Multi-GPU 정리
Multi-GPU 사용하기 위해 정리한 글입니다.
퍼렁이님의 "Multi-GPU" 블로그글을 메인으로 참고하였습니다.
https://m.blog.naver.com/jjunsss/222920508815
https://tkayyoo.tistory.com/27
PyTorch를 위한 병렬처리
Distributed Data Parallel(DDP): single-process, single-machine, multi-processing
Data Parallel(DP): multi-thread
용어 정리
multi-thread: 하나의 process를 실행하기 위해, 같은 자원을 활용해 여러개의 실행 단위를 사용하고, 하나의 프로그램을 공유하므로 context-switching이 빠름
multi-process: 여러개의 process를 실행하기 때문에 각각의 자원을 활용하고, 어느 하나가 죽더라도 전체가 죽지는 않음
RAM: 컴퓨터 기본 메모리. 어플리케이션을 실행하는데 필요한 범용 메모리
VRAM: GPU와 함께 작돋하여 화면에서 이미지를 랜더링하는데 필요한 그래픽 데이터를 저장 및 관리
-> RAM은 전체 시스템을 위한 범용 메모리, VRAM은 GPU에만 사용가능. RAM은 다양한 작업을 처리할 수는 있지만 그래픽처리의 경우 VRAM보다 느림. VRAM은 그래픽 데이터 처리에 최적화되어 있고, GPU에 더 빠르게 데이터를 제공함.
1. Data Parallel (DP)
사용방법: nn.DataParalell
- 현재 거의 사용하지 않은 방식
문제점:
- 파이토치의 데이터 병렬화 작업때문에 하나의 GPU에 VRAM이 과하게 사용됨
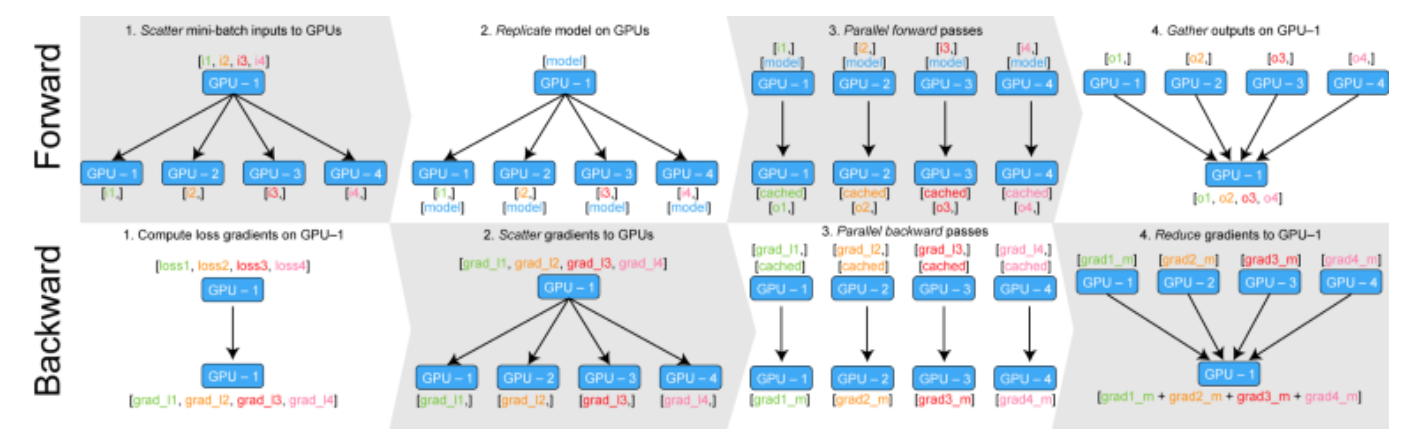
- 하나의 GPU에 데이터들이 모두 모여있다가, 각각의 GPU에 분배되고 연산되고, 그 정보들을 다시 하나의 GPU로 모으고 추합하는 과정을 forward, backward로 수행하면서 VRAM이 하나의 GPU로 모이게 되는 문제가 있음

GPU의 병렬적 사용
GPU를 병렬적으로 사용하기 위해선,
- Replica Model (각각의 GPU에 모델을 할당하는 과정)
- Scatter (각 Iter를 나누는 역할)
- Progress
- Gather (각 GPU에서 출력한 결과들을 하나의 GPU에서 다시 모으는 역할)

-> 하나의 GPU가 과도하게 많이 사용됨으로 PyTorch 공식에서도 권장하지 않음.
