[Designing data-intensive applications] Chapter 1. Reliable, Scalable, and Maintainable Applications
BookClub

이번 학기 연구실에서 북클럽으로 진행되는 책은 Designing Data-Intensive Applications 라는 책이다. 이전 학기 (2021년 1월~8월)에는 Distributed Systems 책을 공부했고, 2020년에는 Parallel Computing 책을 공부했다. 교수님께서 정리해주신 이 세가지 책의 관계는 아래 그림과 같다.
practical 에서 쓰이는 tool은 계속해서 바뀌기 때문에 principle을 익혀야 한다. tool을 공부하는 것은 각자의 역할!
이 포스팅을 포함하여 이 책을 정리한 포스팅에 있는 기울임체는 교수님께서 설명해주신 추가 설명이다.
Thinking About Data Systems
많은 사람들은 database, cache, search indexs, stream processing 그리고 batch procesesing 등이 모인 application을 data intensive system이라고 부른다. 하지만 각각을 비교해보면 서로 다른 특징과 구현 방법을 가진다. 그렇다면 왜 사람들은 앞선 용어들을 data system이라고 포괄적으로 말할까? 이유는 다음과 같다.
- data를 처리하고 저장하기 위한 많은 tool이 등장하면서 분류 간의 경계가 모호해졌다.
- 많은 application이 하나의 tool로는 충족하지 못할 정도의 까다롭거나 광범위한 requiremnet를 가지고 있다. ( 하지만
work는task로 분할되어 단일 tool에서 효율적으로 수행 가능하며, 다양한 tool 들이 application code를 통해 서로 연결된다. )
data system이나 service를 설계하는 경우에 까다로운 질문도 많이 발생하고, 상황에 따라 다양한 요소들이 설계에 영향을 미친다.
좋은 system은 다음의 특성을 가져야 한다.
- Reliability : system은 하드웨어 / 소프트웨어 결함 혹은 사람의 잘못에도 불구하고 원하는 성능 수준에서 올바른 기능을 수행해야 한다.
- Scalability : 시스템의 규모가 커짐에 따라 합리적으로 처리할 수 있어야 한다.
- Maintainability : 시간이 지남에 따라 다양한 사람들이 시스템에서 많은 작업을 해도 현재 동작을 유지하고 생산적으로 작업을 할 수 있어야 한다.
Reliability
Reliability란, 잘못되더라도 계속해서 올바르게 (working "correctly") 작동한다는 뜻이다.
여기서 "올바르게"란, 다음 네가지를 의미한다.
-
application은 사용자가 기대한대로 기능을 수행한다.
-
사용자가 실수를 저지르더라도 혹은 소프트웨어가 예기치 못한 일을 하더라도 tolerate 해야 한다.
-
load 및 data volume 이 늘어나더라도 충분한 use case를 만족해야 한다.
-
시스템은 허용되지 않은 접근 혹은 오남용을 방지한다.
"잘못될 수 있는 것"을 fault라고 부르며, 시스템은 fault를 예상하고, 대처할 수 있어야 한다. 이러한 특성을 fault tolerant 혹은 resilient라고 한다. ( 특정 유형의 fault에서만 만족하면 된다.)
fault가 일어날 가능성을 0으로 만드는 것은 쉽지 않은 일이므로, 궁극적인 목적은 "fault로 인해 failure (시스템 전체가 멈춰서 사용자에게 필요한 기능을 제공하지 못하는 것)을 방지하는 fault tolerance 메커니즘을 만드는 것" 이다.
(failure를 기댓값을 제공하지 못했다는 결과 그 자체에 초점을 맞춰서 이해하면 조금 더 일맥상통 하다.)
Netflix Chaos Monkey 에서는 의도적으로
fault를 유도하여fault tolerance machinery가 지속적으로 실행되고 테스트되도록 하여fault가 발생할 때 올바르게 처리될 것이라는 접근 방식을 사용했다.(여기서 말하는 fault는 예를 들어, 컨테이너가 죽는 것이라고 말할 수 있고, 테스트하는 것은 컨테이너들을 무작위로 죽이는 방법을 사용한다.)
