Flink로 시작하는 Stream Processing 1
개요
저는 데이터 엔지니어로서, 2019년부터 Flink를 사용하여, stream processing을 업무에 적용하고 있습니다. 데이터 처리에 Flink 사용한 경험을 바탕으로, 데이터 엔지니어로서 Flink를 선택한 이유, Flink를 사용하는 여러가지 방법 그리고 어떤 상황에서 Flink가 가장 사용하기 적합한지를 블로그로 남기고자 합니다. 이 글은 시리즈로 적어 볼까 합니다.
데이터 엔지니어는 어떤 일을 할가?
데이터 엔지니어는 데이터와 밀접하게 일하는 직군으로서, 데이터를 수집, 변환 그리고 관리하며, 궁극적으로는 데이터를 필요한 모든 분에게 접근하기 쉽고, 사용하기 좋은 데이터를 제공해주는 직군이라고 생각 합니다.
사실 위에 처럼 거창하게 말했지만, 실제로는 아래와 같은 문제를 해결하는 게 대부분 입니다.
통상적으로 데이터 엔지니어가 푸는 문제: data1 -> processing -> data2
데이터 엔지니어는 위와 같이 data1 모양을 data2 모양으로 변경하는 문제를 풀며, 품질적인 부분으로는 아래와 같은 것들을 고민을 합니다.
- 효율성 (Efficiency) - 어떻게 하면, 컴퓨터자원 사용을 최소화 하여 data1을 data2 만들 수 있을가?
- 시간성 (Timeliness) - 어떻게 하면, 요구 하는 시간안에 데이터를 가공하여, 사용자에게 전달할 수 있을가?
- 유효성 (Availability) - 처리된 데이터를 지속적으로 사용자에게 제공할 수 있을가?
- 확장성 (Scalability) - 데이터의 양이 커져도 감당할 있을가?
- 정확성 (Accuracy and Integrity) - 데이터 처리가 정확했고, data1를 기반으로 data2가 일관적인지.
사실 가장 중요하다고, 생각하는 5가지 부분만 적은 것이지, 실제로는 list of system quality attributes를 data의 기준으로 대입한다면, 데이터 엔지니어로서 데이터 처리에 대한 높은 퀄리티를 달성할 수 있다고 생각합니다.
데이터 엔지니어는 왜 생기게 된걸가?
데이터 엔지니어와 같은 직군이 생긴 이유는 다음과 같다고 생각 합니다.
- 데이터에 중요성 인지 - 지겹도록 들으셧을 테지만, 4차 산업혁명에 중심에는 데이터가 있습니다. 데이터에 가치는 날이 갈수록 높아지고 있으며, 회사로서는 당연히 자산으로서 높은 가치를 지닌 데이터를 관리해야 합니다.
- 방대한 데이터 용량 - 하드웨서 성능 진화가 관리해야 하는 데이터 양에 비해 느리게 진화하고 있습니다. 하여, 하드웨어만으로는 제대로 데이터를 관리하기 힘이들며, 데이터 관리에 특화된 소프트웨어 기술들을 활용하여, 데이터를 관리 해야 합니다.
- 데이터 보안 - 데이터의 활용성이 높아지며, 이는 민감한 정보들을 사용하여, 서비스를 제공하는 분야도 늘고 있습니다. 하여, 민감한 정보를 가진 데이터들을 안전하게 보관 하는 일도 중요한 일입니다. 데이터와 근접하게 일하는 데이터 엔지니어는 데이터의 보안 또한 신경써야 합니다.
- 유니콘(슈퍼맨) - 통상적으로 데이터 분석가들이 분석을 위해 사용하는 시간에, 70 ~ 80%는 데이터 가공에 사용합니다. 데이터를 효율적으로 빠른시간에 처리하기란 쉽지 않으며, 데이터 가공과 분석이라는 두가지 분야는 생각 보다 괴리감이 있습니다. 분석은 수학 그리고 통계학을 기반으로한 기술이 많이 필요 하다면, 가공쪽은 computer science쪽 능력이 많이 필요합니다. 데이터 싸이언티스트 또는 분석가가 데이터 가공을 효율적이며, 재사용까지 가능하게 만드는 능력을 지니고 계시다면, 진정한 능력자라고 이야기 하고 싶습니다. 하여, 분석은 데이터 싸이언티스트, 가공은 데이터 엔지니어로 나뉘어 자리 잡고 있지 않나 싶습니다.
