🔵 분할정복(Divide and Conquer)이란?
말 그대로 두 단계 분할과 정복으로 나눠서 해결하는 것을 말한다.
재귀 호출과 아주 잘맞는다.
분할하는 단계에서는 주어진 문제를 여러 개의 부분 문제들로 나눈다. -> 문제가 작아질수록 풀기 쉬워지는 성질 이용.
문제의 크기가 엄청나게 줄어든다면(N=1, N=2) 답을 구할 수 있는 수준이 되고, 이는 재귀 호출에서의 기저 사례 (base case)와 같다.
분할 정복 알고리즘의 대략적인 묘사도
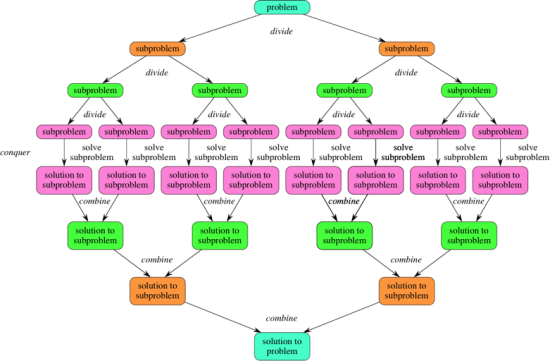
계속 2개의 부분문제들로 나눠가다가 분홍색까지 쪼개졌을 때 그들은 기저 사례가 되어서 바로 풀 수 있고, 푼 뒤 이들을 나눴던 대로 다시 합쳐 나간다.
분할 정복의 대표적인 예
병합 정렬(merge sort), 이분 탐색(binary search), 거듭제곱 연산(a^b)
분할 정복 알고리즘의 수행시간 구하기
병합 정렬의 경우를 예로 들어보자.

필요한 것! ① 나누어지는 문제의 개수, ② 분할 후 문제의 크기, ③ 정복 단계에서 걸리는 시간
-
분할
해당 문제 크기를N이라 할 때 ① 나누어지는 문제의 개수 : 2 , ② 분할 후 문제의 크기 : N/2 , ③ 정복 단계에서 걸리는 시간 : O(N) 이다.
①, ②번은 위 그림의 상황과 일치하고, ③ 정보를 통해 최종 시간복잡도를 구할 수 있다. -
정복 (여기선 병합)
분할을 다 했으니 이제 역순으로 저걸 병합해 나갈 차례! 각 단계의 부분문제의 개수
k-1 단계에서는 2^(k-1)번, ... 2단계에서는 2^2 = 4번, 1단계에서는 2번, 0단계에서는 1번의 병합을 해야 한다. 각 병합에 걸리는 시간은 해당 문제 크기가 N일 때, O(N)이므로
0단계 : 1 O(N)
1단계 : 2 O(N/2)
2단계 : 4 O(N/4)
...
m단계 : 2^m O(N/(2^m)) = O(N)
...
따라서 단계별 식을 일반화해보면 각 단계에서 드는 총합 연산량은 O(N)이다. 그리고, 단계는 총 O(logN)개가 있으므로, 이를 곱해서 시간복잡도를 구해보면 O(NlogN)이라는 결과를 구할 수 있다.
💡 마스터 이론
① 나누어지는 문제의 개수, ② 분할 후 문제의 크기, ③ 정복 단계에서 걸리는 시간이 무엇이냐에 따라 바로 전체 시간복잡도를 구할 수 있는 즉, 분할 정복 기법 시간복잡도의 일반화인 마스터이론을 이해해보자!
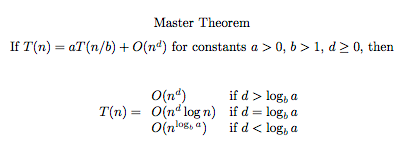
① 나누어지는 문제의 개수, ② 분할 후 문제의 크기, ③ 정복 단계에서 걸리는 시간이 각각 a, b, d와 대응한다.
마스터 이론을 이용하여 시간복잡도 구해보는 연습
이분 탐색 은 별도의 병합과정조차 필요없다. 분할을 하긴 하는데 그 중 한 문제만 풀면 되기 때문. 마스터 이론에 a=1, b=2, d=0을 대입하면 되고, 시간복잡도는 가운데 케이스가 되어 O(logN)이 된다.
