🔵동적계획법, DP란?
프로그래밍이라는 단어는 컴퓨터 언어로 코딩하는 것이 아니라 계획하는 것을 의미하는 바가 크다. 문제를 특수한 형태로 변형시켜 쉽게 풀려는 어떤 과정이다.
다이나믹이라는 단어는 이 기법과 아무런 상관이 없대...ㅋㅋㅋㅋ 만든 사람이 그냥 "이름이 멋있어 보여서 붙였다"고...
하여튼 dp란!?
하나의 문제를 단 한 번만 풀도록 하는 알고리즘이다.
분할 정복은 동일한 문제를 다시 푼다는 단점이 있다. 하지만 dp는 문제를 단 한 번만 풀도록 한다.
⚫ DP 입문에 가장 뻔하고 쉬운 예시 ! 피보나치 수열
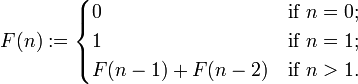
^ 피보나치 수열의 점화식
n<=1 일 때 값이 특정되고, 그보다 클 때는 자신의 바로 전 2개 항의 값으로 결정된다. 이것을 재귀함수로 구현하는 예제 또한 빠지지 않고 등장한다. 이를 단순히 재귀로 구현하면 O(2^N)이라는 쓰레기복잡도가 나온다... 하지만, 이를 dp로 구현한다면? 시간복잡도를 O(N)으로 줄일 수 있다!
◼ 재귀호출로 구하기 (top-down)
가장 먼저 호출하는 문제는 가장 큰 문제이기 때문에 큰 문제부터 방문하기 때문에 탑다운방식이라고 부른다.
#include <iostream>
using namespace std;
int fibonacci(int n){
if(n == 0) return 0;
if(n == 1) return 1;
return fibonacci(n-2) + fibonacci(n-1);
}
int main(){
int N;
cin >> N;
cout << fibonacci(N);
} ⬆ 위 점화식을 재귀함수로 옮긴 것
코드가 굉장히 간편하고, 알아보기 편하다. 그러나 N이 증가하면 증가할수록 실행시간은 기하급수적으로 늘어난다. 호출 횟수가 불필요할 정도로 커진다.
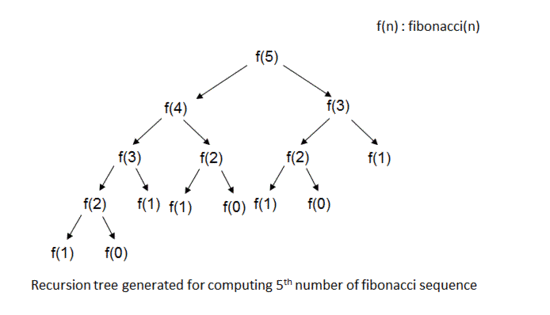
⬆
f(5)의 값을 구하기 위해 f(4)와 f(3)의 값을 알아야 한다.
그런데 f(4)의 값을 구할 때도 f(3)과 f(2)의 값을 알아야 하기 때문에, f(4)를 계산해냈을 시점에서 우리는 이미 f(3)이 뭔지도 계산했다.
그러나, 뒤에 f(3)을 다시 계산할 때 우리가 했던 짓은 다 잊어버리고 다시 계산하고 있다. 너무나도 불필요한 시간낭비죠!?
그럼 어떻게 해야할까?
★ 메모이제이션(memoization) 기법으로 구하기
메모이제이션, 말그대로 메모! 전에 구한 값을 기록해두는 거야. 또 구하지 않게!
