보여주는 Demand fetch 기법을 사용한다. 그럼에도 Anticipatory fetch(pre-paging) 기법을 배우는 것은 스스로 만든 프로그램에서 내가 만든 알고리즘은 예측이 가능함으로, 개인 프로그램에 사용하게 된다고 한다. -
Placement strategies (배치 기법)
page/segment를 어디에 적재할 것인가?
paging system에서는 공간이 일정하기에 불필요한 기법이고, segmentation system에서 배운 배치 기법과 같다. -
Replacement strategies (교체 기법)
빈 page frame이 없는 경우, 새로운 page를 어떤 page와 교체할 것인가?
새로운 page를 어떤 page와 교체할지 고민할 때 기준이 되는 것은 Locality(지역성)이다. 지역성이 가상 메모리 관리에 영향을 미치는 것이 잘 표현된 예시는 아래와 같다.n = 1000 for i in range(n): A[i] = B[i] + C[i]page size = 1000 words
Machine instruction size = 1 word
주소 지정은 word 단위로 이루어지고
위 프로그램이 4번 page에 continuous allocation 된다고 가정할 때,
실제 기계어로 바꾸면 19000번 정도의 메모리 참조 중 5개의 page만을 집중적으로 접근하게 된다. 하여 메모리 관리 시 locality를 최대로 활용한다면, 성능을 높일 수 있다.-
Fixed allocation
- Min Algorithm (Optimal solution)
page fault 수를 최소화하는 알고리즘으로, 앞으로 가장 오랫동안 참조되지 않을 page를 교체하는 기법이다. page reference string을 미리 알고 있어야 하기에 실현 불가능한 기법이다. 하지만, 이를 배우는 이유는 교체 기법의 성능 평가 도구로 사용되기 때문이다. - Random Algorithm
무작위로 교체할 page를 선택하여 overhead가 적지만 이 또한 평가의 기준으로 사용되는 기법이다. - FIFO Algorithm
First In First Out으로 가장 오래된 page를 교체하는 기법으로 page가 적재된 시간을 기억하고 있어야 한다. 이는 locality에 대한 고려가 없기에 자주 사용되는 page가 교체될 가능성이 높다. 또한 더 많은 page frame을 할당받음에도 불구하고 page fault의 수가 증가하는 FIFO anomaly 즉, 이상 현상이 발생할 수 있다. - LRU (Least Recently Used) Algorithm
가장 오랫동안 참조되지 않은 page를 교체하는 기법으로, page 참조 시마다 시간을 기록해야 한다. 이는 locality에 기반을 둔 교체 기법으로 Min Algorithm에 근접한 성능을 보여주어 실제로 가장 많이 활용되는 기법이다. 하지만 이 기법 또한 단점이 있는데 참조 시 마다 시간을 기록해야하기에 overhead가 있고, loop 실행에 필요한 크기보다 작은 수의 page frame이 할당될 대, page fault가 급격히 증가하게 된다. 이는 page frame 수를 늘려주는 등 allocation 기법에서 해결해야한다. - LFU (Least Frequently Used) Algorithm
가장 참조 횟수가 적은 page를 교체하는 기법으로, page 참조 시마다 참조 횟수를 누적시켜놓기만 하면 된다. locality를 활용했기에 LRU 대비 적은 overhead를 갖지만, 최근 적재됐지만 참조될 가능성이 높은 page가 교체될 수도 있다. - NUR(Not Used Recently) Algorithm
LRU에서 시간을 기록하는 overhead를 줄이기 위한 것으로 Bit vector를 사용하여 LRU보다 적은 overhead로 비슷한 성능에 달성한다. Bit vector는 위에서 말한 것과 같이 reference bits vector(r)와 update bits vector(m)로 구성되어 있다. 교체 순서는 아래와 같다.- (r,m) = (0,0)
- (r,m) = (0,1)
- (r,m) = (1,0)
- (r,m) = (1,1)
update bits vector(m)이 1인 경우는 memory에서 나올 때 초기화되고 write-back으로 overhead가 크기 때문에 overhead가 작은 것부터 교체하게 되는 것이다.
