

이번 chapter에서는 database가 data를 저장하는 방법과 data를 요청했을 때 data를 찾는 방법을 배운다.
개발자는 data storage engine를 직접 구현하지 않고 선택하여 쓴다. 자신이 개발하려는 application에 맞는 engine을 선택하려면 storage engine이 어떻게 작동하는지 대략적인 지식이 있어야 한다. 예를 들어서, transaction workload에 최적화 된 engine과 analytics에 최적화 된 engine에는 큰 차이가 있다.
가장 먼저, RDB와 NoSQL 같은 친숙한 데이터베이스에 대한 storage engine에 대해서 소개를 한 후, log-structured storage engine과 page-oriented storage engine 두가지에 대해 살펴본다.
Data Structures That Power Your Database
- 많은 database들은 내부적으로 append-only data file인
log를 사용한다.- log는 append-only sequence record이다.
- human-readble 하지 않으며, binary 일 수도 있다.
- 다른 프로그램이 읽을 수 있도록 되어있다.
- database에서 특정 key를 효율적으로 찾으려면
index라고 하는 data structure가 필요하다.- index는 부가적인 metadata를 둬서 원하는 데이터를 효율적으로 찾게 하고, signpost 역할을 한다.
- 몇가지 다른 방법으로 같은 data를 찾으려고 하는 경우, data의 다른 부분에 대해 여러 개의 다른 index가 필요할 수 있다.
- index는 primary data에서 파생된 additional structure이다. index는 데이터베이스의 내용에는 영향을 주지 않는데, 쿼리를 수행할 때 이 additional structure를 유지하면서 write overhead가 발생한다. 왜냐하면 data가 write 될 때 index도 같이 update 돼야 하기 때문이다. 즉, read 속도는 증가하지만, write 속도는 오히려 감소한다. -> 개발자는 application의 query 패턴을 찾아서 그에 맞는 index를 선택해야 함.
Hash Indexes
-
Hash map은 key-value data를 구현할 때 사용된다. inmemory data structure에서 쓰이는 hash map을 disk에 있는 data의 index로 쓰는 방법은 다음과 같다.
-
data storage는 간단하게 file을 추가하는 것으로만 구성된다고 하자. key를 data file의 byte offset에 맵핑시켜서 in-memory hash map을 구성한다. 파일에 새로운 key-value 쌍을 추가할 때마다 hash map을 update하여 byte offset을 update 해줘야 한다. value를 찾으려면 data file에서 byte offset에 있는 값을 위치로 하여 읽으면 된다.
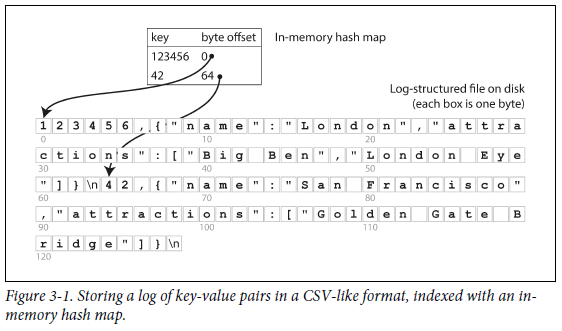
-
이런 storage engine 방식은 각 key의 value가 자주 update 되는 상황에서 적합하다.
-
value가 자주 update 됨에 따라 file을 계속 추가하기만 하면 disk의 공간이 부족해진다는 문제가 발생한다.
-
-
disk 공간 부족을 방지하기 위해 특정 크기의 segment로 log를 분할하는 방법을 사용한다.
-
특정 크기에 도달하면 segment를 닫고 새 sement file에 subsequent write를 수행한다. 그 후, segment를 압축하는데, 여기서 압축이란 아래 그림처럼 log에서 중복된 key를 버리고 각 키에 대한 최신 update만 유지하는 것이다.
