Breaking the Length Barrier: LLM-Enhanced CTR Prediction in Long Textual User Behaviors
https://arxiv.org/pdf/2403.19347
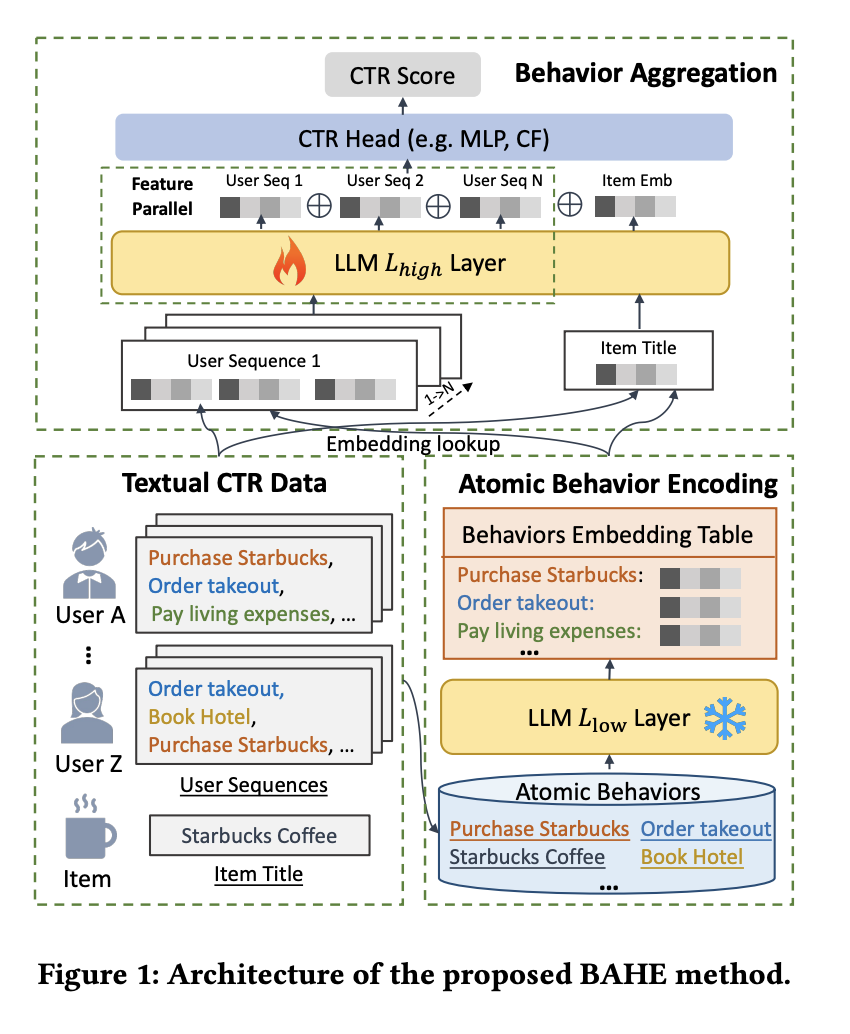
LLM을 CTR예측에 쓴다고 하면 일단은 피처를 텍스트로 넣는 것을 생각할 수 있는데, 이러면 토큰이 많이 필요하니까 아무래도 트레인/인퍼런스 모두 부담이 된다. 그래서 이 페이퍼에서는 User Action / Item 같은 것을
1) pretrained LLM의 Lower layer를 활용해서 인코딩 (그냥 mean pooling해도 잘된다고 한다)
2) 같은 LLM의 Higher layer들은 1)을 이해할 수 있을테니, 이거를 가지고 user action / item 의 인터랙션을 계산한 후에 CTR계산하는 MLP에 넣어준다.
CTR 모델의 구조를 다룬다기보다는 LLM을 가지고 효율적으로 sequences를 인코딩하는 방법에 가깝다. 물론 LLM을 안 써도 할 수 있지만, 잘 pretrain된 LLM을 가지고하면 처음부터 인코더를 훈련하는 것보다는 훨씬 나을 것이다.
궁금했던 점
1) eq(6) -> eq(7) 로 넘어갈 때 뭔가 pooling 같은 것이 있어야 할 것 같은데 잘 나와있지가 않다
2) 이런 회사들은 그냥 user embedding / item embedding도 퀄리티가 무지 좋을텐데, 그냥 이런거 써서 seqences를 인코딩 하는 것에 비해서도 장점이 있는지?가 궁금했다. 여기서는 그냥 LLM을 사용한 방법끼리만 비교를 해놓았다. (그냥 둘 다 써도 될 수도..)

노션 대용 velog