
Relational Model Versus Document Model
가장 유명한 data model은 relational database을 기반으로하는 SQL 모델이다. 각 data는 relation (=table) 로 구성되며, 관계는 순서가 없는 tuple (=rows)의 모음이다. relational database는 data를 저장하고 쿼리하는데 효율적이며, 이를 시작으로 object database (현재는 없어짐), XML datbase 등이 등장했다. 컴퓨터가 발전함에 따라 relational database는 다양하게 사용되며 일반화되었다. 대표적으로 online publishing, discussion, social networking 등에서 사용된다.
The Birth of NoSQL
relation model의 강력함을 넘어서기 위해 NoSQL이라는 모델이 등장했다. 원래는 트위터에서 open source, distributed, nonrelational database에 대한 인기 해시태그였지만, Not Only SQL로 재해석되며 많은 인기를 끌게 되었다.
NoSQL의 장점은 다음과 같다.
- relational database보다 뛰어난 scalability ex) large dataset, high write throughput
- 무료 오픈소스 소프트웨어에 대한 선호
- 전문화된 쿼리 작업
- 더 dynamic하고 expressive한 data model
application마다 요구사항이 다르기 때문에 relational database와 nonrelational database가 함께 사용 될 수 있다. 이를 polyglot persistence라고 한다.
The Object-Relational Mismatch
오늘날 대부분의 application들은 객체 지향 프로그래밍(OOP) 언어로 이루어지는데, 여기서 relational database와 OOP 사이에 데이터 구조와 기능에 대한 충돌로 인해 model 간의 연결이 끊어지는 impedance mismatch가 발생한다. 그렇기 때문에 application code와 database model 간에 translation layer가 필요하다. 이런 문제점을 해결하기 위해 Object-relational mapping(ORM) 프레임워크를 사용하여 boilerplate code의 양을 줄일 수 있다. 하지만 두 모델 간의 차이를 완벽히 숨길수는 없다.
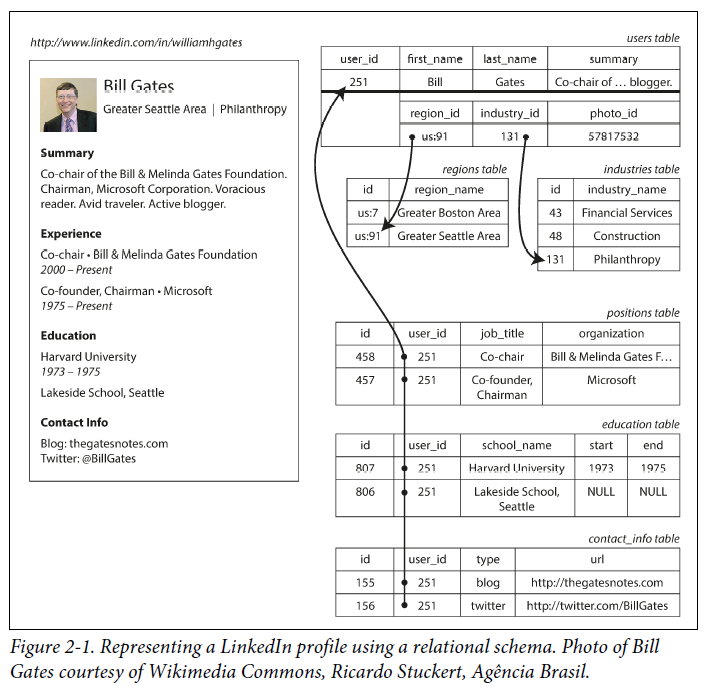
relational schema에서 one-to-many 관계가 발생했을 때 나타낼 수 있는 방법
-
foriegn key reference 사용
-
SQL의표준 이후 버전의 structured datatypes와 XML data 사용
-
JSON 또는 XML 문서로 인코딩하여 database의 text column에 저장하고 application이 구조와 내용을 해석
이력서와 같은 data structure는 JSON이 가장 적합할 수 있다. MongoDB, RethinkDB와 같은 document oriented database가 이러한 데이터 모델을 사용한다. (아래는 이력서를 JSON으로 변환한 예제이다.)
