
Replication이란, 같은 data가 여러 machine에 복사되어 network로 연결되어 있는 것을 의미한다.
replication을 사용했을 때의 이점
- 사용자와 data를 지리적으로 가깝게 위치하게 하여 latency를 줄인다.
- 특정 part가 fail 되어도, system이 계속 작동할 수 있기 때문에 availability가 증가한다.
- query를 read하기 위한 machine의 수를 늘려서 read throughput을 향상시킨다. -> ?
만약 replicating 한 데이터가 긴 시간동안 변하지 않는다면 모든 node에 data를 copy 해놓기만 하면 replication이 되지만, 데이터가 변하는 경우엔 어려움이 생긴다. 이 챕터에서는 데이터가 변하는 경우에 어떻게 replication을 할 것인지를 배운다. 이를 위한 3가지 알고리즘이 있다. : single-leader, multi-leader, leaderless replication.
Leaders and Followers
-
replica: database의 복사본을 저장하는 각각의 node -
모든 데이터가 모든 replica에 저장되도록 하려면 어떻게 해야 할까?
leader-based replication(=active/passiveormaster-slave replication) : 모든 replica에 대해 모든 write를 적용하는 방법
- replica들중 하나를
leader(master,primary)로 정해서, database에 write하기 위한 request를 leader에게 전달한다. leader는 해당 request를 local storage에 저장한다. - leader를 제외한 replica들을
followers(read replicas,slaves,secondaries,hot standbys)라고 한다. leader가 local storage에 새로운 data를 write 할 때마다, follower들에게replication log혹은change stream을 보낸다. follower들은 그를 바탕으로 (leader에서 처리된 것과 동일한 순서로) 자신들의 local copy를 update 한다. - client는 leader와 followers 아무에게나 read를 요청할 수 있다.
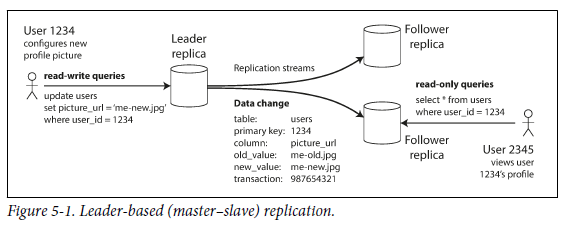
이 방법은 relational database, nonrelational database, network filesystem 등에 널리 사용된다.
Synchronous Versus Asynchronous Replication
- replicate 된 system에서는
synchronous하게 replication이 발생했는지,asynchronous하게 발생했는지가 중요하다.
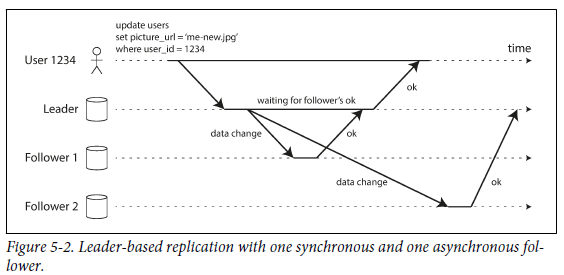
- follower 1으로의 replication은 synchronous하다.
- follower1이 ok를 보낼 때까지 기다리기 때문에 항상 최신 data를 보장할 수 있다.
- leader가 갑자기 fail이 나도 follwer들이 최신 data를 유지하고 있기 때문에 follower를 사용하면 된다.
- follower가 crash 혹은 network fail로 인해 응답을 하지 않아도 leader는 계속해서 기다려야 한다.
- follower 2로의 replication은 asynchronous하다.
- follwer2가 ok를 보내는 것을 기다리지 않는다.
- 상당한 지연이 있을 수 있다. (follower가 failure를 recovering 하고 있거나, node 간의 네트워크에 문제가 있으면 latency가 발생한다.)
- follower 1으로의 replication은 synchronous하다.
semi-synchronous: 실제로는 database에서 하나의 follower는 synchronous하고, 나머지는 asynchronous한 경우가 대부분이다.- synchronous가 unavailable하거나 느려지면 다른 asynchronous follower를 asynchronous로 바꾼다.
- 최소한 2개의 node (asynchronous follower와 leader)에서 최신 data를 유지할 수 있다.
- 주로, leader-based replication은 완전한 asynchronous하게 구성되어 있다.
- 장점 : leader가 fail 나지만 않으면, follower가 조금 뒤쳐져도 무방하다.
- 단점 : leader가 fail 나면, follwer에게 replicate 되지 않은 write들은 모두 손실된다.
Setting Up New Followers
- 새로운 follower들이 생길 때 (replica의 수가 증가하거나, fail난 node를 대체하기 위해), 새로운 follower가 leader의 정확한 복사본을 갖도록 어떻게 보장할까?
- 특정 시점에 leader의 database를 snapshot 한다.
- 새로운 follower node들은 snapshot을 복사한다.
- follower는 leader에게 snapshot을 찍은 이후 발생한 모든 변경사항을 요청한다. (snapshot이 leader의 replication log에 정확한 위치와 연결되어야 한다.)
- follower가 snapshot 이후의 변경 사항을 모두 적용했을 경우
caught up이라고 한다.
- follower를 설정하는 실제 단계는 데이터베이스마다 다른데, 자동화 되어 있을 수도 있고, 관리자가 수동으로 수행해야 할 수도 있다.
Handling Node Outages
목표 : 개별 노드에 오류가 나도 시스템 전체를 계속 실행하고 노드 중단의 영향을 가능한 한 작게 유지하는 것
leader-based replication에서 high availability를 어떻게 달성할까?
