[논문 리뷰] Vision Transformers Need Registers
이 글은 ICLR 2024에 게재된 "Vision Transformer Need Registers"을 리뷰하기 위해 작성한 글입니다.
Abstract
- 이 논문에서는 supervised and self-supervised ViT networks의 feature map에서 나타나는 artifacts에 관해 분석함
- ViT의 inference시에 low-informative background areas of images에서 나타나는 이 artifacts는 high-norm tokens때문에 나타난다는 것을 밝힘
- 본 논문에서는 ViT의 input sequence에 additional tokens (registers)을 주어 이를 해결하고자 함
- 이 방법은 supervised, self-supervised 모두에서 효과적인 해결책으로 작용하고 self-supervised visual models의 visual prediction tasks에서 SoTA 갱신함
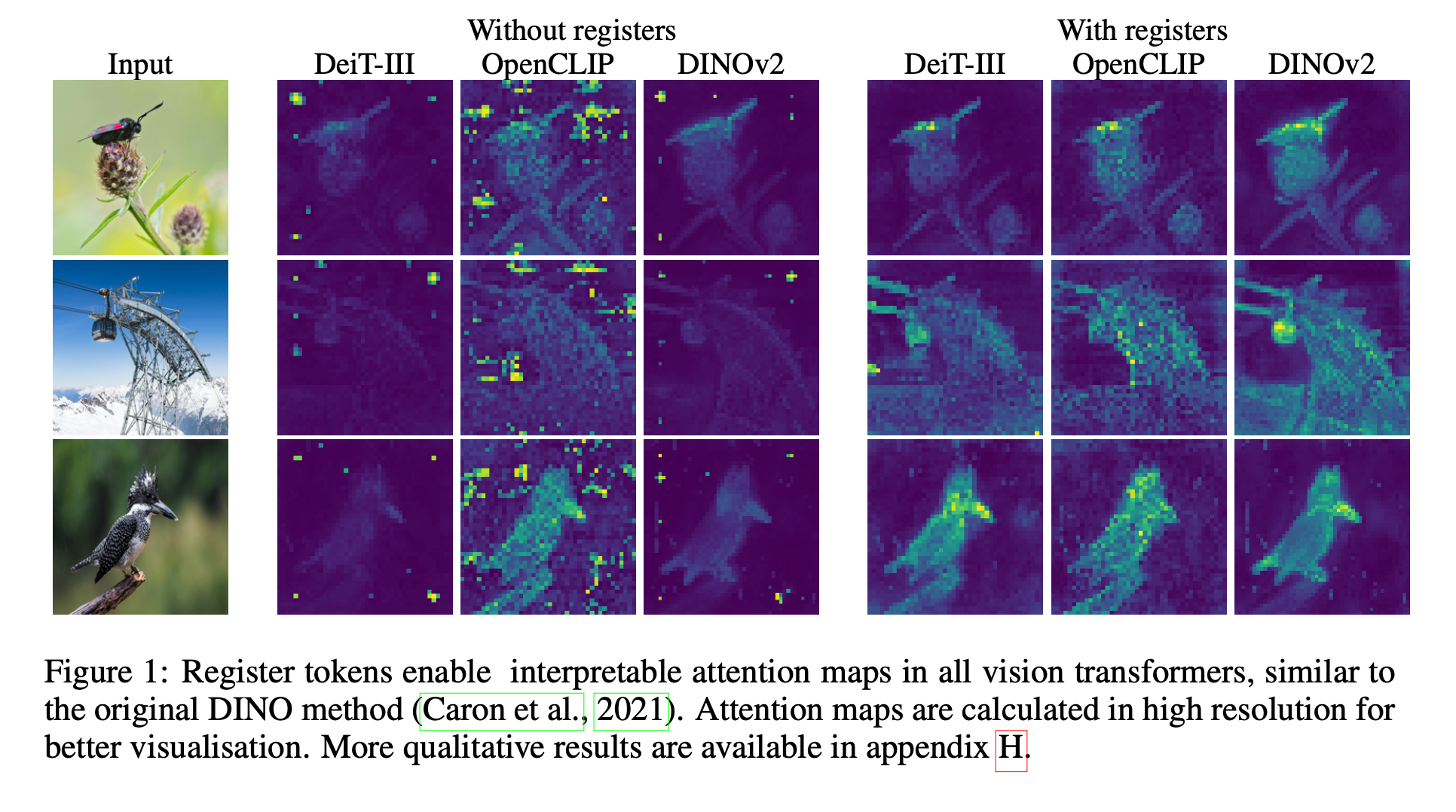
Introduction
1. 이미지에서 generic feature를 잘 뽑는 것은 굉장히 중요하다
- 양질의 데이터셋을 많이 구할 수 없는 현실에서는 가지고 있는 데이터에서 더 좋은 feature를 추출하는 방법이 계속 연구, 제안되어 왔음
- 그 방법에는 supervised - pretrain, self-supervised downstream 등의 방식이 있음

2. DINO 알고리즘이 이미지의 의미적 레이아웃에 대한 명시적인 정보를 포함하는 모델을 생성하는 것으로 나타나면서, 이러한 특성을 이용해서 객체 탐지 알고리즘이 DINO기반으로 구축됨
- 이런 알고리즘들은 supervision없이 attention map에서 정보를 모으는 것만으로 objects detect가 가능함
- 또한 last attention layer가 semantically consistent parts of image and often produces interpretable attention maps