{
"user_id": 251,
"first_name": "Bill",
"last_name": "Gates",
"summary": "Co-chair of the Bill & Melinda Gates... Active blogger.",
"region_id": "us:91",
"industry_id": 131,
"photo_url": "/p/7/000/253/05b/308dd6e.jpg",
"positions": [
{"job_title": "Co-chair", "organization": "Bill & Melinda Gates Foundation"},
{"job_title": "Co-founder, Chairman", "organization": "Microsoft"}
],
"education": [
{"school_name": "Harvard University", "start": 1973, "end": 1975},
{"school_name": "Lakeside School, Seattle", "start": null, "end": null}
],
"contact_info": {
"blog": "http://thegatesnotes.com",
"twitter": "http://twitter.com/BillGates"
}
}
JSON은 impedance mismatch를 줄일 수 있으며, multi-table schema보다 더 좋은 locality를 가지기 때문에 관련 정보를 하나의 쿼리로 가져올 수 있다. 아래 사진에서 볼 수 있듯이 one-to-many 관계는 data의 tree structure 를 만든다.
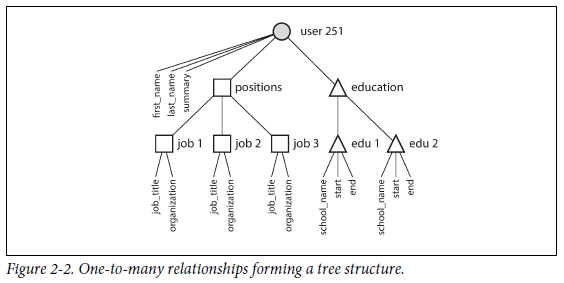
Many-to-One and Many-to-Many Relationships
이전 section의 이력서 예제를 보면 region_id와 industry_id 필드가 평문이 아닌 id로 되어 있다. 이렇게 함으로써 여러 이점을 얻을 수 있다.
- 일관적인 스타일 및 맞춤법
- 모호성 방지
- 업데이트 용이
- localization 지원
- 더 쉬운 검색 가능
id를 사용하면 정보가 변경되더라도 동일하게 유지된다는 편리함이 있다. 특정 정보에 대한 중복이 여러개 있는 상황에서 해당 정보가 변경되면 모든 중복 사본을 업데이트 해야 한다. 이는 write overhead와 inconsistency를 유발할 수 있다. 이러한 ""중복 (duplication)을 제거하는 것""이 데이터베이스 정규화의 핵심이다.
하지만 중복된 데이터를 정규화하려면 many-to-one 관계가 필요한데, 이것은 document model에 잘 맞지 않다. 관계형 데이터베이스에서는 join operation이 쉽지만, document model에서는 일반적으로 join operation을 지원하지 않는다. 데이터베이스 자체가 join operation을 지원하지 않을 경우에는 여러 query를 수행해서 join operation을 흉내내야 한다. join-free application이더라도 기능이 추가 됨에 따라 data들은 더 긴밀한 연관성을 갖기 때문에 (즉, many-to-many 관계) 어쨌거나 join operation이 필요하게 될 수도 있다.
Are Document Databases Repeating History?
many-to-many 관계와 join은 관계형 데이터베이스에서 일상적으로 사용되지만 document model과 NoSQL에서는 그렇지 않다.
IBM의 IMS(Information Management System)
IMS는 계층적 모델을 사용하였는데, 모든 데이터를 JSON 구조처럼 레코드 트리로 표현하였다. many-to-one 관계에서는 잘 작동하였지만, many-to-many 관계와 join 연산을 지원하지는 않았다. 그렇기 때문에 개발자들은 데이터를 duplicate 할 것인지, 아니면 reference를 수동으로 해결할 것인지 결정해야 했다.
이러한 계층적 모델을 해결하기 위한 두가지 솔루션이 있다.
- relational model
- network model
The network model
이 모델은 CODASYL 모델이라고도 한다. 계층적 모델의 트리 구조에서 레코드는 단 하나의 부모 레코드를 가진다. 하지만 네트워크 모델에서는 access path를 통해 (foriegn key가 아닌 프로그래밍의 포인터와 비슷한 개념으로) 여러 개의 부모를 가질 수 있으며, 이런 개념으로 many-to-many 관계를 모델링 한다. mant-to-many 관계를 linked list로 표현하면 특정 레코드에 접근하는데 root 부터 시작하여 여러 개의 경로가 생길 수 있다. 이것은 n차원 데이터 공간을 탐색하는 것과 같다.
계층적 모델과 네트워크 모델의 큰 단점은 원하는 데이터에 대한 경로가 없을 때 새로운 access path를 처리하기 위해 수많은 database query code를 작성해야 한다는 것이다.