Follower failure : Catch-up recovery
- follower는 leader로 부터 받은 데이터 변경 사항을 log 형태로 local disk에 저장하기 때문에, follower가 충돌나거나 재시작 되어도 쉽게 복구될 수 있다.
- 복구 후의 변경 사항은 leader에게 요청하면 해결된다.
Leader failure : Failover
- Failover
- follower 중 하나가 새로운 leader가 되어야한다.
- client는 새로운 leader에 대한 reconfigure를 해야 한다.
- 다른 follower 들은 새로운 leader에게 변경 사항을 수신받아야 한다.
- Failover가 자동으로 이루어지는 단계
- 현재 leader가 fail 났다고 판단
- fail이 나는 원인은 다양하다 : 충돌, 정전, 네트워크 문제 ....
- timeout을 사용하여 fail 여부를 판단함
- 새로운 leader를 선택
- election process (투표 과정)을 통해 결정하거나
controller node에 의해 임명 받음 (->Chpater 9) - 새로운 leader로 가장 제격인 replica는 원래 leader로부터 최신 data를 자주 update 한 node.
- election process (투표 과정)을 통해 결정하거나
- 새로운 leader를 위해 reconfiguring
- 원래 leader가 복구되어도 새로운 leader와 헷갈리지 않도록 해야함.
- 현재 leader가 fail 났다고 판단
- 하지만 Failover는 잘못될 수도 있다.
- 만약 asynchronous replication 방식이라면 이전 leader로 부터 모든 write를 받지 않을 수도 있다. 또한, 이전 leader가 복구되면 새로운 leader와 conflict가 발생할 수도 있다. 이를 위한 solution으로는 이전 leader의 replicate 되지 않은 write를 버리는 것이다.
- client의 durability expectation을 위반할 수도 있음
- database 외부의 다른 storage system을 database 콘텐츠와 조정해야 하는 경우 위험
split brain: 두 개의 node가 동시에 자신이 leader라고 믿는 상황- 두 leader가 write를 accept 하면, conflict를 해결 할 process가 없음
- 한 node가 leader가 2개인 것을 인식하면 shut down 시키는 solution 존재
- fail으로 판단되기까지의 timeout 시간이 길다는 것은 leader의 fail이 복구되는데 오랜 시간이 걸린다는 뜻이다. timeout 시간이 짧으면 불필요하게 failover를 해야 할 수도 있다.
- 만약 asynchronous replication 방식이라면 이전 leader로 부터 모든 write를 받지 않을 수도 있다. 또한, 이전 leader가 복구되면 새로운 leader와 conflict가 발생할 수도 있다. 이를 위한 solution으로는 이전 leader의 replicate 되지 않은 write를 버리는 것이다.
- 이러한 위험성이 따르기 때문에, 자동으로 failover를 하는 것보다는 manually 하는 것을 선호한다.
Implmentation of Replication Logs
leader-based replication은 내부적으로 어떻게 동작할까?
Statement-based replication
- leader는 가장 간단한 방법으로, 모든 write request (statement)를 기록하고 해당 statement log를 follower에게 보낸다. -> 관계형 데이터베이스의 경우 INSERT, UPDATE, DELETE문 형태로 전달되고 수신되고 실행한다.
- 위 방법의 문제점
NOW()또는RAND()와 같은 nondeterministic function을 호출하면 각 replica 마다 다른 값을 생성한다.- statement가 autoincrementing column (자동 증가 열)을 사용하거나 기존 데이터에 의존해야 하는 경우 각 replica에서 동일한 순서로 실행되어야 하는데, 동시에 실행되는 transaction이 여러 개 있는 경우엔 제한이 있다.
- side effect(trigger, sotred procedures, user-define function)를 가진 statement는 각 replica마다 서로 다른 side effect를 발생시킬 수 있다.
Write-ahead log (WAL) shipping
-
log-structured storage engine(SSTables and LSM-Trees)와 B-Tree 모두 log는 데이터베이스에 대한 모든 write를 포함하는 append-only sequence of byte이다. leader는 이 log를 disk에 write 하거나, network를 통해 follower에게 전송한다.
WAL : 트랜잭션을 로그에 일단 기입해 기록을 남기고 특정 데이터가 쌓이면 이를 flush 해 DB의 disk에 DATA BLOCK 형태로 wirte 하는 것
-
WAL에는 disk block에서 변경된 byte에 대한 세부 정보가 포함되기 때문에 replication이 storage engine과 밀접한 연관을 가지게 된다.
- 데이터베이스가 storage 형식을 다른 버전으로 변경하면, leader와 follower가 다른 버전의 database software를 사용할 수 없다.
- replication protocol을 사용하여 follower가 leader보다 최신 software를 사용할 수 있는 경우에는 upgrade를 수행함으로써 follower 중 하나를 새로운 leader로 만드는 solution이 있다.
- 만약 replication protocol이 version 불일치를 허용하지 않으면 downtime이 필요하다.
Logical (row-based) log replication
logical log: 위에서 언급한 위존성을 없애기 위한 solution으로, replication과 storage eingine (physical)에 대한 log format을 서로 다르게 해서 replication log를 storage engine 내부에서 분리할 수 있도록 하는 것이 있다.- 관계형 데이터베이스용 logical log는 row 단위로 데이터베이스 table에 대한 write를 설명하는 record이다.
