Collaborative Filtering을 활용한 여러가지 추천 방법들이 존재한다. kNN 기법을 활용한 user 혹은 item based CF, Matrix Factorization, Neural Collaborative Filtering 등등...
CF에서의 핵심은 아래 두가지다.
나와 비슷한 사람이 좋아하는 아이템을 추천
내가 좋아한 아이템과 비슷한 아이템 추천
즉 user, item간의 유사도를 측정하는 것이 핵심이라고 할 수 있고, MF 계열의 모델은 이를 나름대로 수행해왔다.
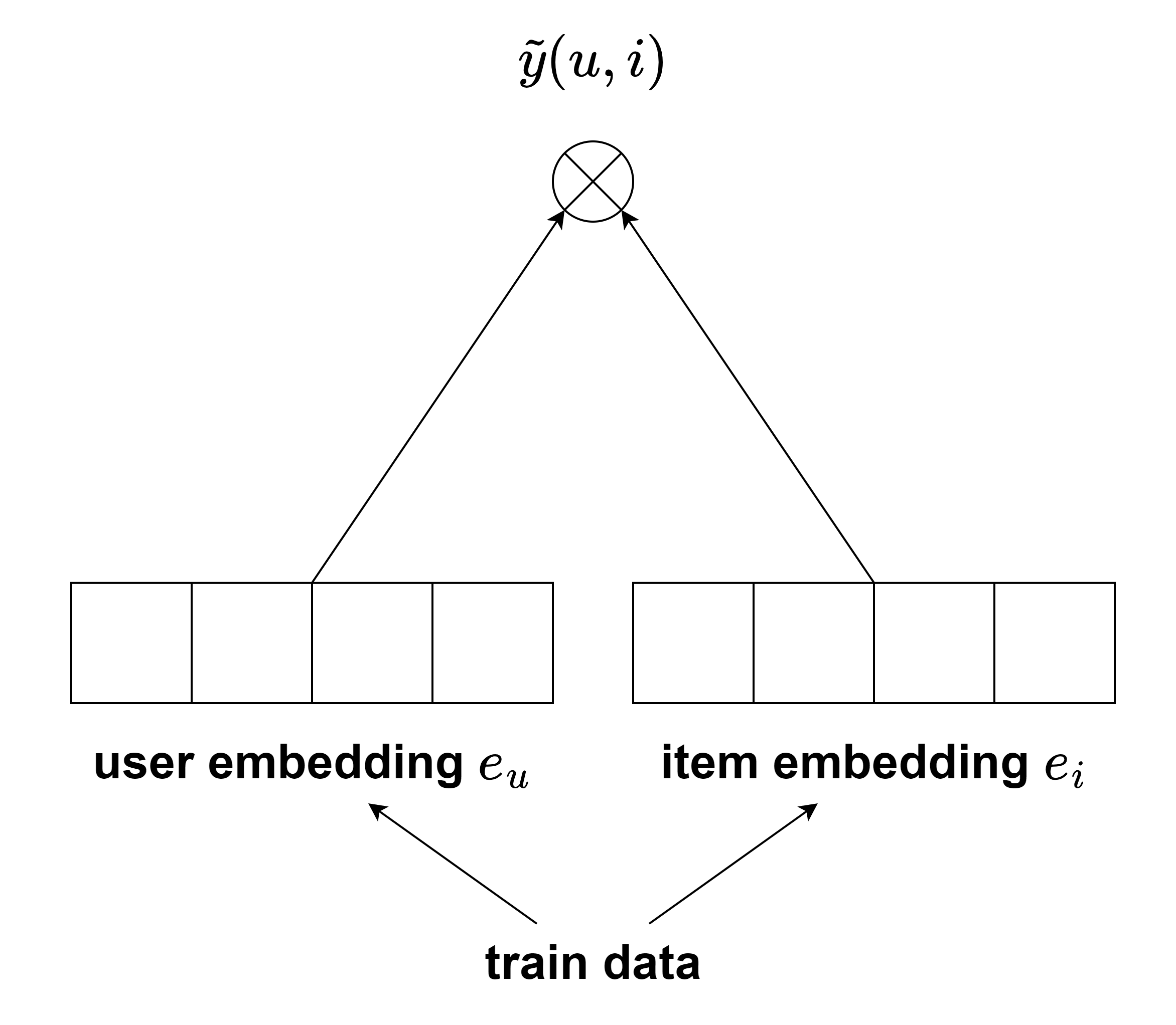
위 그림은 대략적으로 Factorization 계열 모델을 설명한다. 물론 context를 반영할 수도 있고, inner product가 아닌 NCF와 같이 neural network의 구조를 사용할 수도 있지만, 아주 기본적인 모델을 예시로 들었다.
