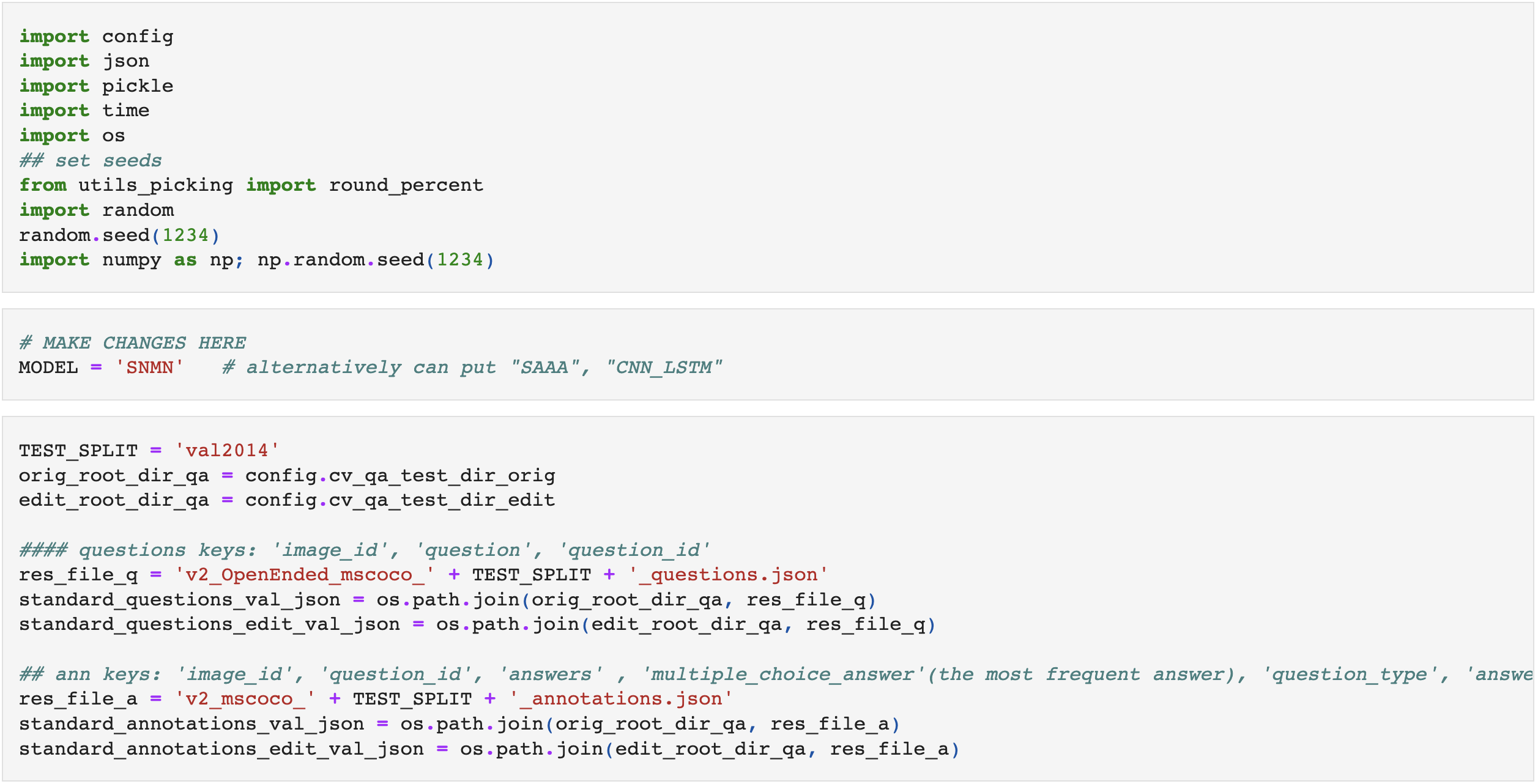
[논문 리뷰] Towards Casual VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing
들어가기 전에
이 글은 2020년 CVPR에 게재된 "Towards Casual VQA: Revealing and Reducing Spurious Correlations by Invariant and Covariant Semantic Editing" 논문 리뷰입니다.
Background: What is VQA?
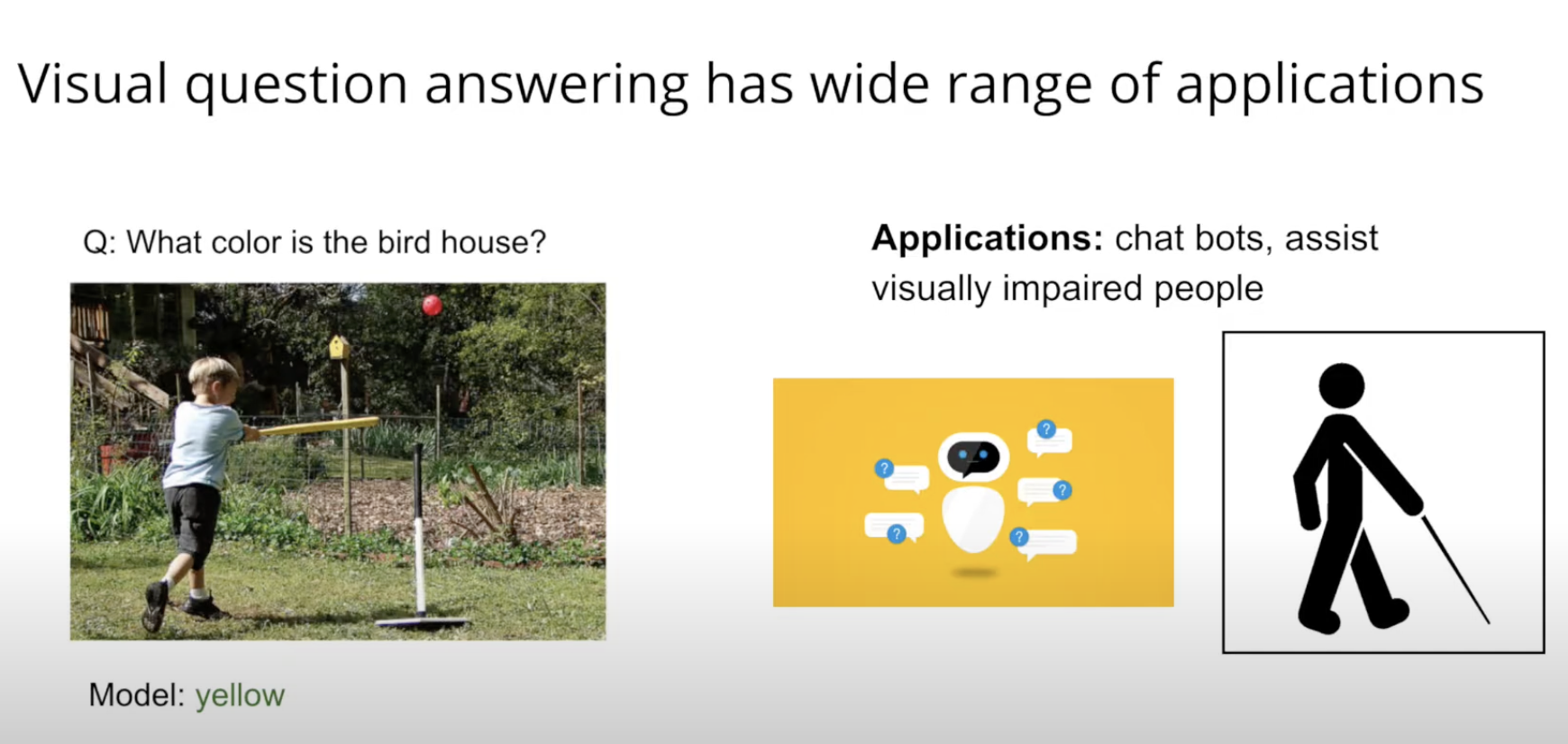
VQA: Visual Question Answering
-> VQA task는 이미지(Visual, 영상으로도 확장 가능)와 그 이미지에 대한 질문(Question)이 주어졌을 때, 해당 질문에 맞는 올바른 답변(Answer)을 만들어내는 task이다.

