[논문 리뷰] Self-supervised Learning from a Multi-view Perspective
들어가기 전에
이 글은 2021년 ICLR에 게재된 "SELF-SUPERVISED LEARNING FROM A MULTI-VIEW PERSPECTIVE" by Yao-Hung Hubert Tsai, Yue Wu, Ruslan Salakhutdinov, and Louis-Philippe Morency 논문 리뷰입니다.
Backgrounds
what is Self-supervised learning?
Supervised learning vs Unsupervised learning: tagged label의 유무
-> Supervised learning은 데이터에 label이 없기 때문에 Data의 특징(representation)에 따라 범주를 묶는 Clustering을 수행

Self-supervised learning(SSL): Label이 없는 untagged data를 기반으로 자기 스스로 학습 데이터에 대한 분류를 수행
1. Introduction
1.1 Problem Statement and Motivation
*Self-Superviesd Learning(SSL): 데이터에 Label이 없을 때, input 데이터와 self supervised signals 사이의 objectives를 학습하기 위해 사용
일반적인 SSL Pipeline
1) Pretext task: unlabeled된 input data의 특징(representation)을 학습한다
= Pre-trained: 대량의 untagged data를 이용해 해당 데이터셋에 대한 전반적인 특징을 학습하는 단계
ex) Bert model
2) Downstream task
= Fine-Tuning
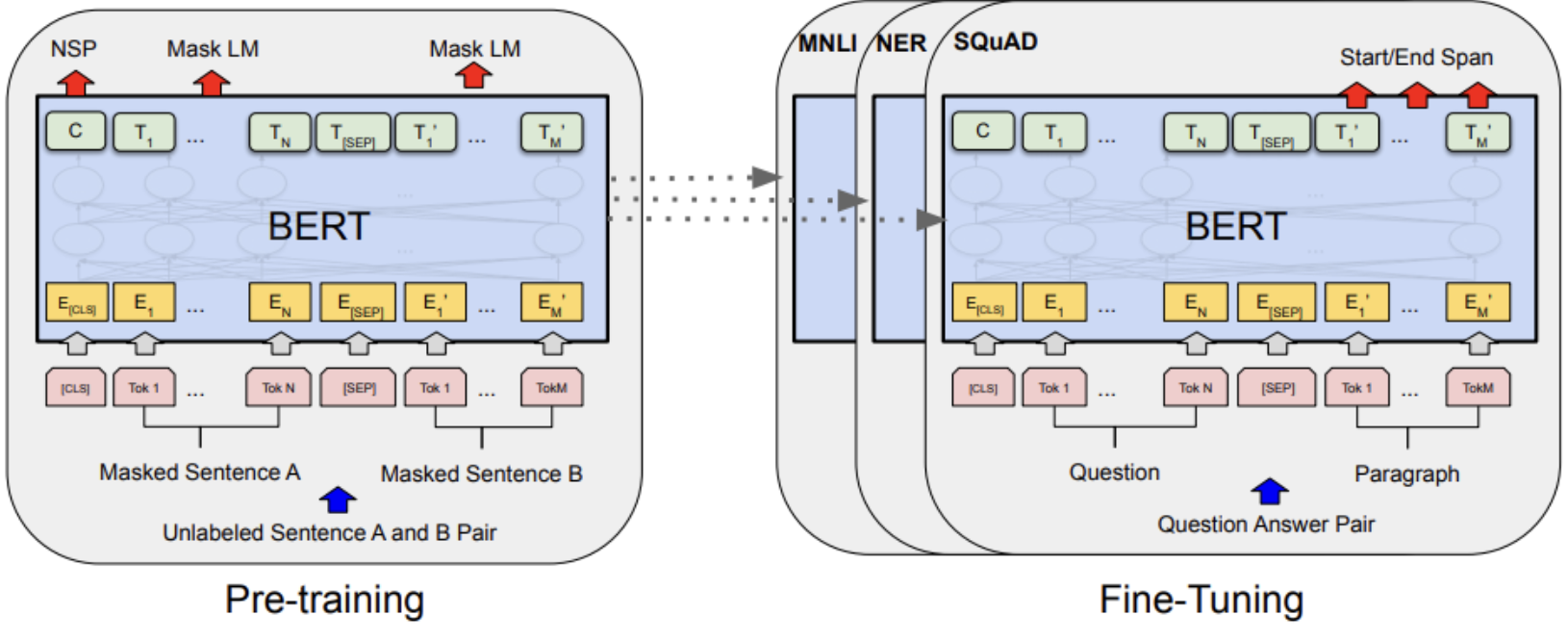
논문의 목표
This paper aims at analyzing why self-supervised learning performs well theoretically and practically.
