새로운 데이터 아키텍처의 시대 1편 - Modern Data Architecture
새로운 데이터 아키텍처의 시대는 2편의 시리즈로 구성되어 있습니다.
1 편 - 데이터 아키텍처의 변화
2 편 - 빅인사이트의 데이터 아키텍처를 구성
들어가면서
현시대에서 데이터의 중요성은 누구나 인지하고 있는 개념이고 생각합니다. 데이터의 중요성과 더불어 데이터가 다양한 곳에 활용되며, 수집이 되는 데이터의 종류도 많아졌습니다. 이 글에서는 데이터양과 활용성에 증가에 따라 과거부터 지금까지 데이터를 처리하기 위한 아키텍처가 어떻게 변화하였는지 알아보겠습니다.
Relational database라는 단어가 고안된 1970년 이후, 지금까지도 데이터 아키텍처의 중심에는 Relational database 있습니다. Relational database는 다대다 관계 및 transactional 한 데이터 처리를 기반으로 다양한 요구사항들을 충족시키며, 개발자들의 default 데이터 저장소로서 자리 잡았습니다. 하지만, 1990년도에 인터넷 열풍과 함께 처리해야 할 데이터가 급증하며, database는 과거 일반적으로 사용되던 거래 내역 저장에서 벗어나, 더 많은 문제를 해결하기 위한 도구로 변화되었습니다.
현재 DB의 용도는 크게 두 가지 분류의 데이터 처리로 나누어졌습니다. 이는 온라인 거래 내역 종류에 데이터 처리 OLTP (Online Transaction Processing) 그리고 다양한 문제를 풀기 위한 분석 데이터 처리 OLAP (Online Analytical Processing)입니다. 예전에는 많은 회사들이 OLTP 대한 기능에 집중했다면, 현재는 OLTP에 대한 기능은 기본이며, 경쟁사보다 우위를 차지하기 위해, 더 많은 문제를 풀기 위한 분석을 할 수 있는 OLAP에도 많은 집중을 하고 있습니다.
OLAP라는 데이터 처리 업무가 정의되는 **과정에 초기 회사들은, 운영 중인 database에 분석 쿼리를 바로 사용했었습니다. 하지만, OLAP에 사용 패턴은 OLTP와 많이 달라서, 운영환경에 성능적 저하 또는 database가 shut down 하는 문제가 많이 발생했습니다. 해당 문제를 해결하기 위해 OLTP와 개별적인 database 환경을 따로 구성하여, data를 복제하여 분석을 하는 방식으로 변화하였고, 따로 복제된 database에 요구사항과 구조가 고도화되며, 이를 EDW (Enterprise Data Warehouse)라고 부르게 됐습니다.
OLTP vs OLAP 특성
| 특성 | OLTP | OLAP |
|---|---|---|
| 주요 읽기 패턴 | Query 당 적은 양에 레코드를 Key 기준으로 가져온다. | Query 당 많은 양에 레코드를 집계한다. (sequential read 성향) |
| 주요 쓰기 패턴 | 임의 접금, 사용자 입력을 낮은 지연 시간으로 기록 | 대규모 불러오기 또는 이벤트 스트림 처리 |
| 주요 사용처 | 웹 애플리케이션을 통한 사용자 | 의사결정 지원에 필요한 내부 분석가 |
| 데이터 표현 | 데이터의 최신 상태 | 시계열 데이터 |
