SQL 파싱과 최적화
1.구조적, 집합적, 선언적 질의어
- SQL은 구조적, 선언적, 집합적 질의어
- 하지만 그 결과 집합을 만드는 과정은 절차적(프로시저 필요) -> 프로시저를 만드는 DBMS 내부 엔진이 SQL 옵티마이저
- SQL 최적화 : DBMS 내부에서 프로시저를 작성하고 컴파일해서 실행 가능한 상태로 만드는 과정
2. SQL 최적화
1) SQL 파싱
- SQL 파서가 파싱 진행
- SQL 파서가 파싱 진행
- 파싱 트리 생성
- Syntx 체크
- Semantic 체크(의미상 오류, ex - 존재하지 않는 테이블/사용, 권한 문제 확인)
- SQL 파서가 파싱 진행
2) SQL 최적화
- 옵티마이저 진행
- 효율적인 실행 경로 선택해서 진행
- DB 성능을 결정하는 핵심적인 엔진
3) 로우 소스 생성
- 옵티마이저가 선택한 실행 경로를 실행 가능한 코드/프로시저로 포맷팅
- 로우 소스 생성기
3. SQL 옵티마이저
- DBMS 핵심 엔진
- 사용자가 원하는 작업을 가장 효율적으로 수행할 수 있는 최적의 데이터 액세스 경로를 선택해준다
1) 사용자로부터 전달받은 쿼리를 수행하는데 후보군이 될만한 실행계획들을 찾음
2) 각 실행 계획의 예상 비용 산정
- 데이터 딕셔너리에 미리 수집해 놓았음(오브젝트 통계/시스템 통계)
3) 최저 비용을 나타내는 실행계획을 선택
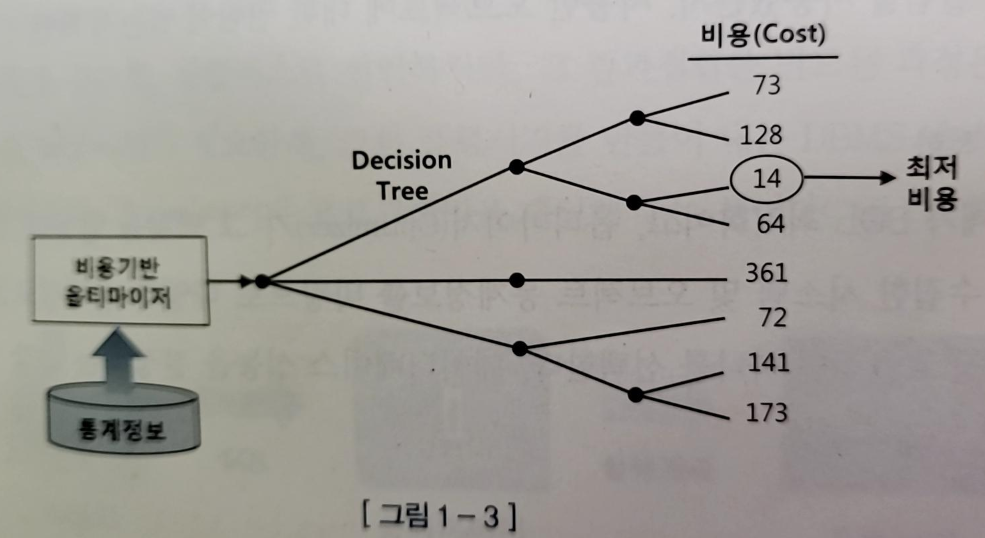
4. 실행계획과 비용
- 실행계획을 통해 SQL 실행 경로를 미리 볼 수 있다
- postgresql의 경우 explain 명령어를 통해 확인할 수 있다
- 내가 작성한 SQL의 테이블 스캔/인덱스 스캔 여부, 어떤 인덱스인지 등에 대해 확인할 수 있다
