본 포스팅은 메타코드M강의를 참고하여 작성하였습니다.
환경준비하기
1. 가상환경만들기
#diffusion 가상환경을 만들기
conda create -n diffusion python=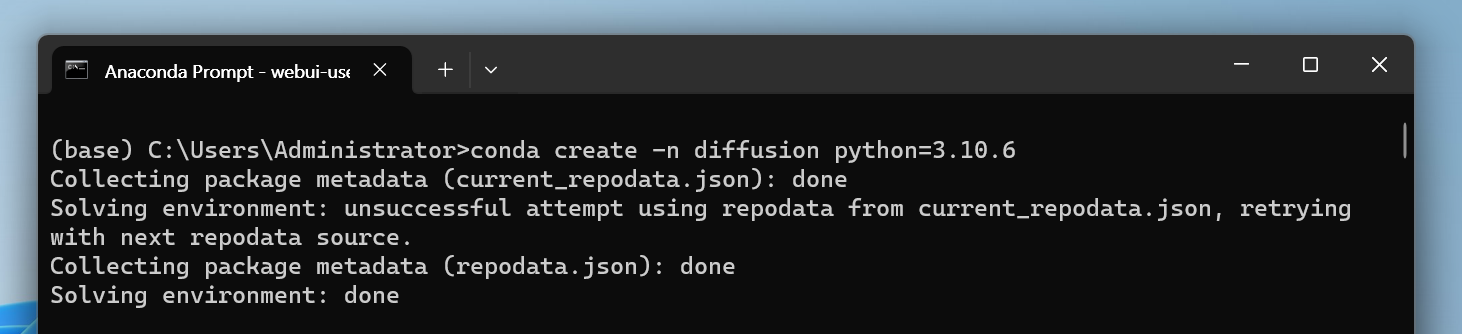
2. git clone 하기 → webui 깃허브 주소
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git3. webui 실행
cd webui-user.bat 4.Torch is not able to use GPU (경고문)
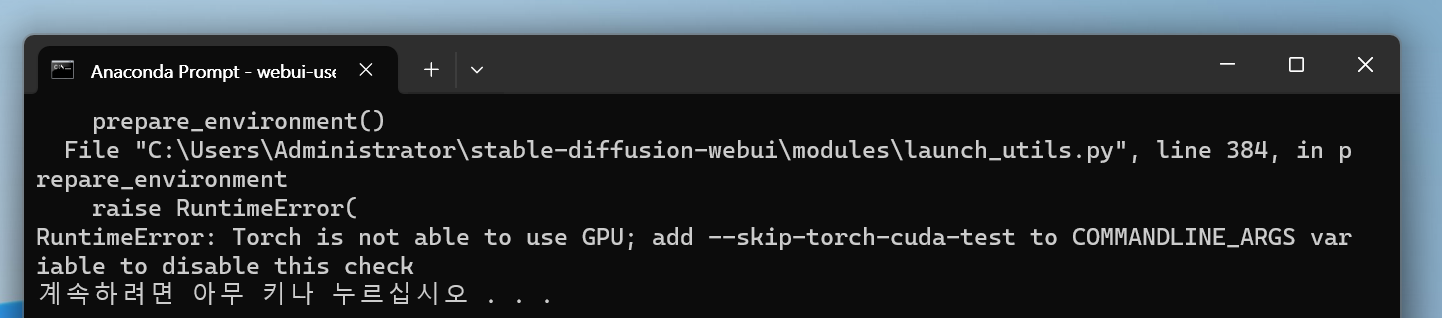
고사양에서 스테이블디퓨전 구동을 위해 NVIDIA 그래픽 카드를 필요로하며 VRAM 4GB 이상의 그래픽카드를 추천한다. 저사양에서도 진행을 하기 위해 COMMANDLINE_ARGS= --lowvram --precision full --no-half --skip-torch-cuda-test 을 추가해주면 된다.

xformers도 같이 가해주는 게 좋을 듯 하다.
5. 설치가 완료되기까지 오랜시간이 걸린다. 완료된 후 Running on local URL에 확인된 주소를 웹 브라우저로 접속해주면 된다.

접속하게 되면 이런 화면이 뜨는 것을 볼 수 있다.