Hardware Faults
하드웨어는 약 10년 ~ 50년의 평균 고장시간(MTTF)(Mean Time To Failure)를 갖는다. 이 뜻은, 10,000개의 하드 디스크가 있는 스토리지 클러스터에서는 평균적으로 하루에 하나의 디스크가 죽을 수도 있다는 뜻이다.
(책에서는 약 10년 ~ 50년이라고 설명하는데, 실제로는 약 5년 정도로 훨씬 짧다고 한다. 실제로 데이터 센터에서 사용하는 하드 디스크는 단가가 굉장히 싸다고 한다. 이 뜻은 자연스럽게 수명이 짧아진다는 것인데, 그 이유는 비싼 단가를 투자한만큼 MTTF에 효율을 못 보기 때문이다. 그래서 하드웨어가 하나 죽으면 하드웨어를 고치거나 새로운 것으로 교체하는 시간 동안 얼른 살아있는 다른 머신으로 옮겨서 작업하는 것이 효율적인 대응책이라고 볼 수 있다. 이런 흐름으로 인해 소프트웨어적인 솔루션이 중요해지고 급속도로 발전하고 있는 것이다.)
이에 대한 대응으로는,
-
system의 실패율을 줄이기 위해 개별 하드웨어 컴포넌트에
redundancy를 추가한다.한 컴포넌트가 죽었을 때, 복구하는 동안 그 컴포넌트의
redundant component가 역할을 대신한다는 뜻이다. 이 대응 방법은 새 시스템에 백업을 빠르게 복원할 수 있는 한 가동 시간이 critical 하지 않기 때문에 resonable하다고 볼 수 있다. 하지만 data volume과 application에 요구되는 연산이 복잡해지고 증가함에 따라 더 많은 하드디스크를 쓰게 되고, 자연스럽게 하드웨어 오류 비율이 증가했다.Amazon Web Service (AWS)와 같은 일부 클라우드 플랫폼에서는 single machine의 reliability 보다는 flexibility와 elasticityi를 우선시 하도록 설계되어 있다.
-
소프트웨어 fault tolerance 기술을 추가로 사용한다.
single server system의 경우에는, machine을 reboot 하는 경우에 downtime이 추가로 필요하지만, machine failure를 허용하는 시스템에서는 downtime을 고려하지 않아도 된다는 이점이 생긴다.
Software Errors
시스템 내의 시스템 오류는 예측하기 어렵고, 노드 간에 correlation이 있기 때문에 Hardware Faults보다 더 많은 failure를 일으키는 경향이 있다.
한 가지 예를 들자면, 한 컴포넌트의 작은 fault가 다른 컴포넌트의 fault를 트리거하고, 차례로 다른 컴포넌트들의 fault를 유발하는 cascading fault 가 있다. 혹은 시스템이 의존하는 서비스가 느려지거나 응답하지 않거나 손상된 응답을 리턴하는 경우도 있을 수 있다.
소프트웨어의 systematic fault 문제에 대한 빠른 solution은 없다. (이럴 때 no silver bullet 이라는 말을 쓴다고 한다.) 상황에 맞는 check 및 warning 발생을 하던가, testing, process isolation, process 충돌 및 재시작의 허용 등을 모두 수행함으로써 대응할 수도 있는 등의 작은 solution들을 통합할 뿐이다.
Human Errors
결국엔 소프트웨어 시스템을 설계하는 것도 사람이고, 시스템을 운영하는 것도 사람이다. (한 조사에 따르면, 정전의 주요 원인은 하드웨어 오류(10~25%)가 아닌 운영자의 구성 오류라고 한다.) HW/SW error를 최소화하는 방향으로 시스템을 설계하려고 노력할테지만, 어느정도 한계가 있다.
이를 위해서 다음과 같은 대응책이 있다.
1. 사람들이 가장 많이 실수하는 곳과, failure를 많이 일으킬 수 있는 곳을 분리해야 한다.
2. unit test에서 whole-system test까지 모든 수준에서 철저하게 테스트를 해야 한다.