- 예상과 다른 방식으로 처리된다면 실행경로 변경이 가능하다
gather_table_stats로 통계 정보 수집
autotrace 활성화 후 sql 실행 시 실행계획 확인할 수 있음 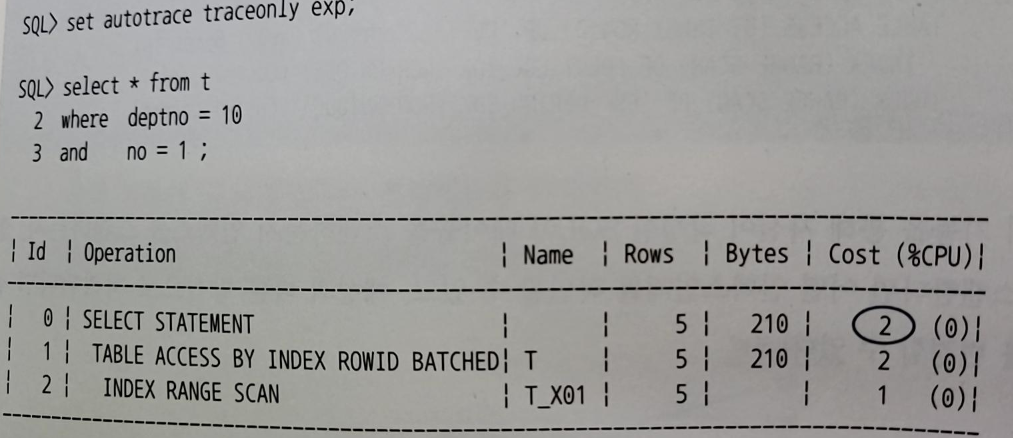
- 비용은 예상 IO 횟수, 예상 소요 시간을 표현한 값이다
- 비용에 따라 선택이 달라진다
- index hint, full scan hint 등을 줄 수 있다
- cost는 어디까지나 예상값이다
5. 옵티마이저 힌트 대신 pg_hint_plan
- 옵티마이저도 한계가 있는데 통계 정보에 담을 수 없는 데이터 또는 업무 특성을 이용해 효율적인 경로를 찾을 수 있다
- 옵티마이저 힌트를 통해 데이터 엑세스 경로를 바꿀 수 있다
- postgresql은 옵티마이저 힌트 대신 pg_hint_plan을 사용하면 된다
- hint 이상으로 plan tree 자체를 변경하는 방식
2. SQL 공유 및 재사용
1. 소프트 파싱 VS 하드 파싱
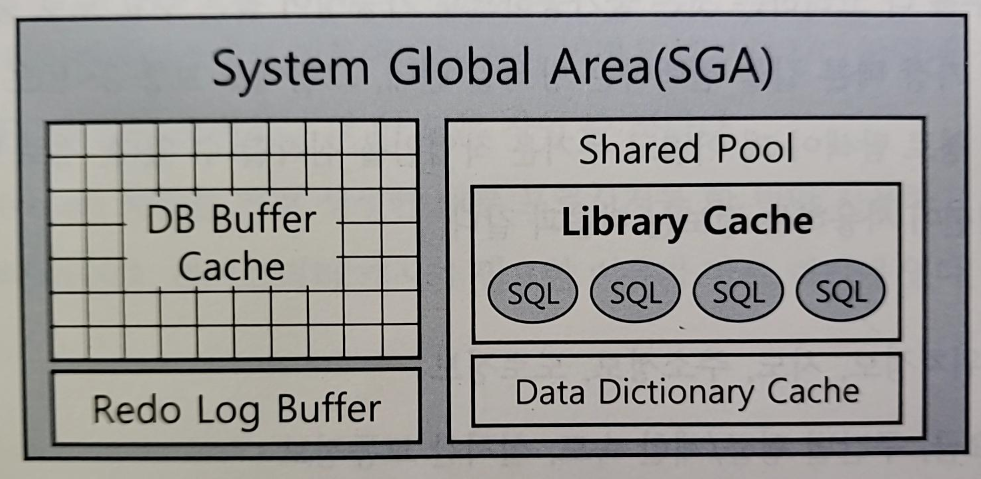
- 라이브러리 캐시 : SQL 파싱, 최적화, 로우 소스 생성 과정을 거쳐 내부 프로시저를 반복 재사용할 수 있도록 캐싱해두는 메모리 공간
- 라이브러리 캐시는 SGA 구성요소이다
- SGA(System Global Area) : 서버 프로세스와 백그라운드 프로세스가 공통으로 액세스하는 데이터와 제어 구조를 캐싱하는 메모리 공간
파싱 과정
-> 사용자가 SQL 전달
-> DBMS는 SQL을 파싱
-> 해당 SQL이 라이브러리 캐시에 존재하는지 여부 확인