The relational model
relational model에서 관계(table)은 튜플(row)의 모음이다. 일부 column을 key로 지정하고 일치시켜서 특정 튜플을 읽을 수 있다. 또한, 다른 테이블의 foreign key와 상관없이 모든 테이블에 새 row를 삽입 할 수 있다.
query optimizer는 query를 날렸을 때 query의 어떤 부분을 먼저 실행할 지 즉, access path를 자동으로 선택한다. 또한, 새로운 방식으로 쿼리할 때 새로운 index를 추가하기만 하면 가장 적절한 index를 자동으로 사용한다. 이러한 장점들로 인해 관계형 모델을 사용하면 새로운 기능을 추가하기가 쉬워진다.
Comparison to document databases
document database와 위에서 언급한 두 모델을 비교하면 각각 한가지의 공통점이 있다.
-
network model - duplicate 레코드는 별도의 테이블이 아닌 상위 레코드 내에 저장한다.
-
relational model - many-to-many와 many-to-one 관계를 나타낼 때 관련 item은 foreign key와 같은 개념인
document reference로 참조되며, 이는 join operation 혹은 후속 query를 사용해서 read 시점에서 확인된다.
Relational Versus Document Databases Today
Relational database와 Document database를 비교할 때는 fault-tolerance와 concurrency 등 고려해야 할 속성들이 있다. RDB와 DDB를 간단히 비교하면 다음과 같다.
-
RDB : join, 다대다 및 다대일 관계 지원
-
DDB : 스키마의 유연성, locality로 인한 성능 향상, 일부 application에 최적화된 데이터 구조
Which data model leads to simpler application code?
어떤 데이터베이스를 쓸지는 데이터 항목 간의 관계 유형에 따라 달라진다.
application의 데이터가 한 번에 로드되는 다대일 관계의 트리 구조를 가지고 있다면 document model을 사용하는 것이 좋다. document와 같은 구조를 여러 테이블로 분할하는 relational sherdding 기술은 스키마와 코드를 더 복잡하게 하기 때문이다. 하지만 앞에서 언급했듯이 중첩 항목에 대한 한계점이 있다. 또한, join을 지원하지 않는다는 점이 있는데 이것은 application이 다대다 관계를 가지지 않는다면 큰 문제가 되지는 않는다. 다대다 관계를 사용하는 경우엔 denormalization을 통해 어느 정도 해결할 수 있지만, 데이터의 일관성을 위한 추가 작업이 필요하다. 때문에 이러한 경우엔 relational model이 더 용이하다.
정리하자면,
데이터가 문서와 비슷한 구조일 경우 : document model
데이터가 다대다 관계를 사용할 경우 : relational model
데이터가 고도로 상호연결된 경우 : graph model
Schema flexibility in the document model
-
JSON - document database과 relational database에서 지원되며 스키마를 적용하지 않는다. (스키마를 지원하지 않는다는 뜻은 document에 임의의 키와 값을 추가할 수 있으며, 읽을 때 필드의 존재 여부를 알 수 없다는 뜻이다.)
-
XML - 선택적 유효성 검사와 함께 relational database에서 지원된다.
document database는 스미카를 적용하지 않지만, 사실 명백하게 보면 데이터를 읽는 코드에서 일종의 구조를 가정하기 때문에 암시적인 스키마가 있다.
-
schema-on-read: 데이터 구조가 암시적이며 데이터를 읽을 때에만 해석, 프로그래밍 언어의 dynamic (runtime) type checking 과 유사. 모든 레코드가 동일한 구조일 때 용이.if (user && user.name && !user.first_name) { // Documents written before Dec 8, 2013 don't have first_name user.first_name = user.name.split(" ")[0]; }application이 데이터 형식을 변경하려는 상황에서, document database에서는 새로운 필드를 가진 document를 생성하고 application code에서 위와 같이 처리해줘야 한다.
-
schema-on-write: 스키마가 명시적인 관계형 데이터베이스의 전통적인 접근 방식, 프로그래밍 언어의 static (compile-time) type checking과 유사. 컬렉션 내의 항목이 모두 동일한 구조가 아닐 때 용이.ALTER TABLE users ADD COLUMN first_name text; UPDATE users SET first_name = split_part(name, ' ', 1); -- PostgreSQL UPDATE users SET first_name = substring_index(name, ' ', 1); -- MySQL마찬가지로 application이 데이터 형식을 변경하려는 상황에서는 data를 migraion 해야 한다. 이 방법은 ALTER TABLE 구문과 UPDATE 구문 수행으로 인해 시간이 더 소모된다.