| 데이터 셋 크기 | Gigabytes에서 terabytes | Terabytes에서 petabytes |
| 읽기/쓰기 비율 | 쓰기보다 읽기에 빈도가 높은 편이다. | 읽기보다 쓰기에 볼륨이 높다. (이벤트 스트림일 경우 쓰기 빈도도 높아진다.) |
출처: https://www.amazon.com/Designing-Data-Intensive-Applications-Reliable-Maintainable/dp/1449373321 p91
데이터 아키텍처의 과거 - EDW
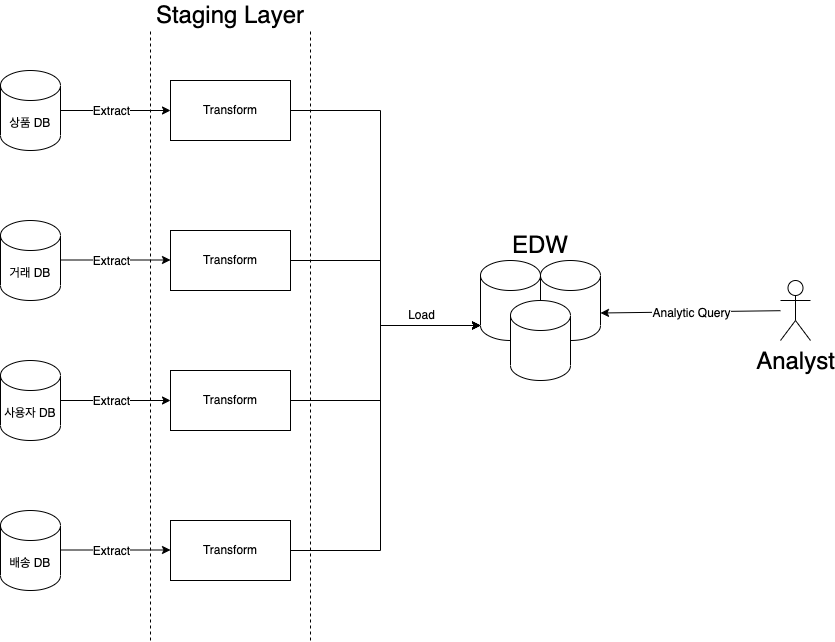
EDW는 위 그림과 같이 다양한 structured data source로부터 ETL (Extract Transform Load)을 거쳐, 하나의 RDBMS에 관리됩니다. EDW는 데이터를 동기화를 위해 주기적으로 ETL 작업이 실행됩니다. 일반적으로 ETL 작업에 주기는 월, 주 또는 일 단위로 진행되지만, 데이터의 적시성에 높은 우선순위가 있는 EDW 같은 경우 시간 단위 또는 10분 단위로 mini batch로 운영되는 경우도 있습니다.
장점
- 운영 database와 분리되어, 대용량 분석 query를 서비스에 지장 없이 사용할 수 있습니다. 운영 database에 균등한 성능이 제공되어야 한다면, 필수적으로 분리해야 합니다.
- 새로운 분석 요구사항 또는 데이터 소스가 추가되었을 시, 개발이 운영 database에 영향을 주지 않기 때문에, 확장에 유연성을 가지고 있습니다.
- ETL을 통해 데이터 schema가 분석 적합하게 변화시켜, query의 성능을 향상시킬 수 있습니다. EDW는 통상적으로 운영 database의 데이터를 그대로 사용하지 않고, staging layer에서 ETL 작업을 수행하여, 데이터를 분석에 적합하게 함축적으로 변환하여, EDW에 적재합니다.
단점
- EDW 또한 내부 분석가들을 위한 운영 서버이기 때문에, 기능 업데이트하려면 여러 의존성이 존재합니다.
- 데이터 분석의 환경이 RDBMS로 제한되어, 성능 그리고 분석의 유연성을 잃을 수 있습니다. e.g. 3NF 디자인, 테이블 형식의 데이터 표현.
- 대용량 데이터를 지닌 DB를 계속 운영해야 하기 때문에 서버 운영비가 많이 나오게 됩니다. e.g. 실제로 분석 쿼리는 일, 주, 월, 년과 같은 주기로 사용되기 때문에 지속적으로 운영될 필요는 없습니다.
- RDBMS에 적재할 수 있는 데이터만 사용 가능합니다.
- 데이터가 많아지면서, ETL 작업으로 고도화하는데 추가적인 자원이 많이 사용됩니다.
- 데이터 단위로 보안 및 관리가 힘듭니다.
- 가공 처리를 통해, 원천 데이터가 내포하고 있는 의미를 잃을 수 있습니다.
EDW 결론
EDW 기업에 필요한 OLAP 요구사항을 충족 시켰지만, 기하급수적으로 증가하는 데이터와 변화 속도에 대응할 수 없었으며, 일반적인 SQL과 BI data 이외에도 많은 분석에 대한 needs가 생기면서, 개발자들은 EDW보다는 big data를 다루기 적합한 cloud 생태계로 데이터 아키텍처를 이전하게 만들었습니다.