참고: https://m.blog.naver.com/jjunsss/222920508815
해결방안
- DP에서 생기는 VRAM 쏠림 현상은 Loss와 Ouput이 하나의 GPU에 모였다가 다시 모든 GPU에 분배되는 과정들이 반복되기 때문에, 이를 해결하기 위해 각각의 GPU에서 Gradient를 계산하고 업데이트까지 하면 됨.
- Main GPU를 다른 GPU ID로 변경해서 적용한다
-> 결국 특정 GPU에 쏠리게 됨으로 해결방안이 안됨 - Loss를 GPU parallel 연산에 분배
-> Loss에 필요한 Target을 모든 GPU로 scatter한 뒤, 각각의 GPU에서 loss계산 후 모델의 훈련을 진행
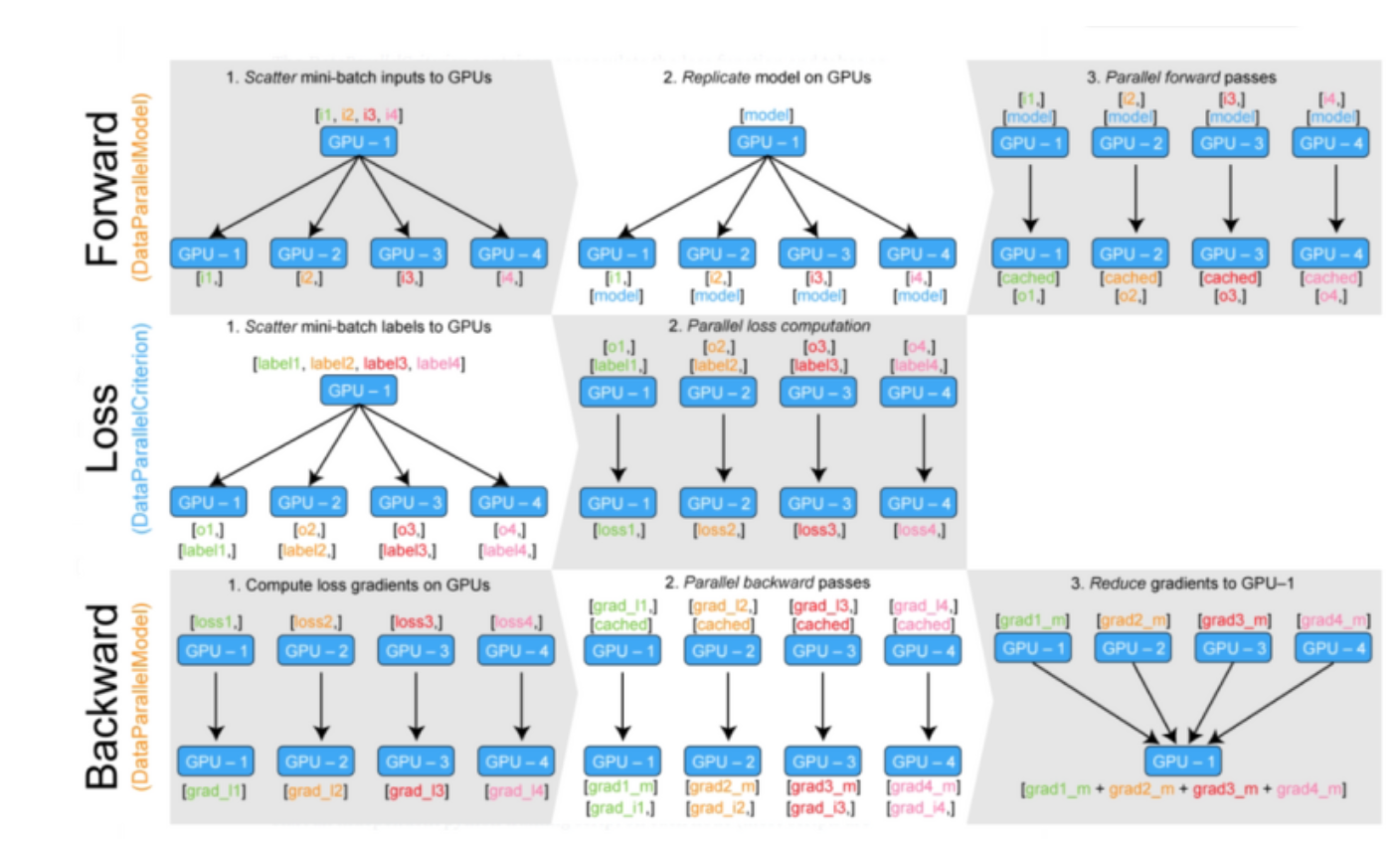
2. Distributed Data Parallel (DDP)
사용방법: nn.DistributedDataParallel (DDP)
torch.nn.parallel.DistributedDataParallel(model,device_ids=[gpu])
용어 정리:
- —nproc_per_node = 4 : 프로세스 할당 (1개의 서버에 GPU가 4개인 경우)
- torch.distributed.launch --nproc_per_node=4로 사용
-> GPU 순서에 상관없이 랜덤으로 할당됨. 이때, 이 수는 내가 사용하고자 하는 GPU 수와 무조건 일치해야함. 필수값임. - node: 컴퓨터의 개수 (한대에 설치된 4개의 gpu 사용시 node=1)
- world_size: (컴퓨터 개수) x (각 컴퓨터에 달린 GPU 개수) = 모델을 훈련하는데 필요한 총 GPU 개수
- torch.distributed.get_world_size : world_size를 얻을 수 있는 코드
- torch.distributed.get_rank() : get_rank()를 통해서 local rank를 얻음