3. human error로 부터 빠르고 쉽게 복구하여 failure가 일어났을 때의 영향을 최소화한다.
4. 성능 지표 및 오류율과 같은 상세하고 명확한 모니터링을 설정한다.
(결국엔 사람이 error를 만들지 않도록 software를 design 하는 것이 핵심이다. 즉, 사람은 "do the right thing" 과 "discourage the wrong thing" 에 대한 책임이 있다.)
Scalability
시스템이 현재 안정적으로 작동한다고 해도 미래에도 반드시 안정적으로 작동할 것이라는 보장은 없다. 성능 저하의 일반적인 이유 중 하나는 부하(load) 증가이다.
scalability란 증가된 부하에 대처하는 시스템의 능력을 의미한다. "X는 확장 가능하다" 와 같은 1차원 적인 의미가 아니다. 즉, 시스템에서의 scalability는 "시스템이 특정 방식으로 증가하는 경우 성장에 대처하기 위해 개발자들이 선택할 수 있는 옵션은 무엇인가?" 또는 "추가 부하를 처리하기 위해 컴퓨팅 리소스를 어떻게 추가할까?"이다.
Describing Load
부하(load)는 load parameter라고 하는 몇 개의 숫자로 표현할 수 있다. parameter는 system architecture에 따라 다르다.
(ex. 웹 서버에 대한 초당 요청 수, DB의 read 대 write의 비율, 대화방에서 동시에 활성인 사용자 수 등,,,)
Twitter를 예시로 들어보자. Twitter에는 2개의 key operation이 있다.
Post tweet
사용자가 팔로워들에게 새로운 메세지를 게시한다. ( 평균 1초당 4.6k request, 피크 때는 1초당 12k request)
Home timeline
사용자는 본인들이 팔로우하는 사람들의 트윗을 볼 수 있다. (1초당 300k request)
Twitter의 scaling challenge는
fan-out문제 ( 모든 팔로워들에게 tweet을 보여줘야하는 것 )이다. Twitter는 이를 위해서 두가지 방법을 사용한다.
사용자가 자신의 home timeline을 요청하면 팔로우하고 있는 모든 사람을 찾아서 각각의 모든 tweet을 합쳐서 보여준다.
-> home timeline query의 부하가 심하다는 단점이 있다.
사용자 각각의 cache를 유지하면서, 사용자가 post tweet을 하면 팔로우하고 있는 모든 사람을 찾아서 그 사람들의 timeline cache에 새로운 tweet을 집어넣는다.
-> tweet을 작성하는 작업 자체가 많은 부가작업을 필요로 하는데, 팔로워가 많은 사용자의 tweet 일수록 부하가 심해진다는 단점이 있다. Twitter는 보통 5초내에 팔로워들에게 tweet을 전달하려고 하기 때문에 적절한 시점을 잘 맞추는 것이 중요하다.
즉 Twitter에서의
key load parameter는 사용자 당 팔로워 수이다.(이런 문제점으로 인해 현재 Twitter는 1번과 2번 방법을 섞은 hybrid 방식을 채택하였다. 관련 내용은 12장에서 더 자세하게 다루게된다.)
Describing Performance
부하 증가를 설명할 때는 다음과 같은 방법으로 측정해야 한다.
load parameter는 증가시키고, 시스템 리소스는 그대로 유지하면 시스템의 성능에는 어떤 영향이 미칠까?load parameter를 증가시킬 때, 성능을 그대로 유지시키려면 시스템 리소스는 얼마나 증가 시켜야할까?
이 질문들은 공통적으로 "성능"에 대해서 말하고 있다.
성능은 다양한 지표로 측정할 수 있다.
- 하둡(Hadoop)과 같은 시스템에서는
throughput(ex. 1초당 처리할 수 있는 record의 수)를 사용한다. - 온라인 시스템에서는 서비스 응답 시간을 고려한다.
