인덱스 구조 및 탐색
- 인덱스 탐색 과정이 수직적 탐색/수평적 탐색 두 단계로 진행이 된다
-> 이를 이해해야 인덱스를 제대로 사용할 수 있고 개발 성능이 좋아질 수 있다
1. 인덱스 튜닝
- 데이터베이스 테이블에서 데이터를 찾는 방법은 단 두가지
- 테이블 전체 스캔
- 인덱스 이용
- 전자는 튜닝 거리가 없지만 후자는 튜닝할 여지가 많다
인덱스 튜닝의 핵심 요소(2개)
- 인덱스는 큰 테이블에서 소량 검색할 때 이용한다
- 튜닝 요소는 다음과 같다
1) 인덱스 스캔 효율화 튜닝
- 인덱스 스캔 과정에서 발생하는 비효율 줄이기
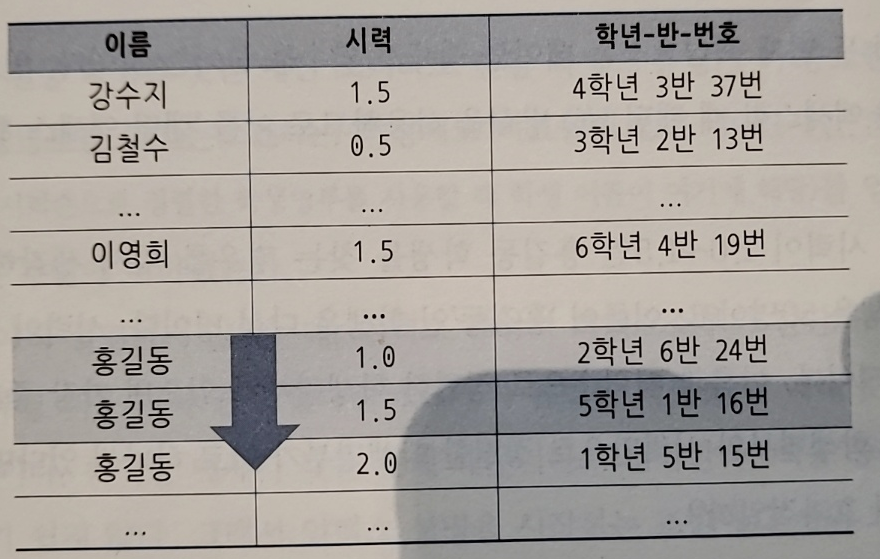
- 홍길동을 찾을 때 정렬 순서가 이름-시력, 시력-이름으로 다를 때 전자가 훨씬 빠르다(후자는 많은 양 스캔 필요)
2) 랜덤 액세스 최소화 튜닝
- 테이블 액세스 횟수 줄이기
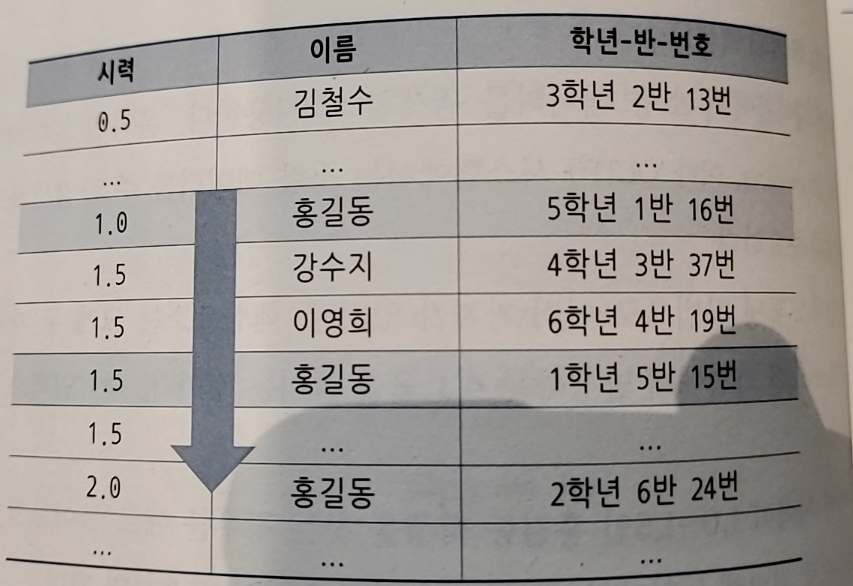
- 시력과 이름으로 정렬한 명부가 각각 두개 있다면 이름순 정렬을 한 명부를 사용하는 것이 좋다
- 그래야 액세스 횟수가 줄어든다
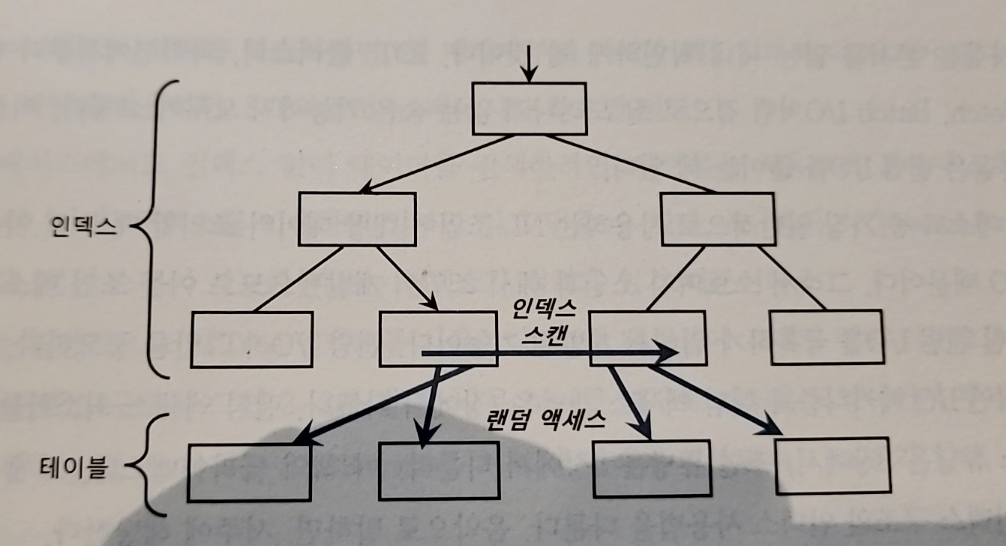
- 랜덤 액세스 최소화 튜닝을 하는 것이 성능에 더 큰 영향을 미친다
- SQL 튜닝은 랜덤 I/O와의 전쟁이다
- 디스크 I/O 중에서도 랜덤 I/O를 줄이는 것이 중요하다