- Local Rank: DDP 코드 내에서 Loss, Model, set_device 등을 프로세서마다 동작시켜줘야하는데 이 때 값을 지정하기 위함. 따라서 코드내에 parser를 사용한다면 parser.add_argument("--local_rank", type=int, default=0)와 같이 무조건 선언해두어야함

문제점:
- 학습에 사용하지 않는 파라미터가 있는 경우 학습을 정지: 훈련중 에러레포팅을 하려고하거나, print를 하려고하면 학습 중간에 정지하면 대부분 이경우, main GPU한대에서만 작동하도록 먼저 돌려보기
- 오류가 많고, 속도면에서 느리기 때문에 요즘 모델들은 대부분 사용하지 않음
- 메모리를 전부 균일하게 사용하지만, launch 등장 후 잘 사용하지 않음
3. DDP launch
DP with torch.distributed.launch ( torch 버전 1.10 미만 )
사용 방법: torch.distributed.launch
python -m torch.distributed.launch --nproc_per_node 4 multigpu.py
용어 정리:
- single node의 경우, master_addr, port등은 필요하지 않음
- python -m은 torch.distributed.launch를 실행시키기 위해 필수적인 요소
- node_rank: 컴퓨터(서버)가 여러 대일 때 컴퓨터별(서버) 노드를 지정해주는 것
- master_addr: 하나의 호스트에서 모든 결과를 취합해야하는데, TCP를 사용해서 지정하는 경우, master_addr 주소를 지정해야함
- gpus_per_node: 하나의 node에 실행할 프로세서를 지정하는 변수. 만약에 총 4대의 GPU가 있는데 3만 사용할 경우, CUDA_VISIBLE_DEVICES로 GPU id 3개를 지정하고, gpus_per_node도 3으로 지정해주어야함
주의할 점:
- —nproc_per_node : 각 node에 돌아가는 gpu를 설정. CUI환경에서 launch를 할당할 때 무조건 있어야함.
