테이블 액세스 최소화
- SQL 튜닝에는 랜덤 I/O가 중요하다
- 테이블 랜덤 액세스가 성능에 미치는 영향을 알아보자~
1. 테이블 랜덤 액세스
인덱스가 만능이 아님
- 인덱스가 있는데 파티셔닝/파티션 프루닝을 하는 이유 등을 알아야 한다
- 대량 데이터를 조회하는 경우 인덱스를 사용하는 것 보다 테이블 전체 스캔이 빠를 수도 있다
){kind=link}
인덱스 ROWID 는 물리적 주소? 논리적 주소?
- SQL 이 참조하는 모든 데이터를 인덱스가 가지고 있지 않은 이상 인덱스 스캔 이후에는 반드시 테이블에 액세스를 한다
- 이 때 INDEX의 ROWID 를 이용함(TABLE ACCESS BY INDEX ROWID)
- 인덱스 스캔의 이유는 검색 조건을 만족하는 소량의 데이터를 인덱스에서 빨리 찾고 거기서 테이블 레코드를 찾아가기 위한 주소값(ROWID)를 얻는 것에 있다
- ROWID를 물리적 주소라고 설명한다면 틀리지는 않지만 논리적 구조에 가깝다
- 인덱스는 물리적으로 직접 연결되지 않고 테이블에 찾아가는 주소들을 가지고 있다
메인 메모리 DB(MMDB)
- 메인 메모리 DB(MMDB) : 데이터를 모두 메모리에 로드해놓고 메모리를 통해서만 I/O를 수행하는 DB
- 잘 튜닝된 OLTP성 데이터베이스 시스템이면 버퍼캐시 히트율이 99% 이상이다
-> 디스크를 경우하지 않고 대부분 데이터를 메모리에서 읽는다는 뜻
-> 하지만 메인메모리 DB만큼 빠르지는 않다(특히 대량의 인덱스로 액세스 시) - 메인 메모리 DB의 경우 인스턴스를 기동하면 디스크에 저장된 데이터를 버퍼캐시로 로딩하고 이어서 인덱스를 생성한다
-> 이 때 인덱스는 디스크 상의 주소정보를 얻는 것(오라클은 이와 같이 얻음)이 아니라 메모리상의 주소정보(포인터)를 가지게 된다
-> 따라서 인덱스를 경유해 테이블을 액세스 하는 비용이 낮다 - DBMS에서는 테이블 블록이 수시로 버퍼캐시에서 밀려났다가 다시 캐싱된다
-> 그때마다 다른 공간에 캐싱되기 때문에 인덱스에서 포인터로 직접 연결할 수 없는 구조다
-> 메모리 주소 정보(포인터)가 아닌 디스크 주소 정보(DBA, Data Block, Address)를 이용해 해시 알고리즘으로 버퍼 블록을 찾아감
-> 일반 DBMS에서 인덱스 ROWID를 이용한 테이블 액세스가 생각만큼 빠르지 않은 이유
I/O 매커니즘 복습
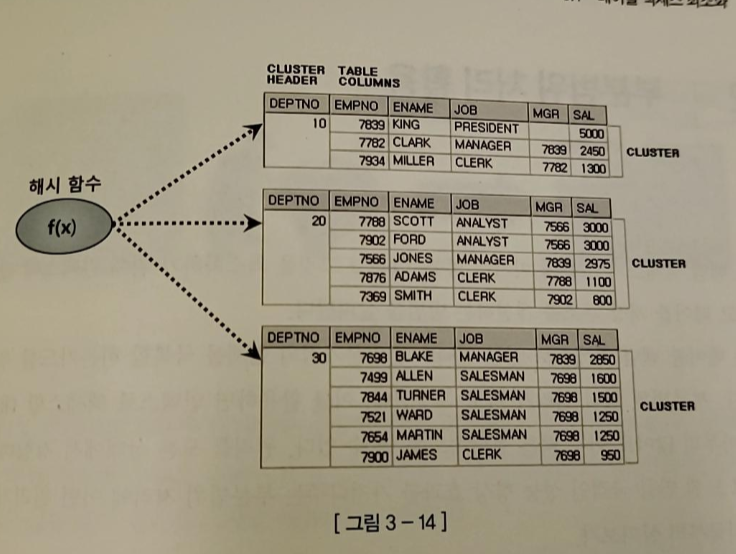
- 블록을 읽을 때 디스크로 가기 전 버퍼캐시부터 찾게 된다
- 읽고자 하는 DBA(데이터 파일 번호 + 블록 번호)를 해시 함수에 입력해 해시 체인을 찾고 거기서 버퍼 헤더를 찾는다
- 캐시에 적재할 때와 읽을 때 같은 해시 함수를 사용하므로 버퍼 헤더는 항상 같은 해시 체인에 연결된다
- 실제 데이터가 가진 버퍼 블록은 매번 다른 위치에 캐싱되는데, 그 메모리 주소값을 버퍼 헤더가 가지고 있다
-> 해싱 알고리즘으로 버퍼 헤더를 찾고 거기서 얻은 포인터로 버퍼 블록을 찾아간다
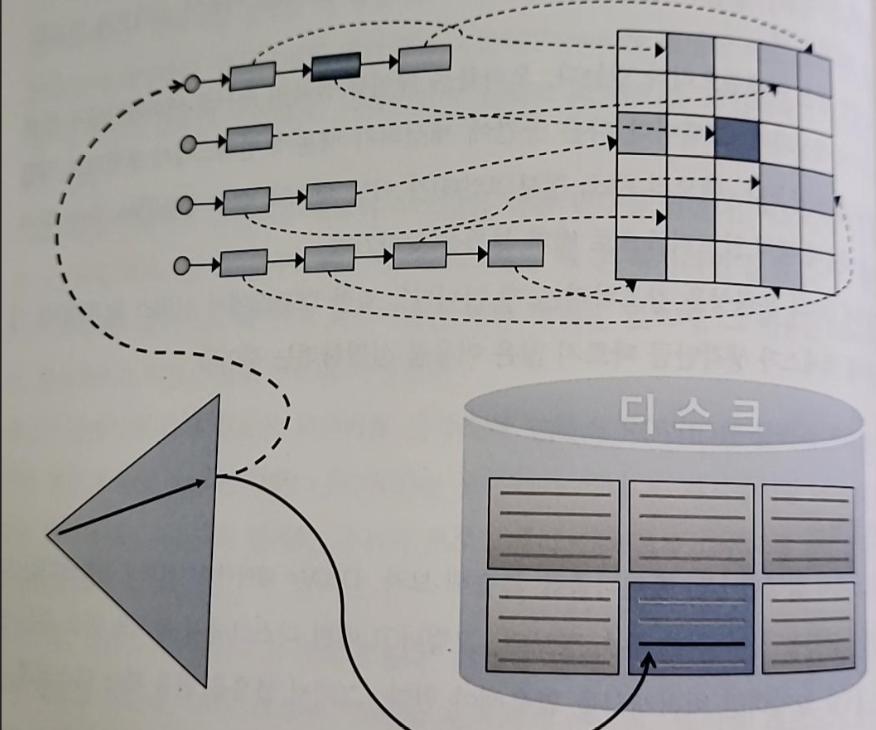
- 인덱스로 테이블 블록 액세스 시
- 리프 블록에서 읽은 ROWID를 분해해서 DBA 정보 얻음
- 테이블 Full Scan 시에는 익스텐트 맵을 통해 읽을 블록들의 DBA 정보를 얻는다
- 인덱스 ROWID는 포인터가 아니고 디스크 상에서 테이블 레코드를 찾아가기 위한 논리적인 주소 정보이다
- ROWID가 가리키는 테이블 블록을 버퍼 캐시에서 먼저 찾아보고 못 찾을 때에만 디스크에서 블록을 읽는다(그리고 버퍼캐시에 적재한 후 읽는다)
- 모든 데이터가 캐싱돼있다 해도 테이블 레코드를 찾기 위해 매번 DBA 해싱과 래치 획득 과정을 반복해야 한다
-> 동시 액세스가 심하면 캐시버퍼 체인 래치와 버퍼 Lock에 대한 경합도 발생
-> 인덱스 ROWID를 이용한 테이블 액세스는 생각보다 고비용 구조임
인덱스 ROWID는 우편구조
- ROWID는 우편주소(직접 방문이여서 느림)에, 메인 메모리 DB가 사용하는 포인터를 전화번호(빠름)에 비유 가능
- DBMS에서 젤 빠른 연산임에도 고비용임을 항상 생각해야 한다