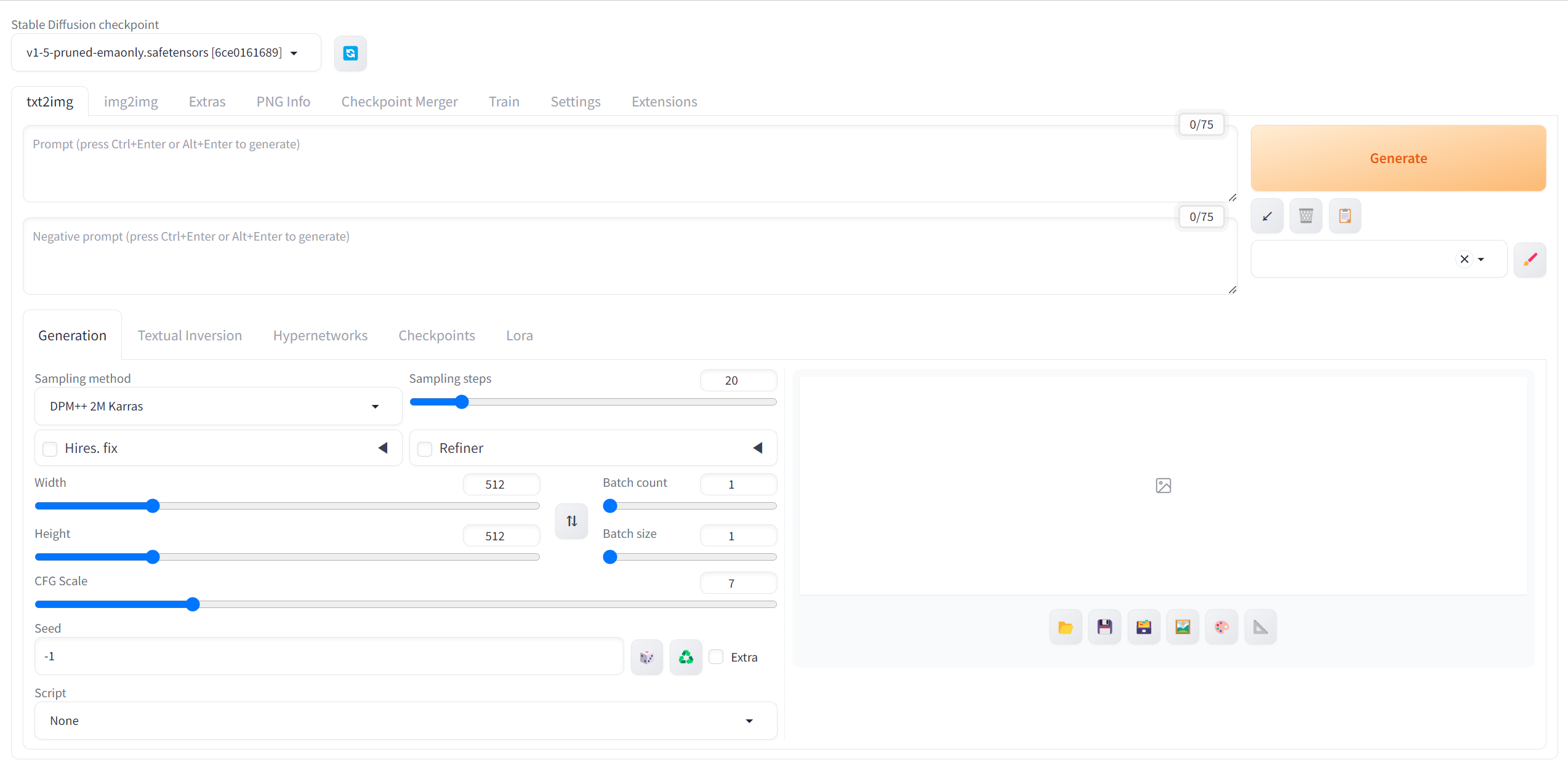
사실 위의 방식으로 강의가 진행되긴 하지만, 실행해본 결과 저사양인 경우 이미지가 생성되는데 꽤 오랜시간이 걸린다. 따라서 나는 Colab에서 진행했다.
