본 포스팅은 신박AI 를 참고하여 작성한 내용입니다. 복잡한 CNN의 개념을 아주 간단하고 이해하기 쉽게 잘 정리해주셨습니다.
CNN (Convolutional Neural Network)
: 이미지 처리와 패턴 인식에 탁월한 성능을 보여주는 신경망입니다.
Image
픽셀로 이루어진 격자 형태의 데이터입니다.- 각각의 픽셀은
rgb값을 가진 데이터입니다.
CNN은 이러한 이미지 데이터의 공간적 특징을 추출하여 학습하고, 이를 기반으로 패턴을 인식하는데 사용됩니다.
이를 위해 CNN은 다음과 같은 층으로 주로 구성이 됩니다.
① 합성곱 층 (Convolutional layer)
② 풀링 층 (Pooling layer)
③ 밀집 층 (Fully- Connected layer or Dense layer)
1. 합성곱 층
- CNN에서 이미지 처리와 패턴 인식을 위해 주로 사용되는 중요한 구성요소입니다.
- 합성곱 층은 입력 이미지와 작은 크기의 필터(kernel) 간의
합성곱 연산을 통해 새로운 맵(feature map)을 생성합니다. - 이를 통해 이미지의 지역적인 패턴을 감지하고 추출할 수 있습니다.
합성곱 연산이란?
: kernel과 이미지의 각 픽셀별로 곱하여 합산하는 과정을 말합니다.
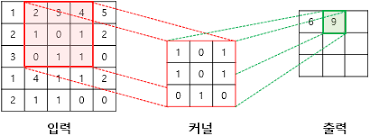
그렇다면 합성곱 연산이 갖는 의미는 무엇인가요?
여러 종류가 있는 kernel이 있다고 가정할 때,
- 1이라는 이미지가 입력값이 될 경우 → 직선 형태의 kernel들의 합성곱 출력 값이 높아질 것입니다.
- 0이라는 이미지가 입력값이 될 경우 → 곡선 형태의 커널들의 합성곱 출력값이 높아질 것이다.
즉, 합성곱의 출력을 일종의 확률 값으로 생각해본다면, 합성곱 레이어의 역할은 이미지의 지역적 특성(feature)을 분석하여 확률로 return 하는 역할을 수행합니다.
따라서 합성곱이 깊어질수록 복잡한 형태의 local feature도 처리할 수 있게 됩니다.
Kernel의 크기와 보폭(stride)
- kernel의 크기와 보폭(stride)는 합성곱 층의 출력층 크기를 조절하는 중요한 요소입니다.
Kernel크기 - kernel의 크기에 따라서 feature map의 크기가 달라집니다.
- 층이 깊어질수록 feature map의 크기가 크면 당연히 복잡한 이미지를 더 잘 분석할 수 있겠지만 , CNN은 연산량이 아주 커지게 됩니다.
* feature map의 크기가 클수록 feature의 디테일을 표현할 수 있습니다. (픽셀 수 ↑)- 따라서 적절한 크기를 찾는 것이 중요합니다.
stride
- 몇칸 씩 kernel을 움직이며 연산을 수행할 것인가에 대해 정의하는 것입니다.
- 만일 stride가 2일 경우는 두칸 씩 움직이며 합성곱연산을 수행합니다.
- 따라서 kernel 크기가 같아도 보폭에 따라 feature map의 크기가 달라질 수 있습니다.
kernel 크기와 보폭은 연산량과 모델의 정확성 사이에서 balance를 맞추어 설정해주면 되겠습니다.
padding
- Filter와 stride의 작용으로 feature map이 계속적으로 작아지는 것을 방지하기 위해 적용합니다.
- Filter 적용 전, 보존하려는 Feature map 크기에 맞게 Feature 좌우 끝과 상하 끝에 각각 열과 행을 추가한 뒤 0값을 채워 사이즈를 증가시킵니다.
- 모서리 주변의 Conv 연산 횟수가 증가되어 모서리 주변 feature들의 특징을 강화하는 장점이 있습니다.