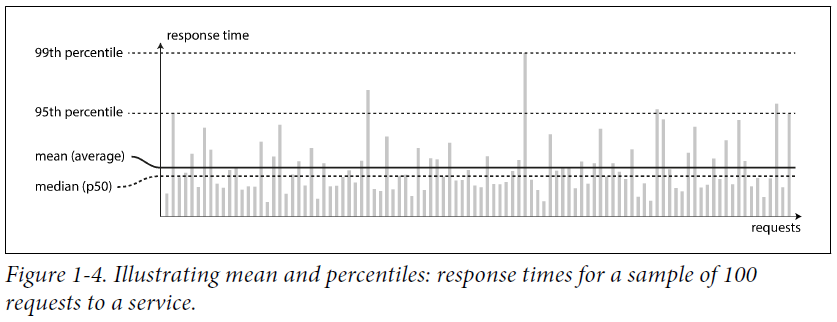
서비스 응답 시간 (service response time)은 클라이언트가 request를 보내고, response를 받을 때까지의 시간이다. 같은 request를 여러번 보내도 클라이언트는 조금씩 다른 응답시간을 받게된다.
위 그림을 보면 가끔씩 응답 시간이 오래걸리는 것(
outlier)을 볼 수 있다. 그 이유는 다양할 수 있는데 대표적으로 백그라운드 프로세스의 context switch, 네트워크 패킷 손실, TCP 재전송 등이 있다.보통 서비스의
평균(average) 응답시간을 보는데, "typical response time"을 알고 싶을 땐 얼마나 많은 사용자들이 delay를 겪었는지 알려주지 않기 때문에 그닥 좋은 지표가 아니다.그래서
백분위(percentiles)이라는 지표를 사용한다. 이 지표를 사용하면median값이 나오는데median을 중심으로, 반은 보다 빠른 속도를 가지고 다른 반은 느린 속도를 가진다고 해석할 수 있다. 또한outlier가 어느 정도로 성능이 안 좋은지 판단하고 싶을 땐95th,99th,99.9thpercentiles 을 보면 된다. 예를 들어, 95번째 percentile 응답 시간이 1.5초인 경우, 100개의 요청 중 95개는 1.5초 미만이고 나머지 5개는 1.5초 이상이 걸린다고 해석할 수 있다. 아주 높은 백분위 응답시간은 개발자의 control 범위 밖의 랜덤 이벤트에 의한 것들이므로 이 시간을 줄이는 것은 쉽지 않다.
Approaches for Coping with Load
scalability를 위한 2가지 방법
-
scaling up : 수직적 scaling, single machine을 더 강력하게.
-> single machine에 돌리는 것이 간단하지만, 너무 비싸다.
-
scaling out : 수평적 scaling, 여러 작은 machine들에게 load를 분산. a.k.a
shared-nothing architecture
부하를 예측하기 힘들 땐 elastic system이 유용한데, 이것은 부하가 증가되는 것을 감지하면 자동으로 computing resource를 추가하는 시스템이다. 하지만 사람이 직접 capacity를 측정하고 scaling하는 것이 더 간단하고 운영상 더 안전하다.
stateless service를 여러 machine에 분산하는 것은 쉽지만, state를 저장해야 한다면 single node에 database를 구축하는 것 (scaling up)이 통념이다. 하지만 요즘은 점점 분산시스템이 default가 되어가고 있다.
large scale을 작동시키는 시스템의 아키텍쳐는 해당 application에 특화되어 있다. 예를 들어서, 한 시스템은 1kB 크기의 request를 1초당 100,000개 처리할 수 있고, 다른 한 시스템은 2GB 크기의 request를 1분당 3개 처리할 수 있다고 가정했을 때, 두 시스템이 같은 data throughput을 가진다 하더라도 엄연히 매우 다른 시스템이다. 그러므로 특정 application에 대해 scaling을 잘 하는 architecutre를 위해서는 load parameter를 분명히 하는 것이 중요하다.
Maintainability
소프트웨어에서는 초기 개발 비용보다 유지보수 비용이 훨씬 많이 든다. 사람들은 소위 말하는 legacy system(다른 사람의 실수를 고친다거나, 기한이 만료된 플랫폼을 쓴다던가 등등의 낡은 기술이나 방법론, 컴퓨터 시스템을 사용하는 것)을 싫어한다. 이를 피하기 위해서 3가지 디자인 원칙을 따라야 한다.