- DB의 주요 기능(IOT, 클러스터, 파티션, 테이블 Preference, Batch IO)의 본질은 랜덤 I/O를 줄이는 것에 있다
- 조인 메소드 중 NL 조인이 느린 이유는 랜덤 I/O 때문이다
-> 소트 머지 조인/해시 조인이 이를 극복하기 위해 개발됨
2. 인덱스 구조
- 인덱스를 이용하면 범위 스캔(Range Scan)이 가능하다
- 범위 스캔이 가능한 이유는 인덱스가 정렬되있기 때문
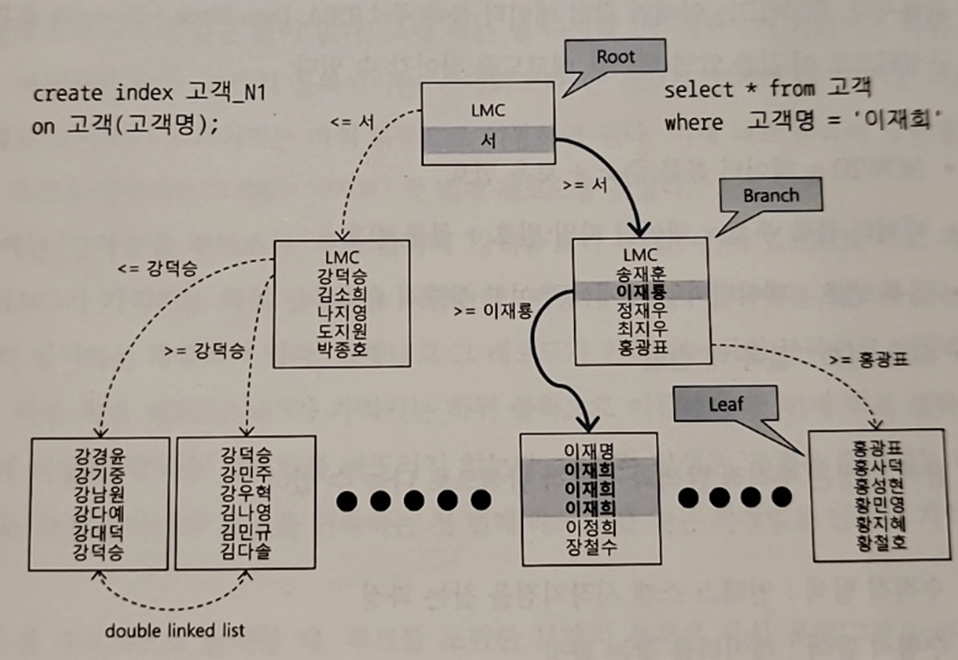
- DBMS는 일반적으로 B-Tree 구조를 이용한다
- 루트와 브랜치 블록에 있는 각 레코드는 하위 블록에 대한 주소값을 갖는다
- 키 값은 하위 블록에 저장된 키 값의 범위를 나타낸다
- LMC(Leftmost Child)는 키 값을 갖지 않는 특별한 레코드이다(루트, 브랜치 블록 등)
- LMC가 가리키는 주소로 찾아간 블록에는 키 값을 가진 첫번째 레코드보다 작거나 같은 레코드가 저장되어있다
- 리프 노드에 저장된 각 레코드는 키 값 순으로 정렬되어있고, ROWID를 갖는다
- ROWID : 테이블 레코드를 가리키는 주소값, 인덱스 키 값이 같으면 ROWID 순으로 정렬됨
- ROWID : 데이터 블록 주소 + 로우 번호
- 데이터 블록 주소 : 데이터 파일 번호 + 블록 번호
- 블록 번호 : 데이터 파일 내에서 부여한 상대적 순번
- 로우번호 : 블록 내 순번
- 인덱스 탐색 과정은 수직적 탐색과 수평적 탐색으로 나눌 수 있다