- Keras에서 conv2D() 매개변수로 padding = 'same'을 넣어주면, Conv 연산 시 자동으로 입력 Feature map의 크기를 출력 Feature map 에서 유지할 수 있게 padding 면적을 계산하여 작용합니다.

활성화 함수 (Activation fuction)
- 합성곱 층은 활성화 함수를 사용하여 비선형성을 도입합니다.
- 대표적으로는 ReLu함수가 있습니다.
- 활성화 함수는 합성곱 층의 출력에 적용되어 비선형성을 추가하고 모델이 복잡한 패턴을 학습할 수 있게 합니다.
2. 풀링 층 (Pooling layer)
- 풀링 층은 합성곱 층에서 추출된 feature map의 크기를 줄이는 역할을 합니다.
- 아까 살펴봤듯이, feature map의 크기가 클 경우 복잡한 이미지를 처리할 수 있겠지만, 연산량이 급증하는 것이 문제가 됩니다.

- 최대 풀링 층 → 주어진 풀링 윈도우 내의 값 중 최대 값을 리턴합니다.
- 평균 풀링 층 → 주어진 풀링 윈도우 내의 값 중 평균 값을 리턴합니다.
- 최대 풀링의 경우 보다 Sharp 한 feature 값을 추출하고 평균 풀링의 경우 보다 smooth한 feature 값을 추출합니다.
- 일반적으로 sharp한 feature 가 보다 Classification에 유리하여 최대 풀링이 더 많이 사용됩니다.
- 보통은 pool 사이즈와 stride 값을 같게 합니다.
- 풀링층을 통해 공간적인 크기를 줄이고, 계산비용을 줄이면서 중요한 특징을 추출할 수 있습니다.
3. 밀집 층(Dense layer)
- 추출된 feature 들을 기반으로 최종 출력을 생성하는 역할을 합니다.
- 최종 출력을 생성하기 위해 보통 Fully-connected layer는 CNN 모델의 마지막에 있습니다.
- Fully Connected layer전에 모든 local feature을
1차원으로 만들어주는Flatten에 배치합니다. - 그런 다음 모든 local feature 들과 연결된 fully-connected layer로 출력값을 보내 최종 output을 계산합니다.
Local feature들은 어디까지나 '지역적'확률이기 때문에 최종 확률을 계산하기 위해서는 반드시 전체를 고려해야합니다. 따라서 모든 local feature의 입력을 받는 fully - connected layer가 마지막 단계에서 필요한 것입니다.
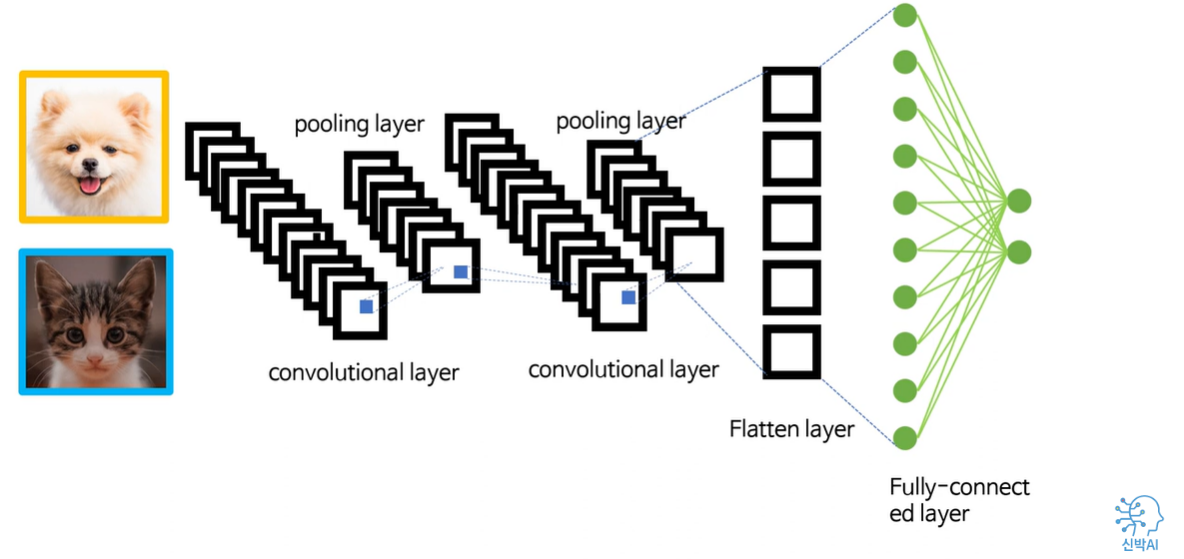
1) 만약, 강아지 이미지가 들어오게 된다면
2) 순전파의 결과 최종 출력값이 (0.7 , 0)이 나왔다고 해봅시다.