출처: 논문 VQA: Visual Question Answering
Related work
-
Text-based Q&A: 이 문제는 NLP와 텍스트 처리 분야에서 잘 연구됨. 텍스트 질문에 대한 대답은 VQA 기술과 밀접하게 연관.VQA는 text와 vision 모두에 의존한다.
-
Describing Visual Content: 이미지 태깅, 이미지 캡셔닝, 비디오 캡셔닝 등 VQA와 관련. 그러나 대부분의 캡션 연구는 vision에 특화된 것이 아닌 지나치게 일반적인 (많은 이미지에 대해 동일한 캡션을 써도 말이 되는) 경우가 많음.
-
Other Vision+Language Tasks: 이미지 캡셔닝보다 평가가 쉬운 coreference resolution, generating referring expressions 등의 task가 있다.
출처: CVPR
Introduction
오늘 날의 VQA 모델들은 질문의 변형에 취약하다는 문제점이 있음.
-> 동일한 질문이어도 변형된 질문에 대한 정답을 잘 하지 못함
본 연구에서는
1. VQA모델의 Robustness를 평가하는 방법을 제시
2. VQA Task에 의미론적, 시각적인 변형을 가해 변형된 내용이나, 가짜 질문에 대해 모델이 더 Robust하게 반응하도록 하는 방법을 제시