왜 자기 지도학습이 여러가지 task에서 잘 수행되는지 이론적으로, 실용적으로 분석하는 것을 목표로함.
1.2 Contributions
1) Multi-view assumption: input data and self-supervised signals are two different views of data
2) Each of these two views is sufficient for downstream task
3) Minimal but sufficient learned representation extracts task-relevant information with loss and discard task-irrelevant information with gap
4) Combination of input and self-supervised signals is also discussed
2. Methodology
2.1 Minimal and sufficient representations for self-supervised learning
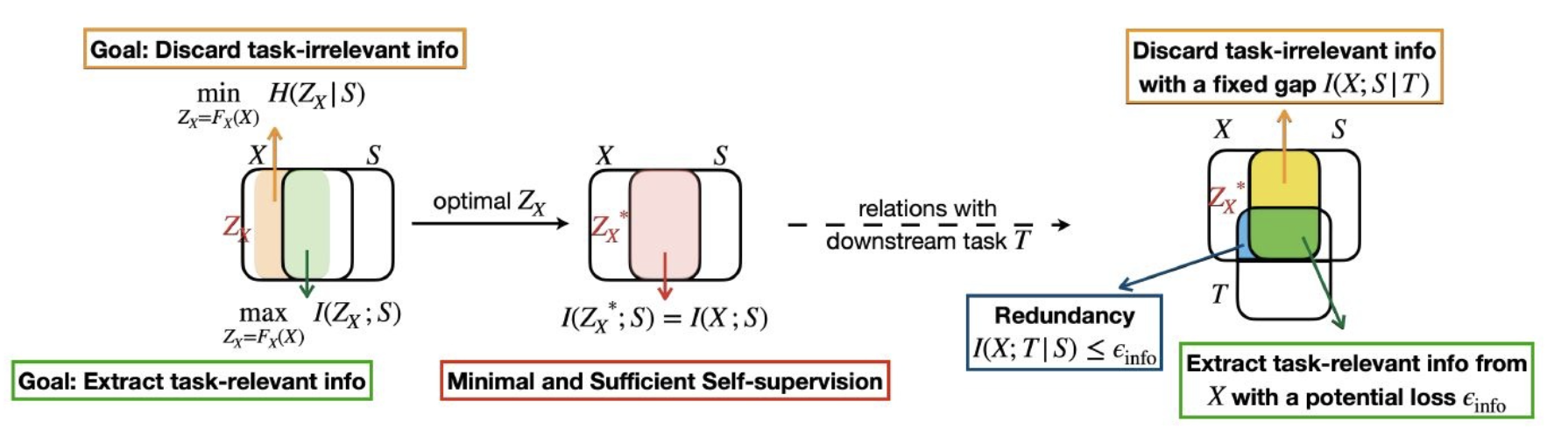
Notations
X = Input
S = Self-supervised Signals
Z = representation
T = Task-relevent information
I(X;Y) = Mutual information of X and Y
H(X) = Entropy
X|Y = conditional X based on Y
작동 원리 정리
1) X는 Input data, S는 Self-supervised signals. 이 둘의 공통 부분은 최대가 되게 하고 다른 부분은 최소가 되게 한다.