- inserted row : log에 모든 column의 새 값이 포함
- deleted row : 삭제된 row를 고유하게 식별하기 위한 정보가 포함
- updated row : update 된 row와 모든 column의 새로운 값을 고유하게 식별하는 정보가 포함
- 여러 행을 수정하는 transacntion은 여러 log record를 생성한 다음 transaction이 commit 되었다는 record를 생성
- logical log는 storage engine 내부와 분리되었기 때문에 version 호환성을 더 쉽게 유지할 수 있다.
- leader와 follower에서 완전히 다른 storage engine을 실행할 수 있다.
Trigger-based replication
- 이때까지의 replication 방식은 application code 사용 없이 DBMS에 의해 구현된다.
- 더 많은 flexibility를 원하는 경우엔 application layer로 이동할 수 있다.
- triggers and stored procedures
- trigger를 사용하면 database 시스템에서 데이터 변경이 발생했을 때 자동으로 실행시킬 수 있는 사용자 정의 application code를 등록할 수 있다.
- trigger는 변경 사항을 외부 process가 읽을 수 있도록 분리된 table에 logging 할 수 있고, 외부 process는 필요한 application logic을 적용하고 변경 사항을 다른 system에 replicate 할 수 있다.
- 하지만 overhead 혹은 bug가 발생할 가능성이 높지만, flexibility 면에서는 유용하다.
Problems with Replication Lag
- node 내결함성을 하려는 이유 : replication, scalability, latency
read-scalingarchitecture : 대부분이 read request이고, write가 아주 작은 비율로 구성된 workload는 많은 follower를 만들어서 follower 간 read request를 분산하고, 근처 replica에서 read request를 처리한다.- asynchronous replication에서만 동작
- asynchronous folloser가 뒤쳐져 있는 상태에서 data를 읽으면 inconsistency가 발생할 수도 있지만, database에 write를 멈추고 잠시 기다리면 follower는 leader를 따라잡게 된다 :
eventually inconsistency
- 이번 section에서는 replication lag(지연)이 있을 때 발생할 수 있는 세 가지 사례와 해결방법을 소개한다.
Reading Your Own Writes
-
새로운 data가 제출되었을 때는 leader에게 전송해야 하지만, data를 read 할 때는 follower에 요청해도 된다. (주로 read가 빈번하고, write는 드문 케이스에 적합)
-
asynchronous replication은 사용자가 write를 수행한 직후 data를 본다면 새로운 data가 replica에 반영되지 않았을 수도 있다.
read-after-write consistency: 사용자가 페이지를 reload 했을 때 항상 자신이 제출한 모든 update를 볼수 있음을 보장하지만, 다른 사용자에 대해서는 보장하지 않는다.- 위 방법을 구현하는 기법
- 사용자가 수정한 내용을 읽을 때는 leader에서 읽고, 그 외에는 follower에서 읽는다. 이를 위해서는 실제로 query 하지 않고 무엇이 수정됐는지 알 수 있는 방법이 필요하다.
- application 내 대부분의 내용을 사용자가 편집하는 경우, read-scaling의 이점을 무효화하기 때문에 leader에서 읽을지 말지를 결정하기 위해 다른 기준이 필요하다. ex) 마지막 update 후 1분 동안은 leader에서 모든 읽기를 수행한다.
- client는 가장 최근 write의 timestamp를 기억할 수 있기 때문에 시스템은 사용자 read를 위한 replica가 최소한 해당 timestamp 까지 update를 반영하게 할 수 있다. timestamp는
logical timestamp이거나 실제 시스템 시간일 수 있다. - replica가 여러 datacenter에 분산되어 있으면 복잡도가 증가하기 때문에 leader가 제공해야 하는 모든 request는 leader가 포함된 datacenter로 routing 되어야 한다.
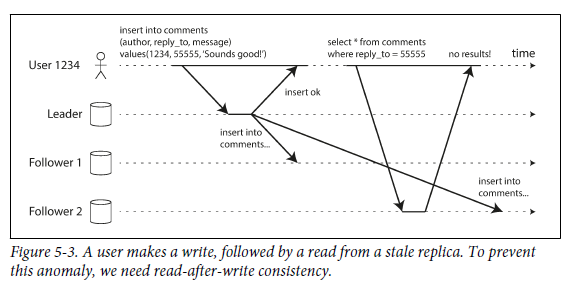
-
사용자가 여러 device로 service에 접근하면,
cross deviceread-after-write consistency를 제공해야 한다.- 사용자의 마지막 update timestamp를 기억해야 하는 방식이 더 어렵기 때문에, centralized 방식으로 메타데이터를 관리해야 한다.
- replica가 여러 datacenter에 분산되어 있는 상황에서는 leader에서 읽어야 하는 접근법은 먼저 사용자 device의 요청을 모두 동일한 datacenter로 routing 해야 한다.
Monotonic Reads
-
asynchronous follower에서 read를 수행할 때
moving backward in time즉, 시간이 거꾸로 흐르는 현상이 일어날 수 있다. (주로 사용자가 각기 다른 replica에서 여러 read를 수행할 때 발생한다.)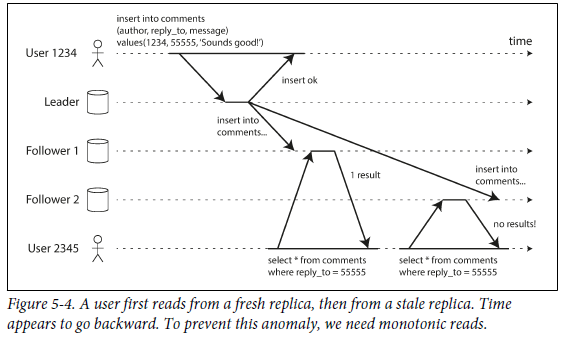
-
monotonic read는 moving backward in time이 발생하지 않음을 보장한다.- strong consistency 보다는 덜하지만, eventual consistency르 더욱 보장할 수 있다.