Data locality for queries
document는 일반적으로 JSON, XML 또는 이외의 binary 변형으로 인코딩 된 single continuous string으로 저장된다. 만약 application이 전체 document에 자주 access 해야 하면, 저장된 위치(locality)에 따라 성능차이가 난다.
locality의 이점은 document의 많은 부분이 동시에 필요한 경우에만 적용된다. database는 document의 작은 부분에만 access 하더라도 전체 document를 로드해야 한다. 또한, document를 업데이트 할 때도 인코딩된 크기를 변경하는 업데이트면 전체 document를 업데이트 해야 한다.
locality를 위해 관련 데이터를 함께 그룹화하는 아이디어는 document model에만 적용되는 것은 아니다.
relational model에서 locality를 위해 관련 데이터를 함께 그룹화하는 case
Google의 Spanner database : 스키마가 table의 row가 상위 table 내에서 interleaved 되게 선언되게 함.
Oracle : multi-table index cluster table 사용
Bigtable data model : column - family 개념
Convergence of document and relational databases
-
Relational database의 document model convergence
MySQL을 제외한 다른 relational databse에서는 XML을 지원하고, 9.3 ver. 이상의 PostgreSQL, 5.7 ver. 이상의 MySQL, 10.5 ver. 이상의 IBM DB2는 JSON을 지원함으로써 document model과 유사한 데이터 모델을 사용한다.
-
Document database의 relational model convergence
RethinkDB는 join과 같은 relational query 언어를 지원하고, 일부 MongoDB 드라이버는 자동으로 database reference를 확인함으로써 relational model과 유사한 데이터 모델을 사용한다.
Query Languages for Data
SQL은 선언적 (declarative) query 언어이고, IMS와 CODASYL은 명령적 (imperative) query 언어이다. 선언적? 명령적? 이게 무슨 뜻일까?
-
imperative query lang.- 일반적으로 많이 사용되는 프로그래밍 언어는 명령적 (imperative) 언어이다.
- 컴퓨터에 특정 작업을 특정 순서로 수행하도록 지시한다.
-
declarative query lang.-
원하는 데이터 패턴 (결과가 충족되어야 하는 조건과 정렬, 그룹화, 집계와 같은 데이텨 변환 방법)을 지정하기만 하면 된다.
-
어떤 인덱스와 어떤 조인 방법을 사용할 지, 쿼리를 어떤 순서로 진행할 지는 데이터베이스 시스템의 query optimizer 프로그램이 결정한다.
-
데이터베이스 엔진의 구현 세부 정보를 숨기므로 쿼리를 변경하지 않고도 데이터베이스 시스템의 성능을 향상시킬 수 있다.
-
순서에 의존하지 않기 때문에 병렬 실행에 적합하다.
-
Declarative Queries on the Web
선언적 쿼리 언어의 장점은 데이터베이스에만 국한되지 않는다.
바다 동물에 대한 웹페이지가 있다고 가정하고, 현재 사용자가 상어 페이지를 보고 있다고 해보자. 코드는 다음과 같다.
<ul>
<li class="selected">
<p>Sharks</p>
<ul>
<li>Great White Shark</li>
<li>Tiger Shark</li>
<li>Hammerhead Shark</li>
</ul>
</li>
<li>
<p>Whales</p>
<ul>
<li>Blue Whale</li>
<li>Humpback Whale</li>
<li>Fin Whale</li>
</ul>
</li>
</ul>여기에 현재 선택한 페이지의 제목에 파란색 배경을 지정해보자. 이를 위한 CSS 코드는 다음과 같다.
li.selected > p {
background-color: blue;
}브라우저는 li.selected>p 규칙이 적용되어야 하는지 아닌지를 감지하고, 선택한 클래스가 제거되면 ( 다른 페이지를 선택하면 ) 즉시 파란색 배경을 제거한다. 외에도 XSL 코드는 다음과 같다.
<xsl:template match="li[@class='selected']/p"> // css 코드에서의 li.selected > p와 동일
<fo:block background-color="blue">
<xsl:apply-templates/>
</fo:block>
</xsl:template>이 두 언어의 공통점은 선언적 언어라는 것이다.
만약 위 코드를 명령형 접근 방식으로, Javascript의 DOM API를 사용해서 구현한다면 다음과 같을 것이다.
var liElements = document.getElementsByTagName("li");
for (var i = 0; i < liElements.length; i++) {
if (liElements[i].className === "selected") {
var children = liElements[i].childNodes;
for (var j = 0; j < children.length; j++) {
var child = children[j];
if (child.nodeType === Node.ELEMENT_NODE && child.tagName === "P") {
child.setAttribute("style", "background-color: blue");
}
}
}
}이 코드는 몇 가지 문제점을 가진다.