출처: CVPR
이전 연구들은 VQA모델의 Robustness를 Linquistic variation을 두어서 연구한 연구들이 대부분.

출처: CVPR
1. 학습시에 Answer에 변형을 가하는 연구
Don't Just assume; look and answer: Overcoming priors for Visaul Question Answering, 2018 CVPR
2. 질문에 변형을 가하는 연구
Cycle-consistency for robust visual question answering, 2019 CVPR
Sunny and Dark outside? Improving answer consistency in vqa through entailed question generation, 2019 Arvix
*Main Contributions
-
데이터와 모델의 Bias로 생기는 VQA모델들의 성능을 정량화하는 방법 제안.
-> 자체적으로 만든 synthetic data를 사용하여 이 문제들을 검증하고 새로운 평가 metric을 제안하여 VQA모델의 성능을 평가함 -
Contribute Methodology and a synthetic dataset
-> human study에 기반해서 직접 systematic variations를 가해 synthetic dataset을 생성함.
-> human annotations로 dataset을 validate함 -
실제 3개의 VQA state of art models를 가지고 실험을해보고 성능 향상이 있음을 검증함
-
Adversarial training으로 제안한 synthetic dataset을 가지고 Data augmenation하여 위의 문제들을 해결할 수 있음을 보여줌.
무엇보다도, "First systematic study to visual robustness at scale"
Synthetic Dataset for Variances and Invariances in VQA
Synthtic Dataet
-> Built upon existing VQAv2, MS-COCO datsets
How? removing object by GAN
1. Invariant VQA (IV-VQA)
Editing Where Answer does not change
-> Question에 대한 답변이 변경되지 않도록 변형을 가함