앞서 말했듯이, user, item간의 유사도를 학습하는 것이 핵심이다. 그런데 위 그림에서 알 수 있듯 이를 반영하는 부분이 model에 나타나있지 않다. 즉, 기존의 모델들은 이러한 관계를 직접적으로 학습하지는 않고, y~와 y의 차이를 이용해 간접적으로 학습하게 된다.
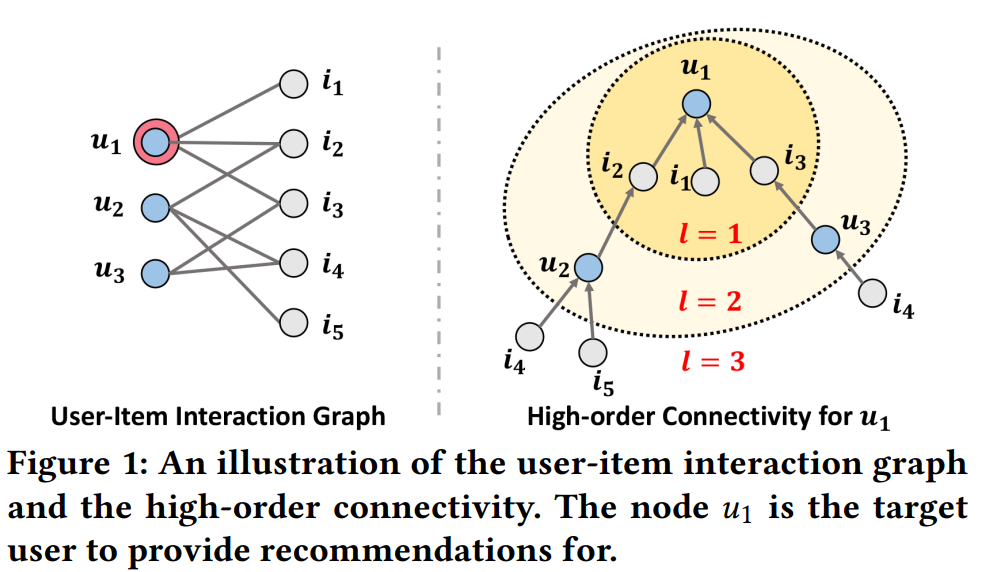
논문에서 발췌한 그림이다. 왼쪽 그림에서 u1을 기준으로 생각하면 오른쪽과 같은 그래프를 만들 수 있다. i1,i2,i3과 직접적으로 연결되어있고, i2,i3을 구매한 u2,u3와는 한단계 건너 연결되어 있다. 이런 상황에서 i4,i5 중 하나를 u1에게 추천해야 한다면, i4 or 5→u1 를 나타내는 경로는 아래와 같다.
i4: (i4→u2→i2→u1), (i4→u3→i3→u1)
i5: (i5→u2→i2→u1)
rating과 같은 요소들을 무시한다면, 경로가 더 많은 i4를 추천하는 것이 좀 더 reasonable하다. 이 때 주의해야 할 사항이 두가지 있다.
너무 멀리 떨어진 경우까지 고려하면 오히려 정확도가 떨어질 수 있다.
가까운 요소의 중요도가 멀리 떨어진 요소의 중요도보다 더 크다.
해당 내용을 단지 y~와 y의 차이만을 이용해 간접적으로 embedding에 반영하던 기존 모델들과 달리 NGCF는 위의 설명한 내용을 embedding 과정에서 직접적으로 학습하는 방법을 제시한다.
Neural Graph Collaborative Filtering
시작하기에 앞서 몇가지 용어를 정리하고 넘어가자.
layer는 얼마나 멀리 떨어진 node까지 embedding에 반영할 것인지를 의미한다.
message 라는 개념이 등장한다. mu←i 처럼 쓰는데, 말 그대로 i가 u에 전달한 메세지, 정보 정도로 이해하면 된다.