2. 인덱스 클러스트링 팩터
- 클러스트링 팩터(CF)는 특정 컬럼을 기준으로 같은 값을 갖는 데이터가 서로 모여있는 정도를 말한다
- 아래 그림에서 위 부분은 클러스터링 팩터가 좋은 상태/아래는 클러스터링 팩터가 좋지 않은 상태
- 좋을 때에는 인덱스 레코드의 정렬 순서가 테이블 레코드 정렬 순서와 100% 일치하게 된다
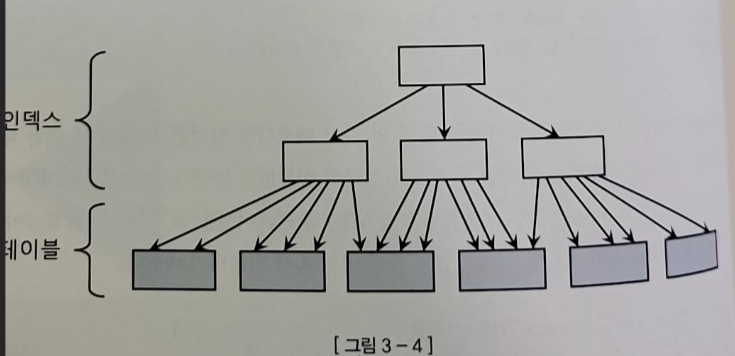
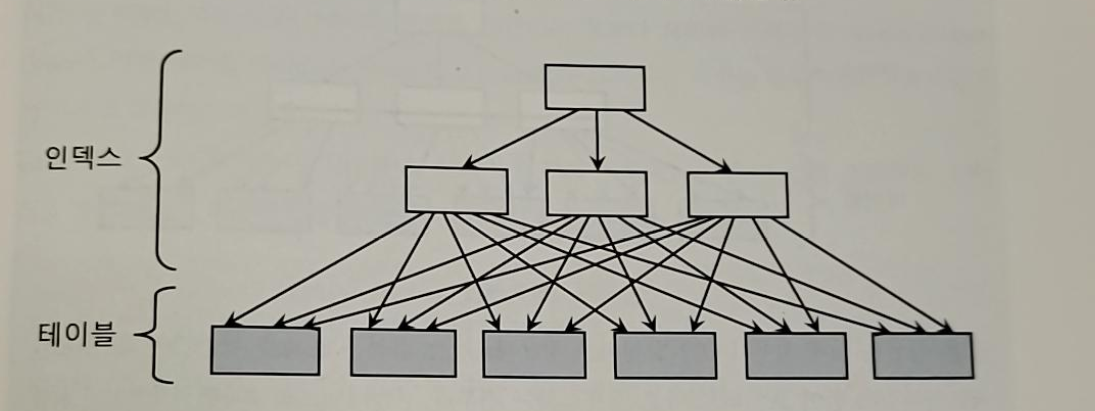
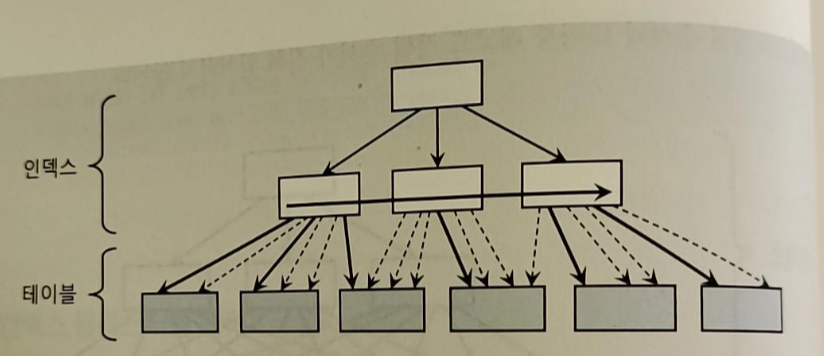
- 인덱스 클러스터링 팩터 효과
- 버퍼 피닝(Pinning) 효과 덕분에 효율적
- ROWID로 테이블을 액세스 할 때 래치 획득과 해시 체인 스캔 과정을 거쳐 어렵게 테이블 블록을 찾아간다
- DBMS는 테이블 블록에 대한 포인터(메모리 주소값)을 바로 해제하지 않고 유지한다
-> 그래서 다음 인덱스 코드를 읽을 때 마침 직전과 같은 테이블 블록을 가리키게 되고 래치 획득과 체인 스캔 과정을 생략하고 테이블 블록을 읽게 된다
-> 그래서 논리적 블록 I/O 과정을 생략할 수 있게 된다
-> 검정 선은 실제 블록 I/O가 발생하는 경우이다
3. 인덱스 손익 분기점
- ROWID를 이용한 테이블 액세스는 고비용 구조이기 때문에 읽어야 데이터가 일정량을 넘는 순간 테이블 전체를 스캔하는 것 보다 느려진다
- 인덱스 손익 분기점 : Index Range Scan에 의한 테이블 액세스가 Table Full Scan보다 느려지는 시점
- Table Full Scan은 성능이 일정하지만 인덱스를 이용해 데이터에 액세스 할 때에는 전체 중 몇 건을 추출하느냐에 따라 성능이 달라진다
- 이는 ☆랜덤 액세스, 인덱스 스캔량 증가 때문이다
- 이런 현상이 발생하는 이유들은 다음과 같다
- Table Full Scan은 시퀀셜 액세스인 반면 인덱스 ROWID를 이용한 테이블 액세스는 랜덤 액세스 방식
- Table Full Scan은 Multiblock I/O인 반면 인덱스 ROWID를 이용한 테이블 액세스는 Singleblock I/O 방식
- 인덱스 CF가 나쁨 정도에 따라 손익분기점이 달라진다
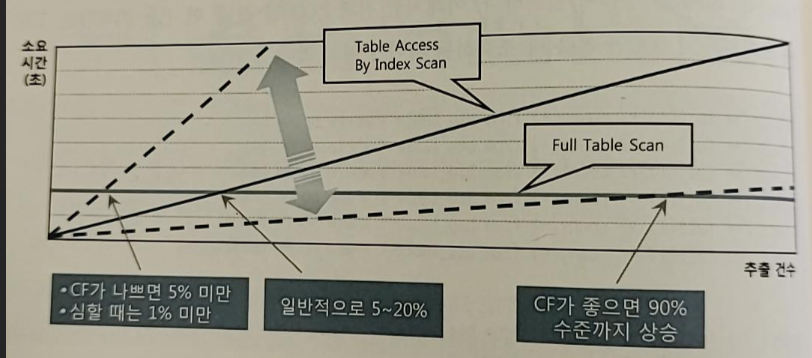
- 조회 건수가 많을 수록 인덱스를 이용하면 성능이 더 느려지는 현상을 경험할 수 있다
-> 버퍼 캐시에서 찾을 가능성이 작아지기 때문
-> 이는 배치 프로그램 튜닝 시 중요하게 다뤄진다
온라인 프로그램 튜닝 VS 배치 프로그램 튜닝
- 온라인 프로그램
- 소량 데이터를 읽고 갱신
- 인덱스를 이용하는 것이 효과적
- 조인도 대부분 NL 조인을 사용하게 된다
-> NL 조인은 인덱스를 사용하는 방식
-> 인덱스를 이용해 소트 연산을 생략한다면 부분범위 처리 방식에서 빠르게 응답 속도 낼 수 있음
- 배치 프로그램
- 항상 전체 범위 처리 기준 튜닝이 필요
- Full Scan과 해시 조인이 유리
ex)
- 한건/소량 데이터일 경우는 아래와 읽는 것이 효과적
select c.고객번호 ...
from 고객 c, 고객변경이력 h
where c.실명확인버놓 = :rmnno
and h.고객번호 = c.고객번호
and h.변경일시 = (
select max(변경일시) from 고객변경이력 m
where 고객번호 = c.고객번호
and 변경일시 >= trunc(add_months(sysdate, -12), 'mm')
and 변경일시 < trunc(sysdate, 'mm'))
)- 하지만 대량의 데이터를 읽을 때 조건절만 바꿔서 위와 같은 방식으로 수행한다면 결코 빠른 성능을 낼 수 없다
- Full Scan과 해시 조인을 사용해야 효과적
- 조건절에 해당하지 않는 데이터까지 읽는 비효율이 있지만 수행 속도는 훨씬 빠르다
insert into 고객_임시
select /*+ full(c) full(h) index_ffs(m.고객변경이력)
ordered no_merge(m) use_hash(m) use_hash(h) */
c.고객번호, ...