- 위의 이미지에서 DINO는 artifacts가 거의 없고 DINOv2에서는 artifacts가 있음
3. 이 논문에서는 이 artifacts가 나타나는 현상에 대해 고찰하고, 나아가 이 artifacts를 탐지할 수 있는 방법을 제안함
Artifacts??
-
이 artifacts는 tokens이고, 10x higher norm at the output and correspond to a small fraction of the total sequence (2%)
-
이 artifacts는 only appear after a sufficiently long training of a sufficiently big transformer.
-
hold less information about their original position in the image or the original pixels in their patch
-> 모델이 discards local information contained in these patches during inference -
contain global information about the image

Method
- Figure2에서 볼 수 있듯이 거의 모든 ViT의 attention map에서 artifacts가 나타남
- 저자들은 Why and When에 초첨을 맞춰서 이 artifacts를 분석함
1. Artifacts are high-norm outlier tokens.
- Figure3에서 DINO norms과 DINOv2 norms를 비교한 결과, norm of artifacts (yellow)가 명확하게 높은 것을 확인할 수 있음
- !!! 앞으로 저자들은 이 논문에서 "norm higher than 150"를 "high-norm tokens"라고 지칭
- !!! 또한 논문에서 등장하는 "high-norm"과 "outlier"는 interchangeably하게 사용한다고 말함
2. Outliers appear during the training of large models.