1. Covariant VQA (CV-VQA)
Editing Where Answer change
-> Question에 대한 답변이 변경되도록 변형을 가함



Area-Overlap threshold
- If, GAN으로 지워진 Object가 QA와 관련된 Object라면 어떻게하지?
- 전체 이미지에서 큰 Object는 작은 Object에 비해 GAN으로 지우기가 어렵다.
-> 이미지 왜곡으로까지 이어진다 - Object를 지우고 생성한 새로운 이미지가 이전 이미지에 비해서 quality degrade가 이루어지면 안된다.
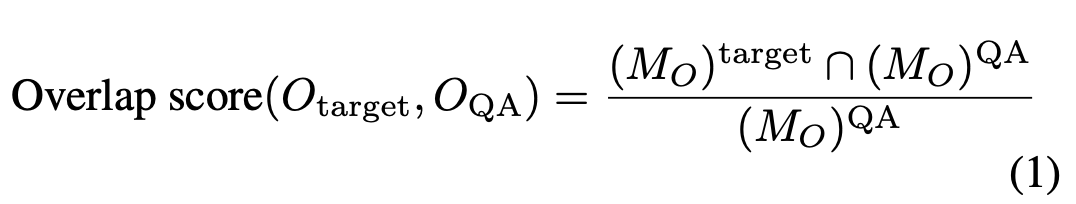
Validation of Three Human
1. 새로 생성된 이미지의 퀄리티 검증
2. 지워진 Object가 QA에서 등장하는지, 혹은 연관되어있는지
3. 모델이 synthetic datasets을 보고 VQA task를 수행하는데 그 결과가 correct for the given image and question (yes/no/ambiguous)
Consistency Analysis
The goal of creating edited datasets
: 모델이 이미지의 의미 변화에 대해 얼마나 일관성이 있는지 측정하는 것.
IV-VQA: QA에 관련이 크게 없는 Object를 제거했기 때문에 모델이 정답을 변경하지 않을거라 가정
CV-VQA: QA에 관련이 있는 Object를 제거했기 때문에 모델이 정답을 변경할 것이라 가정. 이 연구에서는 개수를 물어보고, 하나의 object를 없앴기 때문에 모델의 결과가 1개 작아졌을거라고 예상
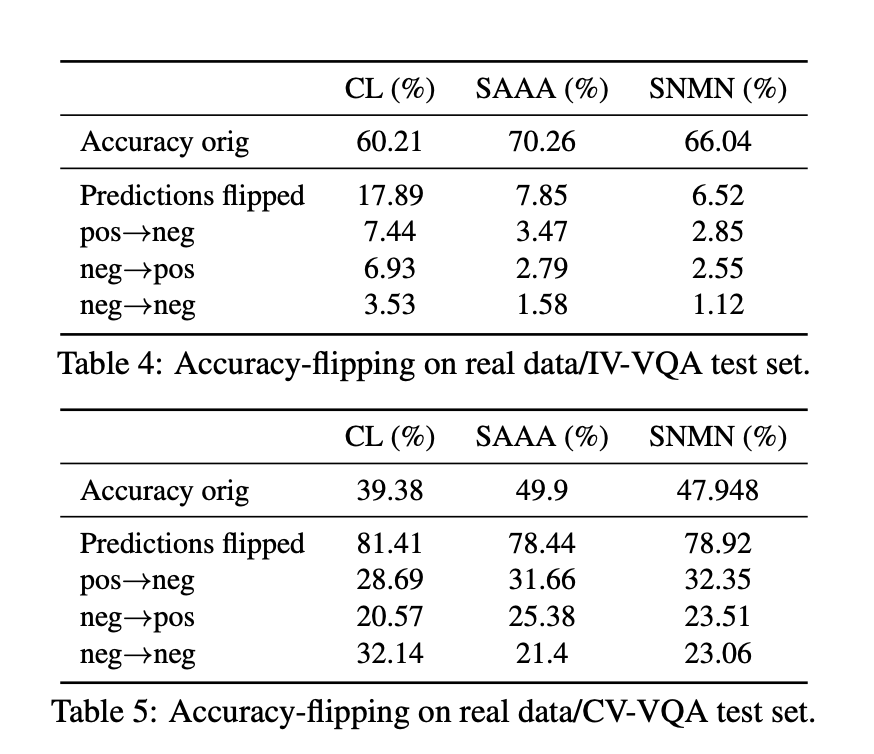
다음으로, 모델의 정확도와 일관성을 평가. 구체적으로, 모델이 변형에 대해서 얼마나 자주 예측 답을 변경하는지를 살펴보고, 이 다양한 변형에 대한 질적 및 양적인 일관성 메트릭을 제안.