- Clock Algorithm
OS에 실제 구현된 기법으로, reference bit를 사용한다. 하지만 기존 reference bit를 주기적으로 초기화하는 방식이 아닌 page frame들을 순차적으로 가리키는 pointer(마치 시곗바늘)를 사용하여 교체될 page를 결정하게 된다. pointer가 가리키고 있는 page의 reference bit를 확인하여 0인 경우 교체 page로 결정하고, 1인 경우 reference bit 초기화 후 pointer를 한 칸 이동시킨다. - Second Chance Algorithm
Clock algorithm과 유사하나 update bits도 함께 고려한다.
(0,0) : 교체 page로 결정
(0,1) : -> (0,0), write-back list에 추가 후 이동
(1,0) : -> (0,0) 후 이동
(1,1) : -> (0,1) 후 이동
- Min Algorithm (Optimal solution)
-
Variable allocation
* Working Set (WS) Algorithm
working set 이란 process가 특정 시점에 자주 참조하는 page들의 집합으로 locality를 활용하기 위한 것이다. window size라고 하는 최근 일정 시간 동안, 참조된 page들의 집합인 working set은 시간에 따라 당연히 변한다. locality에 기반을 두었기에 page fault rate (thrashing)은 감소하고, 시스템 성능을 향상시킬 수 있다.
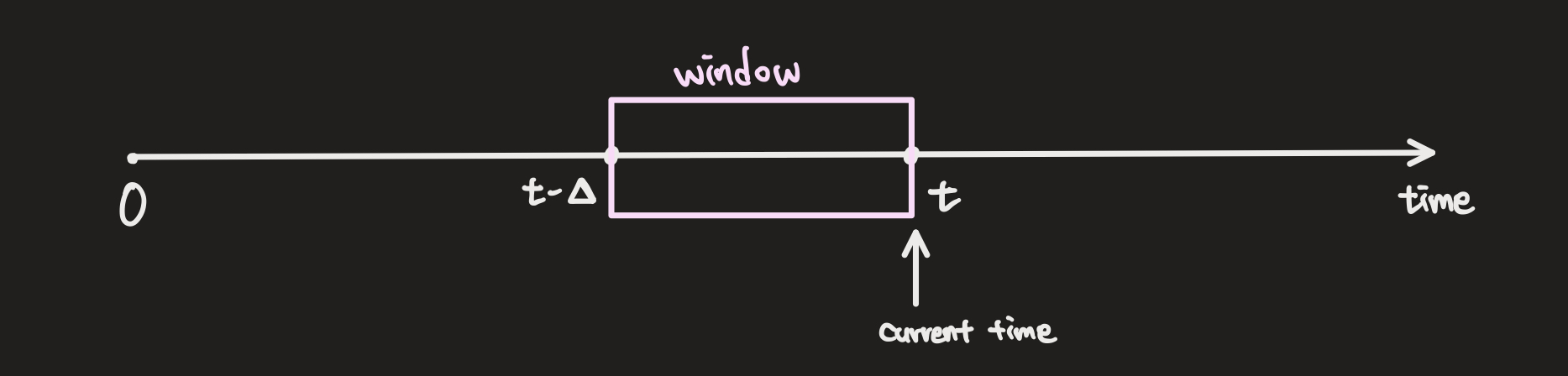
working set은 메모리에 항상 유지되어 있어야 하며, 최근 일정 시간인 window size는 고정이기에 window size 값이 성능을 결정짓는 중요한 요소가 된다. 그럼 window size 값은 어느 정도의 값이 좋을까?