이외에도 여러가지 이유가 있겠지만, 위 설명드린 부분들이, 제가 현업에서 데이터 엔지니어로서 일하면서, 실질적으로 회사에 도움을 주었다고 생각되는 부분입니다.
데이터 엔지니어는 왜 streaming processing을 해야 하는가?
Streaming Processing은 무었인가?
데이터 처리 쪽을 경험 하신 개발자분이시라면, stream processing에 대해서는 한번은 들어보셨을 거라고 예상합니다. 명칭을 그대로 직역해 본다면 흐르며 처리한다... 라고 할 수 있습니다. 기존에 많이 사용되던 batch processing이 발전하여, 보다 소규모 단위로 처리하는 mini-bactch가 되었고, 여기서 더 발전하여, 더 이상 데이터적으로 나뉘면 의미가 없는 단위 바로 직전까지 나뉘어 처리하는 방식을 stream processing 이라고도 부를 수 있을거 같습니다. (이 단위는 작업하는 domain에 따라 row, event, line, document 등이 될수 있습니다.)
하지만, 가장 좋은 정의는 역시 wikipedia 겟죠? 위키에서는 이렇게 정의 합니다. 짧게 요약해서, "Stream processing은 하나의 programming paradigm이며, 어플리케이션을 개발할때, 특별한 병렬처리에 기술을 사용하지 않고도, 단순하게 병렬처리를 할수 있게 도와줍니다." 여기서 키포인트는 단순하게 병렬처리를 할수 있게 해준다는 부분인거 같습니다. 병렬처리 자체도 개발적으로 힘들지만, 처리해야 하는 데이터양이 많아지면, 많아질수록, 병렬처리 난이도는 더 올라가기 때문입니다.
Stream Processing을 왜 사용하는가?
Stream processing은 컴퓨터 개발의 paradigm으로서 간단하게 검색만해도 아주 많은 검색결과로 사용해야하는
이유를 찾을 수 있을것입니다. 하지만, 제 경험을 바탕으로 개발을 진행하면서 stream processing으로 처리하지
않으면 안되겟구나!? 라고 피부로 와닿았던 상황은 아래와 같습니다. (통상적으로 stream processing을 반댓말로 batch processing을 말하기에 batch를 기준으로 상황을 기재 하였습니다.)
- 제한된 메모리 - Python으로 간단한 데이터 계산을 하기 위헤 100GB 용량의 CSV를 리스트 변수에 할당 하였더니... OOM(Out of Membory) Exception과 함께 프로그램이 강제 종료가 되어, 실행할 수 없었다.
- 제한된 시간 - CronJob을 통해 하루 단위의 batch 작업을 매일 새벽 2시에 수행하는데, 점점 작업량이 늘어나더니 다음날 새벽 2시에 작업을 만나러가는... (batch는 하루에 새벽시간이나 특정 제한 시간안에 처리 해야 한다면, stream은 하루종일 처리해도 상관없음)
- 제한된 자원과 관리 - 짧은 시간내에 많은 데이터를 처리해야 하기 때문에, high spec 컴퓨터와 memory 과다 사용하여, 비용을 많이 사용하게 된다. 여기서 spot instance로 비용절감 하려다, instance 뺏겨서 데이터 처리 다시 시작 관리 및 잠시 사용하기에 부담스러워 RI(Reserved Instance)를 사지못해서 On-demand 고려 등 여러 힘든 결정을 해야 할수도 있다. (비싸다 -- memory -- ssd -- hdd -- object-storage -- 싸다) 하지만, stream processing 한다면, 트래픽이 높은 상황에는 scale-out, 낮을때는 scale-in등, 더욱 현상황에 맞게 컴퓨터 자원을 효율적으로 사용가능하다.