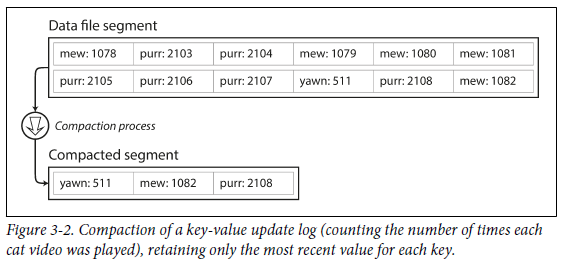
-
압축을 수행하면서 동시에 여러 segment를 병합할 수도 있다. 병합된 segment는 새 파일에 작성된다. 고정된 segment의 병합 및 압축은 background thread에서 실행될 수 있기 때문에 수행 도중 read/write 요청이 들어오더라도 이전 segment를 사용하여 정상적으로 처리가능하다. 수행이 완료되면 새로 병합된 segment를 사용하고, 이전 segment는 삭제한다.
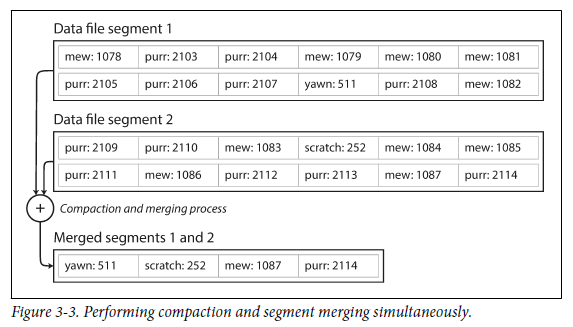
-
-
이 방식을 구현하는데 고려해야 할 문제들이 있다.
- File format : CSV 파일 보다는 문자열의 길이를 바이트 단위로 인코딩하고 그 다음 raw string이 따르는 binary format이 더 빠르고 간단하다.
- Deleting records : key와 관련 value들을 삭제하려면 data file에 special deletion record를 추가해야 한다. log segment가 병합되어 있는 경우엔 tombstone이 병합된 프로세스에게 삭제 된 key에 대한 이전 value를 삭제하라고 지시한다.
- Crash recovery : 데이터베이스가 재시작 되면 전체 segment file을 처음부터 끝까지 읽으면서 가장 최근 value의 offset을 기록함으로써 hash map을 복원해야 하는데, segment file이 크면 이 작업이 오래 걸린다. 이를 위해 disk의 각 segment hash map에 snapshot을 저장하여 복구 속도를 높인다.
- Partially written records : database는 log에 record를 기록하다가 충돌이 일어날 수도 있다. 이럴 땐 Bitcask file에 포함된 checksum을 사용하여 log의 손상된 부분을 감지한다.
- Concurrency control : write는 strict한 순서를 가지고 수행되기 때문에 일반적으로 하나의 write thread만을 사용한다. data file segment는 append-only이고 immutable 하기 때문에 여러 thread로 동시에 읽는 것은 가능하다.
-
append-only의 장점
- segment를 append하고 merge하는 것은 순차적이기 때문에 random으로 write를 하는 것보다 빠르다.
- appen-only이고 immutable 하면 concurrency 와 crash recovery 면에서 편리해진다.
- 오래된 segment를 merge하면 시간이 지나면서 data file이 조각화되는 문제를 피할 수 있다.
-
hash table의 단점
- hash table은 memory에 맞아햐 하므로 key가 많은 경우엔 적합하지 않다.
- range query가 효율적이지 않다.
- range query란, 상한과 하한 사이에 있는 모든 record를 검색하는 database query이다.
SSTables and LSM-Trees
-
SST (Sorted String Table): segment file의 key-value 쌍을 key를 기준으로 정렬 (각 key는 merge 된 segment file 내에서 한 번만 나타나야 한다.) -
SST는 Hash index를 가진 segment file 보다 몇 가지 장점을 가진다.
-
가용 메모리보다 file이 더 크더라도 segment를 merge하는 것이 더 간단하고 효율적이다. (merge sort 알고리즘과 같은 방식을 사용한다. 아래 그림에서 숫자를 따라가면서 보면 잘 이해될 것이다.)