- 사용자가 다른 페이지를 클릭해서 선택한 클래스가 제거되면 코드를 다시 실행하더라도 파란색 배경이 제거되지 않는다. 즉, 전체 페이지가 다시 로드될 때까지 항목이 강조 된 상태로 유지된다.
- 성능을 향상시킬 수 있는
document.getElementsByClassName("selected")또는document.evaluate()와 같은 새 API를 활용하려면 코드를 싹 갈아야 한다.
결론은, 웹브라우저에서도 선언형 CSS 스타일이 효율적이며, 데이터베이스에서도 선언적 쿼리 언어가 훨씬 낫다는 것이다.
MapReduce Querying
MapReduce는 많은 컴퓨터에서 대량의 데이터를 처리하기 위한 프로그래밍 모델이다. MongoDB, CouchDB를 포함한 일부 NoSQL 데이터 저장소는 제한된 형태의 맵리듀스를 지원한다. 주로 많은 doucment를 대상으로 read-only query를 수행할 때 사용한다. (맵리듀스에 대한 자세한 설명은 Chap10에서 설명된다.)
MapReduce는 declarative query lang.과 imperative query lang.의 중간이다. 함수형 프로그래밍의 map(=collect)와 reduce(=fold / inject) 함수를 기반으로 한다.
- MongoDB의 MapReduce
- map과 reduce 함수는
pure function이어야 한다. 즉, 입력으로 전달된 데이터만 사용하고 추가적인 데이터베이스 query를 수행할 수 없어야 하며, side effect가 없어야 한다. - 이를 통해 MongoDB의 MapReduce는 임의 순서로 함수를 실행 할 수 있고, 장애가 발생해도 함수를 재실행 할 수 있다.
- 2.2 ver.부터
aggregation pipeline이라 부르는 declarative query lang.을 지원한다.- MapReduce의 사용성에 있어서, coordinated javascript 함수 두개를 작성해야 하는 것은 어렵기 때문에 이를 해소하고자 한다.
- JSON 기반 구문을 사용한다.
- map과 reduce 함수는
Graph-Like Data Models
앞의 내용을 정리하면서 설명해보자면 아래와 같다.
-
document model : one-to-many 관계이거나 레코드간 관계가 없을 때 적절
-
relational model : many-to-one 관계이거나 단순한 many-to-many 관계일 때 적절
-
graph model : 데이터 간 연결이 복잡할 때 적절
그래프는 vertex와 edge로 이루어져있다. 일반적으로 graph model이 쓰이는 경우는 아래와 같다.
- social graph : vertex는 사람, edge는 사람간의 관계
- web graph : vertex는 웹 페이지, edge는 다른 페이지에 대한 HTML 링크 -> pagerank를 통한 인기 검색어
- road or rail network : vertex는 교차로, edge는 교차로 간 도로나 철로 선 -> 네비게이션의 최던 경로 검색
그래프는 homogeneous data 뿐만 아니라, 다른 유형의 객체도 일관성 있게 저장할 수 있다.
facebook은 다른 여러 유형의 vertex와 edge를 단일 그래프로 유지한다.
vertex는 사람, 장소, 이벤트, 체크인, 사용자가 작성한 코멘트를 나타내고, edge는 어떤 사람이 서로 친구인지, 어떤 위치에서 체크인이 발생했는지, 누가 어떤 포스트에 코멘트를 했는지 등을 나타낸다.
이번 절에서 배울 내용은 아래와 같다.
- 그래프 데이터를 구조화하는 방법
- property graph model : Neo4j, Titan, InfiniteGraph
- triple-store model : Dataomic, Allegrograph
- 그래프용 query lang.
- declarative graph query lang. : Cyper, SPARQL, Datalog
- imperative graph query lang. : Gremlin
- graph processing framework : Pregel
Property Graphs
property graph model의 vertex와 edge의 구성 요소
- vertex
- A unique identifier
- A set of outgoing edges
- A set of incoming edges
- A collection of properties (key-value pairs)
- edge
- A unique identifier
- The vertex at which the edge starts (the tail vertex)
- The vertex at which the edge ends (the head vertex)
- A label to describe the kind of relationship between the two vertices
- A collection of properties (key-value pairs)
graph model의 특징 3가지가 있다.
- vertex는 다른 vertex와 edge로 연결된다. 이 때, 특정 유형과 관련 여부를 제한하는 스키마는 없다.
- 특정 vertex를 따라 앞 뒤 방향으로 순회할 수 있다.
- 다른 유형의 관계에 서로 다른 레이블을 사용하여 단일 그래프를 유지할 수 있다.