- python -m torch.distributed.launch : -m 옵션을 무조건 사용해야함. 해당 옵션이없으면 launch가 실행 안됨
- 코드 내부에 —local_rank가 무조건 할당되어 있어야함: 해당 값은 파이선이 불러오는 프로세스 순서에 따라서 자동으로 부여. 코드 내부에 선언이 되어 있고, 적절하게 사용

- DDP할 때, GPU 각각에 고정하기 위해서 torch.cuda.set_device(args.local_rank) 코드 사용
-> 파이토치에서 추천하는 방식은 아니고, 미리 os.environ["CUDA_VISIBLE_DEVICES"] = "0,1,2,3" 과 같이 선언한 다음 torch.device(args.local_rank) 의 형태로 변경하고 각 데이터에 할당 방법을 추천
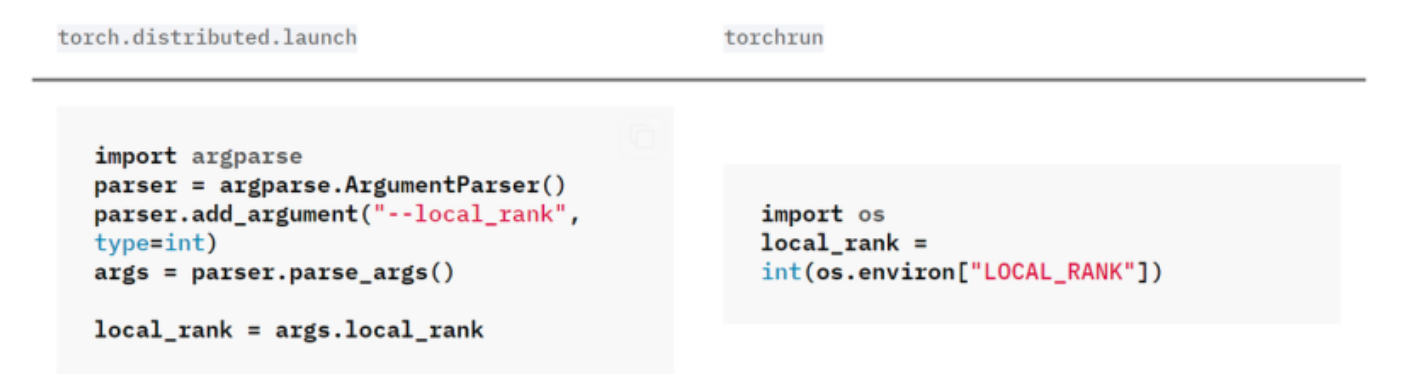
DDP with torchrun ( Torch 버전 1.10 이상 )
사용 방법: torchrun (torch.distributed.launch util이 업데이트된 버전)
CUDA_VISIBLE_DEVICES=0,1,3,4 torchrun --nproc_per_node 4 main.py
주의할 점:
- 이전처럼 local_rank를 args로 사람이 선언하는 것이 아니라 os를 통해 받아오는 것이 다르다!! (local_rank parser를 강제로 만들 필요가 없어짐.)

참고: https://m.blog.naver.com/jjunsss/222920569248
4. DDP 응용
Augmentation GPU마다 다르게 적용하기
- 위에서 각 GPU가 멀티프로세스로 동작한다는 것을 확인했고, 이를 활용하여 GPU마다 다른 augmentation을 적용해서 모델 훈련에 사용할 수 있음
- GPU마다 다른 augmentation 기법이 적용되어 학습되므로 더 robust한 모델을 생성할 수 있도록 기대함