Stable Diffusion 내 설정 설명
- checkpoint :
우리가 사용하고자 하는 가중치 개념
내가 뽑고자 하는 이미지의 성격에 따라서 checkpoint를 설정해주면 된다.
- negative prompt : 이렇게 표현된 이미지는 생성하지 말라는 설정
예) bad , ugly 등등
-
sampling method : 샘플링을 어떤 방식을 통해 할 것인가,즉 노이즈를 제거하는 방법이다. 이미지 생성 속도와 디테일에서 차이가 발생한다.
-
sampling steps(이미지를 만드는 과정) => 얼마나 반복할 것이냐 (보통 20~30으로 설정)
높을수록 선명하고 디테일한 이미지가 나오지만, 많이 반복한다고 이미지가 무조건 좋아지는 건 아님
- width , heght : 이미지 크기 설정
만일 1024 x 1024 크기의 이미지를 만들고 싶다면?
-
Hires.fix : 초해상도 적용
- upscale by : 초해상도 비율
- width = 512 , height = 512, upscale by = 2 로 설정할 경우, width 와 height의 2배의 크기의 사진이 출력된다.
- Upscaler : 어떤 방식으로 초해상도를 할건지 정의
- Hires steps: 초해상도 이미지에 대한 스텝
-
Denoisiong strength : 얼마나 변화를 줄 것인가? (default = 0.7)
-
얼마나 강도를 높여서 노이즈를 제거할 것인가? → 높을수록 시간이 오래걸림
-
Refiner : 베이스 모델과 프롬프트 이해도가 높은 모델을 함께 사용
- Switch at : Refiner 모델의 비율
-
Batch count : 몇 번 반복해서 뽑을 것인지 정의
-
Batch size : 한 번에 몇개를 뽑을 건지 정의
-
CFG Scale : 높을수록 prompt를 따르려고 함, 낮을수록 prompt 와 연관성이 떨어지지만 품질은 향상됨. (prompt 가 많을수록 복잡한 연산을 하기 때문이다.)
(얼마나 면밀하게 prompt를 따를 것인가) -
Script :
- prompt matrix : | 로 구분하여 프롬프트 내에서 이미지를 조합
- x/y/z plot : 여러가지 조합을 custom하여 출력
-
seed : 랜덤시드를 고정하는 역할 ( 출력할 때 마다 같은 이미지가 출력되게 함 )
* 마치 창고 속에 맞는 열쇠를 찾아간다(명언입니다,,)🤓
Civitai를 활용한 모델/프롬프트 탐색
* 핸드폰 케이스 만들어보기
* 실제 기업에서 활용되는 생성 AI 활용 방안들
* 나의 AI 프로필 만들기 Rev Animated 가중치를 활용
강사님 말씀으로는 수많은 이미지가 학습되어 퀄리티가 좋다고 한다. 이 Rev Animated는 3D 화풍 이미지로 나타나는 컨셉이다. 최초에 로딩할 때는 시간이 조금 걸린다고 한다.
즉, 하고 싶은 컨셉에 따라 가중치를 달리하여 출력을 할 수 있는 것이다.
Controlnet
말그대로 이미지를 컨트롤 할 수 있는 것이다. prompt를 하나하나 작성하면서 이미지를 뽑아내기가 쉽지 않다. 이러한 작업을 쉽게 해주는 것이 바로 controlnet이다.
https://github.com/Mikubill/sd-webui-controlnet
openpose란?
사람이 어떤 골격을 취하고 있는 지 뽑아주는 것이다.
Controlnet도 모델이 필요하다. 아래는 현업에서 주로 많이 쓰는 것들이다.