- 수직적 탐색 : 인덱스 스캔 시작지점을 찾는 과정
- 수평적 탐색 : 데이터를 찾는 과정
3. 인덱스 수직적 탐색
- 인덱스 스캔 시작 지점을 찾는 과정
- 정렬된 인덱스 중 조건을 만족하는 첫번째 레코드를 찾는 과정
- 루트 블록부터 시작해 리프노드까지 진행하게 된다
- 이는 루트/브랜치 블록에 저장된 각 인덱스 레코드는 하위 블록에 대한 주소값을 갖기 때문
- 수직적 탐색 과정에 찾고자 하는 값보다 크거나 같은 값을 만나면 바로 직전 레코드가 가리키는 하위 블록으로 이동함
4. 인덱스 수평적 탐색
- 수직적 탐색을 통해 스캔 시작점을 찾은 후 찾고자 하는 데이터가 더 안 나타날 때 까지 인덱스 리프 블록 수평적 스캔 진행
- 인덱스 블록끼리는 서로 앞뒤 블록에 대한 주소값을 갖는다(양방향 연결 리스트)
- 수평적 탐색 이유는 다음과 같다
- 조건절에 만족하는 데이터를 모두 찾기 위해
- ROWID를 얻기 위해
- 일반적으로 인덱스 스캔 이후 테이블 액세스를 하기 때문에 ROWID를 필요로 하게 된다
5. 결합 인덱스 구조와 탐색
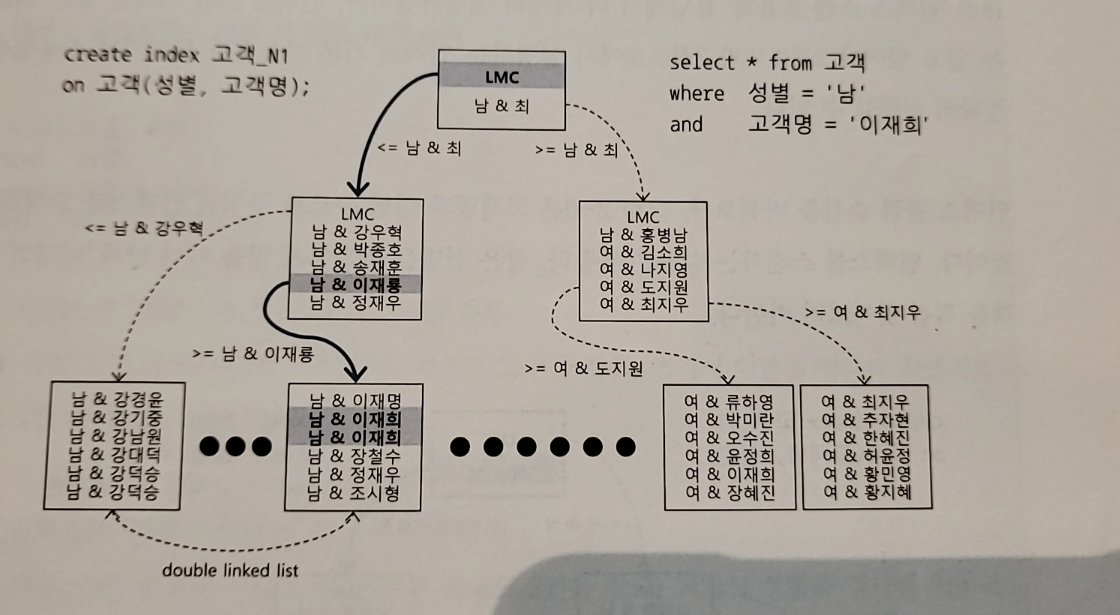
- 두 개 이상의 컬럼을 조합해 인덱스를 만들 수 있다
- 인덱스를 어떻게 구성하든 블록 I/O 개수가 같으므로 성능도 같다(물론 인덱스 구성에 따라 성능 차이가 날 수 있지만 어느 컬럼을 앞에 두든 일량에는 차이가 없다)
- B-Tree 구조는 엑셀처럼 아니기 때문에..