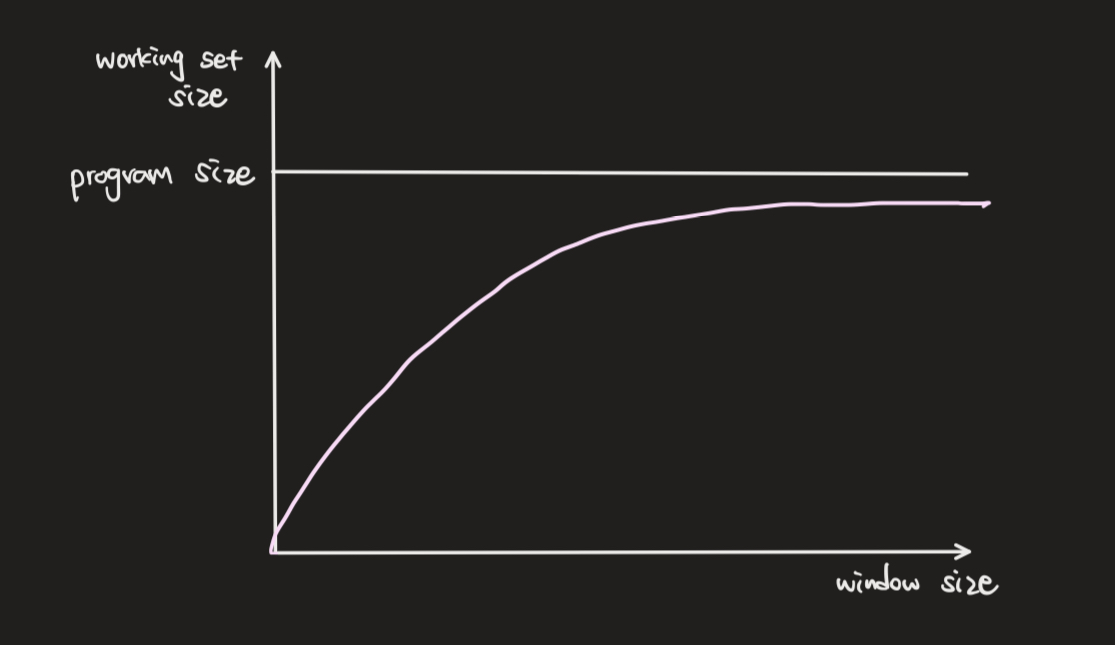
초반에는 windwo size를 조금만 늘려도 working set size가 급격하게 증가를 하고, 어느 구간에 돌입하면 완화되고, 어느 수준 이상으로 window size가 커지면 더 이상 working set size가 커지지 않는 시점이 온다. 이는 locality로 인해 아무리 window size를 늘린다 해도 특정 시간에 부분만 보기에 working set size가 늘지 않는 것이다.
이 기법의 성능을 평가할 때에는 page fault와 함께 평균 할당된 page frame 수도 영향을 미쳐서 함께 고려해야 한다. page fault가 없더라도 working set을 계속 관리해야 하기에 overhead가 있다.- Page Fault Frequency (PFF) algorithm
page fault가 발생하면 관리를 하는 전략으로, page fault가 잘 발생하지 않으면 process에 할당된 page frame 수를 감소하고, page fault가 자주 발생하면 page frame 수를 증가시키는 기법이다. 자주 일어난다는 기준을 threshold value로 정해준다. page fault 발생시 그전 page fault와의 간격을 계산해 주어 기준보다 큰지 작은 지로 판단할 수 있다. - Variable Min (VMIN) algorithm
평균 메모리 할당량과 page fault 발생 횟수를 모두 고려했을 때의 최적을 찾는 기법이다. 이는 page reference string을 미리 알고 있다는 것을 가정함으로 실현 불가능한 기법으로 평가 기준으로 사용할 수 있다.
- Page Fault Frequency (PFF) algorithm
-
-
Cleaning strategies (정리 기법)
변경된 page를 언제 wrtie-back 할 것인가?
즉, update bit가 1일 때 변경된 내용을 swap device에 write-back 하는 것을 언제 할 것인가?에 대한 기법이다.
변경된 해당 page가 메모리에서 내려올 때 write-back 하는 Demand cleaning 기법과 더 이상 page에 data 변경이 될 가능성이 없다고 판단할 때, 미리 write-back을 하는 Anticipatory cleaning(pre-cleaning) 기법이 있다.