2) Optimal Z는 이 둘의 공통 부분이 최대가 되는 부분 = Minimal and Sufficient Self-Supervision.
3) 이후, Down stream task T에 대해서 T와 공통인 부분들은 Task-relevent infomation, 겹치지 않는 부분은 gap이라 부르고 discard한다.
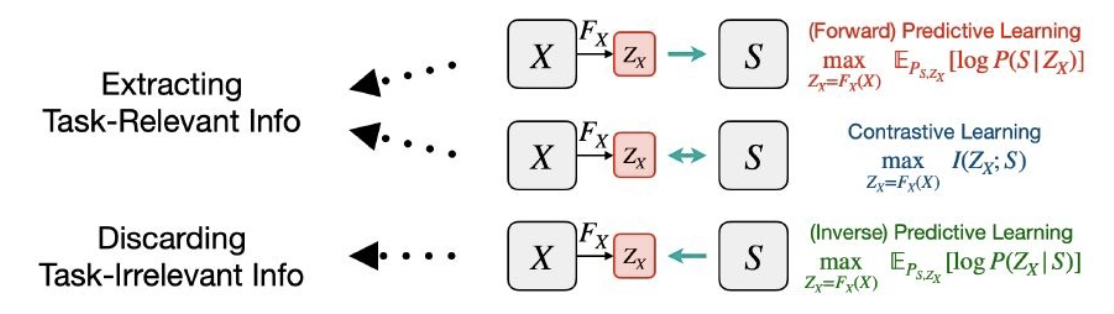
2.2 connections with different learning objectives
*Different Learning Objectives
1) Predicting Learning
Uses cases of 𝑍𝑋 to reconstruct cases of 𝑆
2) Contrasive Learning
To maximize the similarity of X and S, in order to maximize 𝐼(𝑍x;𝑆), which minimizes the 𝜖𝑖𝑛𝑓𝑜 and maximizes the task-relevant information in 𝑍x.
3) Predictive Learning
Uses cases of 𝑆 to reconstruct cases of 𝑍𝑋
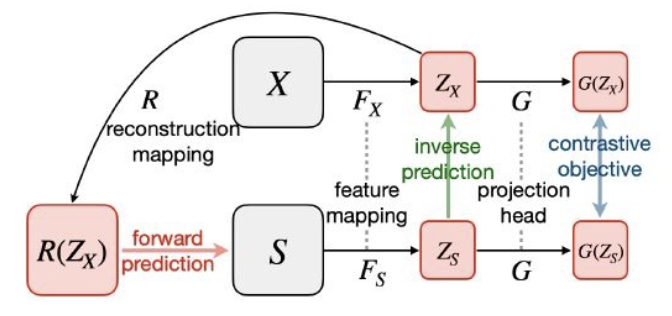
*Composing SSL Objectives
combine the contrastive learning objective 𝐿𝐶𝐿, the forward predictive learning objective 𝐿𝐹𝑃, and the inverse predictive learning objective 𝐿𝐼𝑃, which leads to the composing SSL objective 𝐿𝑆𝑆𝐿.