from 고객 c
,
(select 고객번호, max(변경일시) 최종변경일시 from 고객변경이력
where 변경일시 >= trunc(add_months(sysdate, -12), 'mm')
and 변경일시 < trunc(sysdate, 'mm')
group by 고객번호) m
, 고객변경이력 h
where c.고객구분코드 = 'A001'
and m.고객번호 = c.고객번호
and h.고객번호 = m.고객번호
and h.변경일시 = m.최종변경일시 - 고객변경이력을 두 번 읽는 비효율을 없애기 위해 WINDOW 함수를 사용할수도 있다
- 초대용량에서 Full Scan을 할 경우 시스템에 부담이 가고 느릴 수 있다
-> 파티션 전략을 잘 이용하는 것이 중요
-> 병렬처리를 하는 것도 좋다- 위의 경우 테이블 변경일시 기준 파티셔닝을 하면 변경일시 조건에 해당하는 파티션만 골라서 Full Scan을 하므로 부담을 줄일 수 있다
- 파티셔닝을 하는 이유는 Full Scan을 빠르게 하기 위해서이다
- 인덱스는 큰 테이블에서 아주 적은 일부 데이터를 빠르게 찾고자 할 때 사용하는 도구일 뿐 만능이 아님
4. 인덱스 컬럼 추가
- 테이블 액세스 최소화를 위해 가장 일반적으로 사용하는 기법은 인덱스에 컬럼 추가
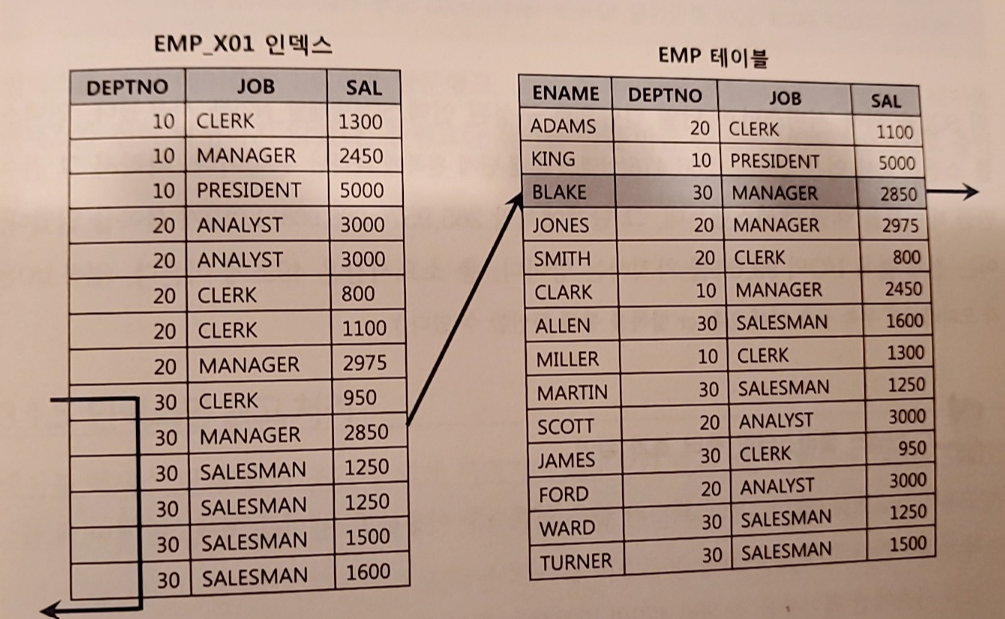
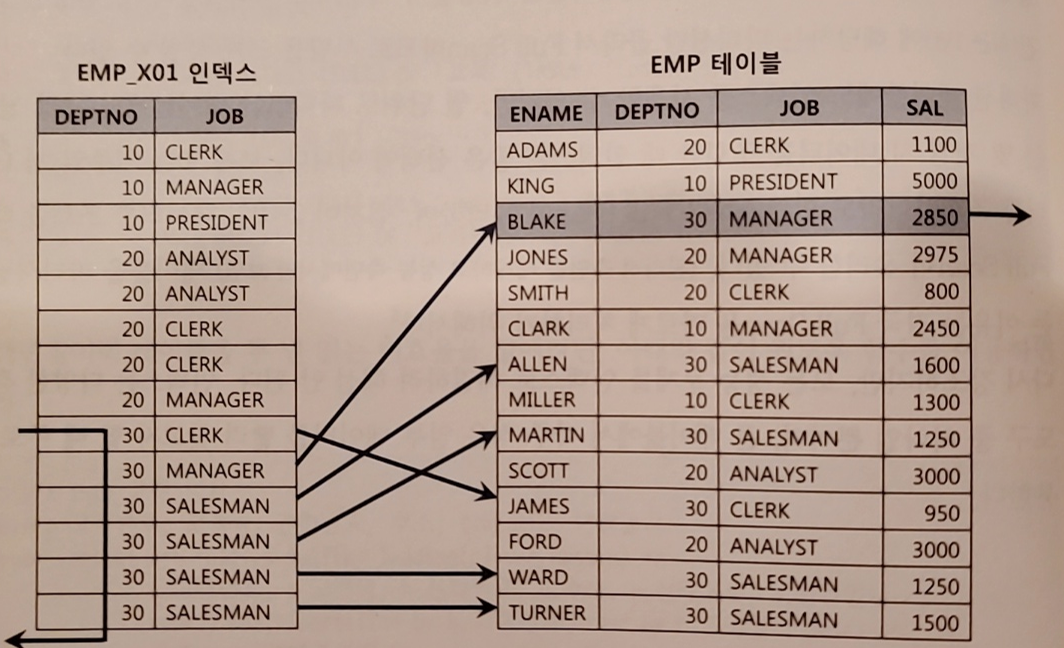
ex) 현재 DETPNO, JOB 순으로 구성된 인덱스가 있음
이 때 아래 쿼리 실행
select /*+ index(emp emp_x01) */ * from emp
where deptno = 30
and sal >= 2000-
그럼 아래와 같이 테이블을 여섯번 액세스함
-
그럼 기존 인덱스에 SAL 컬럼을 추가해주는 것만으로도 큰 효과를 얻을 수 있다
-> 인덱스 스캔량은 줄지 않지만 테이블 랜덤 액세스 횟수를 줄여준다
-> 불필요한 총 블록 I/O도 줄어들게 된다 -
이는 테이블 액세스 단계 필터 조건에 의해 버려지는 레코드가 많을 때 효과적이다
{kind=link}
5. 인덱스만 읽고 처리
- 테이블 랜덤 액세스가 많아도 필터 조건에 의해 버려지는 레코드가 거의 없다면 비효율은 없다
ex) 부서번호를 인덱스로 지정했을 때 아래 쿼리 실행
select 부서번호, SUM(수량)
from 판매집계
where 부서번호 like '12%'
group by 부서번호 - 쿼리나 인덱스 문제가 아니라 절대 일량이 많다는 문제가 있음
- 반드시 성능 개선을 해야 한다면 쿼리에 사용된 컬럼을 모두 인덱스에 추가해서 테이블 액세스를 아예 발생하지 않게 하는 방식이 있다
-> covered 쿼리 방식(covered 인덱스)
-> 하지만 추가해야 할 컬럼이 많아 실제로 적용하기 어려울 때가 있다
Include 인덱스
- 인덱스 키 이외에 미리 지정한 컬럼을 리프 레벨에 함께 저장하는 기능
- 인덱스 생성 시 include 옵션 지정, 컬럼 최대 1023 개 지정 가능
create index emp_x01 on emp (deptno) include (sal)
create index emp_x02 on emp (dempno, sal)- emp_x01의 경우 수직적 탐색에는 deptno만 사용하고 sal은 수평적 탐색에서만 사용된다
-> sal 컬럼은 테이블 랜덤 액세스를 줄이는 용도로 사용
-> 아래의 경우 covered 인덱스이므로 테이블 랜덤 액세스를 생략할 수 있다
select sal from emp where deptno = 20 - 아래 경우에도 랜덤 액세스 측면에서 emp_x01, emp_x02의 일량은 같음
-> 불필요한 테이블 액세스 발생 X
-> 하지만 인덱스 스캔량은 emp_x02 인덱스가 더 적음
-> sal 컬럼도 인덱스 액세스 조건이기 때문
select * from emp where deptno = 20 and sal >= 2000
select * from emp where deptno = 20 and sal <= 3000
select * from emp where deptno = 20 and sal between 2000 and 3000- 또한 아래 경우 emp_x01 인덱스는 소트 연산을 생략할 수 없다
select * from emp where detpno = 20 order by sal-> include 인덱스는 순전히 테이블 랜덤 액세스를 줄이는 용도로 개발됨
6. 인덱스 구조 테이블
- 인덱스를 이용한 테이블 액세스가 고비용 구조이므로 랜덤 액세스가 아예 발생하지 않도록 테이블을 인덱스 구조로 생성
-> IOT(Index Organized Table), 클러스터형 인덱스 - 일반 인덱스는 테이블을 찾아가기 위해 ROWID를 가짐
- IOT는 그 자리에 테이블 데이터 가짐
-> 즉 인덱스 리프 블록에 데이터를 모두 저장하고 있는 형태 - 일반 테이블은 힙 구조이므로, 데이터를 입력할 때 랜덤 방식을 사용한다
-> Freelist로부터 할당 받은 블록에 정해진 순서 없이 데이터 입력 - IOT 는 인덱스 구조이므로 정렬 상태를 유지하며 데이터를 입력
- 이는 인위적으로 클러스터링 팩터를 좋게 만드는 방법임
- 데이터를 랜덤 액세스가 아닌 시퀀셜 방식으로 액세스
- 부등호 조건 등 넓은 범위 읽을 때 유리
- 데이터 입력과 조회 패턴이 서로 다른 테이블에도 유리
ex) 실적 등록을 일자별(100명씩 일별 입력/1개 블록)로 진행, 실적 조회를 사원별로 진행
- 아래 쿼리를 가장 많이 사용한다고 가정
select substr(일자, 1, 6) 월도 , sum(판매금액) 총판매금액,
avg(판매금액) 평균판매금액
from 영업실적
where 사번 = 'S1234'
and 일자 between '20180101' and '20211231'
group by substr(일자, 1, 6)- 이 때 그냥 인덱스를 사용하면 클러스터링 팩터가 안좋기 때문에 조회 건수만큼 블록 I/O 가 발생
- 이 처럼 입력 조회 패턴이 다를 때 사번이 첫번째 정렬 기준이 되도록 처리하면 4개 블록만 읽고 처리할 수 있다
create table 영업실적 (사번 varchar2(5), 일자 varchar2(8), ... ,
constraint 영업실적_pk primary key (사번, 일자))
organization index;클러스터 테이블
1) 인덱스 클러스터 테이블
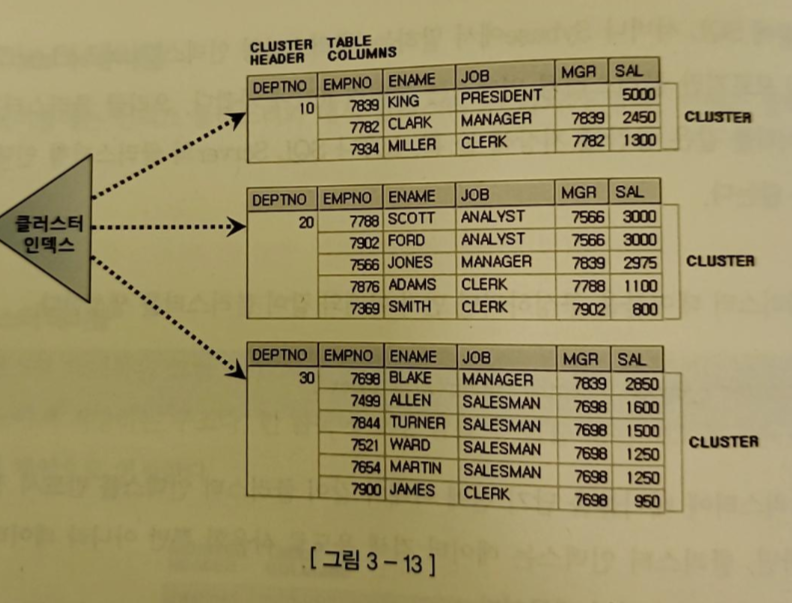
- 클러스터 키 값이 같은 레코드를 한 블록에 모아서 저장하는 구조
- 한 블록에 모두 담을 수 없을 때는 새로운 블록을 할당해 클러스터 체인으로 연결한다
- 다중 테이블 클러스터 : 여러 테이블 레코드를 같은 블록에 저장하는 것
- 일반 B*Tree 구조를 사용하지만 테이블 레코드를 일일이 가리키지 않고 해당 키 값을 저장하는 첫번째 데이터 블록을 가리킨다
-> 클러스터 인덱스는 테이블 레코드와 1:M관계를 갖는다
-> 클러스터 인덱스의 키 값은 Unique - 랜덤 액세스가 값 하나당 한 번씩 밖에 발생하지 않는다
-> 클러스터에 도달해서는 시퀀셜 방식으로 스캔하기 때문에 넓은 범위를 읽어도 비효율이 없다
2) 해시 클러스터 테이블
- 인덱스 대신 해시 알고리즘을 이용해 클러스터를 찾아간다는 점만 다르다
부분범위 처리 활용
- 부분범위 처리 원리로 인덱스로 빠른 응답속도를 낼 수 있다(대상 레코드가 아무리 많아도!)