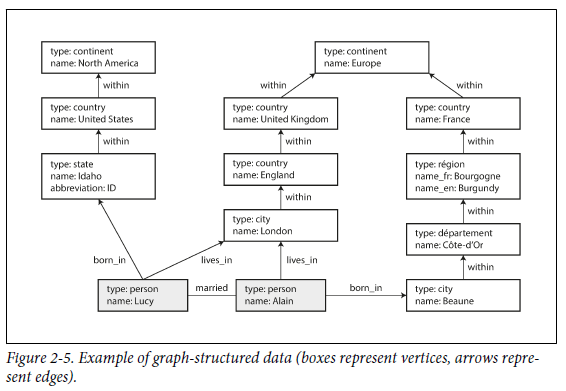
위 그림은 traditional relational schema에서 표현하기 어려운 사례 몇 가지를 보여준다. 예를 들어, 국가마다 다른 지역 구조 (프랑스의 주와 도, 미국의 군과 주)를 표현할 수 있다.
graph model은 evolvability가 좋아서 application에 기능을 추가하는 경우, application의 데이터 구조 변경을 수용할 수 있도록 그래프를 쉽게 확장할 수 있다.
The Cypher Query Language
Cypher는 Neo4j 그래프 데이터베이스로 만들어진 속성 그래프의 선언형 쿼리 언어이다.
아래 예제는 Figure 2-5의 왼쪽 부분을 삽입하는 코드를 Cypher query로 만든 것이다. 각 vertex는 USA 혹은 Idaho와 같은 symbolic name으로 주어진다. 마지막 두줄은 vertex 간의 edge를 생성하는 부분이다.
CREATE
(NAmerica:Location {name:'North America', type:'continent'}),
(USA:Location {name:'United States', type:'country' }),
(Idaho:Location {name:'Idaho', type:'state' }),
(Lucy:Person {name:'Lucy' }),
(Idaho) -[:WITHIN]-> (USA) -[:WITHIN]-> (NAmerica),
(Lucy) -[:BORN_IN]-> (Idaho)이런식으로 Figure 2-5의 모든 부분을 database에 추가하면, "United State에서 Europe으로 이민 간 모든 사람을 찾아라" 와 같은 질문을 할 수 있다. 이런 경우엔 US에서 BORN_IN edge를 가진 vertex와 Europe에서 LIVING_IN edge를 가진 vertex를 찾아서 각 vertex의 name property를 리턴하면 된다.
Cypher의 query 예제를 살펴보자. 위에서 봤던 United State에서 Europe으로 이민 간 모든 사람을 찾기 위한 query이다. 아래 쿼리에서 (person) - [:BORN_IN]->()와 같은 구문은 BORN_IN label을 가진 edge와 관련된 모든 vertex를 찾는다는 뜻이다.
MATCH
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (us:Location {name:'United States'}),
(person) -[:LIVES_IN]-> () -[:WITHIN*0..]-> (eu:Location {name:'Europe'})
RETURN person.name이 query를 해석하자면, 아래 조건을 만족하는 person vertex를 찾으면 해당 name property를 리턴하라는 것이다.
- outgoing
BORN_INedge가 있는personvertex을 찾는데,nameproperty가United State이고,Location유형인 vertex를 찾을 때까지 outgoingWITHINedge를 따라가라. - outgoing
LIVES_INedge가 있는personvertex를 찾는데, name property가Europe이고,Location유형인 vertex를 찾을 때까지 outgoingWITHINedge를 따라가라.
query를 수행하는 방법에는 위의 방식이 아니더라도 여러 방식이 있다. 보통 declarative query lang.은 작성할 때 execution detail에 대해 구체화 할 필요가 없다. 왠하면 query optimizer가 가장 최적의 전략을 자동으로 고르기 때문이다.
Graph Queries in SQL
graph data를 relational database에 넣으면 SQL을 사용해서 query를 날릴 수 있다. 하지만, relational database에서는 query에 필요한 join을 미리 알고 있어야 한다는 어려움이 있다. graph query에서는 vertex를 찾기 전에 가변적인 여러 edge를 순회해야 하기 때문에 필요한 join 수를 미리 알 수 없다.
SQL:1999 이후로 variable-length traversal paths에 대한 query 개념은recursive common table expression (WITH RECURSIVE 문)을 사용해서 표현할 수 있다.
이전 section에서 United State에서 Europe으로 이민 간 모든 사람을 찾는 query는 4줄이지만, 이를 SQL문으로 바꾸면 29줄이 된다. (-> 책 Example 2-5)
즉, 다양한 data model이 서로 다른 use case를 만족하기 위해 설계됐다는 것이고, application에 적합한 data model을 선택하는 것이 중요하다.