- 각 사용자의 read가 항상 동일한 replica에서 수행되게 하여 성취할 수 있다.
Consistent Prefix Reads
-
replication lag은 causality를 위반할 수 있다.
-
예를 들어서, 아래 대화를 가정해보자.
A - "B야, 점심 뭐 먹었어?"
B - "로제 떡볶이 먹었어. JMT이더라,,,,"
제 3자의 관점에서 B의 답변은 latency 없이 follower에게 전달되었지만, A의 질문은 긴 replication latency가 있었다면, 제 3자는
B - "로제 떡볶이 먹었어. JMT이더라,,,,"
A - "B야, 점심 뭐 먹었어?"
와 같이 causality를 위반하는 모습을 보게 된다.
-
causality를 방지하기 위해서는 일관된 순서로의 read는 write가 발생한 순서대로 보여져야 한다는
consistent prefix read가 보장되어야 한다. -
주로 분산 database에서 위와 같은 문제가 발생한다. 즉, 사용자가 database에서 read를 수행할 때 예전 상태의 일부와 새로운 상태의 일부를 함께 보게 된다.
-
causality가 있는 write는 동일한 partition에 기록되게끔 하는 solution이 있다.
-
Solutions for Replication Lag
- Replication Lag의 solution은 "replication이 asynchronous하게 발생하지만, synchronous하게 발생하는 척"하는 것이다.
- 혹은
Transaction을 사용해서 application 개발자가 replication 문제를 걱정하지 않고 올바른 작업 수행을 위해 항상 database를 신뢰하도록 하는 것이다. - 하지만 분산 database로 전환됨에 따라 transaction을 포기하고 있다.
- 성능과 가용성 측면에서 너무 비쌈
- scalable system에서는 불가피하게 eventual consistency를 사용해야 한다.
Muti-Leader Replication
- Leader-based replication의 가장 중요한 단점 : 하나의 leader만 존재하며, 모든 write는 leader에게로 간다.
- Replica가 leader에게 connect 하지 못하면 (network interruption 등으로 인해), database에 write 하지 못함.
multi-leaderconfiguration : 각각의 leader가 다른 leader의 follower 처럼 행동
Use cases for Multi-Leader Replication
single datacenter에서 multi-leader는 시스템을 더 복잡하게 만들기 때문에 타당하지 않지만 이 configuration을 사용하기에 합당한 몇 가지 상황이 있다.
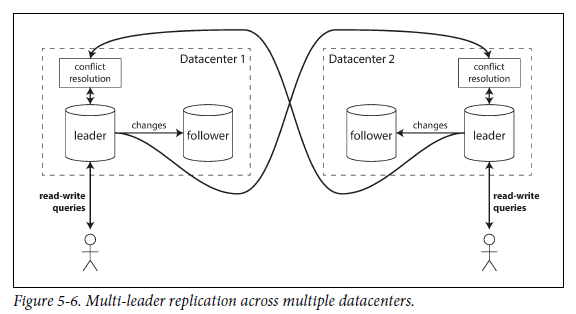
Multi-datacenter operation
-
normal leader-based replication : several datacenter의 상황에서, 오직 하나의 leader만이 허용된다.
-
multi leader configuration : several datacenter의 상황에서, 각 datacenter마다 leade를 둘 수 있다.
이때, datacenter 사이에서 각각의 leader는 자신의 변경 사항을 다른 datacenter로 replicate 한다.
-
single leader VS multi-leader
- Performance
- single-leader : 모든 write는 인터넷을 통해 datacenter로 이동 -> latency 증가 -> 여러 datacenter 두는 의미 x
- multi-leader : 사용자는 network delay 잘 느끼지 못함
- Tolerance of datacenter outages
- single-leader : leader가 fail한 datacenter는 다른 datacenter에 있는 follower를 leader로 만든다.
- multi-leader : leader가 fail한 datacenter가 다시 복구되면 그냥 다른 datacenter들을 catch up한다.
- Tolerance of network problems
- 보통 datacenter 간의 traffic은 public internet으로 가는데, 이건 datacenter 간의 local network 보다 덜 reliable 하다.
- single-leader : datacenter 간에 synchronously 하게 wirte가 이루어지기 때문에 위 문제에 대해 sensitive하다.
- multi-leader : asynchronous replication이기 때문에 일시적인 network가 발생하더라도 큰 문제가 되진 않는다.
- Performance
-
multi-leader configuration은 Tungsten Replicator (MySQL), BDR (PostgreSQL), GoldenGate (Oracle)과 같으 외부 tool을 사용해야 한다.
-
multi-leader의 단점 : 서로 다른 2개의 datacenter에 의해 같은 data가 동시에 modify 될 수 있다.
Clients with offline operation
- internet이 끊긴 상황에서도 작업을 계속할 수 있는 상황에서도 multi-leader replication이 적절하다.
- 휴대폰, 노트북 등의 device는 local database가 leader 역할을 하고, 다른 device들과는 asynchronous multi-leader replication process를 갖는다.