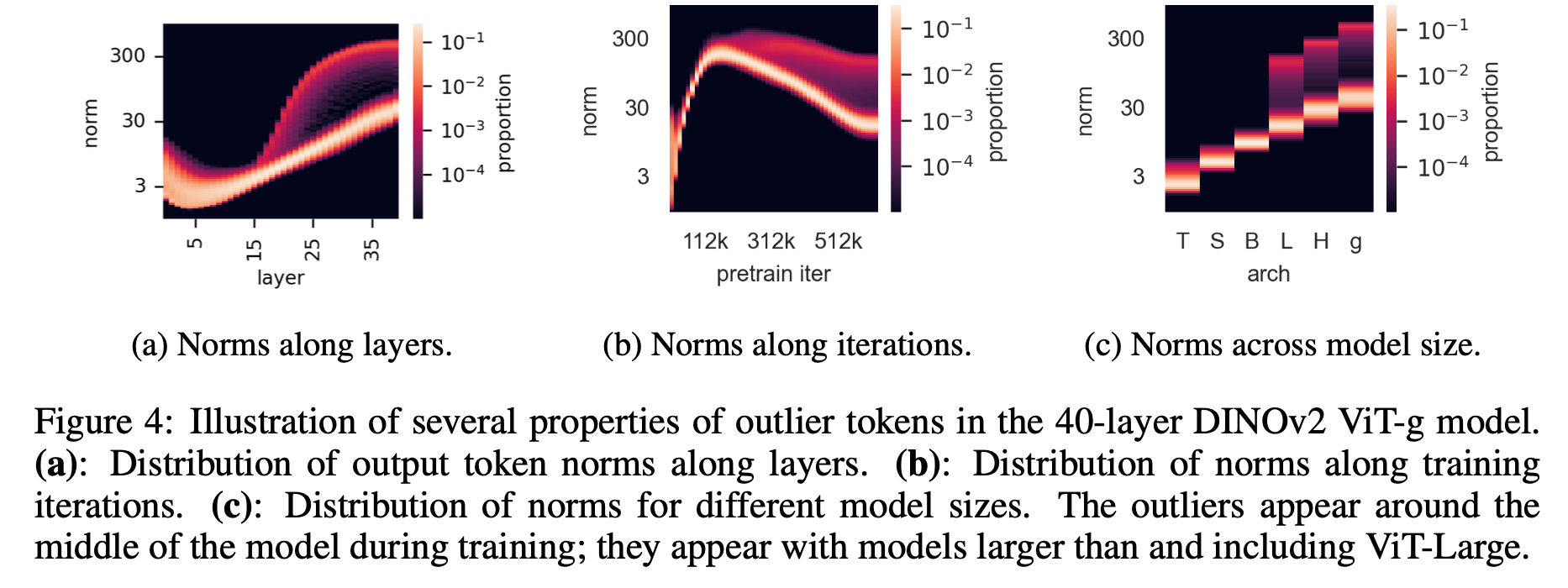
-
(1) Fig4-(a): 저자들은 DINOv2 학습과정에서 이 outlier patches를 분석했는데, 이 high-norm patches는 around layer 15 of 40-layer ViT에서 두드러지기 시작함
-
(2) Fig4-(b): distribution of norms 를 보면, DINOv2 학습 과정에서 outlier가 only appear after one third of training.
-
(3) Fig4-(c): models of different size (Tiny, Small, Base, Large, Huge and giant)에서 오직 three largest models에서만 나타남
3. High-norm tokens appear when patch information is redundant.
-> 이를 확인하기 위해 high-norm token과 그들의 4 neighbors right after the patch embedding layer간의 cosine-similarity를 계산함.
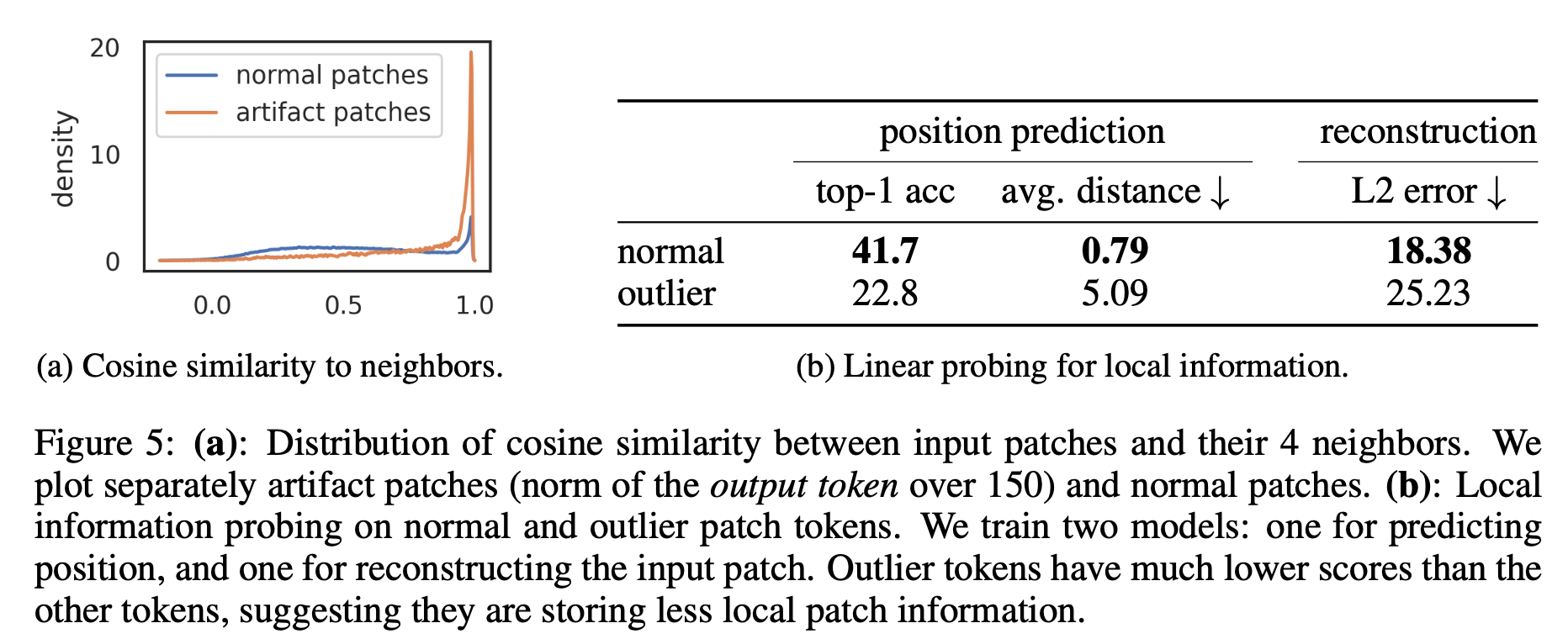
- Fig5-(a): high-norms tokens들은 그들의 neighbors와 굉장히 비슷하게 나타남
-> 이는 즉, 이 patches들이 contain redundant information and that the model could discard their information without hurting the quality of the image representation.
-> 굉장히 중요!!!!!
4. High-norm tokens hold little local information.
-> 이 tokens에 대해 더 자세히 이해하기 위해 이 tokens들을 가지고 실험들을 진행해봄 Fig5-(b)
-
Position prediction: We train a linear model to predict the position of each patch token in the image, and measure its accuracy