Inconsistent behavior on edited data into three categories
1. neg -> pos
2. pos -> neg
3. neg -> neg
가령 1번의 겨웅, answer in real IQA was wrong, but answer in edited was correct
Robustification by Data Augmentation


출처: CVPR 저자 발표내용 일부
Conclusion and Future Works
-
propose a semantic editing based approach to study and quantify the robustness of VQA models to visual variations.
-> Visual 변형을 주어서 VQA models의 robustness를 평가한 첫 연구 -
Our analysis shows that the models are brittle to visual variations and reveals spurious correlation being exploited by the models to predict the correct answer.
-> 기존의 VQA model들은 시각적 변형에 취약하고, 모델만의 잘못된 상관관계에 의존하여 예측을 하고 있다는 것을 밝혀냄 -
Next, we propose a data augmentation based technique to improve models’ performance.
-> 저자들이 만든 synthetic datasets을 가지고 data augmentation을 진행하였더니 모델의 성능과 일관성이 모두 향상하였다. -
Our trained models show significantly less flipping behaviour under invariant and covariant semantic edits, which we believe is an important step towards causal VQA models.
-> Synthetic dataset으로 학습한 모델은 Invariant VAQ와 Covariant VQA에서 모두 답변을 변경하는 정도가 낮았고, 논문의 저자들은 이것이 "Casual VQA"를 향한 단계라고 강조하면서 논문의 제목이 이렇게 됨 -
By making our invariant and covariant VQA sets as well as evaluation and synthesis available to the community, we hope to support research in the direction towards causal VQA models.
-> 이 데이터셋으로 Causal VQA를 향한 다양한 연구들이 나오길 기대한다
Code Review
전체적인 코드
https://github.com/AgarwalVedika/CausalVQA
- flip_accuracy_cal_cv_vqa.ipynb
- flip_accuracy_cal_iv_vqa.ipynb
https://github.com/AgarwalVedika/CausalVQA/blob/master/flip_accuracy_cal_cv_vqa.ipynb
- Object Remover
https://github.com/AgarwalVedika/CausalVQA/blob/master/object_remover.py
개인 견해
장점
-
명확한 동기: 기존의 방식들의 문제점을 제기한 것이 명쾌
-
논문의 흐름이 굉장히 자연스러움
문제 -> 해결 -> 검증 -
논문의 작성이나 구조도 굉장히 논리정연함
-
실험과정과 결과에 대한 자신감이 있어서 그런지 비교 실험을 굉장히 잘했다는 느낌이 들었다
단점/아쉬운점
일단 멀티모달 연구라고 생각해서 그런지 어떻게 피쳐를 뽑고 사용했는지 등의 모델관련한 내용이 있을거라 생각했는데 그냥 SoTA모델을 사용한 결과들만 나열해서 아쉬웠다. (멀티모달 연구라기 보다 데이터검증 연구 느낌)
느낀점
분명 contribution에서 정량화하는 새로운 metric을 제안한다고 했는데, 수식이나 공식을 생각했는데 synthetic dataset으로 학습하고 모델이 일관성을 유지하는지 안하는지를 평가하는 그 일련의 과정을 의미하는 거였다.
추가 논문
위 논문에서 Sota모델로 사용한 SAAA
Show, Ask, Attend, and Answer: A Strong Baseline For Visual Question Answering
https://arxiv.org/abs/1704.03162

4개의 댓글


논문 자체도 흥미로운데, 설명도 잘해주셔서 정말 재미지게 들었습니다!!!! 여기서 기존 연구들의 한계점과 이를 극복한 부분들이 너무 반박불가여서 배울점이 많았습니다!!!

이 논문이 데이터셋 구성과 관련된 논문이라서 어떤 모델들이 어떤 구성을 가지고 있을지도 궁금해졌는데,
그 부분도 잘 짚어주셔서 좋았습니다 ! 감사합니다 😀
피규어를 활용해서 깔끔하게 설명해주셔서 좋았습니다 :-) !!!