O -> 캐시에서 찾으면 실행단계로 넘어감
X -> 찾지 못하면 최적화 - 소프트 파싱 (O) : SQL 을 캐시에서 찾아 곧바로 실행하는 것
- 하드 파싱(X) : 찾는 것에 실패해 최정화 및 로우 소스 생성 단계까지 모두 거치는 것
- SQL 최적화 과정은 너무 많은 경우의 수가 있기 때문에 하드하다
ex) 조인 순서, 조인 방식, 테이블 전체 스캔여부, 인덱스 스캔 여부, 인덱스 스캔 방식 등 - 옵티마이저는 연산에 아래와 같은 정보들을 사용함
- 테이블, 컬럼, 인덱스 구조에 관한 정보
- 오브젝트 통계
- 시스템 통계
- 옵티마이저 관련 파라미터
- 이렇게 어렵게 생성한 내부 프로시저를 한번 사용하고 버리는 것은 비효율적이기 때문에 라이브러리 캐시를 이용하게 된다
2. 바인드 변수의 중요성
1) 이름 없는 SQL 문제
- SQL은 이름이 없고 텍스트 자체가 SQL 이름 역할을 한다
- 딕셔너리에 저장하지도 않고 캐시 공간에 적재만 하고 공간이 부족하면 버려지게 된다
- SQL 텍스트가 변하면 SQL ID도 변한다
- 특히 일회성 SQL도 많기 때문에 이를 다 저장하는 것은 많은 공간이 필요하며 속도도 느려진다
2) 공유 가능 SQL
- DBMS에서 발생하는 부하는 대개 과도한 I/O가 원인이다
- 그렇지 않음에도 불구하고 CPU 사용률은 급격히 올라가는 경우가 있는데 이는 동시다발적으로 발생하는 SQL 하드파싱이 원인일 때가 있다
String SQLStmt = " SELECT * FROM CUSTOMER WHERE LOGIN_ID = '" + login_id + "'";
- 위와 같이 짰을 때 내부 프로시저를 하나씩 생성해서 라이브러리 캐시에 적재하게 된다