- B-Tree(Balanced Tree)는 인덱스 루트에서 리프 노드에 도달하기까지 읽는 블록 수가 모두 같다
-> 즉 루트로부터 모든 리프 블록까지의 높이는 항상 같다
-> 때문에 delete 작업 때문에 인덱스가 불균형 상태에 놓일 일은 없다
인덱스 기본 사용법
- 인덱스 기본은 Range Scan
- Index Range Scan 외에도 다양한 스캔 방식이 존재한다
1. 인덱스를 사용한다는 것
- 인덱스 컬럼(선두 컬럼)을 가공하지 않아야 인덱스를 정상적(Index Range Scan)으로 사용할 수 있음
ex1) 색인이 가나다 순으로 정렬 되어있어야 빨리 찾을 수 있다(찾고자 하는 단어들이 모여 있음) - 인덱스 가공값, 혹은 중간값으로는 스캔 시작점을 찾을 수 없다
- 찾고자 하는 단어들이 흩어져있기 때문에 스캔하다 중간에 중단할 수도 없다
-> 리프 블록 전체를 스캔하는 Index Full Scan 방식으로 작동하게 된다
2. 인덱스를 Range Scan 할 수 없는 이유
- 인덱스 컬럼을 가공하면 인덱스를 정상적으로 사용할 수 없다
1) 인덱스 스캔 시작점을 찾을 수 없어서- Index Range Scan에서 Range는 범위를 의미한다
-> 일정 범위를 스캔한다는 뜻
-> 시작/끝지점이 있어야 한다 - 범위의 시작지점을 찾는 과정은 수직적 탐색에 해당한다
- 이는 인덱스 뿐만 아니라 where 절도 마찬가지
- Index Range Scan에서 Range는 범위를 의미한다
그래서 아래와 같이 가공을 하면 스캔 시작/끝지점을 찾을 수 없다
where substr(생년월일, 5, 2) = '05'
where nvl(주문수량, 0) < 100
where 업체명 like '%대한%'
where (전화번호 := tel_no OR 고객명 :=cust_nm)
where 전화번호 in (:tel_no1, :tel_no2)- OR 조건으로 검색할 경우 수직적 탐색을 통해 어느 한 시작 지점을 찾을 수 없기 때문에 인덱스를 어떤 방식으로 구성해도 Range Scan을 할 수 없다
- 하지만 OR Expansion을 이용해 가능하게 할 수 있다
- OR 조건식을 SQL 옵티마이저가 위와 형태로 변환할 수 있다
- 이를 OR Expansion이라고 함
- 이와 같은 쿼리 변환이 일어나지 않으면 OR 조건식에는 Index Range Scan이 불가능하게 된다
select * from 고객 where 고객명 = :custom_nm
union all
select * from 고객 where 전화번호 = :tel_no
and (고객명 <> :cust_nm or 고객명 is null) 
- In 조건도 기본적으로는 index range scan이 안된다
- 하지만 Or 과 마찬가지로 UNION ALL 방식으로 작성하면 각 브랜치 별로 인덱스 스캔 시작점을 찾을 수 있다
select * from 고객 where 전화번호 = :tel_no1
union all
select * from 고객 where 전화번호 = :tel_no2 - IN 조건에 대해 SQL 옵티마이저가 IN-List Iterator 방식을 사용한다
-> IN-List 개수만큼 Index Range Scan을 반복하게 된다
-> 이를 통해 SQL을 UNION ALL 방식으로 변환한 것 같은 효과를 얻을 수 있다

3. 더 중요한 인덱스 사용 조건
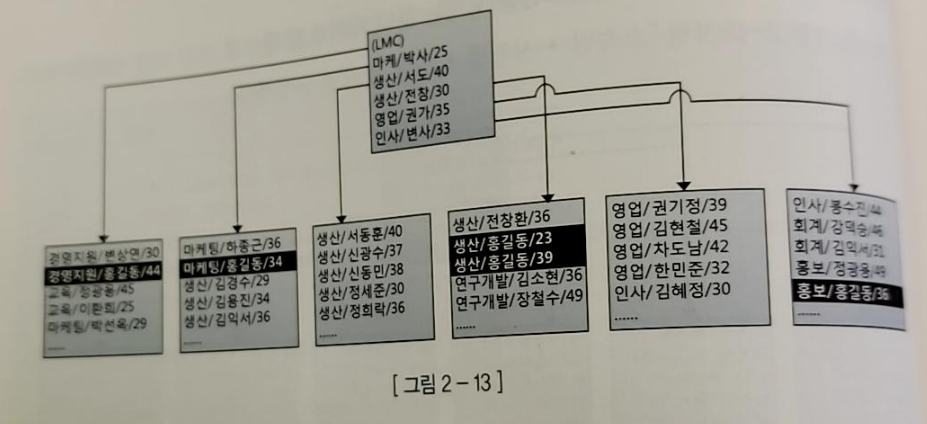