- high-norm tokens have much lower accuravy than the other tokens- 이는 이 tokens들이 less information about their position in the images가지고 있다는 것을 의미
-
Pixel reconstruction: We train a linear model to predict the pixel values of the image from the patch embeddings, and measure the accuracy of this model.
- high-norm tokens achieve much lower accuracy than other tokens- 이는 이 tokens들이 less information to reconstruct the image than the others를 가지고 있다는 것을 의미
5. Artifacts hold global information.
-> 이 tokens들이 global information을 얼마나 가지고 있는지는 분석하기 위해 standard image representation learning benchmark에 검증
- classification dataset
- used DINOv2-g and ex- tract the patch embeddings
- choose a single token at random, either high-norm or normal
-> This token is then considered as the image representation - then train a logistic regres- sion classifier to predict the image class from this representation
- measure the accuracy
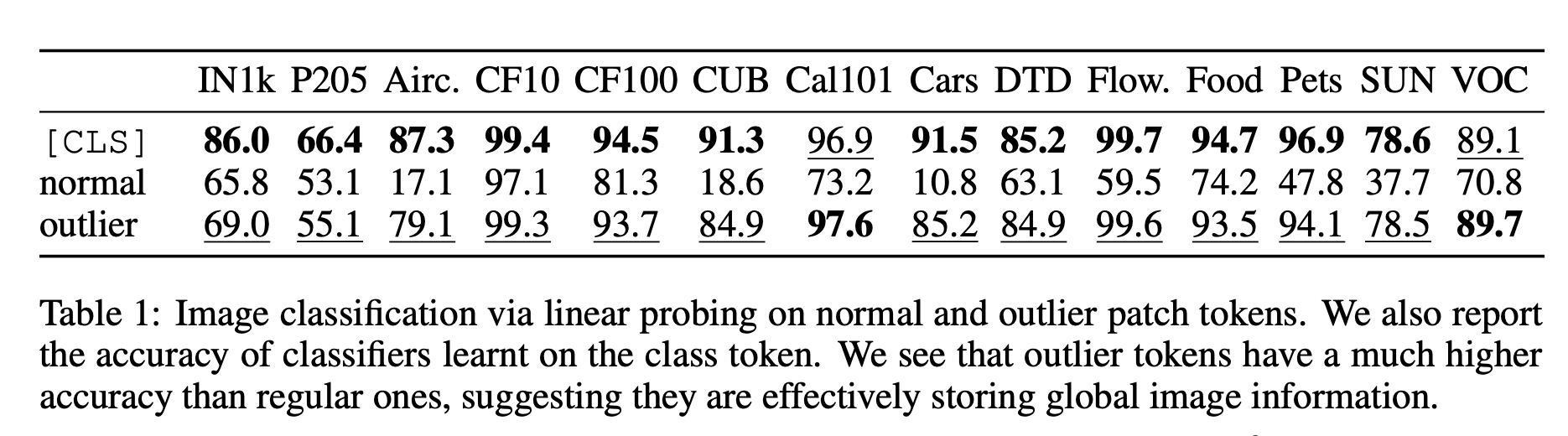
- 실험 결과: the high-norm tokens have a much higher accuracy than the other tokens (Table 1).