Collaborative editing
-
Real-time collaborative editingapplication : 여러 사람들이 동시에 문서를 수정할 수 있는 applicationex) Etherpad, Google Docs ..
-
editing conflict를 방지하기 위해, 사용자가 문서를 수정하기 전에, 문서를 lock한다.
- 다른 사람이 수정하고 있는 문서에 수정을 하고 싶을 땐, 그 사람이 변경 사항을 commit 하고 lock을 풀 때까지 기다려야 한다.
Handling Write Conflicts
write conflict에 대한 solution
Synchronous versus asynchronous conflict detection
- single-leader databse에서, second writer는 block 당하던지, first writer가 완료할 때까지 기다리던지, 자신의 write를 중단하던지, write를 재시도한다.
- multi-leader 에서는, 두 write 모두 성공된 후 한참 있다가 asynchronously 하게 conflict가 감지된다.
- conflict detection을 synchronous하게 만들어보자.
- 모든 replica들이 write에 성공했다고 응답을 받을 때까지 기다린다.
- 하지만 이것은, multi-leader replication의 장점 즉, 각각의 replica가 독립적으로 수행된다는 것에 위배된다.
- conflict detection을 synchronous하게 만들어보자.
Conflict advoidance
-
특정 record에 대한 모든 wirte가 동일한 leader에게 가도록 보장해서 conflict 자체를 피한다.
-
datacenter에 fail이 발생하거나, 사용자가 다른 위치로 이동해서 다른 datacenter에 접근한 경우, designated leader for a record를 변경해야 한다.
-> conflict avoidance가 깨지기 때문에, 다른 leader에 동시에 write 되는 상황에 대한 solution이 필요하다.
Converging toward a consistent state
- multi-leader configuration에서는, write에 순서가 별도로 있지 않기 때문에 어떤 값이 final value가 될 지 모른다.
- conflict를
convergent(수렴)하는 방식으로 해결해야 한다. = 모든 변경 사항이 replicate 되었을 때 모든 replica가 동일한 최종 값에 도달해야 한다.- write에 ID(timestamp, randon number, UUID, hash 등)를 부여한다. -> data 손실 위험
- replica에 ID를 부여해서 가장 높은 number를 가진 replica에 적용된 write를 최종 선발한다. -> data 손실 위험
- value를 합친다.
- 모든 정보를 기록하는 별도의 data structure에 conflict를 기록하고, 나중에 conflict를 해결하는 application code를 작성한다.
Custom conflict resolution logic
- conflict를 해결하는 방법은 application에 따라 다르다.
- 대부분의 multi-leader replication tool을 사용하면 application code로 conflict를 해결한다.
- 이 code는 on read / on write에서 실행할 수 있다.
On write: database system이 복제된 변경사항 log에서 conflict를 발견하면 바로 conflict handler를 부르며, 이 conflict handler는 background process에서 실행된다.On read: conflict가 감지되면, 모든 conflict된 write는 저장된다. 다음에 data가 읽히면 여러 version의 data가 return 되고, application은 사용자에게 message를 표시하거나 confict를 자동으로 해결해서 database에 결과를 쓴다.
- conflict resolution은 주로 개별 row 또는 document 수준에서 적용된다.
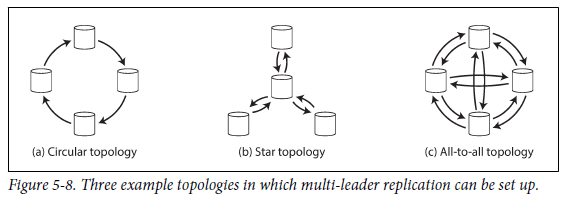
Multi-Leader Replication Topologies
-
replication topology: write가 한 노드에서 다른 노드로 전파되는 communication path -
2개 이상의 leader를 사용하는 경우의 topology
-
star topology와 all-to-all topology의 경우, 무한 replicate loop를 방지하기 위해 각 node에 고유 식별자가 부여되며, replication log에는 각 write가 통과한 node들의 식별자가 tag로 저장된다.
-> 자신의 식별자가 tag된 변경사항을 받으면, 해당 변경 사항은 무시함.
-
circular topology와 star topology의 경우, 하나의 node가 실패하면 다른 node간의 replication message 흐름도 방해한다는 단점이 있다. 이런 경우, 사용자가 수동으로 reconfiguration을 수행해야 한다.
-
-
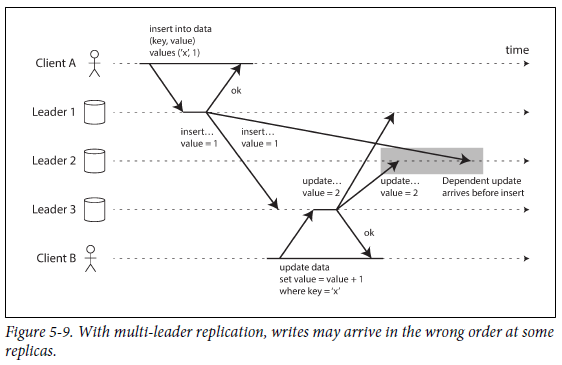
all-to-all topology의 경우, network link가 다른 것들보다 더 빠를 수도 있기 때문에 아래 그림처럼 다른 메세지를 추월할 수도 있다.
update는 이전 insert에 따라 값이 달라지므로, insert를 먼저 처리한 다음 update를 처리해야 한다. -> timstamp 만으로 해결할 수 없는게, 각 clock이 충분히 동기화 되었다고 보기 힘들기 때문이다.