- ex) [소속팀 + 사원명 + 연령] 인덱스를 만들고 아래와 같은 쿼리를 실행했다
select 사원번호, 소속팀, 연령, 입사일자, 전화번호
from 사원
where 사원명 = '홍길동' - 이럴 경우 찾으려고 하는 데이터가 리프 블록 전 구간에 흩어져있게 된다
- 인덱스를 Range Scan 하기 위한 가장 첫번째 조건은 인덱스 선두 컬럼이 조건절에 있어야 한다는 것이다
- 가공을 했는데도 인덱스를 잘 타는 경우가 있는데 아래와 같다
select * from TXA1234
where 기준연도 = :stdr_year
and substr(과세구분코드, 1, 4) = :txtn_dcd - 위의 경우 인덱스 선두 컬럼이 가공되지 않은 상태로 조건절에 있어서 range scan이 가능하다
- 그러나 인덱스 range scan을 한다고 항상 성능이 좋은 것은 아니다
인덱스 range scan을 해도 안좋은 경우
- 인덱스를 잘 타도(index range scan) 성능에 문제가 있을 수 있는데 이는 인덱스 리프 블록에서 스캔하는 양을 따져야 알 수 있다
- 중간값 검색이 포함되어있는 경우, 컬럼 가공 경우 전체 스캔이 포함되고 많은 양을 스캔하게 될 경우 문제가 될 수 있다
4. 인덱스를 이용한 소트 연산 생략
- index range scan 할 수 있는 이유는 데이터가 정렬되어있기 때문
-> 때문에 소트 연산 생략 효과도 부수적으로 얻게 된다 - ex) 장비번호-변경일자-변경순번 인덱스가 있을 때 장비번호-변경일자가 같은 데이터는 변경순번대로 정렬되어 있게 된다
- 때문에 order by를 써도 옵티마이저가 이를 생략해서 연산하게 된다

- 만일 정렬 연산을 생략할 수 있게 인덱스가 구성되어있지 않으면 옵티마이저는 sort order by 연산을 추가하게 한다
- 인덱스 리프 블록은 양방향 연결 리스트이기 때문에 내림차순(desc) 정렬에도 인덱스를 활용할 수 있다
- 내림차순 정렬 시에는 조건을 만족하는 가장 큰 값을 수직적 탐색을 한 후 좌측으로 수평적 탐색을 진행하게 된다
5. order by 절에서 컬럼 가공
- 조건절이 아닌 order by, select-list 에서 컬럼을 가공하면서 인덱스를 정상적으로 사용할 수 없는 경우도 있다
- 아래와 같은 경우에는 order by를 생략할 수 있다(인덱스 정렬 순서대로 나옴)
select * from 상태변경이력 where 장비번호='C'
order by 변경일자, 변경순번 - 그런데 아래와 같이 가공 값 기준으로 정렬하는 경우는 order by 생략할 수 없음
select * from 상태변경이력
where 장비번호 = 'C'
order by 변경일자 || 변경순번 - 아래의 경우에도 order by 절에 to_char로 가공한 값이 들어가기 때문에 sort order by 연산이 들어가게 된다
select * from
(
select to_char(A.주문번호, 'FM000000') from 주문 A
where A.주문일자 = :dt
and A.주문번호 > NVL(:next_ord_no, 0)
order by 주문번호
) where rownum <= 30 6. Select-list에서 컬럼 가공
- 아래와 같은 경우에는 옵티마이저 정렬 연산을 생략할 수 있다
- 최소값을 찾을 때는 수직적 탐색할 때 왼쪽으로, 최대값을 찾을 때는 오른쪽으로 내려가게 된다