이제 출발 할 준비가 끝났다. NGCF는 어떻게 상호작용을 embedding에 직접적으로 반영할 수 있는 것 일까? 간단한 예시를 위해 layer가 한개인 경우를 먼저 보자.
message부터 시작한다. message는 아래와 같이 정의된다.
mu←i=f(ei,eu,pui)(1)
어떤 아이템 i가 어떤 유저 u에게 전달하는 message는 각각의 embedding ei,eu와 decay pui에 대한 f라는 함수인 것이다. NGCF에서는 이를 아래와 같이 정의했다.
mu←i=∣Nu∣∣Ni∣1(W1ei+W2(ei⊙eu))(2)
식에서 Nu,Ni 는 각각 u,i의 neighbor다. (Figure 1에서 u1의 neighbor는 i1,i2,i3 이다.) 즉, i가 u에 주는 message는 아이템 그 자체에 대한 정보(W1ei)와 해당 아이템 i와 유저 u의 상호작용 정보(W2(ei⊙eu)) 의 합에 어느정도의 decay (1/∣Nu∣∣Ni∣) 를 주었다고 해석할 수 있다.
Figure 1에서 u1은 i1,i2,i3 3개의 아이템과의 상호작용을 이루었듯이, 하나의 mu←i 로는 임베딩을 설명하기 힘들다. 따라서 해당 유저와 연결된 모든 아이템, 즉 Nu에 포함된 모든 i에 대해 mu←i 를 계산해준다. 이에 추가적으로 자기 자신에 대한 정보인 mu←u를 고려하여 다음 단계의 user embedding을 생성한다. 식으로 써보면 아래와 같다.
eu(1)=LeakyReLU(mu←u+i∈Nu∑mu←i)(3)
즉, 이러한 과정을 거쳐 생성된 user embedding eu(1) 은 기존의 user embedding eu 와는 다르게, Nu에 포함된 i들과의 상호작용이 반영되어 있음을 알 수 있다. 마찬가지 방법으로 item embedding ei(1) 를 만들 수 있을 것이고, 이는 기존의 item embedding ei와는 다르게, Ni에 포함된 u들과의 상호작용이 반영 될 것이다.
이제 이 과정을 l개의 layer에 대해서 일반화해보자. 아무런 layer를 거치지 않은 기본 embedding, 우리가 MF, NCF와 같은 모델에서 사용하는 embedding을 0개의 layer를 거쳤다고 해서, eu(0),ei(0) 라고 할 수 있다. l=0인 경우에 대한 eu(l),ei(l)은 식 (2), (3)을 이용해 쉽게 얻을 수 있다.