새로운 방향 - MDA (Modern Data Architecture)
OLAP의 중요도는 예전과 비교할 수 없을 만큼 높아졌습니다. 요즘 회사들이 방대한 데이터를 수집하는 형태로 변경되고, 다양한 데이터 분석에 대한 요구사항들이 생겨났습니다. 일반적인 EDW의 통계 분석이었던 매출 금액, 상품 조회 수, 사용자 증가 추이 외에도 로그 분석, 예측 모델링, 사용자 행동 분석을 통한 개인화 마케팅, 개인화 추천, 유입 채널 분석 등 다양한 요구사항들이 생기며, EDW는 그냥 하나 usecase를 처리하는 데이터 저장소 되었습니다. 개발자들은 더 이상 one size fit all (망치로만 집 짓기) 같은 방법으로 요구사항을 처리할 수 없었으며, 분석 usecase에 맞춤형으로 데이터를 분석가들에게 제공해야 했습니다. AWS에서 2022년도에 “Modern Data Architecture Rationales on AWS”이라는 whitepaper를 출간하였습니다. 해당 whitepaper는 다양한 사례를 기반으로 EDW가 풀지 못한 문제를 어떻게 MDA (formerly Lake House)로 해결할 수 있는지 설명합니다.
MDA 특성
- 데이터 아키텍처는 확장성, 가격 대비 성능이 뛰어나야 합니다.
- 데이터 아키텍처는 용도에 맞는 데이터 서비스를 쉽게 구축할 수 있어야 합니다.
- 데이터 아키텍처는 저장되는 데이터 포맷에 제약 없어야 합니다.
- 데이터 아키텍처는 저장소 리소스와 컴퓨터 리소스가 분리되어 필요한 리소스만 사용할 수 있어야 합니다.
- 데이터 아키텍처는 데이터의 이전이 용이해야 합니다.
- 데이터 아키텍처는 다양한 방법으로 데이터 처리가 가능해야 합니다.
- 데이터 아키텍처는 데이터를 기준으로 보안 그리고 관리가 가능해야 합니다.
AWS가 정의한 MDA 구성

MDA (Modern Data Architecture)는 총 5개의 Layer로 구성되며, 각 Layer 별로 데이터가 추상화되어, MDA의 특성을 제공합니다.
Raw layer
Raw layer에 사용되는 저장소는, 대용량의 데이터를 장기간 동안 저렴하게 데이터를 보관할 수 있어야 합니다. 특히 보안과 데이터 재처리 관점에서 데이터의 최초 모습을 최대한 유지하여, 추후 요구사항에 따라 원하는 형식으로 데이터를 변환 가능하게 데이터를 제공해야 합니다. 해당 layer는 원시 데이터 (Raw Data)를 다루기 적합한 layer입니다. (예전에 ETL을 AWS에서 ELT로 변경하여 많이 작업하였는데, 일단 data를 load 하여, 원시 데이터를 보존하여, 추후 transform을 통해 원하는 요구사항에 맞게 데이터를 사용하는 방식으로 많이 사용됐었다.)
Standardized layer
보통은 raw layer와 통합하여, 사용되는 layer로 통상적으로 file format이 정규화 됩니다. Standardized layer 목적은 데이터가 바로 consume 될 수 있게, big data에 적합한 file format으로 데이터들이 변경하는 것이며 (avro, parquet, json, tsv 그리고 csv etc), 해당 파일 포맷을 통해, schema validation, schema evolution, data quality control 그리고 data cleansing을 할 수 있습니다. 이미 분석 쿼리를 사용할 수 있는 최적화된 포맷으로 변경되어, 추가로 데이터 validation 필요 없이, EDA(Exploratory Data Analysis)를 진행 가능합니다.(e.g. AWS Athena, Presto etc) Standardized layer 이후로는 모든 데이터가 structured로 변경되여, 원천 데이터 (Source Data)를 다루는 layer라고 볼 수 있습니다.
Conformed layer
일반적으로, 어떤 회사에서든 공용적으로 사용되는 도메인 모델이 존재하며, 해당 entities들을 conformed entities라고 부릅니다. Conformed entities들은 통상적으로 회사의 주된 business model이기 때문에, conformed layer에서 중앙 관리되며, entities들을 최대한 일찍 형상화 시킵니다.
중앙에서 관리하는 형식으로 데이터 파이프라인을 구성하면, entities들의 ownership을 명확하게 구분할 수 있는 장점이 있습니다. Ownership을 여러 팀에서 나눠 갖게 된다면, 데이터 관리 차원에서 데이터를 관리하는 차원에서 애매모호한 정의들이 생겨나며, 최악의 경우에는 각 ownership을 가진 팀이 데이터를 다르게 처리하여, 정합성이 낮아지는 결과를 초래할 수 있습니다.
Enriched layer
Enriched layer는 logical layer로서 conformed entity와 standard raw data를 통해 서비스를 제공하거나, 새로운 서비스를 발굴할 수 있도록 데이터를 제공합니다.