- 인덱스 리프 블록의 왼쪽 또는 오른쪽의 레코드 하나만 읽고 멈추게 된다
select min(변경순번) from 상태변경이력
where 장비번호 = 'C' and 변경일자 = '20180316'
select max(변경순번) from 상태변경이력
where 장비번호 = 'C' and 변경일자 = '20180316' - 아래의 경우에는 order by를 생략할 수 없다
select nvl(max(to_number(변경순번)), 0) from 상태변경이력
where 장비번호 = 'C' and 변경일자 = '20180316'- 이를 아래와 같이 튜닝하면 정렬 연산이 없이 같은 값을 찾을 수 있다
select nvl(to_number(max(변경순번)), 0) from 상태변경이력
where 장비분석 = 'C' and 변경일자 = '20180316'7. 자동 형 변환
select * from 고객 where 생년월일 = 19821225- 생년월일이 문자열이라고 치자
- 이 때 위와 같이 select를 하면 테이블 전체 스캔을 하게 된다
- 옵티마이저는 sql을 다음과 같이 변경하게 된다
select * from 고객
where to_number(생년월일) = 19821225- 이는 생년월일 컬럼이 문자열인데 조건절 비교값을 숫자형으로 표현했기 때문이다
- 타입 체크를 엄격하게 해서 컴파일 에러를 내는 DBMS 도 있고 자동으로 형변환해주는 경우도 있기 때문에 유의해야한다
- 문자형과 숫자형을 비교할 경우 문자형 컬럼을 숫자형 컬럼으로 변경해서 비교하게 된다
- 문자형과 날짜형이 만나면 날짜형이 이긴다(문자형 -> 날짜형)
- 성능에 문제가 없더라도 올바른 포맷으로 변경해서 비교를 해주도록 하자
select * from 고객
where 가입일자 = TO_DATE('01-JAN-2018', 'DD-MON-YYYY')- 숫자형이 문자형을 이기지만 연산자가 LIKE 일 경우 다르다
-> 이 때는 문자형 기준으로 숫자형 컬럼이 변환된다 - 두가지 컬럼을 LIKE로 처리해 하나로 만든 아래와 같은 경우가 있다
-- 사용자가 계좌번호를 입력할 경우
select * from 거래
where 계좌번호 = :acnt_no
and 거래일자 between :trd_dt1 and :trd_dt2
+
-- 사용자가 계좌번호를 입력하지 않을 경우
select * from 거래
where 거래일자 between :trd_dt1 and :trd_dt2
=
select * from 거래
where 계좌번호 like :acnt_no || '%'
and 거래일자 between :trd_dt1 and :trd_dt2- 이 방식을 사용하면 like, between 조건을 같이 사용했으므로 인덱스 스캔 효율이 안좋아진다
- 계좌번호 컬럼이 숫자형일 때 like 조건으로 검색하면 자동 형변환이 이루어지기 때문에 인덱스 액세스 조건으로 사용되지 못하게 된다
- 또한 자동 변환될 수 없는 문자열이 입력되면 쿼리 실행 도중 에러가 발생하거나 아예 결과 값이 잘못되어 나올 때도 있다
-> 이 기능에 의존하지 말고 인덱스 컬럼 기준으로 반대편 컬럼 또는 값을 명확히 형변환 해줘야 한다 - TO_CHAR, TO_DATE, TO_NUMBER과 같은 형변환 자체가 성능에 영향을 미치는 것이 아니다
-> 어차피 형변환 함수를 생략해도 옵티마이저가 알아서 생성한다 - 결국 중요한 것은 블록 I/O를 줄이는 것!