By adjusting the hyper-parameter,
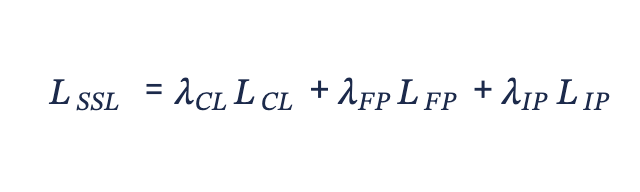
3. Experiments
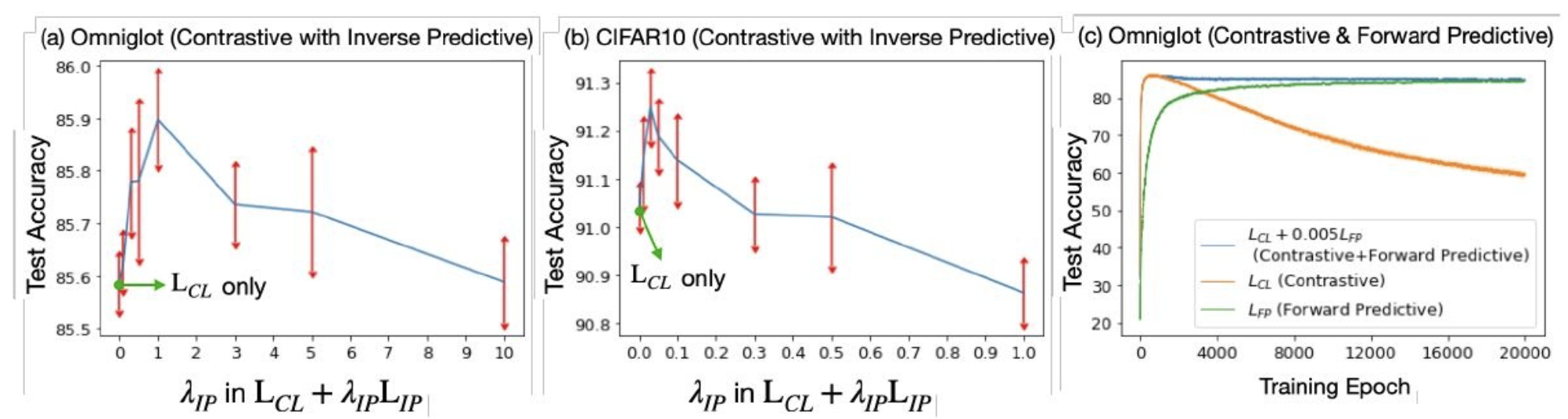
3.1 Experiments 1
𝐿𝐶𝐿 and 𝐿𝐹𝑃, which aim to extract task-relevant information
𝐿𝐼𝑃, which aims to discard task-irrelevant information.
(a) Omniglot dataset
The training dataset includes images from 964 characters, and the test dataset includes images from 659 characters. For each character, it is drawn by 20 people with different styles
(b) CIFAR10
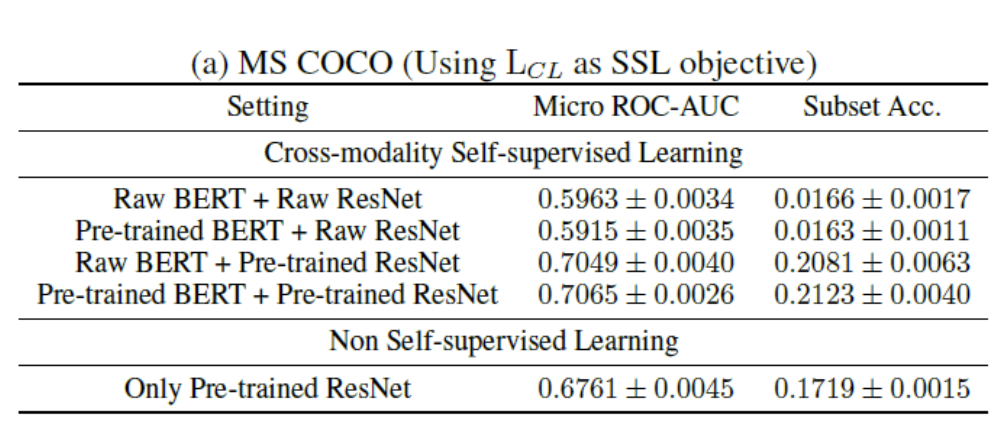
3.2 Experiments 2
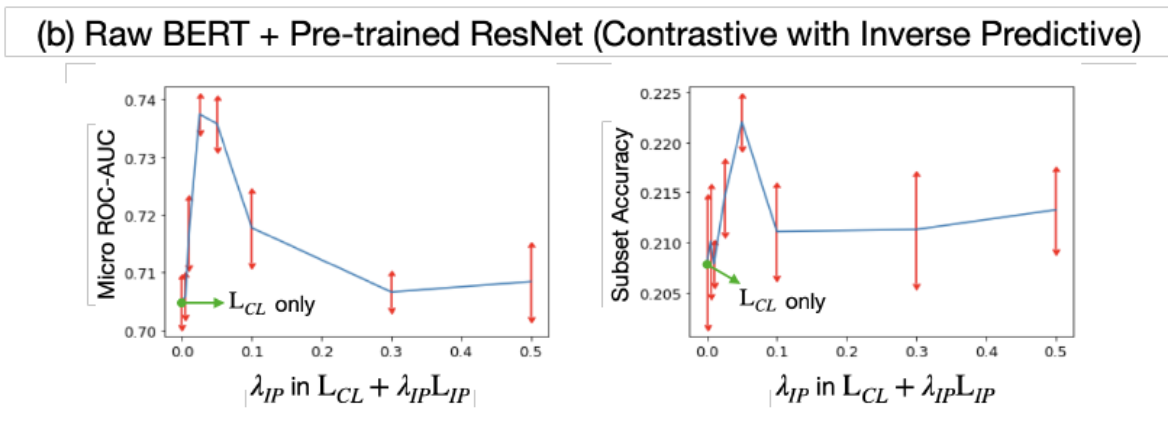
4. Conclusion
1) Multi-view assumption
2) Interaction of Input and self-supervised signals includes enough task-relevent information
3) Can extract and discard information by task-relevent T
5. My Review
개인 정리
Contrastive Learning: aims at extracting task-relevant information
Forward Predictive Learning: aims at extracting task-relevant information
Inverse Predictive Learning: aims at discarding task-irrelevant information