- 프로시저를 여러개 생성할 것이 아니라 프로시저 하나를 공유하면서 재사용하는 것이 마땅하다
- 파라미터 Driven 방식으로 SQL을 작성하는 방법이 제공되는데 바인드 변수가 바로 그것이다
String SQLStmt = " SELECT * FROM CUSTOMER WHERE LOGIN_ID = ? "- 라이브러리 캐시를 조회하면 아래와 같이 SQL 하나만 발견된다
SELECT * FROM CUSTOMER WHERE LOGIN_ID = :1- SQL 하드파싱은 최초 한번만 일어나고 캐싱된 SQL을 여러 고객이 공유하며 재사용하게 된다
데이터 저장 구조 및 I/O 메커니즘
- SQL 튜닝은 IO 튜닝이라고 해도 과언이 아니다
1. SQL이 느린 이유
- 십중팔구 I/O, 구체적으로 Disk IO 때문이다
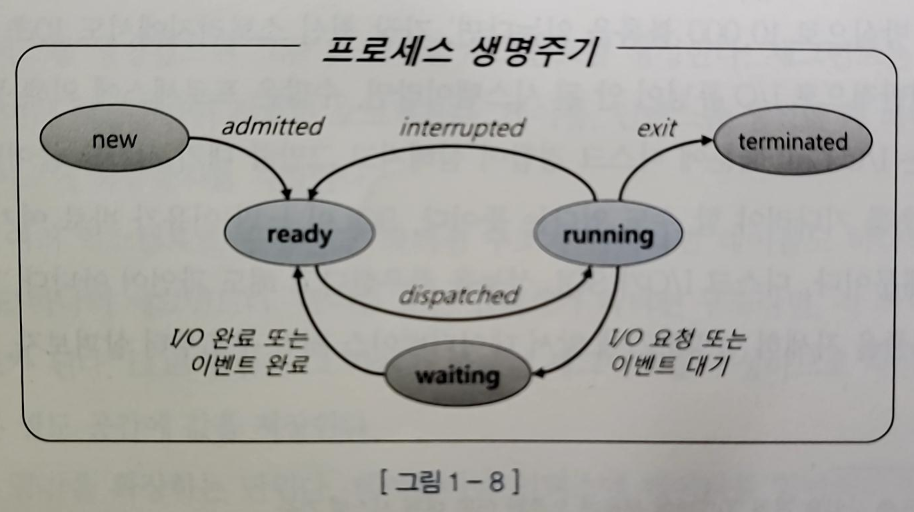
- 프로세스는 위와 같은 생명주기를 가지며 수시로 interrupt 당한다
- 특정 순간에는 하나의 프로세스만 CPU를 사용할 수 있다
- disk에서 데이터를 읽을 떄 interrupt가 걸리게 된다
-> IO가 많으면 성능이 느리다 - 스토리지 성능은 느리고, IO 튜닝이 안된 시스템이라면 IO Call 때문에 디스크 경합이 심해지고 그만큼 대기시간도 늘어난다
2. 데이터베이스 저장 구조
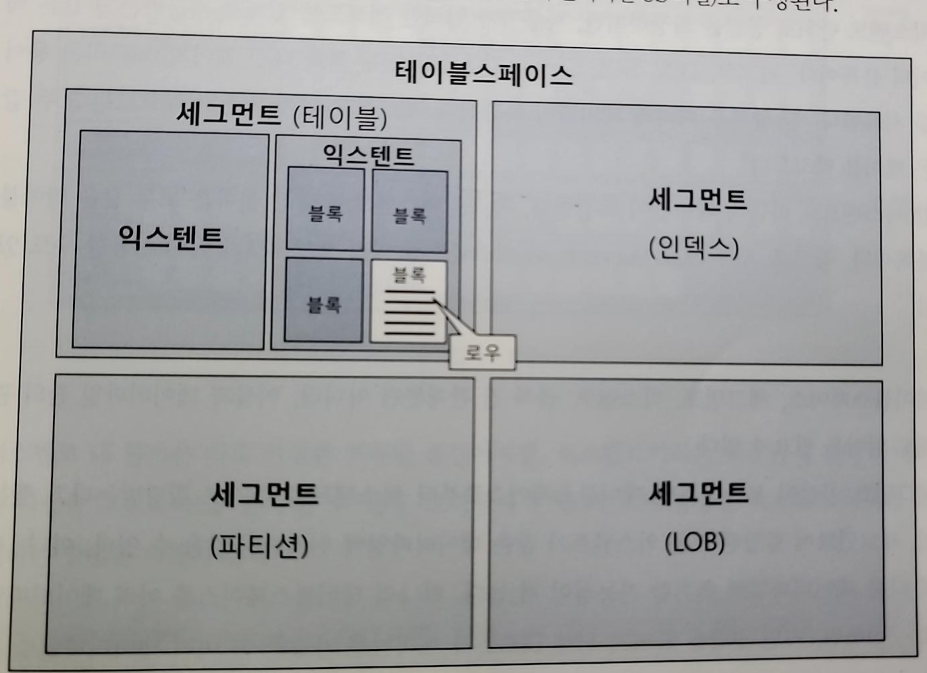
- 테이블스페이스
- 세그먼트를 담는 컨테이너, 여러개의 데이터 파일로 구성됨
- 데이터 파일 : 디스크상의 물리적인 OS 파일
- 세그먼트(테이블, 인덱스, 파티션, LOB 등)
- 테이블, 인덱스처럼 데이터 저장공간이 필요한 오브젝트