1~2. 부분범위 처리
- 부분 범위 처리 : Fetch Call이 있을 때마다 일정량씩 나누어 전송하는 것
- DBMS가 클라이언트에게 데이터를 전송할 때 먼저 읽는 데이터부터 일정량(Array Size)씩 나누어 전송한다
-> 전송 못한 부분이 있어도 client로부터 추가 Fetch Call을 받기 전까지 기다린다(데이터 전송 후 서버 프로세스는 CPU를 OS에 반환하고 대기 큐에서 잠) - order by 등을 사용하면 전체범위처리가 된다
-> db 서버는 모든 데이터를 다 읽어 정렬을 마친 후에야 클라이언트에게 데이터를 전송할 수 있다
(하지만 해당 정렬 기준에 부합하는 인덱스가 있다면 부분범위 처리 가능) - 대량 데이터의 경우 Fetch Call을 줄이기 위해 Array Size를 크게 하는 전략을 사용할 수 있다
<-> 반대로 앞의 일부 데이터만 Fetch 하다 멈춘다면 Array Size를 작게 설정하는 것이 유리하다
3. OLTP 환경에서 부분 범위 처리에 의한 성능개선 원리
- OLTP : Online Transaction Processing
-> 일반적으로 소량 데이터를 읽고 갱신하지만, 수천 수만 건을 조회 할 경우도 있다
-> 이 때 인덱스를 이용한다면 많은 테이블 랜덤 액세스가 발생할 수 있기 때문에 느릴 수 있다 - 다행히 사용자는 쿼리 집합 결과가 많을 때 모든 결과를 다 확인하지 않고 특정 정렬 순서로 상위 일부 데이터만 확인하는 경우가 많다
-> 항상 정렬 상태를 유지하는 인덱스를 사용하면 앞쪽 일부 데이터를 아주 빠르게 보여줄 수 있다
-> sort order by 연산을 생략할 수 있는 인덱스 구성을 하면 된다
멈출 수 있어야 의미 있는 부분 범위 처리
- 문제는 앞쪽 일부만 출력하고 멈출 수 있는가이다
- DB 툴들은 그렇게 구현이 돼있음
- n-Tier 아키텍처에서는 클라이언트가 특정 DB 커넥션을 독점할 수 없기 때문에 SQL 조회 결과를 클라이언트에게 모두 전송하고 커서를 닫게 된다
-> SQL 결과 집합을 나누어 전송하기 어려움
배치 IO
- 읽는 블록마다 건건이 I/O Call을 발생시키는 비효율을 줄이기 위해 고안한 기능
- 인덱스 테이블을 이용해 테이블을 액세스하다 버퍼 캐시에서 블록을 찾지 못하면 일반적으로 디스크 블록을 바로 읽게 된다
-> 배치 I/O를 이용하면 테이블 블록에 대한 디스크 I/O Call을 미뤘다가 읽을 블록이 일정량 쌓이면 한꺼번에 처리한다 - 배치 I/O를 이용하면 인덱스를 이용해서 출력하는 데이터 정렬 순서가 매번 다를 수 있다
-> 때문에 배치를 할 때 order by를 하면 sort order by 연산을 생략할 수 있는 인덱스 구성임에도 옵티마이저가 order by 연산을 진행하게 된다
-> 때문에 애초에 order by를 안하는 상황이나 sort 연산을 생략할 수 없는 경우에는 이 기능을 사용하지 않을 이유가 없음 - 인덱스 기능을 믿고 order by를 생략한 경우 batch 를 생략하는 경우가 많은데, 바람직 하지 않다
-> order by는 명시적으로 써주는 것이 좋다
인덱스 스캔 효율화
- 운영환경에서 할 수 있는 가장 일반적인 튜닝은 인덱스 컬럼 추가
-> 테이블 랜덤 액세스 최소화가 SQL 성능에 미치는 영향이 매우 크지만 튜닝 기법은 단순 - 하지만 인덱스 스캔 효율화는 튜닝 요소가 다양하고 SQL 작성 시 주의할 내용이 많음
1. 인덱스 탐색
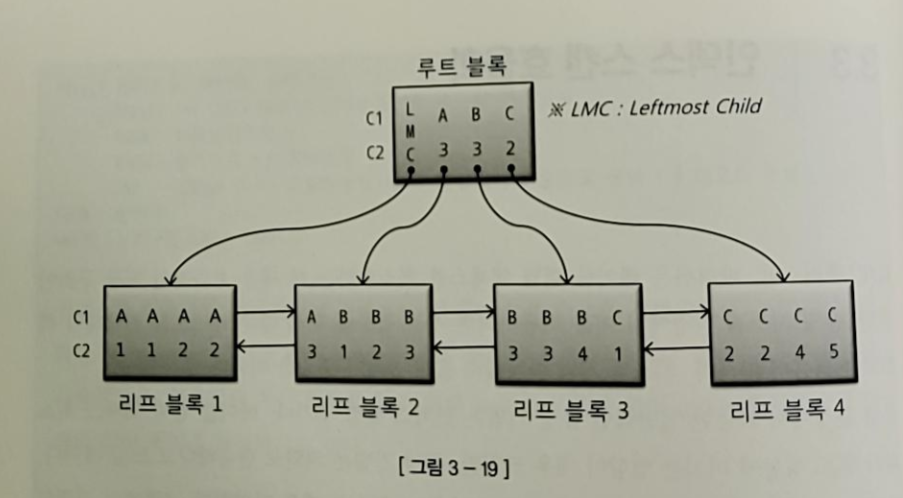
- 각 레코드는 하위 노드를 가리키는 블록주소를 가지게 된다
-> 하위 블록에는 자신의 키 값보다 크거나 같은 값을 갖는 레코드가 저장되게 된다 - 루트 블록에는 키 값을 갖지 않는 특별한 레코드가 있다(LMC)
- LMC는 자식 노드 중 가장 왼쪽 끝에 위치한 블록으로 LMC가 가리키는 블록에는 키 값을 가진 첫번째 레코드보다 작거나 같은 값을 가진 레코드가 저장돼있다
-> ex) A3 이하 값들 - 이 때 조건절에 따라서 스캔의 범위가 달라지게 된다
1) WHERE C1 = 'B'
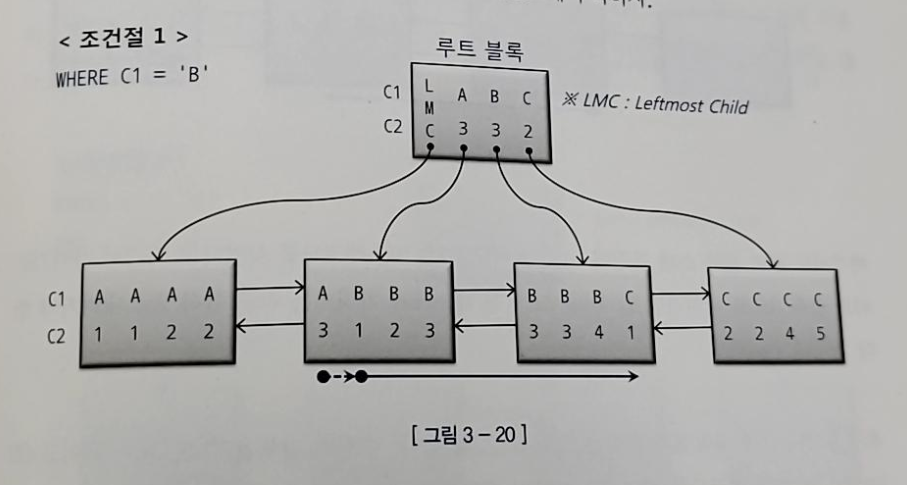
- C1 = 'B'인 첫번째 레코드를 찾고 'C'를 만나는 순간 스캔을 멈춘다
- 첫번째 블록에서 C1 = B, C2 = 3인 것을 찾았다고 그대로 내려가면 안되고 그 직전 레코드가 가리키는 리프블록 2로 가야 B로 시작하는 시작점을 찾을 수 있다
2) WHERE C1 = 'B' AND C2 = 3
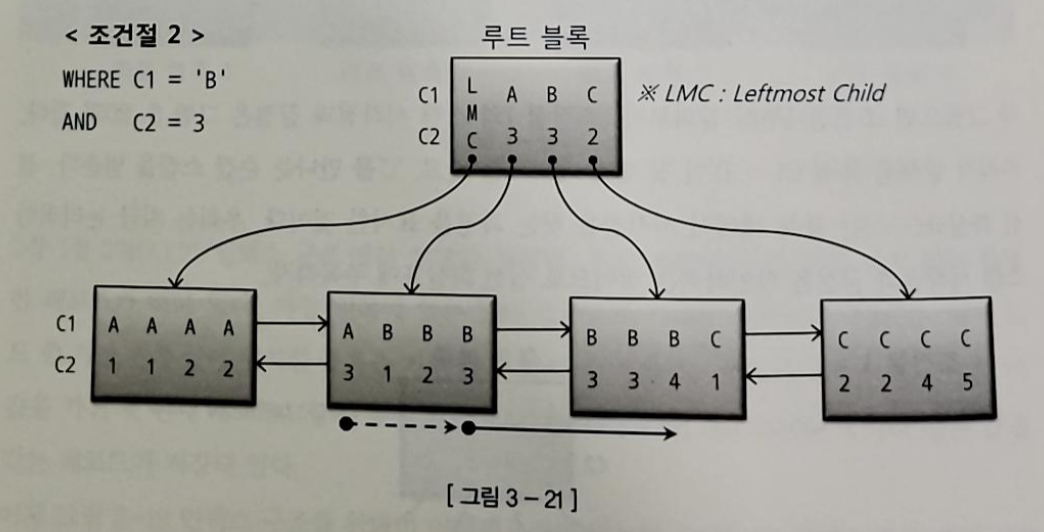
- 여기서도 C1 = 'B', C2 = '3'인 레코드를 찾고 그 직전 레코드가 가리키는 리프블록으로 가서 스캔을 시작한다
- C1, C2 조건절 모두가 스캔량을 줄이는 역할을 했다
3) WHERE C1 = 'B' AND C2 >= 3
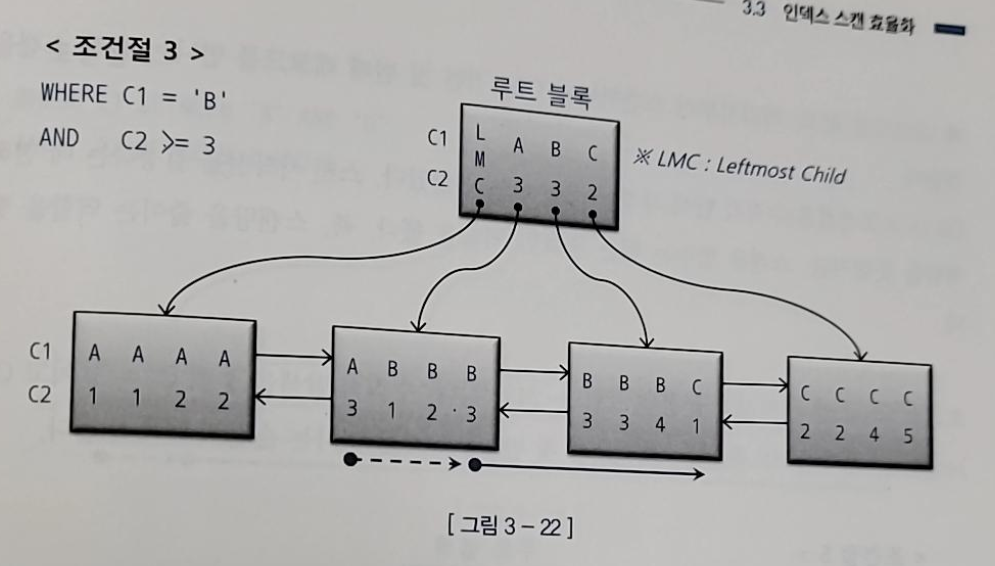
- C2 >= 조건은 스캔을 멈추는데 역할을 하지는 못하지만 스캔 시작점이 달라지도록 한다
-> 스캔량이 달라진다
4) WHERE C1 = 'B' AND C2 <= 3