-
-
위에서 언급한 문제를 해결하기 위해
version vector가 사용된다. -
하지만, 많은 multi-leader replication system에서 conflict detection 기술들은 완벽하게 구현되지 않기 때문에 조심해야 한다.
Leaderless Replication
어떤 data storage system은 leader 개념을 버리고, replica들이 client로부터 write를 직접 받게 하는 방법을 사용한다. 이런 종류의 database를 Dynamo-style이라고 하며, Riak, Cassandra, Voldemort 등이 이를 기반으로 한다. leaderless에서는, client 혹은 coordinate node가 몇몇 replica에게 write를 직접 보낸다. 하지만, wirte의 순서를 강제할 수는 없다.
Writing to the Database When a Node Is Down
-
leaderless에서는 failover가 존재하지 않는다.
-
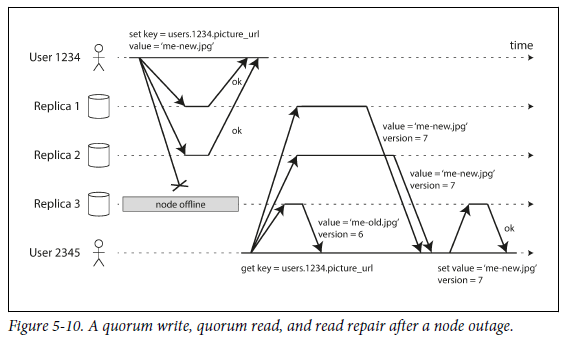
위 상황에서, user1234가 write를 전송했고, replica 3이 이에 대해 응답을 하지 못했다. 하지만, user1234는 replica 3의 응답이 오지 않았다는 것을 무시한다. replica 3이 online이 된 후에 user 2345가 read 요청을 했다. 이때, read 요청을 모든 replica들에게 concurrent하게 전송하면 replica 1,2는 최신 값을 반환하지만 replica 3은
stalevalue를 반환한다. 여기에 version number ("Detecting Concurrent Writes" 184p) 를 사용해서 어떤 값이 최신 값인지 결정한다.
Read repair and anti-entropy
fail 혹은 offline인 node가 복구되었을 때, 어떻게 catch up 할 것인가?
- Dynamo-style datastore에는 2가지 메커니즘이 있다.
- Read repair
- 위에서 언급했던 것 처럼, version number를 사용하여 반환 받은 값들을 비교하여 어떤 값이 new value인지 확인한다.
- Anti-entropy process
- 일부 datastore는 background process를 두고 replica 간 data 차이를 실시간으로 찾아서 누락된 data를 catch up한다.
anti-entropy process는 특정 순서로 write를 복사하지 않기 때문에, data가 복사되기까지 delay가 있을 수 있다.번역본 책에는 "이 안티 엔트로피 처리는 특정 순서로 쓰기를 복사하기 때문에"라고 해석되어 있는데, 원문을 보면 "this anti-entropy process does not copy writes in any particular order"라고 되어 있다. 다시 말해서 특정 순서로 write를 복사하지 않는다는 것이 맞음.
- 일부 datastore는 background process를 두고 replica 간 data 차이를 실시간으로 찾아서 누락된 data를 catch up한다.
- Read repair
- 모든 시스템이 이 두가지 방법을 사용하는 것은 아니다. Voldemort는
anti-entropy process를 가지지 않는다.
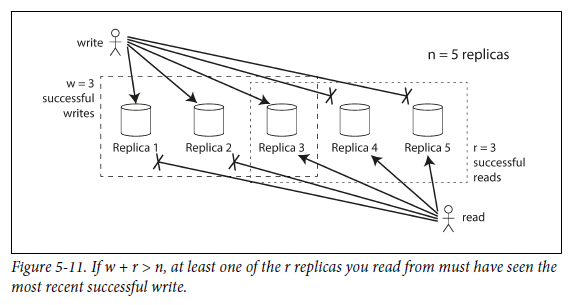
Quorums for reading and writing
Figure 5-10에서는 3개중 2개가 write를 허용했는데, 만약에 단 하나만이 허용하면 어떻게 될까?
-
일반화
- n = # of replica
- w = # of write가 성공된 replica
- r = # of query를 날린 replica
- w+r>n이면 최신 값을 얻을 수 있다.
quorum: r과 w를 따르는 read와 write 즉, r과 w는 valid한 read와 write를 위해 필요한 최소 투표수이다.- 주로 n을 홀수로 설정하고, w와 r은 반올림 한 (n+1)/2 로 설정한다.
- write가 적고 read가 많은 workload에서는 w와 n은 같게하고 r를 1로 하면 read를 빠르게 할 수 있지만 하나의 node가 fail 하면 모든 database write가 실패한다는 단점이 있다.
-
w+r>n은 다음과 같은 unavailable node를 tolerate 할 수 있다.
-
w<n, 한 node가 unavailable 해도 write를 처리할 수 있다.
-
r<n, 한 node가 unavailable 해도, read를 처리할 수 있다.
-
n=3, w=2, r=2, unavailable한 node 하나를 tolerate 한다.
-
n=5, w=3, r=3, unavailable한 node 두개를 tolerate 한다.
-
Limitations of Quorum Consistency
- quorum은 다수일 필요 없이, read와 write 동작에서 사용하는 node 셋 중 적어도 하나의 node만 겹치면 된다.