- 테이블, 인덱스를 생성할 때 어떤 테이블스페이스에 저장할지 지정
- 파티션 구조가 아니라면 테이블 == 세그먼트, 인덱스 == 세그먼트
- 테이블/인덱스가 파티션 구조라면 각 파티션이 하나의 세그먼트
- LOB 컬럼은 그 자체가 하나의 세그먼트를 구성
-> 자신이 속한 테이블과 다른 별도 공간에 값을 저장한다
- 익스텐드
- 공간을 확장하는 단위(연속된 블록의 집합)
- 테이블/인덱스에 데이터를 입력하다 공간이 부족해지면 해당 오브젝트가 속한 테이블 스페이스로부터 익스텐드를 추가로 할당받는다
- 익스텐드 단위로 공간을 확장/레코드를 실제 저장하는 공간은 데이터 블록(페이지)
- 하나의 익스텐드/블록은 한 테이블이 독점
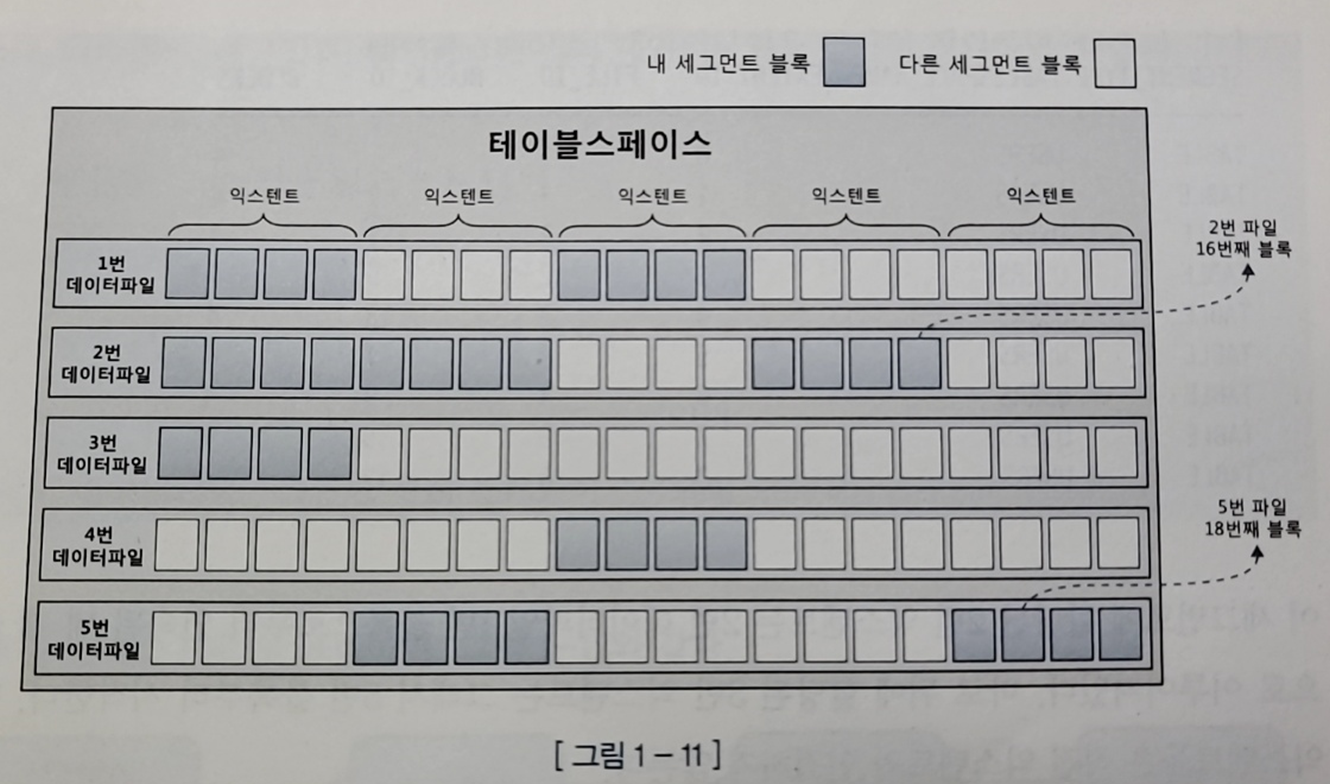
- 세그먼트에 할당된 익스텐드가 서로 다른 데이터 파일에 위치할 가능성이 높다(파일 경합을 줄이기 위한 분산 저장)
- 익스텐드 내 블록은 인접한 공간이지만 익스텐드끼리는 연속된 공간이 아니다
3. 블록 단위 IO
- 데이터 I/O 단위가 블록이므로 특정 레코드 하나를 읽고 싶어도 해당 블록을 통째로 읽음
- postgresql도 block 단위를 읽을 수 있다
- 테이블 뿐만 아니라 인덱스도 블록단위로 읽고 쓴다
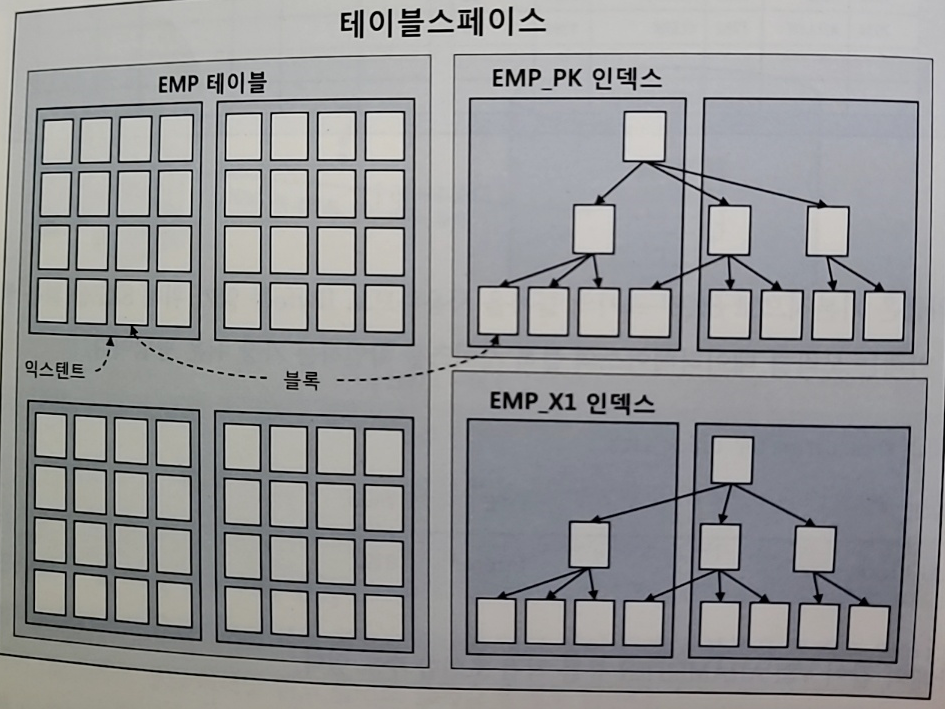
4. 시퀀셜 액세스 VS 랜덤 액세스
1) 시퀀셜 액세스(실선)
- 논리적/물리적 연결 순서에 따라 차례로 블록을 읽는 방식
- 인덱스 리프 블록은 앞뒤를 가리키는 주소값을 통해 논리적 연결이 되어있음
- 테이블 블록 간에는 논리적 연결고리가 없는데 테이블은 어떻게 시퀀셜 방식으로 액세스?