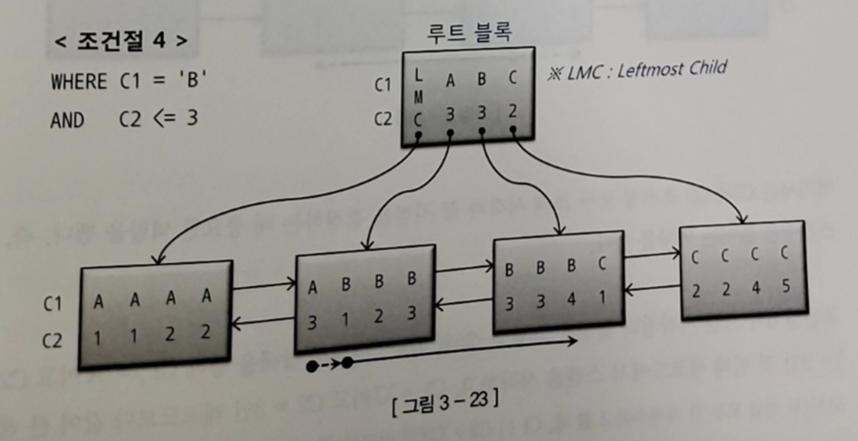
- 수직적 탐색을 통해 C1 = 'B'인 첫번째 레코드(시작점)을 찾음
- 시작점부터 스캔하다가 C2 > 3 인 첫번째 레코드를 만나는 순간 스캔을 멈춘다
-> 스캔량을 줄이는 것에 역할을 한다
5) WHERE C1 = 'B' AND C2 BETWEEN 2 AND 3
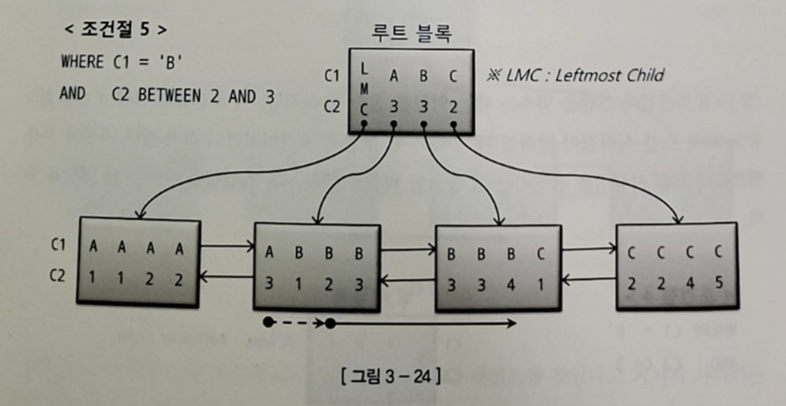
- 수직적 탐색을 통해 C1 = 'B' 이고 C2 >= 인 첫번째 레코드를 찾는다
- C2 > 3인 첫번째 레코드를 만나는 순간 스캔을 끝낸다
-> C1, C2 조건절 모두 스캔 시작과 끝 지점을 지정하는데 중요한 역할을 했다(스캔량 줄임)
6) WHERE C1 BETWEEN 'A' AND 'C' AND C2 BETWEEN 2 AND 3
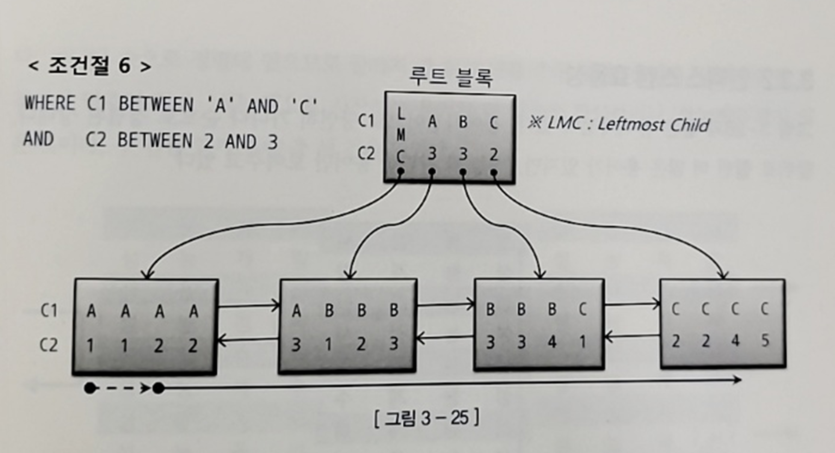
- C1 조건절은 스캔 시작과 끝 지점을 결정하는데 중요한 역할을 함
- 하지만 C2는 스캔량을 줄이는 것에 도움이 되지 않음
-> A, C 구간에서는 그 역할을 했지만 B 구간에서는 전혀 역할을 하지 못함
2. 인덱스 스캔 효율성
ex1. 성능과 관련된 용어사전에서 스캔을 하는 경우를 보여준다(가나다순 정렬)
1-1) 성능검으로 스캔
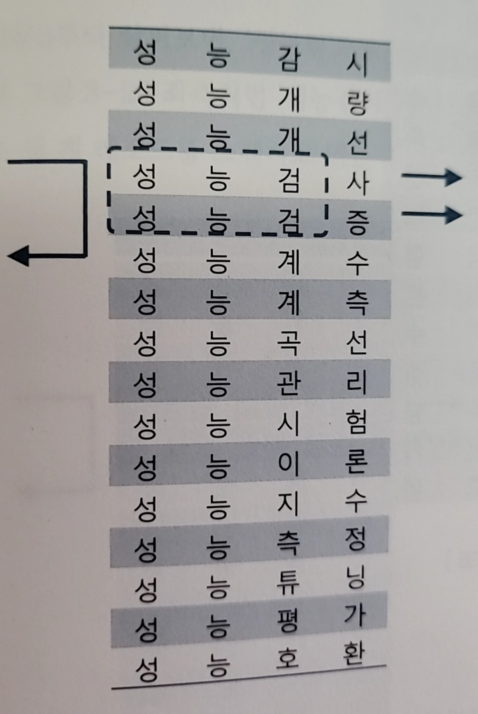
- 성능검으로 검색
- 성능계수에서 멈추면 되므로 2건을 얻기 위해 3건을 얻음
1-2) 성능으로 시작하고 네번째 문자가 선인 용어
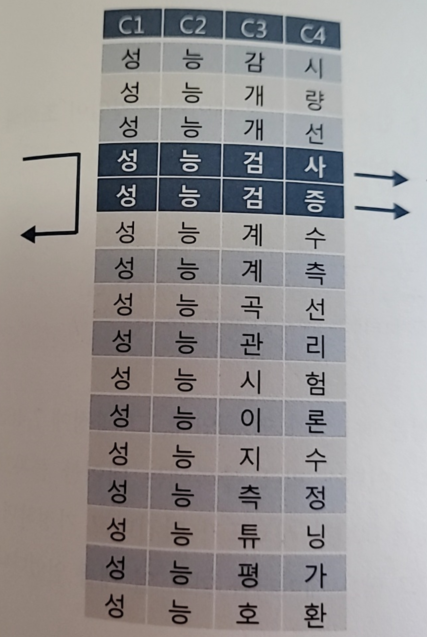
- 성능으로 시작하는 단어를 모두 스캔하게 된다
ex2. C1 + C2 + C3 + C4로 인덱스를 생성
2-1) where C1 = '성' and C2 = '능' and C3 = '검'

- 인덱스 수직적 탐색을 통해 성능검사 레코드로 찾아감
- 성능계수까지 총 3개 레코드를 스캔하고 멈춘다
2-2) where C1 = '성' and C2 = '능' and C3 = '선'
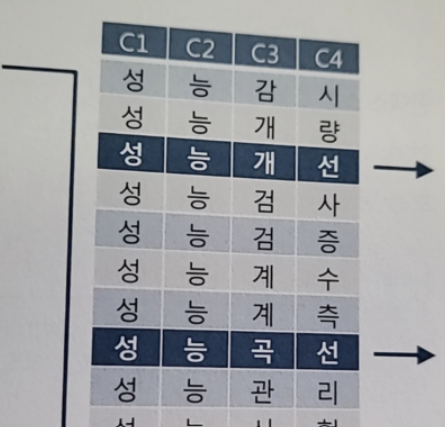
- 전체 스캔
-> 인덱스 전체 컬럼이 조건절에 없기 때문에 효율적이지 않다 - 인덱스 선행 컬럼이 조건절에 없거나 '=' 조건이 아니면 인덱스 스캔 과정에서 비효율이 발생한다
인덱스 스캔 효율성 측정
- SQL 트레이스를 통해 알 수 있다
-> 읽은 블록의 개수 등을 확인할 수 있다
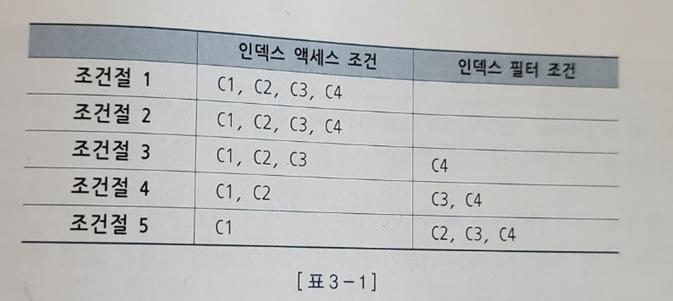
3. 액세스 조건과 필터 조건
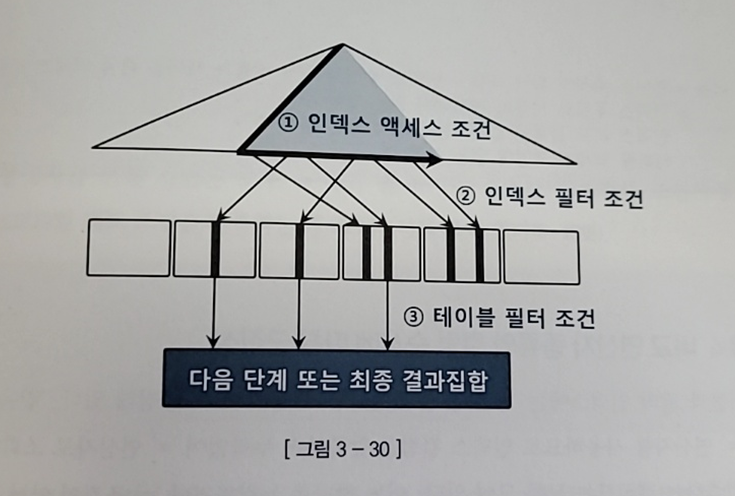
- 인덱스를 스캔하는 단계에 처리하는 조건절은 액세스 조건과 필터 조건으로 나뉜다
- 인덱스 액세스 조건
- 인덱스 스캔 범위를 결정
- 인덱스 필터 조건
- 테이블로 액세스할지를 결정하는 조건
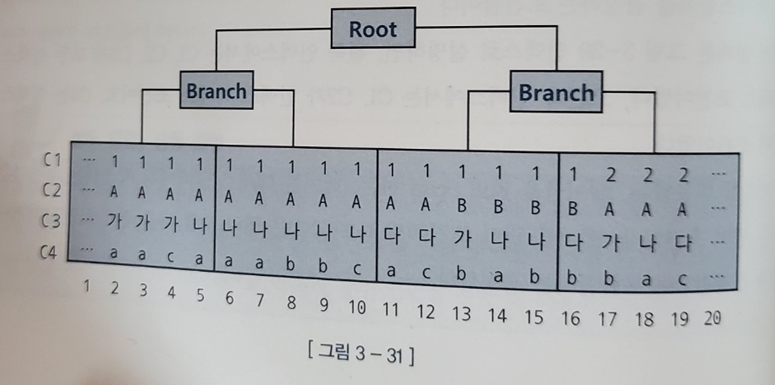
- ex) 2-2에서 C1, C2는 인덱스 액세스 조건, C4가 인덱스 필터 조건
- 인덱스 이용/테이블 Full Scan 경우 모두 테이블 액세스 단계에서 사용되는 조건절은 필터 조건이다
- 테이블 필터 조건은 쿼리 수행 다음 단계로 전달하거나 최종 결과집합에 포함할지를 결정한다
4. 비교 연산자 종류와 컬럼 순서에 따른 군집성
- 인덱스는 같은 값을 가지는 레코드들이 서로 군집해있다
- 인덱스 컬럼을 앞쪽부터 누락없이 '=' 연산자로 조회하면 조건절을 만족하는 레코드들이 모두 모여있게 된다
-> 이 때 어느 하나를 누락하거나 '='이 아닌 연산자로 조회하면 조건절을 만족하는 레코드가 서로 흩어진 상태가 되게 된다
-
ex1) WHERE C1 = 1 and C2 = 'A' and C3 = '나' and C4 = 'a'
- 레코드들이 5 ~ 7까지 모여있다
-
ex2) WHERE C1 = 1 and C2 = 'A' and C3 = '나' and C4 >= 'a'
- 선행 컬럼이 모두 '=' 조건이고 맨 마지막 컬럼만 범위검색 조건(부등호, BETWEEN, LIKE)일 때도 조건을 만족하는 레코드가 모여있다(5 ~ 10)
-
ex3, ex4, ex5)
- WHERE C1 = 1 and C2 = 'A' and C3 = between '가' and '다' and C4 = 'a'
- WHERE C1 = 1 and C2 <= 'B' and C3 = '나' and C4 between 'a' and 'b'
- WHERE C1 between 1 and 3 and C2 = 'A' and C3 = '나' and C4 = 'a'
- 선행 컬럼이 모두 '=' 조건인 상태에서 첫번째 나타나는 범위검색 조건까지만 만족하는 인덱스 레코드는 모두 연속해서 모여있다
- 하지만 그 이하 조건까지 만족하는 레코드는 비교 연산자 종류 상관 없이 흩어진다
-> 물론 범위를 줄여주긴 하겠지만 무시할 정도이다
5. 인덱스 컬럼이 등치(=) 조건이 아닐 때 생기는 비효율
- 인덱스 스캔 효율성은 인덱스 컬럼을 조건절에 모두 등치 조건으로 사용할 때 가장 좋음