Triple-Store and SPARQL
Triple store에서는 모든 정보를 subject(주어), predicate(서술어), object(목적어)와 같은 three-part statement 형식으로 저장한다.
-
subject = graph의 vertex
-
object는 아래 두 가지 중 하나이다.
-
string이나 number와 같은 primitive datatype의 값
이 경우, predicate와 object는 subject vertex의 속성에서 key와 value와 동등하다. 예를 들어서 (lucy, age, 33)는 property {"age":33} 을 가진 lucy vertex와 같다.
-
graph의 다른 vertex
이 경우, predicate는 graph의 edge이고, subject는 tail vertex이며, object는 head vertex이다. 예를 들어 (lucy, marryiedTo, alain)에서 subject와 object인 lucy와 alain은 모두 vertex이고, marryiedTo는 두 vertex를 연결하는 edge의 label이다.
-
-
predicate 또한 아래 두 가지 중 하나이다.
-
edge
이 경우, object는 vertex이다.
-
property
이 경우, object는 string literal이다.
-
아래 예제는 Turtle 형식의 트리플로 작성된 것이다.
@prefix : <urn:example:>.
_:lucy a :Person; :name "Lucy"; :bornIn _:idaho.
_:idaho a :Location; :name "Idaho"; :type "state"; :within _:usa.
_:usa a :Location; :name "United States"; :type "country"; :within _:namerica.
_:namerica a :Location; :name "North America"; :type "continent".The semantic web
Triple store data model은 semantic web과는 완전히 독립적이다. 하지만 많은 사람들이 이 둘을 매우 밀접한 관계가 있다고 생각한다.
semantic web이란, 컴퓨터가 읽을 수 있도록 기계가 판독 가능한 데이터로도 정보를 게시하는 web이다. Resource Description Framework (RDF)는 서로 다른 웹 사이트가 일관된 형식으로 데이터를 게시하기 위한 방법을 제안한다. 또한, 서로 다른 웹 사이트의 데이터가 일종의 internet-wide "database of everything"인 web of data에 자동으로 결합할 수 있게 한다.
하지만 semantic web은 여러 단점들로 인해 현재는 부진한데, 그럼에도 semantic web project에서 유래한 좋은 작업이 많이 있다.
The RDF data model
RDF는 인터넷 전체의 데이터 교환을 위해 설계되었기 때문에 Triple의 subject, predicate, object는 주로 URI이다. 예를 들어, predicate는 앞에 나왔던 WITHIN이나 LIVES_IN이 아니라 <http://my-company.com/namespace#within> 이런 식일 수도 있다는 것이다. 여기서 URL <http://my-company.com/namespace는 실제로 접속 가능한 주소일 필요는 없다. RDF 에서 이는 그저 단순한 namespace 일 뿐이다.
RDF는 터틀 언어로도 쓸 수 있고, XML 형식으로도 쓸 수 있다. 터틀 언어의 경우엔 사람이 RDF 데이터를 읽을 수 있는 형식으로 표현된다. XML의 경우엔 너무 장황하게 표현된다.
The SPARQL query language
SPARQL은 RDF data model을 사용한 triple-store query language이다. Cypher보다 SPARQL이 먼저 만들어졌고, Cypher 패턴 매칭을 SPARQL에서 차용했기 때문에 둘은 비슷해 보인다. 앞 section에서 나왔던 '미국에서 유럽으로 이민간 사람 찾기' 예제는 Cypher 보다 SPARQL에서 더 간결하게 표현할 수 있다.
SELECT ?personName WHERE {
?person :name ?personName.
?person :bornIn / :within* / :name "United States".
?person :livesIn / :within* / :name "Europe".
}Cypher와 SPARQL의 구조를 비교해보면 매우 비슷하다. SPARQL에서 variable을 표현할 때는 ?를 먼저 쓴다.
(person) -[:BORN_IN]-> () -[:WITHIN*0..]-> (location) # Cypher?person :bornIn / :within* ?location. # SPARQLRDF에서는 property와 edge를 구분하지 않고 predicate만 사용하기 때문에 property 매칭을 위해 동일한 구문을 사용할 수 있다.
예를 들어, 아래 예제를 보면 usa라는 변수는 name property를 가지고, value가 United State인 모든 vertex여야 한다.
(usa {name:'United States'}) # Cypher?usa :name "United States". # SPARQLGraph Database와 Network Model의 비교
- CODASYL 데이터베이스에는 다른 레코드 타입과 중첩 (nested) 가능한 레코드 타입을 지정하는 스키마가 있다. 하지만 graph database에는 이런 제한이 없다.