3) 오차인 0.3을 줄여나가기 위해서 강아지 이미지의 local feature들과 유사한 모습이 되어가도록 kernel 들의 가중치를 점진적으로 변화 시킵니다.
4) kernel 가중치 변화 알고리즘 → 역전파, 경사하강법 사용합니다.
5) 위와 같은 과정으로 많은 데이터를 통해 반복학습하면 각각의 kernel들은 강아지와 고양이의 local feature들을 잘 구분하는 kernel들로 변화되어 가는 것 입니다.
CNN 모델과 인간의 시각 정보 처리 과정의 유사점
눈을 통해 들어온 시각정보는 시상에 있는 LGN을 거쳐 일차시각 피질인 V1, V2 ,V4, 그리고 IT 지역으로 올라갑니다. 인간의 시각 정보 처리과정은 상위 영역으로 올라갈수록 처리하는 feature의 복잡도가 올라간다고 알려져 있습니다.
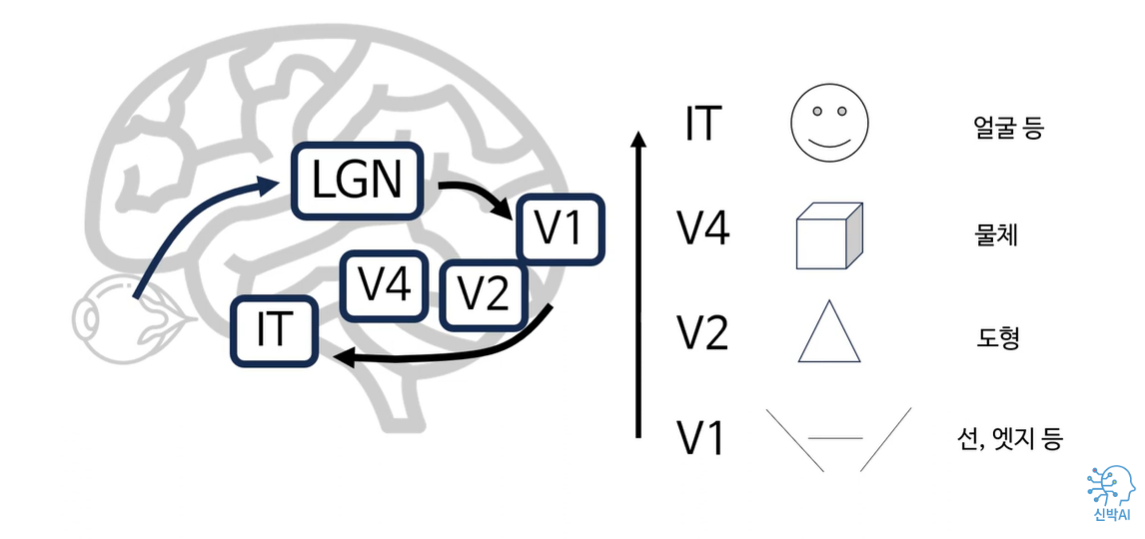
마치 CNN의 합성곱 층이 깊어질수록 복잡한 형태의 feature을 처리하는 특성이 유사한 점이 흥미롭다고 할 수 있을 것입니다.