- 인덱스 조건 중 일부가 조건절에 없거나 등치조건이 아니여도 그것이 뒤쪽 컬럼일 때는 비효율이 없음
- 선행 컬럼이 조건절에 없거나 범위 조건 검색이면 비효율이 발생함
6. BETWEEN 을 IN-List로 전환
- 범위검색 컬럼이 맨 뒤로 가도록 인덱스 순서를 변경하면 좋지만, 운영 시스템에서 인덱스 구성을 바꾸기는 쉽지 않다
-> BETWEEN 조건을 IN-List로 바꿔주면 큰 효과를 얻는 경우가 있다
-> ex) WHERE 인터넷매물 in ('1', '2', '3')
-> 인덱스 수직적 탐색이 세번 일어나게 된다
-> 이는 = 조건으로 세번 탐색한 것을 union 한 것과 같다
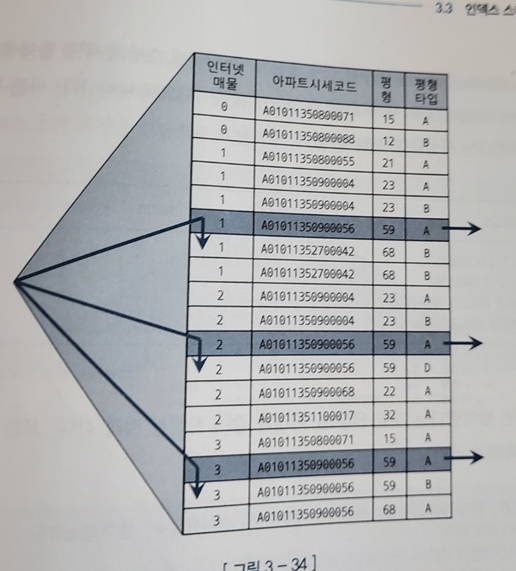
- Index Skip Scan 방식으로 유도해도 비슷한 효과를 얻을 수 있다
- In-List 항목 개수가 늘어날 수 있으면 BEETWEEN을 In-List 항목으로 전황하기 어려울 수 있다
-> NL 방식의 조인문이나 서브쿼리로 구현하면 된다
-> 인터넷 매물을 = 조건으로 구현하고 있다
select /*+ order use_nl(b) */ from 통합코드 a, 매물아파트매매 b
where a.코드구분 = 'CD064'
and a.코드 between '1' and '3'
and b.인터넷매물 = a.코드 BETWEEN 조건을 In-List 전환할 때 주의사항
- In-List 개수가 많으면 안된다
- In-List 개수가 많으면 수직적 탐색이 많이 발생한다
->블록 I/O가 더 많이 발생하는 경우가 있다
-> 데이터 분포/수직적 탐색 비용을 따져본 후 변환을 해야한다
7. Index Skip Scan 활용
- 조건절을 바꾸지 않아도 Between 조건을 In-List조건으로 변환하는 것과 같은 효과를 내는 방법으로 Index Skip Scan을 이용하는 것이 있음
- 선두 컬럼이 BETWEEN이여서 나머지 검색 조건을 만족하는 데이터들이 서로 멀리 떨어져 있을 때 사용하면 좋다
8. IN 조건은 '='인가
- IN 조건은 =이 아니기 때문에 인덱스 구성에 따라 성능도 달라질 수 있다
- ex) 고객별가입상품 테이블의 고객번호의 평균 카디널리티는 3이다(고객별로 평균 3건의 상품을 가입)
- 이 때 아래 다음 쿼리 실행
select * from 고객별가입상품
where 고객번호 = :cust_no
and 상품ID in ('N1', 'N2', 'N3')-
인덱스1) 상품ID + 고객번호 순 생성
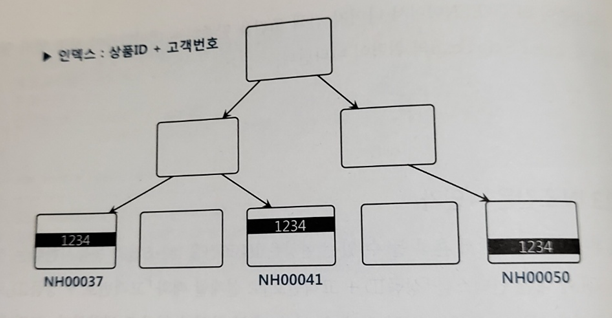
- 같은 상품은 고객번호 순으로 정렬된 상태로 하나(또는 연속된 두 개)의 리프 블록에 저장된다
- 고객번호 기준으로는 같은 고객번호가 상품ID에 따라 뿔뿔히 흩어진 상태가 된다
-> 이 때는 상품ID 조건절이 IN-List Iterator 방식으로 풀리는 것이 효과적이다
-> IN 조건이 '=' 조건이 된다 - 이 때 IN은 상품아이디를 각각 '=' 조건으로 찾은 것을 Union all 하는 것과 같다
-> 인덱스를 수직적으로 3번 탐색하는 과정에서 9개의 블록을 읽는다 - 고객번호와 상품ID 둘 다 인덱스 액세스 조건으로 사용된다
-> 이와 같은 구성의 인덱스에서는 IN-List Iterator 방식을 사용하지 않는다면 상품ID가 필터 조건이므로 테이블 전체/인덱스 전체 스캔이 되게 된다
- 인덱스2) 고객번호 + 상품ID
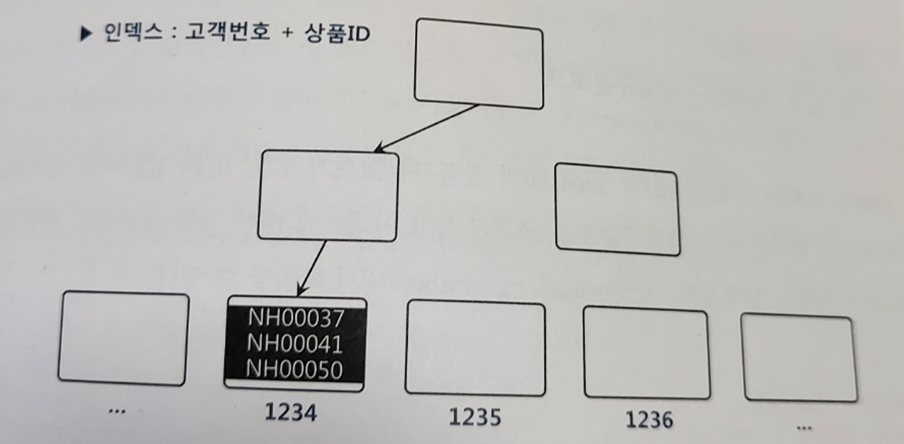
- IN-List Iterator 방식 이용 시 위와 같이 9새의 블록을 읽게 된다
- IN-List Iterator 방식을 사용하지 않으면 상품ID 조건절은 필터로 처리한다
-> 고객정보만 액세스 조건이므로 해당 고객번호 레코드를 모두 스캔한다
-> 같은 고객은 한 블록(또는 연속된 두 블록)에 있으므로 블록 I/O는 수직적 탐색 과정을 포함해 총 3개(또는 4개만 발생한다)
- IN 조건이 = 이 되려면 IN-List Iterator 방식으로 풀려야 한다
- 그렇지 않으면 IN은 필터 조건이다
-> 상품 ID가 액세스 조건으로 의미있는 역할을 하기 위해서는 고객별 상품 데이터가 아주 많아야 한다
-> 그렇지 않으면 상품ID는 필터 방식으로 처리되는 것이 낫다
NUM_INDEX_KEYS 힌트 사용
- num_index_keys 힌트를 이용해 IN-List를 액세스 조건 또는 필터 조건으로 유도할 수 있다
- 필터조건으로 유도
- 힌트를 사용하지 않고 인덱스 컬럼을 가공하는 방법도 있다
select /*+ num_index_keys(a 고객별가입상품_X1 1) */ * from 고객별가입상품
where 고객번호 = :cust_no
and 상품ID in ('N1', 'N2', 'N3')
select * from 고객별가입상품
where 고객번호 = :cust_no
and RTRIM(상품ID) in ('N1', 'N2', 'N3')
select * from 고객별가입상품
where 고객번호 = :cust_no