-> DB는 세그먼트에 할당된 익스텐드 목록을 세그멘트 헤더에 맵으로 관리(익스텐드맵)하며 각 인스턴스의 첫번째 블록 주소 값을 갖는다
-> full table scan : 익스텐드 맵에서 목록을 얻고 각 익스텐드의 첫번째 블록 뒤에 연속해서 저장된 블록을 순서대로 읽는 것
2) 랜덤 액세스(점선)
- 레코드 하나를 읽기 위해 한 블록씩 접근하는 방식
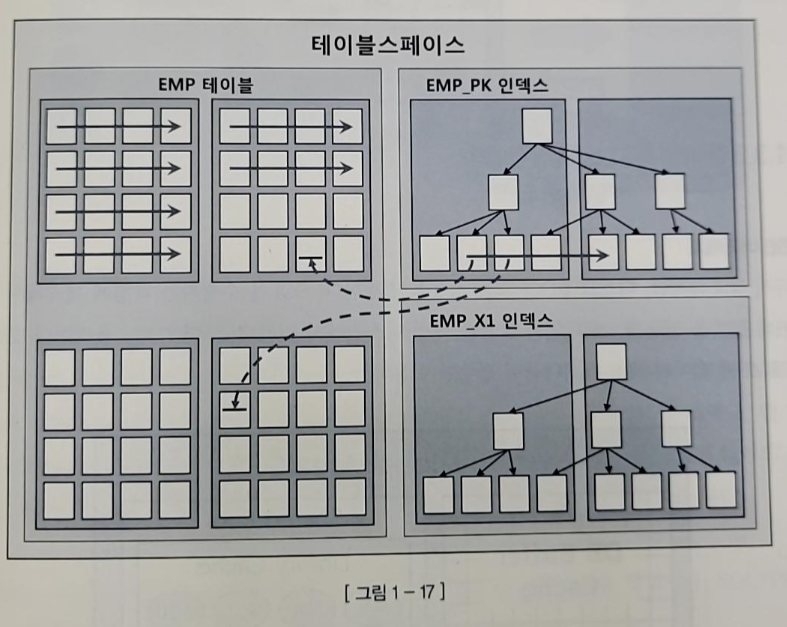
5. 논리적 I/O vs 물리적 I/O
- 자주 읽는 블록을 매번 디스크에서 읽는 것은 비효율적
-> DBMS 데이터 캐싱 메커니즘 중요 - DB 버퍼 캐시 : 데이터 블록을 캐싱하여 같은 블록에 대한 반속적인 I/O call을 줄인다
cf) 코드 캐시인 라이브러리 캐시 - 서버 프로세스와 데이터 파일 사이에 버퍼 캐시가 있어 데이터 블록을 읽기 전에 버퍼 캐시부터 탐색
- 버퍼 캐시는 공유 메모리 영역이므로 같은 블록을 읽는 다른 프로세스도 접근할 수 있다
논리적 IO
- 메모리 버퍼 캐시에서 발생한 총 블록 IO
- Direct Path IO라는 예외 사항도 있지만 대체로 둘이 같다고 보면 됨
물리적 IO
- 블록을 버퍼캐시에서 찾지 못할 때 디스크에 엑세스 하는 것
- 논리적 IO 중 일부를 물리적으로 한다고 볼 수 있으며 느림
- IO를 연속해서 실행하면 논리적 IO가 늘어나고 그렇지 않으면 물리적 IO 비율이 늘어난다
){kind=link}
- 물리적 디스크 IO를 수반하지 않고 곧바로 메모리에서 찾은 비율
- 암튼 정리하자면 실제 SQL 성능을 높이려면 물리적 IO 가 아니라 논리적 IO를 줄여야 한다는 뜻 (물리적 IO는 외부요인)
- 논리적 IO는 SQL을 튜닝해서 읽는 총 블록 개수를 줄여야 한다는 것(통제 가능한 변수)
- BCHR이 SQL 성능을 좌우하지만 저 수치가 높다고 꼭 효율적인 SQL은 아님
-> ex) 같은 블록을 비효율적으로 반복해서 읽어도 BCHR 높아짐
6. Single Block I/O vs Multiblock I/O
- 메모리 캐시가 클수록 좋지만 모두 적재할수는 없다
- 캐시에 없는 데이터 블록은 IO call을 통해 디스크에서 DB 버퍼캐시로 적재하고나서 읽는다
- IO call 시 한번에 한블록씩 요청(Single Block IO)하거나 여러 블록씩 요청(Multiblock IO)하기도 한다
1) single Block IO
- index 이용 시 기본적으로 인덱스/테이블 블록 모두 Single Block IO 방식을 사용한다