인덱스 확장 기능
- index range scan 외에도 다음과 같은 인덱스 확장 기능이 있다
- index full scan
- index unique scan
- index skip scan
- index fast full scan
1. Index Range Scan
- B*Tree index의 가장 일반적이고 정상적인 형태의 액세스 방식
- 인덱스 루트에서 리프 블록까지 수직적으로 탐색한 후 필요한 범위(Range)만 스캔
- 인덱스를 타기 위해서는 선두컬럼을 가공하지 않은 상태로 조건절에서 사용해야 한다
- 인덱스를 탄다고 성능이 꼭 좋은 것은 아니고 인덱스 스캔 범위, 테이블 액세스 횟수를 줄이는 것이 관건이다

2. Index Full Scan
- 수직적 탐색 없이 인덱스 리프 블록을 처음부터 끝까지 수평적으로 탐색하는 방식
- 데이터 검색을 위한 최적의 인덱스가 없을 때 차선으로 선택된다
- 인덱스 선두 컬럼인 ename이 조건절에 없기 때문에 index range scan은 불가능하다
- sal 컬럼이 인덱스 뒤 쪽에 있기 때문에 index full scan을 통해 레코드를 찾을 수 있다
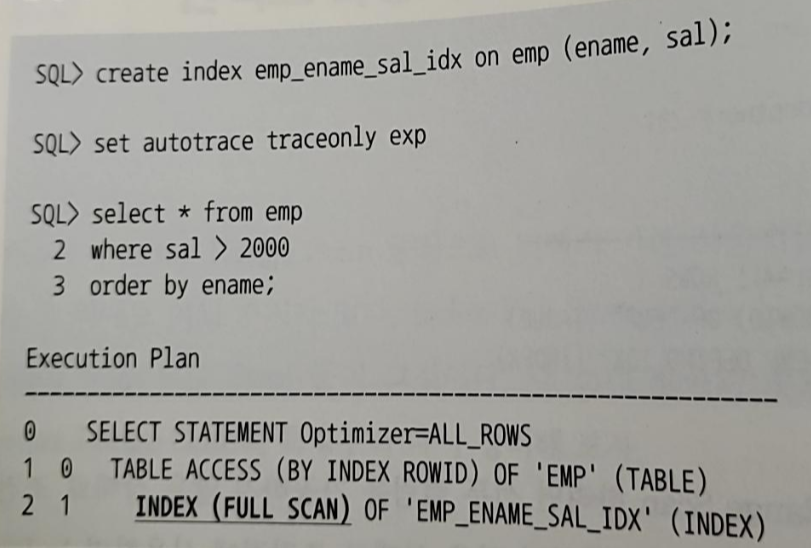
- 위처럼 선두 컬럼이 조건절에 없으면 옵티마이저는 먼저 Table Full Scan을 고려하게 된다
- 대용량 테이블이여서 Table Full Scan에 따른 부담이 크다면 옵티마이저는 인덱스를 활용하지 않을수도 있다
- 인덱스 스캔 단계에서 대부분 레코드를 필터링하고 아주 일부만 테이블을 액세스 하는 상황이면 인덱스 스캔이 유리하므로 옵티마이저는 Index Full Scan 방식을 이용하게 된다

- 위처럼 데이터가 전체 중 극히 일부라면 index full scan을 통한 필터링이 효과적이다
- 하지만 적절한 인덱스를 설정해주는 것이 더 좋다
인덱스를 이용한 소트 연산 생략
- 인덱스 Full Scan 시 Range Scan과 마찬가지로 결과가 인덱스 컬럼 순으로 정렬된다
-> Sort Order By 연산을 생략할 목적으로 사용 가능

- 위의 경우 사용자가 first_rows 힌트로 옵티마이저 모드를 바꿨다
-> 옵티마이저는 소트 연산을 생략하고 전체 집합 중 처음 일부를 빠르게 출력할 목적으로 index full scan을 사용하게 된다 - 때문에 index full scan이 이루어지게 된다
- 그런데 위 선택의 경우 거의 모든 레코드에 대해서 테이블 액세스가 발생하므로 Table Full Scan보다 오히려 불리하다
-> Table full scan보다 더 많은 I/O 를 일으키고 수행 속도도 훨씬 더 느려지게 된다
3. Index Unique Scan
- 수직적 탐색만으로 데이터를 찾는 스캔 방식
- Unique 인덱스를 = 조건으로 탐색하는 경우에 작동한다