위의 식 (4), (5)를 통해 이제 우리는 l개의 layer를 통과한 경우에 대한 user, item embedding을 구할 수 있다. 이후 0번째 부터 L번째 까지의 임베딩을 모두 concatenate한 후, 내적을 이용하여 최종적으로 y^NGCF를 계산한다. 수식으로 써보자면 아래와 같다.
eu∗=eu(0)∥⋯∥eu(L),ei∗=ei(0)∥⋯∥ei(L)(6)
y^NGCF(u,i)=eu∗⊺ei∗(7)
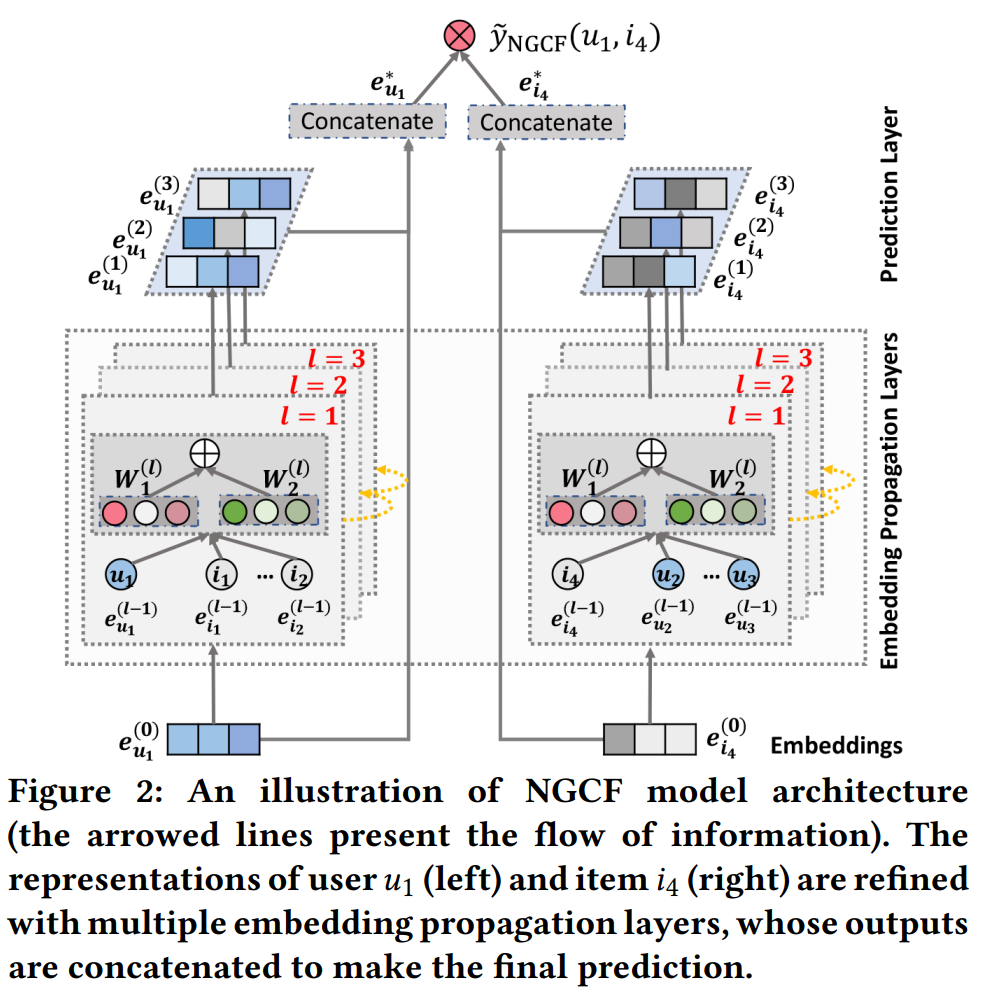
위의 Figure 2는 해당 과정을 그림으로 잘 나타낸 것이다. Figure 1의 예시와 함께 보도록 하자.
eu1(0)은 일반적인 방법으로 만드는 벡터다. layer를 한번 거쳐서 나온 각각의 embedding들에 대해서
eu1(1) 은 i1,i2,i3과의 interaction을,
eu2(1) 는 i2,i5과의 interaction을,
eu3(1) 는 i3,i4과의 interaction을,
담고 있을 것이다. 마찬가지로 item에 대해서도
ei1(1) 은 u1과의 interaction을,
ei2(1) 은 u1,u2과의 interaction을,
담고 있을 것이다. (다 적지는 않았지만 i3,i4,i5에 대해서도 동일하다.)
그렇다면 layer를 두번 통과한 경우를 살펴보자. eu1(2)는 eu1(1),ei1(1),ei2(1),ei3(1)를 조합하여 만들어지는 벡터다. 이 때, 각각의 eu(1) 또는 ei(1)에서 직접적으로 연결된 상호작용을 학습했기 때문에, 이번 경우에는 한 칸 떨어진 상호작용 까지 반영이 가능해진다. 예를 들어 ei2(1)에는 i2와 u1,u2에 대한 상호작용 정보가 이미 반영되어있다. 즉, eu1(2)는 ei2(1)를 이용하여 한 칸 떨어진 u2의 정보까지 반영이 가능해진 것이다. 이를 일반화하면 layer가 늘어날수록, 더 멀리 떨어진 node와의 상호작용을 embedding에 반영할 수 있게된다. 마치 CNN에서 layer를 거칠수록, 멀리 있는 점의 정보를 가져오는 것과 비슷한 맥락이다.
결론
상호작용을 간접적으로 학습하던 기존의 MF계열과 달리, embedding 단에서 직접 학습하다보니, 성능이 뛰어남을 확인할 수 있다. 심지어 마치 CV 분야에서 CNN이 공유된 parameter를 사용하여 parameter 수를 줄인 것처럼, 복잡해보임에도 불구하고 parameter 수는 많이 늘어나지는 않는다. (늘어나긴 한다.)