- w+r<=n이 되게끔 설정할 수도 있으며, 이 경우에는 read와 write를 계속 n개의 node로 전송하지만, 성공에 필요한 성공 응답의 수는 더 적다.
- w와 r이 작을 수록 최신 값을 가진 노드가 읽을 노드에 포함되지 않을 가능성이 높기 때문에 오래된 값을 읽을 확률이 높다.
- w+r>n인 경우 오래된 값을 반환하는 edge case
- sloppy quorum (뒤에 나옴)을 사용하면, w개의 write는 r개의 read와 다른 노드에서 수행될 수 있다.
- 만약 2개의 write가 concurrent하게 발생하면, 어떤 순서로 발생했는지 모르기 때문에 두 write를 concurrent하게 merge하면 된다. (timestamp로 winner를 결정하면 clock skew 때문에 손실이 발생할 수 있다.)
- write와 read가 동시에 발생하면, read의 반환값으로 old value를 반환할 것인지 new value를 반환할 것인지 미리 결정해야 한다.
- write가 일부 replica에서만 성공해서 w보다 더 적다면 성공한 replica는 roll back하지 않기 때문에 write가 실패했다고 보고되었을 때 후속 read해서 해당 write 값이 반환될 수도 있고, 아닐 수도 있다.
- 새로운 값을 전달하는 node가 실패하면, 예전 값을 가진 다른 replica에서 해당 data가 복원되기 때문에 새로운 값을 저장한 replica의 수가 w보다 낮아져서 quorum 조건이 깨진다.
- 모든 write와 read가 올바르게 수행되어도, 시점 문제로 인해 오래된 값을 반환하는 edge case가 발생할 수 있다.
- 따라서 quorum이 read가 최신 값을 반환한다고 반드시 보장할 수는 없다. - 주로 replication lag 상황에서
Monitoring staleness
- 운영 관점에서, 사용자의 database가 최신 값을 반환하고 있는지 모니터링 하는 것은 중요하다.
- leader-based replication에서, database는 일반적으로 replication lag에 대한 지표를 보여준다 : leader의 위치에서 follower의 위치를 빼면 복제 지연량을 측정할 수 있다.
- leaderless replication에서, write가 적용되는 순서가 없기 때문에 monitoring을 하는 것이 어렵다. 또한, read repair만 사용한다면, 자주 read 되지 않는 값은 엄청 오래된 값일 수 있다.
Sloppy Quorums and Hinted Handoff
-
적절한 quorum이 설정된 database는 failover 필요 없이 개별 node의 failure를 허용할 수 있고, 개별 node가 느려지는 것을 허용한다. (모든 n개의 node가 응답하지 않아도, w나 r개 node가 응답하면 반환값을 받을 수 있음)
-> leaderless가 엄청 좋은 것 처럼 보인다. (high availability, low latency, occasional stale read 허용)
-
하지만 quorum은 fault-tolerant가 없다.
교수님이 말씀하시길 "없다"라고 표현하는 것은 너무 강력하고 "없을 수 있다"라고 표현하는 것이 적합하다고 함.- network interruption은 다수의 database와 client 간의 연결을 끊기게 할 수 있기 때문에 응답 가능한 node가 w나 r보다 적을 가능성이 있어서 quorum을 충족할 수 없다.
- 노드가 n개 이상인 대규모 cluster에서, network interruption이 생겼을 때 client는 quorum에 들어가지 않는 노드에 연결될 수도 있는데, 여기서 tradeoff가 발생한다.
- w 또는 r node의 quorum를 만족하지 않는 모든 request에 error를 반환하는 것이 나을까?
- 일단 write를 받아들이고 연결할 수 있는 node에 기록을 할까? =
sloppy quorum
sloppy quorum: read와 write는 값을 위해 지정된 n개의 "home" node에 없는 node에 저장- write availability를 높이는데 유용
- 단지 지속성에 대한 보장으로 데이터가 w 노드 어딘가에는 저장되며, r 노드의 read가 저장된 데이터를 본다는 보장은 없다.
hinted handoff: network interruption이 고쳐지면, 한 노드가 다른 노드 ("home" node) 를 위해 일시적으로 저장한 모든 write를 해당 "home" node로 전송
Multi-datacenter operation
-
leaderless replication은 concurrent write, network interruption, latency spike들의 충돌을 허용하기 때문에 multi-datacenter operation에 용이하다.
-
Cassandra와 Voldemort는 multi-datacenter를 normal leaderless model로 지원한다.
-
모든 datacenter의 노드를 포함한 n개의 replica의 개수를 지정할 수 있다.
-
사용자가 요청한 write는 datacenter에 상관없이 모든 replica로 전송된다.
-> client는 로컬 datacenter 내의 node quorum에서 승인을 기다리므로 datacenter 간 link의 지연 및 중단에 영향을 받지 않는다.
-
-
Riak
-
client와 database node 간의 모든 통신을 하나의 datacenter에 local로 유지한다.
-> n = 하나의 datacenter 내의 replica 수
-
database cluster 간의 cross-datacenter replication은 background에서 asynchronously하게 발생한다.
-
Detecting Concurrent Writes
-
Dynamo-style databse는 같은 key에 대해서 여러명의 client가 concurrent하게 write 하는 것을 허용한다.
-
다른 node에서 다른 순서로 event가 발생하기 때문에 문제가 됨.