- 제한된 모니터링 - batch로 처리할 경우 실시간으로 데이터가 얼마나 쌓엿는지, 자체만으로 모니터링이 힘들. Stream processing 같은 경우 실시간으로 데이터를 처리하고 있는 자체만으로 모니터링이 가능 하기에, 어느 시기에 컴퓨터 자원을 scale-out 또는 scale-in 해야 할지 모니터링이 할수 있다.
- 요구사항 - 최대한 빨리 처리 해주세요.
Apache Flink의 소개
Apache Flink는 Apache incubator를 통해, Apache Software Foundation 공식으로 등록된, Apache license 2.0을 가진 open source framework입니다. Apache Flink를 사용하는 대표 회사로서는 사용자로서, Alibaba, AWS Kinesis, Uber, Netflix 등 아주 큰규모로서 많이 사용되었으며, 특히 Alibaba 같은 경우 blink라는 새로운 branch를 만들어 따로 운영하며, 회사 굵직한 서비스에 해당 기술을 사용하고 있습니다. 추가로 Alibaba는 Apache Flink를 만든 회사 Data Artians를 인수할정도로, Flink를 중요시 생각하는 듯 합니다. (필자는 blink라고 불리는 branch가 flink에 merge가 되기를 희망하고 잇기도 합니다....)
Apache Flink 사용자들 - https://flink.apache.org/poweredby.html
Apache Flink는 stream processing을 쉽게 구현할 수 있게 다양한 상황에 사용 가능한 API를 제공합니다. 아래는 해당 API들의 큰 카테고리 입니다. (추후 다른 시리즈로 작성 예정)
- Stream Application: Flink application을 구성하는 요소
- Streams는 flink로 stream processing을 시작하는 데 필수로 정의해야 하는 부분이며, flink 공식문서에서는 총 bounded, unbounded, real-time 그리고 recorded. 존재한다.
- State - 상태기반 stream processing는 flink 공식문서에서도 first-class citizen이라고, 자랑스럽게 설명할 정도로 공을 많이 들인 flink에 기능입니다. Flink는 다양한 상황에서 상태기반 stream processing이 가능하게 다음과 같은 상태기반 관리를 제공합니다. (Flink를 제가 선택하게 된 계기도 상태기반처리 능력이 컷던거 같습니다.)
- 다양한 원시 상태 타입
- 선택 가능한 백엔드 종류
- 정확한 상태 일관성
- 대용량 상태 지원
- 확장성 지원
- Time - 다양한 시간 관리를 위한 API
- 처리 시간 기반 처리
- 이벤트 시간 기반 처리
- 워터마크 지원
- 늦게 도착한 이벤트 처리
- Layered APIs - 단계 별로 나뉘어진 API로 간결력또는 표현력을 기준으로 개발자로서 선택하여, 개발을 진행할수 있습니다. 그림 출처 - https://flink.apache.org/flink-applications.html
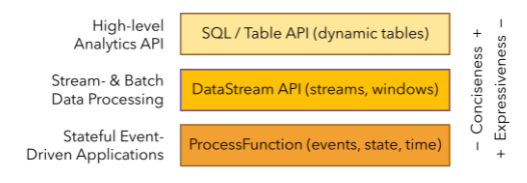
- Libraries - 바로 쓸수 있는 여러 라이브러리 지원
- Complex Event Processing - 바로 사용가능한, 다양한 패턴 분석API
- DataSet API - 원시단위 data operation API로 개인적으로 Flink를 사용하게 되면 가장 많이 사용하게 되는 API 인거 같습니다. Map, reduce, (outer) join, co-group, 그리고 iterate 같은 operator가 대표적으로 있지만, 제공하는 전체 API에 극히 일부입니다.
- Gelly - Graph 분석 또는 데이터 처리 API 입니다. DataSet API를와 연계 가능합니다.