이 역시 실제 대부분의 시스템은 일반적으로 준수한 성능을 보여주는 Demand cleaning 기법을 사용한다. Anticipatory cleaning(pre-cleaning) 기법은 미리 wirte-back을 하므로 page 교체 시 발생하는 wrtie-back 시간을 절약하지만 만약, write-back 이후 page 내용이 수정되는 등 잘못된 예측 시 자원의 낭비가 크기 때문이다. -
Load control strategies (부하 조절 기법)
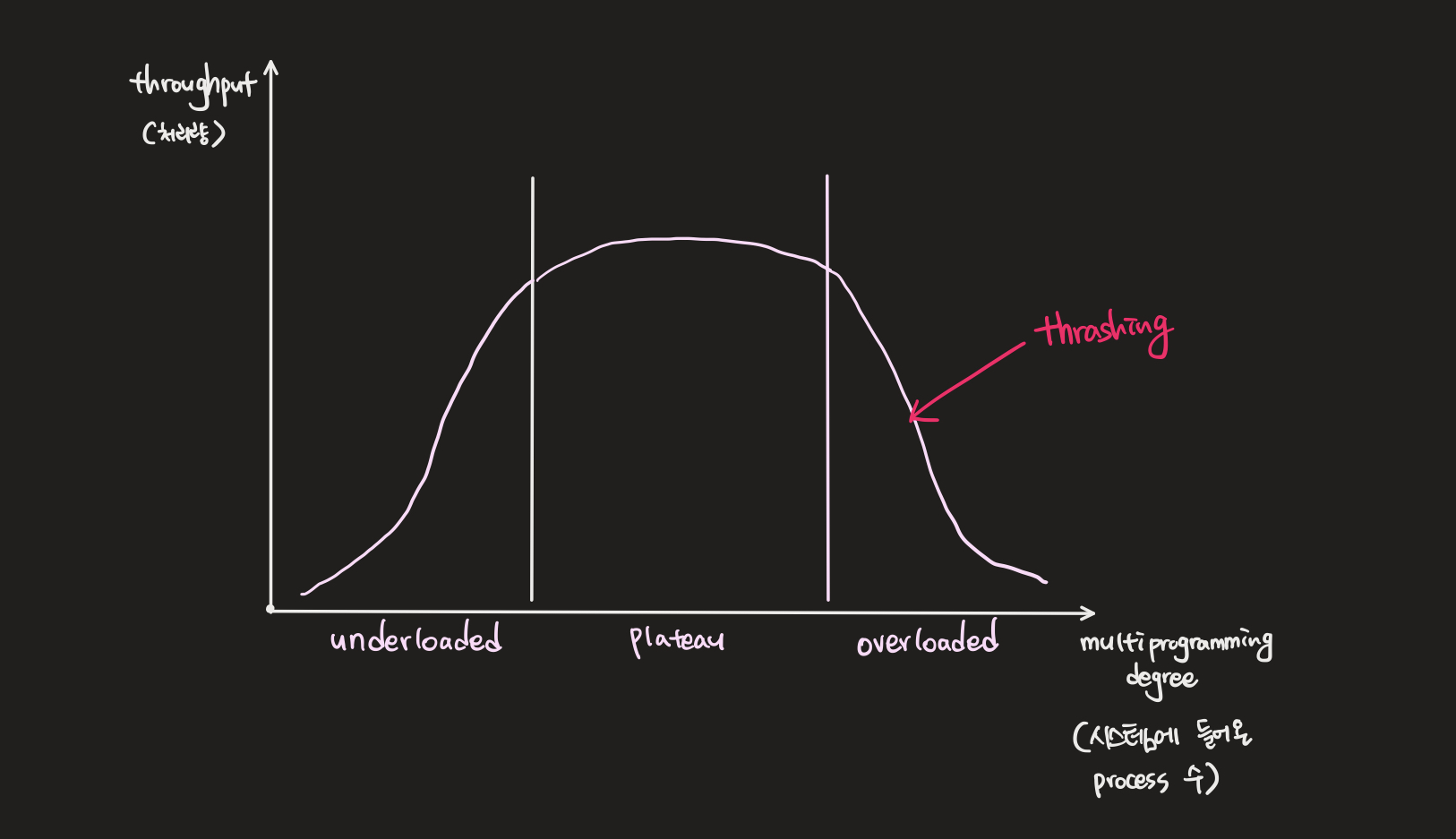
multi-programming degree를 어느 정도로 유지할 것인가?
시스템의 multi-programming degree(시스템에 들어온 process의 수)를 조절하는 전략으로, allocation strategies와 연관되고 적정 수준으로 유지하는 것이 좋다.
저부하 상태라면 시스템 자원이 낭비되고 throughput 면에서 성능이 저하되고, 고부하 상태라면 자원에 대한 경쟁 심화로 성능이 저하되고 과도한 page fault가 급격하ㅔ 많이 발생하는 Thrashing(스레싱) 현상이 발생되므로 좋지 않다.