- Unique 컬럼은 정합성을 유지하기 때문에 = 조건으로 데이터를 한 건 찾는 순간 더 이상 탐색할 필요가 없다
- Unique 인덱스라 해도 범위 검색 조건을 이용하면 Index Range Scan으로 처리된다
- unique 결합 인덱스에 대해 일부 컬럼만으로 검색할 때에도 Index Range Scan이 나타난다
4. Index Skip Scan
- 인덱스 선두 컬럼을 조건절에 사용하지 않으면 옵티마이저는 기본적으로 Table Full Scan을 선택한다
- Table Full Scan보다 I/O를 줄일 수 있거나 정렬된 결과를 쉽게 얻을 수 있다면 Index Full Scan을 사용하기도 한다
- 오라클은 인덱스 선두 컬럼이 조건절에 없어도 인덱스를 활용하는 새로운 스캔 방식을 9i 버전에서 선보였다(Index Skip Scan)
-> 다 지원되는 것은 아니라는 뜻
-> postgresql 은 index skip scan이 없지만 대안은 있는 듯 하다 - 이 스캔 방식은 조건절에 빠진 인덱스 선두 컬럼의 Distinct Value 개수가 적고 후행 컬럼의 Distinct Value 개수가 많을 때 유용하다
- Index Skip Scan은 루트 또는 브랜치 블록에서 읽은 컬럼 값 정보를 이용해 조건절에 부합하는 레코드를 포함할 '가능성이 있는' 리프 블록만 골라서 액세스 하는 스캔 방식이다
5. Index Fast Full Scan
- Index Fast Full Scan은 Index Full Scan 보다 빠르다
- Index Fast Full Scan은 논리적인 인덱스 트리 구조를 무시하고 인덱스 세그먼트 전체를 Multiblock I/O 방식으로 스캔하게 된다
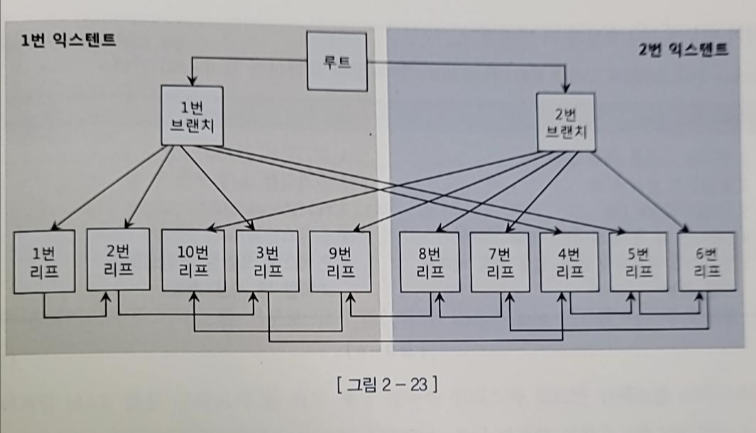
- 기존에는 인덱스의 논리 구조에 따라 루트 -> 브랜치1 -> 1번리프 ....-> 10 번 리프 순서대로 블록을 읽어들이게 된다
- Index Fast Full Scan의 경우 Multiblock I/O 방식으로 왼쪽 익스텐드에서 1 -> 2 -> 10 -> 3 -> 9 방식으로 읽고 그 다음에 오른쪽 익스텐드에서 8 -> 7 -> 4 -> 5 -> 6번 순으로 읽는다
- 루트와 두개의 브랜치 블록도 읽지만 필요 없는 블록이므로 버린다
- 이는 디스크로부터 대량의 인덱스 블록을 읽어야 할 때 큰 효과를 발휘한다
- 속도는 빠르나 인덱스의 키 순서대로 정렬되지 않게 된다
- 쿼리에 사용한 컬럼이 모두 인덱스에 포함돼 있을 때만 사용할 수 있다
- 인덱스가 파티션돼있지 않아도 병렬 쿼리가 가능하다
- 병렬 쿼리시에는 Direct Path I/O 방식을 사용하기 때문에 I/O 속도가 더 빨라진다
6. Index Range Scan Descending
- Index Range Scan과 기본적으로 동일한 스캔 방식
- 인덱스를 뒤에서부터 앞쪽으로 스캔
- 내림차순 정렬 결과 집합을 얻는다

나는야 누워있는 개발머신