다른 framework와의 차이점
장점
- Multi source 그리고 multi sink 지원
- 관리해주는 프로세스가 따로 존재
- 다양한 상태처리 기술 지원
- Learning curve가 낮은 편
- 복잡한 이벤트 처리 가능
- 한국에 커뮤니티 존재함
단점
- 현재로서 공식 지원 언어는 Java, Scala 그리고 Python 이지만.. 실제로 Python을 지원시작 하기 얼마 안되서 전체 API가 지원되지 않는 거 같은...
- Flink 전용 어플리케이션으로 출시 되기에, Flink cluster 어딘가에 존재 필요
- Cluster 관리 해야 할게 추가로 생김 (그래도 k8s operator 존재)
Flink 맛보기
간단한 데이터 처리로 flink가 어떻게 동작하는 지 알아 보려고 합니다. 저는 scala와 maven을 사용하겠으며, 목표는 아래와 같습니다.
MovieLens dataset에 평점별 평가자 수 구하기
MovieLens 데이터 다운받기
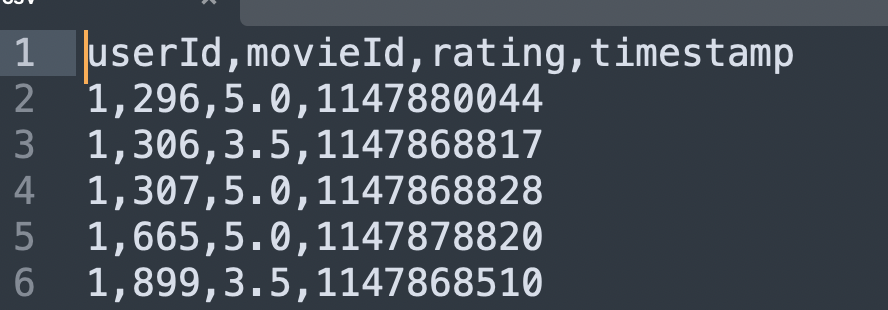
저는 여기서 ratings.csv 파일만 사용 하려 합니다. (https://grouplens.org/datasets/movielens/)
| 파일 | 데이터 구조 (ratings.csv) |
|---|---|
 |  |
Flink 프로젝트 만들기
Flink 프로젝트를 만드는 가장 쉬운 방법은, maven archtype을 통한 방법입니다. 아래의 스크린샷을 통해 InteliJ로 만들어 보겠습니다.
- InteliJ에서 new Project를 선택, 아래와 같은 archtype 정보로 flink 프로젝트를 선택할 것입니다만, 2021/08/15일 기준으로 1.13.2 버젼이 최신이지만, 문제가 있어서 1.13.1을 선택해주셔야 합니다.
scala
<groupId>org.apache.flink</groupId>
<artifactId>flink-quickstart</artifactId>
<version>1.13.1</version>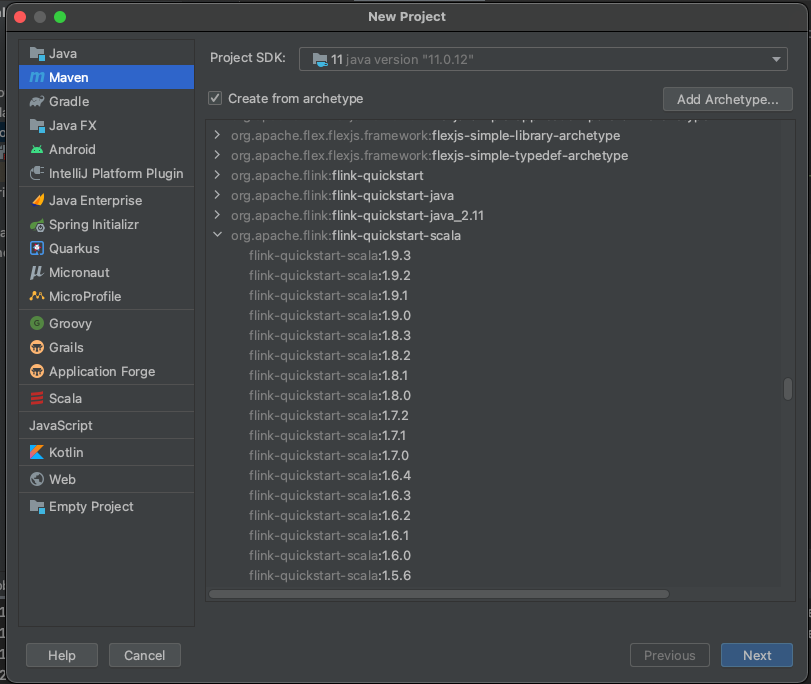 | 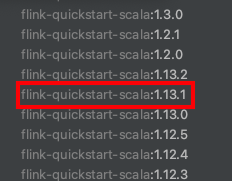 |
|---|
- 프로젝트 이름, 경로 그리고 maven 정보 설정 하기
 |  |
|---|
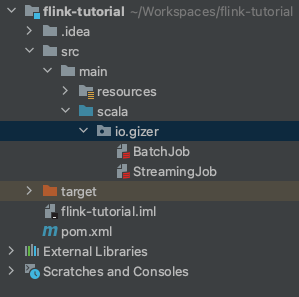
- 만들어진 프로젝트 folder structure 입니다. 여기서 BatchJob을 사용하여, 목표를 달성할 예정입니다.
Flink 코드 작성!
결과만 빨리 보려면, 아래 코드 복사 붙여넣기! (자신의 BatchJob package 명으로 변경해주세요!!)
예제코드
package io.gizer
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.util.Collector
object BatchJob {
def main(args: Array[String]) {