-> This suggests that outlier tokens contain more global information than other patch tokens.
*Hypothesis and Remendiation
이러한 관찰을 바탕으로 저자들은 다음과 같은 가정과 결론, 해결책을 냄
Hypothesis: large, sufficiently trained mod- els learn to recognize redundant tokens, and to use them as places to store, process and retrieve global information
-> Indeed, it leads the model to discard local patch information (Tab. 5b), possibly incurring decreased performance on dense prediction tasks
Solution: explicitly add new tokens to the sequence, that the model can learn to use as registers.
-> add these tokens after the patch embedding layer, with a learnable value, similarly to the [CLS] token.
-> At the end of the vision transformer, these tokens are discarded, and the [CLS] token and patch tokens are used as image representations, as usual.
Experiments
-
저자들은 자기들이 주장하는 solution이 굉장히 simple한 구조라서 기존의 모델들 학습과정에 쉽게 적용할 수 있다고 강조함
-
try it on three different state-of-the-art training methods for supervised, text-supervised, and unsupervised learning, shortly described below.
- DEIT-III
- OpenCLIP
- DINOv2
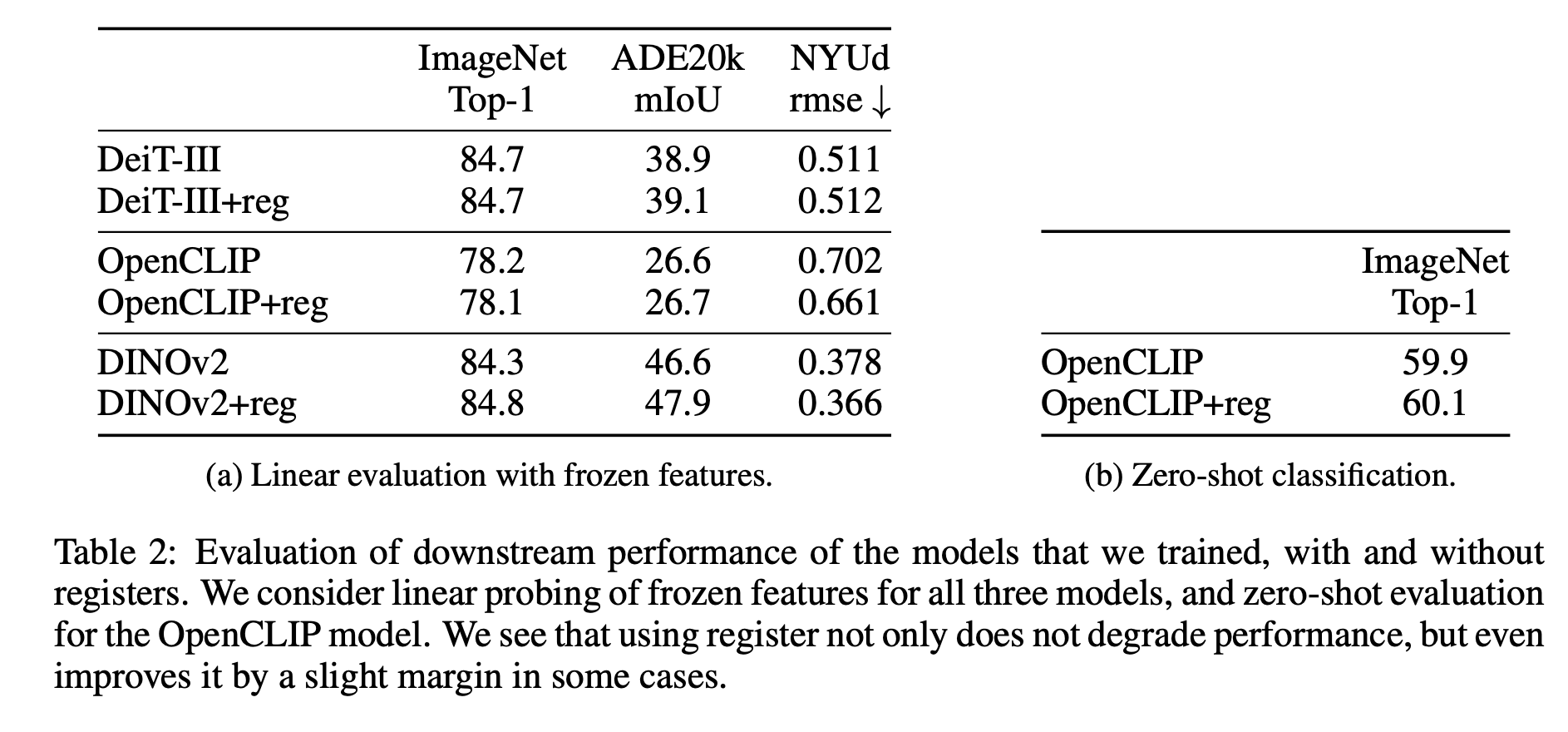
3.2 Evaluation of the proposed solution - Performance regression.
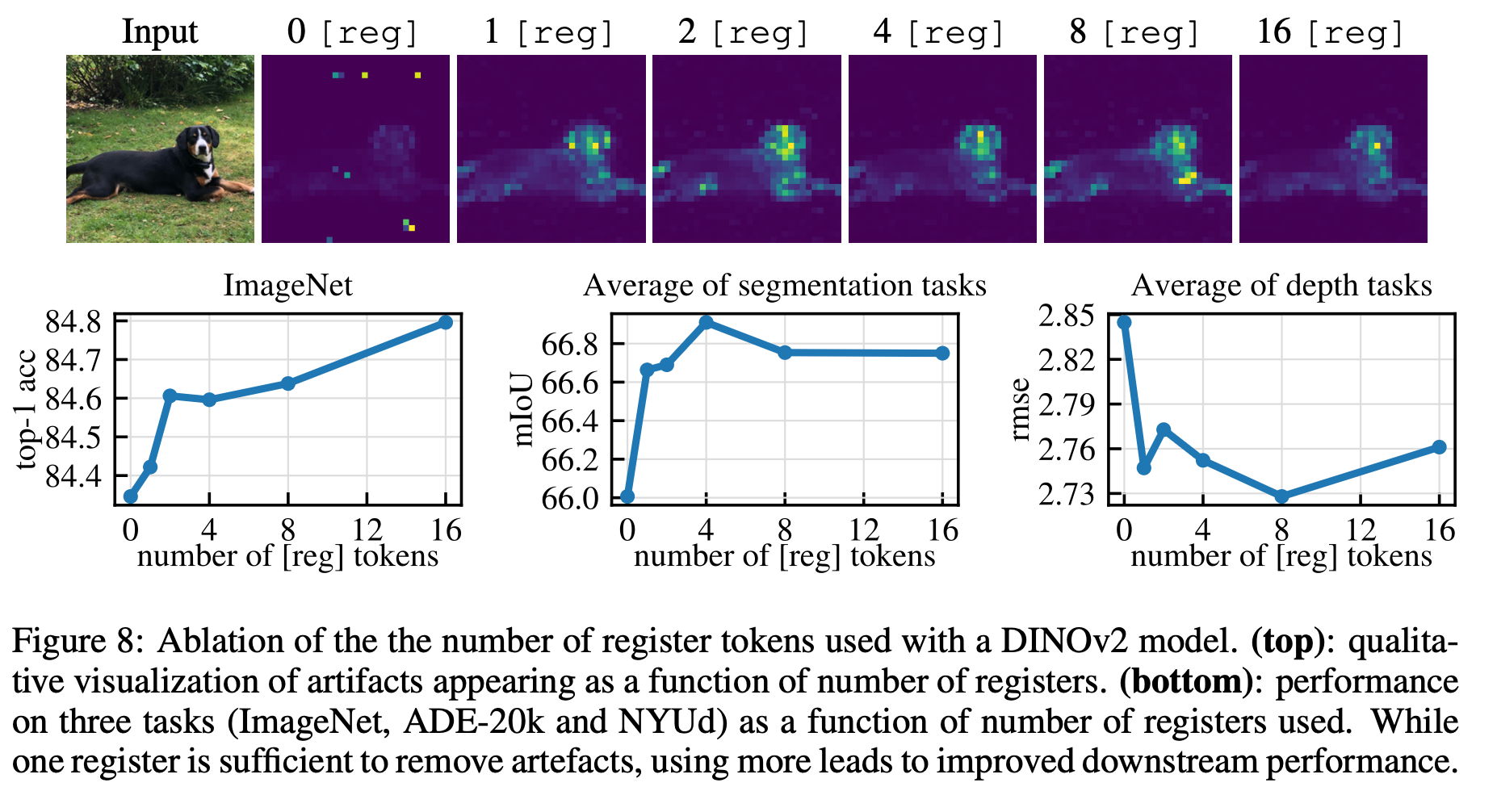
3.2 Evaluation of the proposed solution - Number of register tokens.
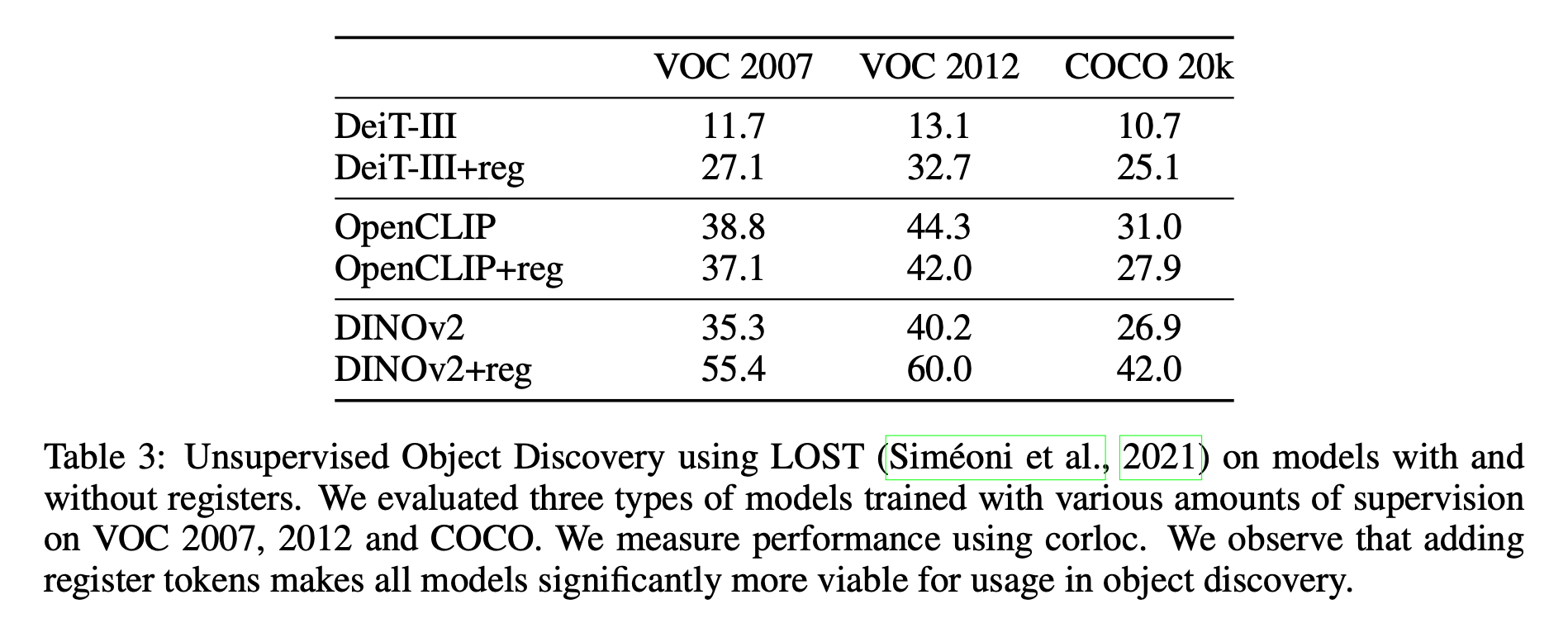
3.3 Object Discovery
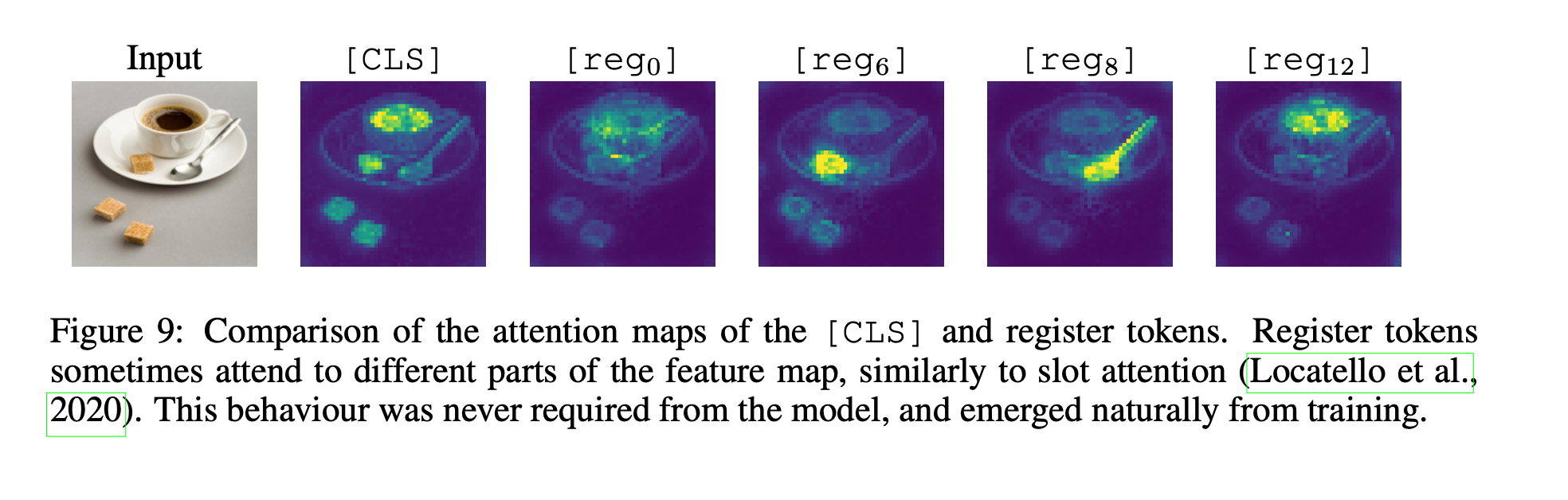
3.4 Qualitative Evaluation of Registers
Conclusion
논문에서 요약
- In this work, we exposed artifacts in the feature maps of DINOv2 models, and found this phe- nomenon to be present in multiple existing popular models.
- We have described a simple method to detect these artifacts by observing that they correspond to tokens with an outlier norm value at the output of the Transformer model.
- Findings: Models naturally recycle tokens from low-informative areas and repurpose them into a different role for inference.
- Following this interpretation, we have proposed a simple fix, consisting of appending additional tokens to the input sequence that are not used as outputs
-> found that this entirely removes the artifacts
-> improving the performance in dense prediction and object discovery.