- Single Block IO 대상 오퍼레이션은 아래와 같다(BTREE 구조)
- 인덱스 루트 블록을 읽을 때
- 인덱스 루트 블록에서 얻은 주소 정보로 브랜치 블록을 읽을 때
- 인덱스 브랜치 블록에서 얻은 주소 정보로 리프 블록을 읽을 때
- 인덱스 리프 블록에서 얻은 주소 정보로 테이블 블록을 읽을 때
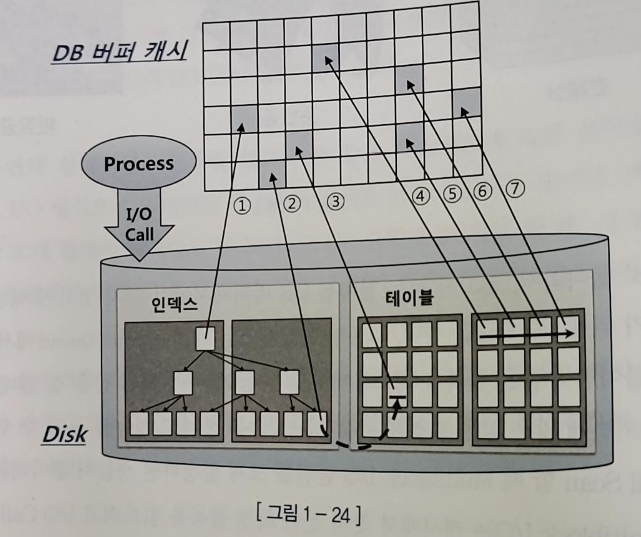
2) Multiblock IO
- 많은 데이터 블록을 읽을 때는 Multiblock IO 방식이 효율적이다
- 인덱스를 이용하지 않고 테이블 전체를 스캔할 때 사용
- 캐시에서 찾지 못한 특정 블록을 읽으려고 IO Call 할 때 디스크 상 그 블록과 인접한 블록(같은 익스텐드에 속한 블록)들을 한꺼번에 읽어 캐시에 미리 적재하는 기능
- Multiblock IO 방식이여도 익스텐드의 경계는 넘을 수 없다
- 테이블이 클수록 Multiblock IO 단위도 크면 좋음 -> IO 횟수를 줄여준다
- Full scan을 할 때 Multiblock IO 단위를 크게 설정하면 성능이 좋아짐
7. Table Full Scan vs Index Range Scan
- Table Full Scan : 테이블 전체 스캔, 테이블에 속한 블록 전체를 읽음
- Index Range Scan : 인덱스를 이용한 테이블 엑세스, 인덱스에서 일정량 스캔해서 얻은 ROWID로 테이블 레코드를 찾아감
- ROWID : 테이블 레코드가 디스크 상 어디에 저장되었는지 가리키는 위치 정보
- Table Full Scan을 피하는 것이 생각보다 성능 향상에 도움이 되지는 않는다
-> index 가 SQL 성능을 떨어뜨리는 경우도 있기 때문에
-> ex) 한번에 많은 데이터를 처리하는 집계용 SQL, 배치 프로그램 등
-> Full scan으로 유도하면 성능이 빨라지는 경우가 있고, 조인 포함 SQL의 경우 조인 메소드로 해시 조인을 선택해주면 된다
-
full scan이 빠른 경우
- Table Full Scan은 시퀀셜 액세스와 Multiblock I/O 방식으로 디스크 블록을 읽음
- 한 블록에 속한 모든 레코드를 한번에 읽음
-> 캐시에서 못 찾으면 IO Call(대기발생)을 통해 인접한 수십~수백개의 블록을 한 번에 I/O 함 - 위 방식을 사용하면 스토리지 스캔 성능이 좋아지는 만큼 성능도 좋아진다
- 수십 ~ 수백건의 소량 데이터를 찾을 때 스캔하는 것은 비효율적이므로 반드시 인덱스를 사용해야 한다