해당 layer에서는 비즈니스에 최대한 많이 유용한 서비스를 제공해야 하며, 특별한 경우에는 하나의 서비스가 다양한 비즈니스 분야에 효과적으로 사용되며, 이를 Golden datasets이라 부릅니다. Golden datasets은 다시 결과물을 만들어 data lake로 넘겨져 많은 곳에 원천 데이터로 공유되기도 합니다.
Conformed layer와 Enriched layer를 구성할 때, 두 가지 종류에 방식이 존재합니다.
- Centralized pattern: 중앙에서 도메인을 정해놓고, 모두 통제. (데이터 도메인에 제한, time-to-market이 느려짐 하지만 governance는 좋아짐)
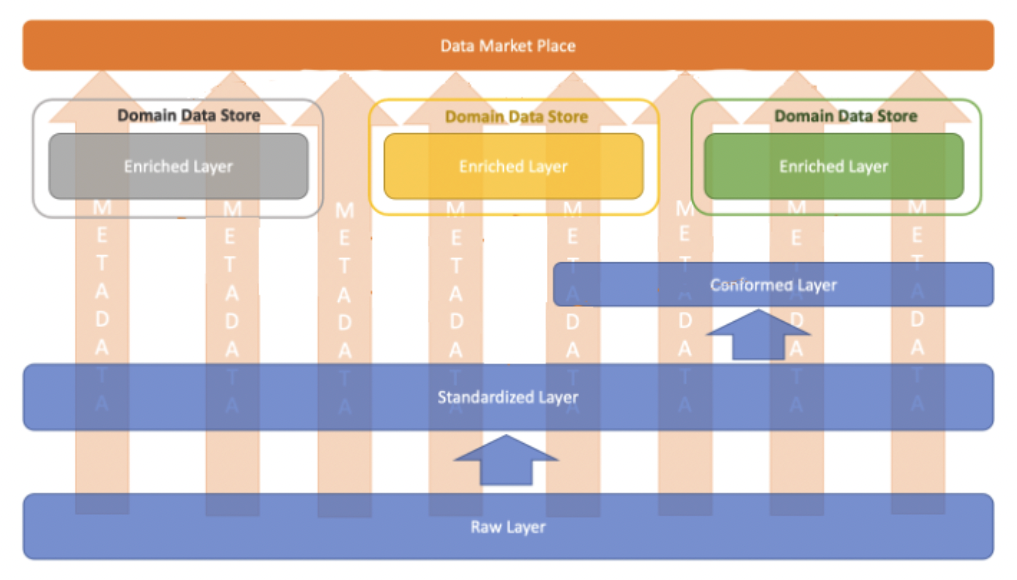
출처: [https://docs.aws.amazon.com/whitepapers/latest/modern-data-architecture-rationales-on-aws/modern-data-architecture-layers-deep-dive.html](https://docs.aws.amazon.com/whitepapers/latest/modern-data-architecture-rationales-on-aws/modern-data-architecture-layers-deep-dive.html)- Distributed pattern: 개별 팀에서 도메인을 관리하며, 새롭게 발굴된 도메인에 대한 dataset도 쉽게 추가 가능 (빅인 사이트 data architecture가 추구하는 방향)
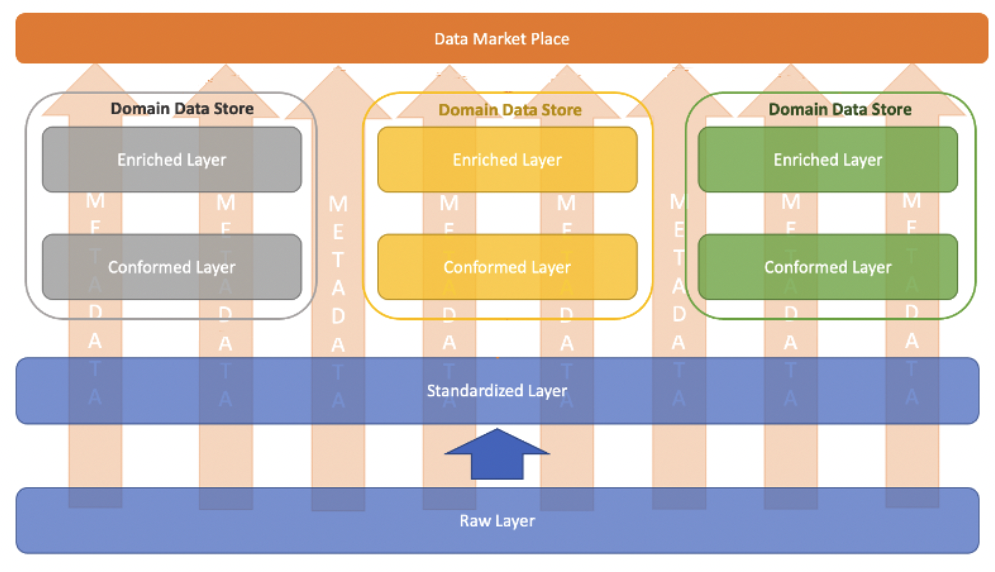
출처: [https://docs.aws.amazon.com/whitepapers/latest/modern-data-architecture-rationales-on-aws/modern-data-architecture-layers-deep-dive.html](https://docs.aws.amazon.com/whitepapers/latest/modern-data-architecture-rationales-on-aws/modern-data-architecture-layers-deep-dive.html)MDA의 사용 사례
Modern 한 데이터 서비스는 일반적으로 사용하는 SQL의 table 형식의 데이터 이외에도 많은 사용 사례들이 있습니다. 아래는 그 예제입니다.