#include <iostream>
#include <vector>
using namespace std;
vector<int> dp;
int fibonacci(int n){
if(n == 0) return 0;
if(n == 1) return 1;
// 이미 값을 계산한 적이 있다면 그 값을 바로 리턴
if(dp[n] != -1) return dp[n];
// 아니라면 계산해서 dp 리스트에 넣어 보존
dp[n] = fibonacci(n-2) + fibonacci(n-1);
return dp[n];
}
int main(){
int N;
cin >> N;
dp.resize(N+1, -1); // 초기값 -1은 fibonacci 결과로 절대 나올 수 없는 값
cout << fibonacci(N);피보나치에서 절대 나올 수 없는 대표적인 값인 -1로 dp를 초기화해주고,
if(dp[n] == -1)로 계산 전적을 확인해준다! 계산한 적이 있다면 추가 재귀 호출없이 그 값을 바로 리턴해버린다. 그럼 얘를 또 구하지 않고, 바로바로 쓸 수 있겠죠? 이렇게 되면 한 번 계산했던 값은 두 번 다시 계산할 필요가 없으므로, f(N)을 구하는 데 O(N)의 시간만이 필요합니다!!!
◼ 재귀 호출없이 반복문으로 구하기 (bottom-up)
가장 작은 문제들부터 차례차례 답을 쌓아올려가기 때문에 바텀업방식이라 부른다.
#include <iostream>
#include <vector>
using namespace std;
int main(){
int N;
cin >> N;
vector<int> dp(N+1, 0);
dp[1] = 1;
for(int i=2; i<=N; i++)
dp[i] = dp[i-1] + dp[i-2];
cout << dp[N];
}-> 시간복잡도는? O(N), but 한가지 늘었당. 공간복잡도도 O(N)임. <메모리 안쓰는 법 있어요! 추후에 나옴.>
자 그래서 dp는 뭔데여??
⚫ DP
정의 : 주어진 문제를 여러 개의 부분문제들로 나누어 푼 다음, 그 결과들로 주어진 문제를 푼다.
오 분할 정복이랑 비슷한데? 분할정복과 dp의 결정적인 차이점은
분할 정복은 문제를 분할했을 때 겹치는 문제가 발생하지 않지만, DP는 겹치는 문제가 발생하기 때문에 메모이제이션 등이 필요하다!!!
디피 ≠ 메모이제이션이긴 하지만 둘은 연관성이 깊다.
모든 경우를 메모리를 소비해가며 샅샅이 뒤진다는 점에서 실행시간이 그리디보다 떨어지지만, 그리디보다 좀 더 폭넓은 범위에서 근사치가 아닌 정확한 값을 얻을 수 있다.
위의 피보나치 문제의 경우, f(N)을 구하기 위해 풀어야 하는 부분 문제가 f(N-1)과 f(N-2)인 셈. Base case인 문제들부터 차근차근 풀어 나가며 원래 풀려던 문제의 답까지 계산해가는 것이다.
또한 f(N)을 구할 때 풀어야 하는 문제의 개수는 O(N)개이고, 따라서 이 답을 모두 저장할 O(N)의 메모리가 필요하며, 각각의 문제를 푸는 데 걸리는 시간이 O(1)이므로 O(N)개의 문제를 푸는 데 O(N)의 시간이 든다.
재귀 호출을 사용하는 방법을 탑다운(top-down) 방식이라고 부르며, 가장 먼저 호출하는 문제는 가장 큰 문제이기 때문에 큰 문제부터 방문하기 때문에 이런 명칭이 붙었고,
반복문을 사용하는 방법을 바텀업(bottom-up) 방식이라고 부르며, 가장 작은 문제들부터 차례차례 답을 쌓아올려가기 때문에 이렇게 불린다.
각 방식의 장점은
탑다운방식은 가독성이 좋고, 본래 점화식을 이해하기 쉽다는 점이며 /
바텀업방식은 함수를 별개로 부르지 않아 시간과 메모리를 소령 더 절약할 수 있다는 점이다.
💙 스터디 예제
◼ ch08
🔘III 1463 1로 만들기 👉 풀이
🔘II 9465 스티커 👉 풀이
🔘I 2294 동전 2 👉 풀이
🔘III 2193 이친수
🔘III 1904 01타일
🔘III 11726 2×n 타일링
🔘III 11727 2×n 타일링 2
🔘III 1699 제곱수의 합
◼ ch09
🟠I 16395 파스칼의 삼각형 👉 풀이
🔘V 15489 파스칼의 삼각형 👉 풀이
🔘II 1890 점프
🔘I 10844 쉬운 계단 수
🔘I 11057 오르막 수
🔘I 11051 이항계수 2