-
index를 하는데 속도가 느려지는 이유
- Index Range Scan은 랜덤 액세스와 Single Block I/O 방식으로 디스크 블록을 읽음
- 캐시에서 블록을 못 찾으면 레코드 하나를 찾기 위해 매번 잠을 잠
- 많은 데이터를 읽을 때는 Table Full Scan보다 불리하다
- 위 방식을 사용하면 스토리지 스캔 성능이 수십 배 좋아져도 성능이 조금 밖에 좋아지지 않음
- 또한 인덱스를 사용하면 읽었던 블록을 반복해서 읽는 비효율이 있다(물리적/논리적 IO 모두 불리)
-> 인덱스에 대한 맹신은 금물이며 예상 카디널리티가 일정량을 넘어서는데도 인덱스로 테이블을 엑세스하면 더 성능이 느려지게 된다
8. 캐시 탐색 매커니즘
- Direct Path I/O를 제외하면 모든 블록 I/O는 메모리 버퍼 캐시를 경유함
- 아래 오퍼레이션은 모두 버퍼캐시의 탐색 과정을 거친다
- 인덱스 루트 블록을 읽을 때
- 인덱스 루트 블록에서 얻은 주소 정보로 브랜치 블록을 읽을 때
- 인덱스 브랜치 블록에서 얻은 주소 정보로 리프 블록을 읽을 때
- 인덱스 리프 블록에서 얻은 주소 정보로 테이블 블록을 읽을 때
- 테이블 블록을 Full Scan 할 때
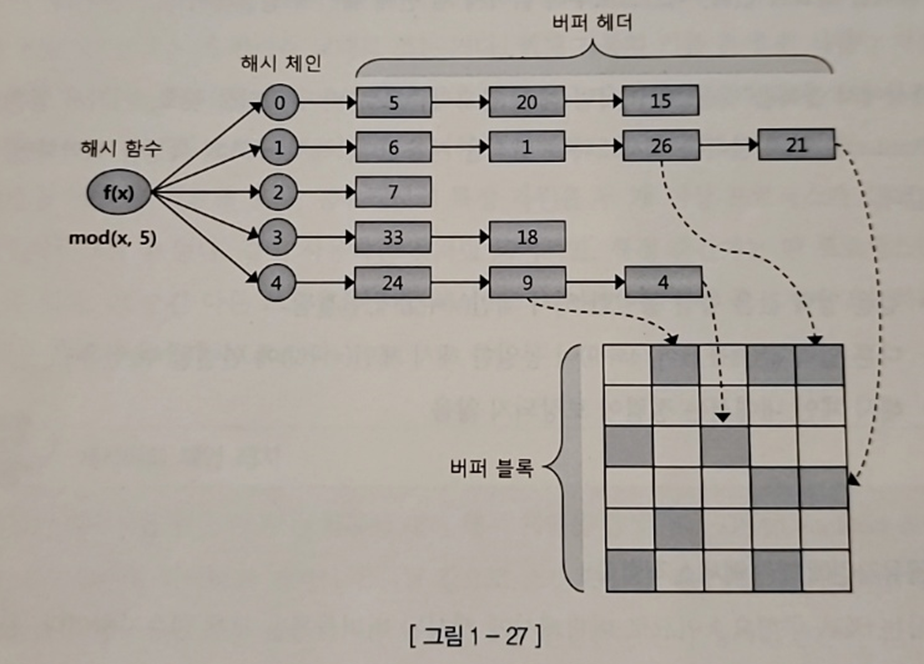
- 위와 같이 해시 알고리즘으로 버퍼 헤더를 찾는다
-> 이후 포인터로 버퍼 블록을 액세스 하는 방식을 사용한다- 같은 입력 값은 항상 동일한 해시 체인(버킷)에 연결된다
- 다른 입력 값이 동일 해시 체인에 연결될 수 있음
- 해시 체인 내에서는 정렬이 보장되지 않음
- 체인에 찾고자 하는 값이 없으면 디스크에서 읽어서 연결하면 된다
메모리 공유 자원에 대한 엑세스 직렬화
- 버퍼 캐시는 SGA 구성 요소이기 때문에 버퍼 캐시에 캐싱된 버퍼 블록은 공유자원이다
- 하나의 버퍼 블록에 동시 접근 시 정합성에 문제가 발생할 수 있다
- 순차적 접근을 위해 직렬화 메커니즘이 필요하다
-> 캐시 버퍼 체인에서는 캐시버퍼 체인 래치, 캐시버퍼 LRU 체인 래치 등의 방식이 있다
-> 버퍼 블록 자체에서도 버퍼 Lock 이라는 직렬화 메커니즘이 있다(캐시버퍼 체인 래치를 해제하기 전 버퍼 헤더에 락을 설정해 버퍼 블록 자체에 대한 직렬화 문제를 해결) - 래치들의 경합 때문에 캐시 I/O가 느릴 수도 있다
-> SQL 튜닝을 통해 쿼리 일량(논리적 I/O) 자체를 줄여야 한다

나는야 누워있는 개발머신