| 사용 사례 | 적합한 시스템 |
|---|---|
| 일반 이커머스 데이터 분석 | RDBMS |
| 머신러닝, 추천 엔진 | SageMaker, Spark MLib |
| Log, event 분석 (시계열 데이터) | Elasticsearch, Apache Druid, Pinot, Clickhouse |
| Social Network System | Neo4J, ArangoDB, Dgraph |
Data 시스템은 대부분 특정 사례를 해결하기 위해, 사례에 맞게 특화되어 개발됩니다. 특정 모델을 기반으로 만들어진 시스템은 다른 모델을 흉내 낼 수 있지만, 그 결과는 대부분 비효율적이고, 성능적으로 문제가 생깁니다. 예제로, 아래는 친구에 친구를 찾는 문제로 RDBMS와 Neo4J의 성능을 비교한 것입니다. 이처럼 특화된 시스템을 잘 사용하면, 동일한 성능에 서버라도 아주 큰 성능에 차이를 보이게 됩니다.

출처: https://neo4j.com/news/how-much-faster-is-a-graph-database-really/
MDA에 목표는 사용목적에 맞게 특화된 시스템에 데이터를 로드하여, 데이터 서비스를 제공하는 것입니다. 하나의 데이터 소스에서 여러 데이터 서비스를 제공해야 한다면, MDA가 보다 효율적으로 사용될 수 있습니다. 예시로, 다양한 데이터 서비스를 제공하게 된다면, 복잡한 ETL 과정을 처리하게 되는데, MDA에서는 Raw, Standized layer를 통해 공통으로 처리되는 데이터를 stage를 나누어, 데이터 처리를 중복으로 하는 것을 방지하여, CPU 리소스를 효율적으로 사용할 수 있습니다. 그리고, MDA 특성인 저장소 리소스와 컴퓨터 리소스가 분리되어 있기 때문에 제공되던 데이터 서비스가 더 이상 필요 없다면, 해당 서비스를 삭제하고, 저장소 리소스만으로 데이터를 유지할 수 있기에 서버 비용을 많이 절약할 수 있습니다.
마치며
과거에는 OLTP에 대한 요구사항이 많았다면, 점차적으로 OLAP 유효성이 검증되며, 다양한 분석 요구사항이 생겨났습니다. 이제는 Data Warehouse 하나만으로는 모두 충족할 수 없는 상황이 되었고, 이는 기업들의 데이터 아키텍처를, 상황에 맞는 분석 환경을 즉석 만들 수 있는 구조로 진화하게 만들었습니다. 요즘 데이터 아키텍처는, 특정 기술에 종속되기 보다, 데이터를 중심으로 점진적으로 데이터가 처리되며 환경이 만들어질 수 있는 MDA 형태가 되었습니다.
이번 “새로운 데이터 아키텍처의 시대 1편 - Modern Data Architecture”편에서는, 과거부터 현재까지 데이터 아키텍처가 어떻게 변화하였고, 변화의 과정에 어떤 단점들을 보안하면서 진화되었는지, 사용 사례와 함께 알아보았습니다. 다음 글에서는, 현재 빅인사이트에서 사용되는 데이터 아키텍처의 소개, 설계 과정을 거치며 내린 결정 그리고 겪었던 다양한 경험을 공유하는 글로 돌아오겠습니다.
긴 글을 시간 내어 읽어주셔서 감사합니다.
레퍼런스