- CODASYL에서 특정 레코드에 도달하는 유일한 방법은 레코드의 접근 경로 중 하나를 탐색하는 것이다. graph database에서는 고유 ID를 가지고 임의 정점을 직접 참조하거나 index를 사용해 특정 값을 가진 정점을 빠르게 찾을 수 있다.
- CODASYL에서 레코드의 하위 항목들은 정렬된 집합이므로, database가 그 순서를 유지해야 하기 때문에 application이 새로운 데이터를 데이터베이스에 넣었을 때 정렬된 집합에서 새로운 레코드의 위치를 염두해야한다. graph database에서는 vertex와 edge들이 정렬되어 있지 않다.
- CODASYL에서 모든 query는 imperative이고, 작성이 어렵다. 또한 스키마가 변경되면 query가 쉽게 손상된다. graph database에서는 개발자가 원하면 순회 imperative code를 적을 수 있다.
The Foundataion : Datalog
Datalog는 query language의 기반이 되는 foundation을 제공한다. 실제로 일부 시스템에서 datalog를 사용하는데, 그 예로 Cascalog 는 datalog의 구현체로서 Hadoop의 대용량 dataset에 query한다.
Datalog의 data model은 triple-store model과 비슷하지만, predicate(subject, object)로 작성한다. 아래는 Datalog로 어떻게 data를 쓰는지 보여준다.
name(namerica, 'North America').
type(namerica, continent).
name(usa, 'United States').
type(usa, country).
within(usa, namerica).
name(idaho, 'Idaho').
type(idaho, state).
within(idaho, usa).
name(lucy, 'Lucy').
born_in(lucy, idaho).이를 기반으로 Datalog로 표현된 query를 작성해보면 다음과 같다.
within_recursive(Location, Name) :- name(Location, Name). /* Rule 1 */
within_recursive(Location, Name) :- within(Location, Via), /* Rule 2 */
within_recursive(Via, Name).
migrated(Name, BornIn, LivingIn) :- name(Person, Name), /* Rule 3 */
born_in(Person, BornLoc),
within_recursive(BornLoc, BornIn),
lives_in(Person, LivingLoc),
within_recursive(LivingLoc, LivingIn).
?- migrated(Who, 'United States', 'Europe').
/* Who = 'Lucy'. */Cypher나 SPARQL은 SELECT로 바로 query를 하는 반면 datalog는 단계를 나눠 한 번에 조금씩 query를 한다. 먼저 새로운 predicate를 databse에 전달하는 rule을 정의한다. 위 예제에서는 within_recursive와 migrated 를 새로 정의한다. predicate는 데이터나 다른 rule로 부터 파생된다. rule은 재귀함수처럼 다른 rule을 참조할 수 있다. rule에서 대문자로 시작하는 단어는 변수다.
name(Location, Name) 은 변수 Location = namerica 와 Name = 'North America'를 가진 triple name(namerica, 'North America')에 대응된다.
rule이 적용되는 방식은 아래와 같다. (예시 중 하나임)
- database에
name(namerica, 'North America')가 있으면 Rule 1이 적용된다. Rule 1은within_recursive(namerica, 'North America')를 생성하는 것이다. - database에
within(usa, namerica)이 존재하고 이전 step에서within_recursive(namerica, 'North America')이 생성되었으면 Rule 2가 적용된다. Rule 2는within_recursive(usa, 'North America')를 생성하는 것이다. - database에
within(idaho, usa)이 존재하고 이전 step에서within_recursive(usa, 'North America')이 생성되었으면 Rule 2가 한 번 더 적용되고,within_recursive(idaho, 'North America')가 생성된다.
위 과정을 그림으로 표현하면 아래와 같다.
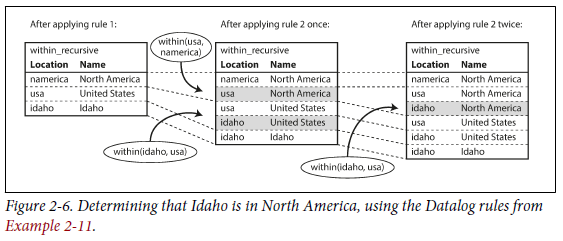
datalog 접근 방식은 이 챕터에서 의논한 다른 언어들과는 다른 사고를 가진다. 하지만 rule이 합쳐질 수 있고, 다른 쿼리에서 재사용 될 수 있기 때문에 강력하다. 단순한 일회성 query에서는 까다로울 수 있지만, 복잡한 데이터인 경우에는 오히려 적합하다.