- openpose , segmantation , lineart , softedge , canny , depth
pixel Perfect → "손 안에 꽉 끼는 장갑을 맞추는 것 처럼 너의 이미지에 대해서 controlnet이 따라할 수 있게 만들거야"
control mode → controlnet이랑 prompt랑 얼마나 비율을 적용할지 정의
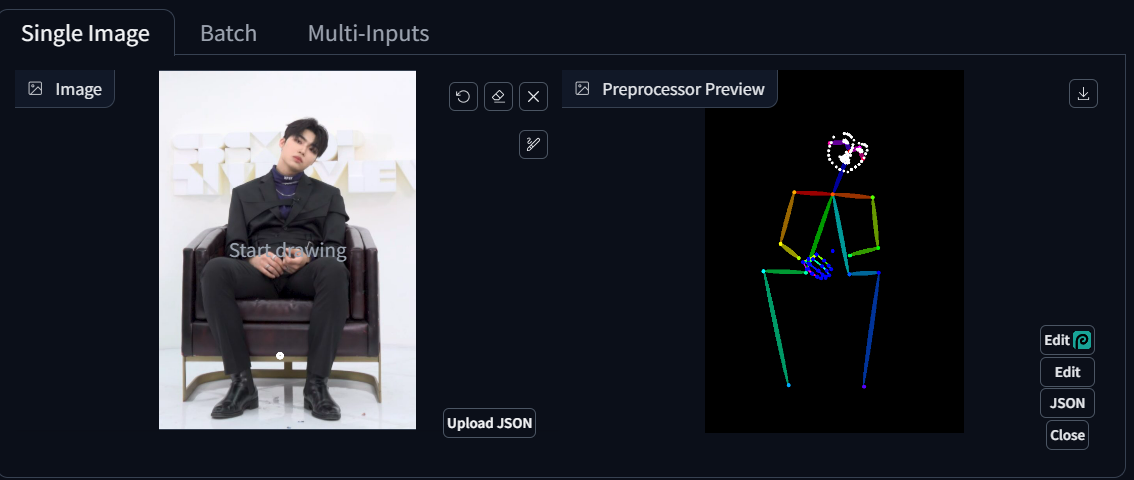
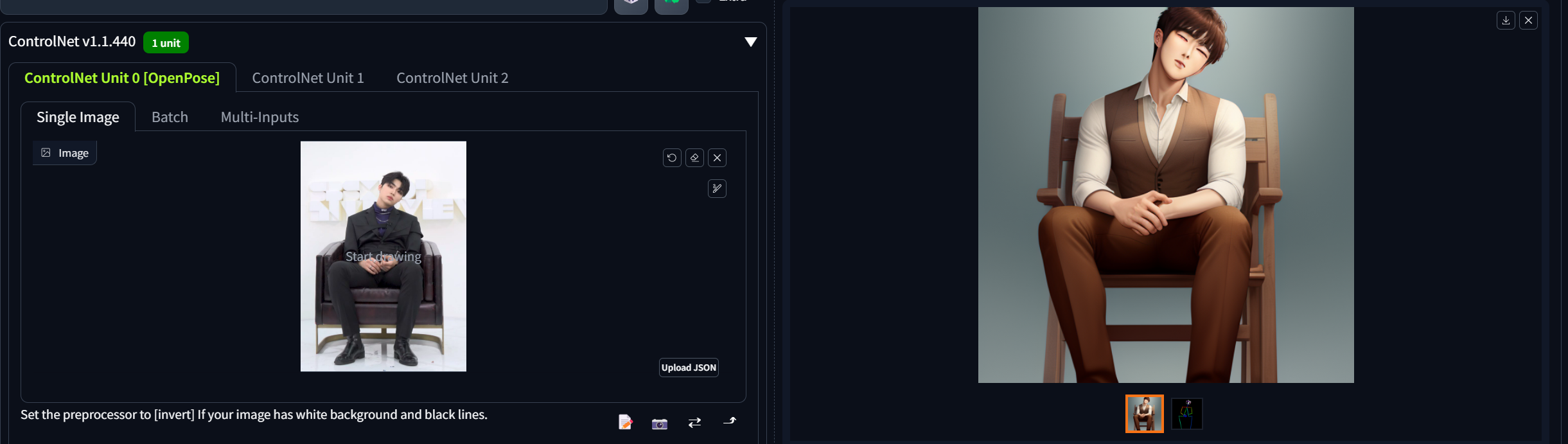
위와 같이 openpose를 활용하여 원하는 포즈의 그림을 뽑아낼 수 있다.
Stable Diffusion Negative Embedding
negative prompt
얼굴이 계속해서 망가지면 face restoration 을 사용하면 된다.