and 상품ID || '' in ('N1', 'N2', 'N3')- 액세스 조건으로 유도
select /*+ num_index_keys(a 고객별가입상품_X1 2) */ * from 고객별가입상품
where 고객번호 = :cust_no
and 상품ID in ('N1', 'N2', 'N3')9. BETWEEN과 LIKE 스캔 범위 비교
- LIKE보다 BETWEEN을 사용하는 것이 낫다
- BETWEEN의 인덱스 스캔량이 훨씬 적다
10. 범위검색 조건을 남용할 때 생기는 비효율
- ex) 회사코드, 지역코드, 상품명으로 가입상품 테이블 데이터 조회
- 인덱스는 회사코드 + 지역코드 + 상품명 순
- 이 때 회사 코드는 반드시 입력하지만 지역코드는 반드시 입력하지 X
- 상품명은 단어 중 일부만 입력 가능
-> 이 때 아래 쿼리 중 하나를 선택적으로 사용할 수 있음
쿼리 1 : 회사코드, 지역코드 , 상품명 모두 입력
select 고객ID, 상품명, 지역코드
from 가입상품
where 회사코드 =:com
and 지역코드 = :reg
and 상품명 like :prod || '%'
쿼리 2 : 회사코드, 상품명만 입력
select 고객ID, 상품명, 지역코드
from 가입상품
where 회사코드 =:com
and 상품명 like :prod || '%'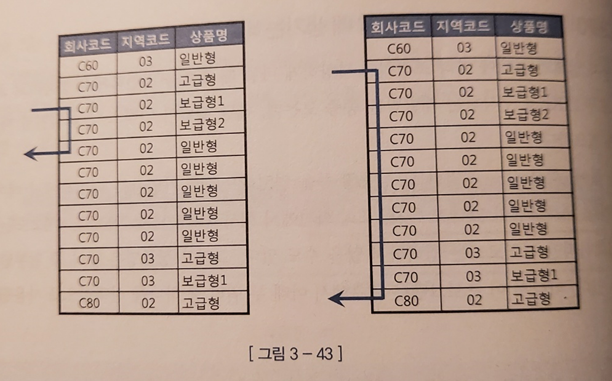
- 그런데 위 쿼리를 귀찮아서 두가지 상황을 하나의 SQL로 처리하려고 하면 지역코드를 입력하지 않을 경우에도 스캔 범위가 오른쪽처럼 늘어나는 비효율이 발생하게 된다
- BETWEEN의 경우에도 사용하지 않는 범위를 만들기 위해 '__' ~ 'ZZZZZZ'를 입력한 경우가 있는데 이 경우에도 인덱스 스캔 효율을 줄이게 된다
11. 다양한 옵션 처리 방식의 장단점 비교
OR 조건 사용
select * from 거래
where (:cust_id is null or 고객ID = :cust_id)
and 거래일자 between :dt1 and :dt2- 위 경우 고객 ID + 거래일자 순으로 인덱스를 구성해도 이를 사용할 수 없다
- 인덱스 선두 컬럼에 대한 옵션 조건에 OR 조건을 사용해서는 안된다
- 거래일자 + 고객ID 순의 인덱스는 사용할 수 있다
- 하지만 고객 ID를 필터 조건으로 사용한다는 점에서 매우 비효율적이다
-> 거래일자 조건을 위해 인덱스 스캔(랜덤액세서 다수 발생) + 고객ID 필터링
- 하지만 고객 ID를 필터 조건으로 사용한다는 점에서 매우 비효율적이다
- 인덱스에 포함되지 않은 컬럼에 대한 옵션 조건은 어차피 테이블에서 필터링할 수 밖에 없기 때문에 OR 조건 사용해도 무방
- OR 조건 활용한 옵션 조건 처리는 다음과 같다
- 인덱스 액세스 조건으로 사용 불가
- 인덱스 필터 조건으로도 사용 불가
- 테이블 필터 조건으로만 사용 가능
- OR 조건을 이용한 옵션 조건 처리를 사용하는 것은 좋지 않다
- 하지만 옵션 조건 컬럼이 NULL 허용 컬럼이여도 사용할 수 있다는 유일한 장점이 있다
LIKE/BETWEEN 조건 활용
- 변별력이 좋은 필수 조건이 있는 상황에서 사용하는 것이 좋다
select * from 상품
where 등록일시 >= trunc(sysdate) -- 필수 조건
and 상품분류코드 like :prd_cls_cd || '%' -- 옵션 조건 -> 필수 조건 컬럼을 인덱스 선두에 두고 액세스 조건으로 사용하면 나쁘지 않다
-> LIKE/BETWEEN이 인덱스 필터 조건이여도 충분한 성능을 낼 수 있다
-> 특히 필수 조건 컬럼이 '='이면 옵션 조건인 상품분류코드도 인덱스 액세스 조건이 될 수 있어 성능이 좋다
-
필수 조건의 변별력이 좋지 않다면 Table Full Scan이 유리할 수 있다
-> Index Range Scan을 선택할 때 문제 발생 가능 -
LIKE/BETWEEN 패턴을 사용할 때 아래 경우들을 확인해야 한다
1) 인덱스 선두 컬럼
- 인덱스 선두 컬럼에 대한 옵션 조건을 LIKE/BETWEEN으로 처리하는 것은 금물
2) NULL 허용 컬럼
- 성능을 떠나 결과 집합에 오류가 생김
- LIKE/BETWEEN에서 컬럼 값이 NULL인 데이터는 결과 집합에서 누락됨
3) 숫자형 컬럼
- 숫자형이면서 인덱스 액세스 조건으로도 사용 가능한 컬럼은 LIKE 방식 사용 불가
- 자동 형변환 때문에 문제 발생 가능
4) 가변 길이 컬럼
- LIKE를 옵션 조건에 사용할 때는 컬럼 값 길이가 고정적이여야 한다
-> 컬럼 값 길이가 가변적일 때는 변수 값 길이가 같은 레코드만 조회되도록 조건절을 추가해야 한다 - 혹은 % 없는 like 조건을 이용해 정확하게 값이 일치할 때만 출력하도록 변경한다
UNION ALL
- 변수 값에 따라서 위 아래 SQL 중 어느 하나만 실행되게 하는 방식
select * from 거래
where :cust_id is null
and 거래일자 between :dt1 and :dt2
union all
select * from 거래
where :cust_id is not null
and 고객ID = :cust_id