val env = ExecutionEnvironment.getExecutionEnvironment // flink 환경 구성
val result = env.readTextFile("path/to/file") // movielens 파일 읽기
.flatMap((event: String, out: Collector[(String, Int)]) => {
try {
val values = event.split(",") // csv ',' 나누어, 3번째 rating column만 사용
out.collect(values(2), 1) // tuple (String, Int) 데이터 내보내기
} catch {
case e: Exception => // 첫번째 헤더는 에러 처리 무시
}
})
.groupBy(0) // tuple에 첫번째를 기준으로 데이터 모으기
.sum(1) // 각 그룹에 tuple에 두번째 필드기준으로 더하기
result.print() // 결과 프린트!
// execute program
env.execute("MovieLens rate counter")
}
}결과!
실행하게 되면 결과는 아래와 같이 console.log에!
(3.5,3177318)
(4.5,2200539)
(5.0,3612474)
(1.5,399490)
(2.5,1262797)
(3.0,4896928)
(rating,1)
(0.5,393068)
(1.0,776815)
(2.0,1640868)
(4.0,6639798)끝으로
저는 Flink를 사용하기 전보다 확실히 데이터 처리하는 코드가 간결해지고, 재사용이 가능한 형식으로 봐뀌는 것을 경험 하였습니다. 데이터 처리 서버관리도, flink에서 제공하는 checkpoint와 savepoint라는 기능을 사용하면, 보다 안정적으로 새로운 코드를 출시할수 있었으며, 데이터 integrity도 잘 지켜지고 있습니다. (checkpoint와 savepoint는 다음에 따로 적어보겟습니다 ㅎ)
다음 시리즈는 위에 사용된 transformation 포함 더 많은 transformation 대한 사용법 및 실무 적용했던 경험을 적어볼 예정입니다. 혹시라도, Flink 사용에 망설이고 계신 데이터 엔지니어 분이 있다면, 이 글이 조금이나마 도움이 되기를 바랍니다.
참고 (reference)
Apache Flink (공식) - https://flink.apache.org/flink-applications.html
Techcrunch - https://techcrunch.com/2019/01/08/alibaba-data-artisans/

데이터 엔지니어가 고민해야 하는 것들과 언제 stream processing을 고려해야 하는지 알 수 있어서 좋았습니다.
Flink 맛보기도 감사합니다. OOM과 processing time 때문에 좌절하는 순간이 오면 Python으로 Flink 다루는 것을 시도해봐야겠군요. 감사합니다~