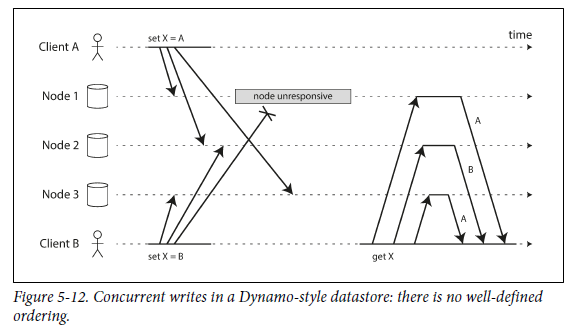
Node 2와 Node 3의 final X 값이 서로 다름
-> 각 replica들은 final value를 converge(수렴) 해야 함.
-
Last write wins (discarding "concurrent writes")
-
각 replica은 가장 "최신" 값만 저장하고 "이전" 값을 덮어쓰거나 삭제할 수 있도록 허용한다고 선언한 후, 어떤 write가 더 최신 것인지 명확하게 결정.
-
하지만 client가 write를 요청할 때 다른 client에 대한 지식이 없기 때문에 어떤 요청이 먼저 발생한건지 모름. 즉, "최신"이라는 것이 좀 애해모호 함.
-
이를 위해 임의의 순서를 정함 :
last write wins(LWW)last write wins(LWW) : timstamp를 붙여서, 가장 큰 timstamp를 가진 write를 적용하고, 나머지는 버림.- 하지만, caching과 같이 write 가 손실되는 경우가 있음. 이런 경우에는 LWW는 적합하지 않음
-
The "happens-before" relationship and concurrency
- 두 operation이 다른 operation 보다 먼저 발생하지 않을 때 concurrent하게 발생한다고 할 수 있다.
- 2개의 operation이 있을 때 발생할 수 있는 경우
- B 전에 A 발생
- A 전에 B 발생
- A와 B 동시 발생
- 2개의 operation이 있을 때 발생할 수 있는 경우
- 분산시스템에서는 clock이 서로 다를 수 있기 때문에 정확히 같은 시간에 발생해야 concurrent 하다고 말할 수 있는 것은 아니다.
Capturing the happens-before relationship
-
두 operation이 cocurrent 한 지 아닌지를 결정하는 algorithm을 살펴보자 -> 먼소리임
-
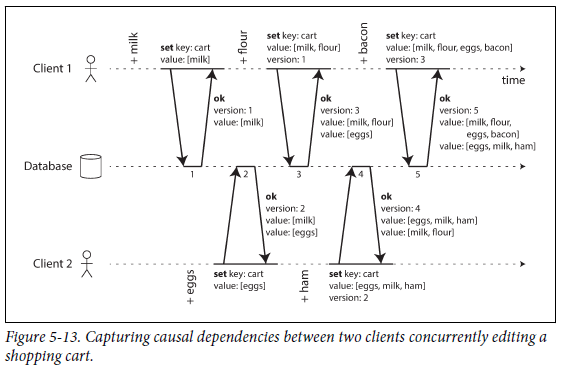
server는 모든 key에 대해 version number를 기록하는데, key가 쓰여질 때마다 number를 증가시킨다.
-
client가 key를 읽을 때 server는 최신 버전과 덮어쓰지 않은 모든 value를 반환한다.
-
client가 key를 쓸 때 이전 read version number를 반환하고, 이전 read에서 받은 모든 값을 merge 해야 한다.
-
server가 특정 버전의 write를 받으면 해당 값으로 overwrite 한다.
-
example
-
-
즉, 이전 read의 version number를 포함하여, write의 기반이 되는 이전 상태를 알려준다.
-
하지만 version number를 포함하지 않고 write를 하면 다른 모든 write와 concurrent하게 수행되무로 아무것도 overwrite 하지 않고 후속 read 중 하나로 반환된다.
Merging concurrently written values
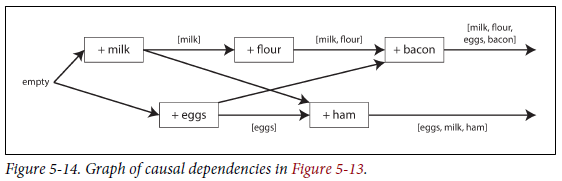
- 이 알고리즘은 data가 자동으로 삭제되지 않도록 하지만 여러 작업이 동시에 발생하면 나중에 동시에 기록된 값(
siblings)을 merge해서 정리해야 한다. - 그림 5-14에서 마지막 값 [milk, flour, eggs, bacon]과 [eggs, milk,ham]에서 [milk, eggs]가 두 번 나타났으므로 [milk, flour, eggs, bacon, ham]으로 merge 한다.
- 이 때, 삭제되어야 하는 값의 version number에 별도의 marker(
tombstone)를 남겨야 한다. - mergin sibling은 복잡하고 에러를 일으키기 쉽다.
Version vectors
- 그림 5-13과 같은 예제와 달리 replica가 여러 개이면서 leader가 없는 상황에서는, replica마다 version number를 사용한다.
- 각 replica는 자신의 version number를 증가시키고 다른 replica에서 본 version number도 추적한다. 이러한 version number의 모음을
version vector라고 부른다. - Riak 에서는
dotted version vector라는 것을 사용한다. - version vector는 databse가 overwrite와 concurrent write를 구별할 때 사용된다.
- 또한 한 replica에서 안전하게 읽고 나중에 다른 replica에서 write 하여 sibling이 올바르게 병합되는 한 data는 손실되지 않도록 보장한다.
- 각 replica는 자신의 version number를 증가시키고 다른 replica에서 본 version number도 추적한다. 이러한 version number의 모음을