-
Operability
시스템이 잘 작동하도록 운영하기 편하게 만든다.
-
Simplicity
시스템에서 복잡한 것은 제거함으로써 새로운 엔지니어가 봐도 이해하기 쉽게 만든다.
-
Evolvability
미래에 시스템을 쉽게 변경할 수 있도록 한다. 더불어 변경 사항이 생겨도 예상치 못한 use case에 대해 적절하게 대응할 수 있게 만든다.
Operability : Making Life Easy for Operations
시스템 개발에 있어서 운영팀은 필수적이다. 운영팀의 책임은 다음과 같다.
- 시스템이 잘 작동하고 있는지 모니터링하고, 만약 시스템의 상태가 좋지 않으면 재빠르게 복구한다.
- 시스템 failure 혹은 성능 저하와 같은 문제의 원인을 추적한다.
- 소프트웨어와 플랫폼은 항상 최신 버전을 유지한다.
- 시스템간의 dependency를 확인하여 문제가 있을만한 변경사항이 손상을 일으키기지 않도록 방지한다.
- 향후 문제를 예측하고 그 문제들이 발생하기 전에 해결한다. (e.g., capacity)
- 배포, 관리 설정 등에 대한 모범 사례와 tool 마련
- 플랫폼 변경과 같은 복잡한 유지 보수
- configuration 변경 시 보안 유지
- 운영을 예측 가능하도록 하고, 생산 환경을 안정적으로 유지할 수 있는 프로세스 정의
- 시스템에 대한 기본 지식 보존
좋은 운영성은 routine task 를 쉽게 만드는 것이다. data system에서 이를 위해 할 수 있는 다음과 같다.
-
우수한 모니터링으로 가시성 제공
-
자동화와 표준 도구와의 통합을 위한 지원
-
개별 머신과의 dependency 피함
-
운영 모델을 쉽게 이해하기 위한 문서 제공 (ex. "내가 X를 하면 Y 가 발생한다.")
-
좋은 default 동작을 제공하고, 필요할 땐 default를 무시할 수 있는 기능 제공
-
적절한 자가 치유와 관리자의 수동 컨트롤 제공
-
최대한 예측 가능한 행동 보여주기
Simplicity : Managing Complexity
소프트웨어의 크기가 커질수록 복잡성이 증가하는 것은 당연하다. 복잡성이 증가하면 발생하는 증상은 state space의 증가, 모듈의 긴밀한 결합, 종속성 증가 등 다양하다. 또한 필요한 예산 혹은 일정이 초과될 것이며, 변경 사항이 있을 때 엄청난 버그가 발생할 것이다.
시스템을 간단하게 만든다는 것은 기능을 줄이라는 것이 아니다. 우발적인 복잡성 (accidental complexity)을 제거하라는 뜻이다. accidental complexity란, 소프트웨어가 해결하는 문제에 내재되어 있는 것이 아니라 구현에서만 발생하는 복잡성이다. accidental complexity를 제거하기 위한 최고의 방법은 abstraction이다. abstraction을 사용하면 많은 양의 구현적인 detail을 숨길 수 있기 때문에 이해하기 쉽고 깔끔해진다. 하지만, 분산 시스템에서 좋은 abstraction을 사용하는 것은 쉽지 않다.
Evolability : Making Change Easy
비즈니스 우선 순위가 변경되거나 사용자가 새로운 기능을 요청하는 등 system requirement는 계속 변한다. 이렇게 자주 변화하는 환경에서 소프트웨어를 개발할 때 유용하게 쓰이는 것이 Agile 패턴, TDD(Test Driven Developtment) , refactoring이다.
하지만 Agile 개발론은 하나의 어플리케이션에 대한 두 개의 소스 코드 파일과 같은 작은 부분을 커버하는데 초점을 맞춘다. 하지만 이 책에서 집중하는 것은 서로 다른 특성을 가진 여러 어플리케이션이나 서비스에서 "민첩성(agility)을 높이는 방법이다. data system에서는 이 민첩성을 다른 말로 evolability라고 말한다.