Composing SSL Objectives: aims at extracting task-relevant information and discarding task-irrelevant information (i.e. finding the minimum and sufficient learned representation).
느낌점
1) Interaction of Input and self-supervised signals의 효과와 관계를 좋은 증명과 실험으로 검증하였다는게 이 논문의 의의인 것 같다.
2) 그러나 본 논문에서 제시하는 mathematic formulae of Bayes error rate과 다양한 학습 목표는 복잡하고 이해하기 어려우므로 그 의미에 대한 더 많은 논의와 설명이 제시되어야 한다고 생각한다.
3) 또한 𝐿𝐶𝐿, 𝐿𝐹𝑃, 𝐿𝐼𝑃 조합에 대한 테스트를 더 많이 해봐야 더 나은 구성 SSL objectives를 찾을 수 있을 것 같다.
4) 마지막으로 Input과 Self-supervised signals가 크게 겹치지 않는 데이터셋에 대해서도 잘 작동하는지 실험해보야하 한다.
Code review
https://github.com/yaohungt/Self_Supervised_Learning_Multiview

4개의 댓글

Self-Superviesd Learning(SSL)의 이점과 원리에 대해서 잘 설명해주셔서 좋았습니당 : ) 스터디 끝까지 파이팅임다 !!!!

- self supervised learning의 학습결과와 input data의 학습결과를 어떻게 둘 다 사용할 수 있을까에 대한 흥미로운 발표였습니당
- 직관적인 아이디어임에도 그를 증명하기 위한 수식이 많았다고 하셨는데, 설명을 잘 해주어 이해가 쏙쏙 되었습니당
- 그럼에도 왜 multimodal인지 아직도 오리무중..

안녕하세요 주호님 소개글이 파이팅 넘치네요 ㅎㅎ 논문 잘 읽었습니다 !
- 여러 분야에 적용할 수 있을 것 같은 좋은 아이디어가 담긴 논문이네요 ~
- 아무래도 정보 이론을 바탕으로 해서 수식이 많았을 것 같은데, 간략하고 직관적으로 잘 정리되어 있어서 좋았습니다
많은 활동 기대하겠습니다 ✊✊✊
재미진 설명 감사합니당~~~!!