and 고객일자 between :dt1 and :dt2 - SQL 코딩량이 길어진다는 단점 빼고는 좋음
NVL/DECODE 함수 활용
select * from 거래
where 고객ID = nvl(:cust_id, 고객ID)
and 거래일자 between :dt1 and :dt2
또는
select * from 거래
where 고객ID = decode(:cust_id, null, 고객ID, :cust_id_
and 거래일자 between :dt1 and :dt2- 변수 입력 여부에 따라 다른 인덱스를 사용한다는 것을 표현
- 고객 ID 컬럼을 함수 인자로 사용(인덱스 컬럼 가공)했지만 OR Expansion 쿼리 변환으로 인해 인덱스로 사용 가능
- 옵션 조건 컬럼을 인덱스 액세스 조건으로 사용하며 UNION ALL과 같은 성능을 내게 된다
- 하지만 LIKE 패턴처럼 NULL 허용 컬럼에 사용할 수 없다
- 옵션 조건 처리용 NVL/DECODE 함수를 여러 개 사용하면 변별력이 가장 좋은 컬럼 기준으로 한 번만 OR Expansion이 일어나게 된다
-> OR Expansion 기준으로 선택되지 않으면 인덱스 구성 컬럼이어도 모두 필터 조건으로 처리된다
-> 때문에 모든 옵션 조건을 이 방식으로 처리할 수는 없다
Dynamic SQL
- 조건절을 동적으로 구성할 수 있으면 위에 보다 더 수월하게 작업 가능
12. 함수호출부하 해소를 위한 인덱스 구성
- PLSQL은 생각보다 느리다
- 가상머신(VM) 상에서 실행되는 인터프리터 언어
- 호출 시마다 컨텍스트 스위칭 발생
- 내장 SQL에 대한 Recursive Call 발생
- 액세스 조건을 고려한 인덱스 구성을 하면 함수 호출 횟수를 줄일 수 있다
4. 인덱스 설계
1. 인덱스 설계가 어려운 이유
- 인덱스가 많으면 아래와 같은 문제 발생
- DML 성능 저하(TPS 저하)
- DB 사이즈 증가 -> 디스크 공간 낭비
- DB 관리 및 운영 비용 상승
- 인덱스 추가는 시스템에 부하를 주고 인덱스 변경은 운영 리스크가 크다
2. 가장 중요한 선택 기준
- 조건절에 항상 사용하거나 자주 사용하는 컬럼을 선정
- 그렇게 선정한 컬럼 중 '='조건으로 자주 조회하는 컬럼을앞으로 두어야 한다
3. 스캔 효율성 이외의 판단 기준
- 그 외에도 수행빈도, 업무상 중요도, 클러스터링 팩터, 데이터량, DML 부하, 저장공간, 인덱스 관리 비용 등을 고려해야 한다
- 이중 수행빈도의 중요도가 가장 높다
- NL 조인할 때 어느 쪽에서 자주 액세스 되는지도 중요하다
- outer쪽에서 액세스 하는 인덱스는 스캔 과정에 비효율이 있어도 큰 문제 X
- inner쪽 인덱스 스캔 과정에 비효율은 성능에 큰 문제 야기 가능
-> inner쪽 인덱스는 '=' 조건 컬럼을 선두에 두는 것이 중요
-> 테이블 액세스 없이 인덱스에서 필터링을 마치도록 구성하는 것이 좋다
- NL 조인할 때 어느 쪽에서 자주 액세스 되는지도 중요하다
4. 공식을 초월한 전략적 설계
- 최적 인덱스를 설계하고 나머지 액세스 경로는 약간의 비효율이 있지만 목표 성능을 달상하는 수준으로 인덱스 구성 필요
- 인덱스 개수를 최소화하면 차후 상황에 따라 최적의 인덱스를 추가할 여유 생김
5. 소트 연산을 생략하기 위한 컬럼 추가
- I/O 를 최소화하며 소트 연산을 생략하려면 아래와 같이 인덱스 구성
- '=' 연산자로 사용한 조건절 컬럼 선정
- ORDER BY 절에 기술한 컬럼 추가
- '=' 연산자가 아닌 조건절 컬럼은 데이터 분포를 고려해 추가 여부 결정
IN 조건은 '='가 아니다
- IN 조건이 '='이 되려면 IN-List Iterator 방식으로 풀려야 한다
- 소트 연산을 생략하려면 IN 조건절이 IN-List Iterator 방식으로 풀리면 안된다
-> IN 조건절을 인덱스 액세스 조건으로 사용하면 안된다
-> 필터 조건으로 사용해야 함
6. 결합 인덱스 선택도
- 인덱스 생성 여부를 결정할 때는 선택도가 충분히 낮은지가 중요한 판단 기준
- 선택도
- 전체 레코드 중에서 조건절에 의해 선택되는 레코드 비율
- 카디널리티 : 선택도 X 총 레코드 수
- 인덱스 선택도 : 인덱스 컬럼을 모두 =로 조회할 때 평균적으로 선택되는 비율
- 선택도가 낮은 것은 변별력이 높다는 뜻이다
- 하지만 선택도가 낮은 컬럼을 앞에 두려는 노력은 의미 없거나 손해일 수 있다
- 따라서 중요한 것은 항상 사용하는 컬럼을 두고 그 중 = 조건을 앞쪽에 위치시키는 것이다
7. 중복 인덱스 제거
- 완전 중복 : 한 인덱스 선두 컬럼이 다른 인덱스 전체를 완전히 포함하는 경우
- 불완전 중복 : 선두 컬럼에 다른 인덱스 전체를 포함하지는 않지만 이후 카디널리티가 매우 낮다면 사실상의 중복
-> 이를 제거
8. 인덱스 설계도 작성을 통한 튜닝
1) 변경 전 인덱스 구성
2) 변경 후 인덱스 구성
3) 액세스 경로
- 전체를 보면서 전략을 수립하기 위해서는 테이블별로 실제 발생하는 액세스 유형을 조사
4) 파티션 구성 기록 필드 - 인덱스 설계 전에 파티션 설계를 먼저 진행하거나 병행해야 제대로된 인덱스 전략 수립 가능하다