-
file에서 특정 key를 찾기 위해 메모리에 모든 key의 index를 저장하고 있을 필요가 없다. (key를 기준으로 정렬되어 있으므로, 해당 메모리에 저장되어 있지 않은 key를 찾으려면 그 key보다 사전순으로 앞에 있는 key의 offset으로 이동해서 찾으면 된다.) 하지만 일부 key는 저장 할 필요가 있다.
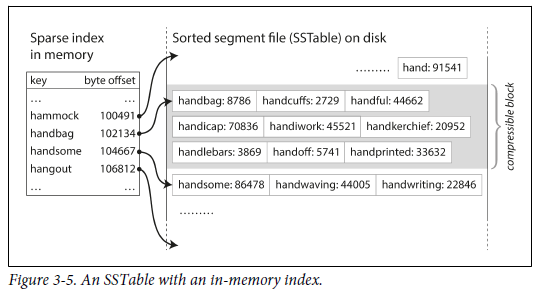
-
read request의 범위 내에서 여러 레코드들을 block 으로 group화하고, disk에 쓰기 전에 압축할 수 있다. index의 각 entry는 block의 시작 위치를 가르킨다. 이런 과정을 통해 디스크 공간을 절약할 수 있고, I/O bandwidth 사용도 줄일 수 있다.
-
Constructing and maintaining SSTables
- disk에 sorted structure를 유지하는 것은 가능한데, 이것보다 메모리에 유지하는 것이 훨씬 쉽다.
- red-black tree나 AVL tree와 같은 data structure를 사용하면 어떤 순서로 key 를 insert 할 수 있고, 정렬된 순서로 해당 key를 다시 읽을 수 있다.
- 이를 위해 아래와 같은 작업이 필요하다.
- write가 들어오면 in-memory balaced tree data structure에 추가한다. 이런 in-memory tree를
memtable이라고 한다. - memtable이 어떤 임계치보다 커지면, SST file로 disk에 기록한다.
- read request를 하려면, memtable -> disk 상의 가장 최신 segment -> 그 다음 최신 segment -> ... 순서로 key를 찾는다.
- 가끔 background에서 merging and compaction process를 수행한다.
- write가 들어오면 in-memory balaced tree data structure에 추가한다. 이런 in-memory tree를
- 만약 DB가 고장나면, disk에 기록되지 않고 memtable에 있는 write들이 손실된다.
- 이를 해결하기 위해 write 때마다 분리된 log를 disk에 저장해야 한다. memtable을 SST로 기록하면 이 log는 버릴 수 있다.
Making an LSM-tree out of SSTables
LSM-tree: Log-Structured Merge-Tree- 정렬된 file merging과 compaction 원리를 기반으로 하는 storage engine을 LSM storage engine이라고 부른다.
Lucene은 Elasticsearch나 Solr에서 사용하는 full text search engine이다. Lucene은 term dictionary를 저장하기 위해 비슷한 방법을 사용한다.
search query에서 단어가 주어지면, 그 단어가 적힌 모든 document (web page ... )를 찾는다. 이를 위해서 key는 word(term), value는 word를 내포한 모든 document의 ID list (
posting list)로 정한다.
Performance optimizations
-
LSM tree algorithm은 database에 존재하지 않는 key를 찾는 경우에 느리다는 단점이 있다. memtable 부터 가장 오래된 segment까지 뒤져야 하기 때문이다.
- 이를 위해
Bloom filter를 추가적으로 사용한다. 이것을 사용하면, key가 database에 존재하지 않을 때 알려준다.
- 이를 위해
-
SST를 compact 하고 merge하는 순서와 타이밍을 결정하는 전략
size-tiered와leveled compaction을 사용.- size-tiered compaction : 더 최신이고 작은 SST를 더 오래되고 큰 SST에 이어서 merge한다.
- leveled compaction : key range를 더 작은 SST로 나눈고 오래된 data는 개별 level로 이동하기 때문에 compaction을 점진적으로 진행하여 disk 공간을 덜 사용한다.
-
LSM tree의 장점 (LSM tree의 기본 개념은 background에서 cascade하게 SST를 지속적으로 merge하는 것)
-
dataset이 가용 메모리보다 훨씬 크더라도 효과적
-
data가 정렬된 순서로 저장돼 있으면 range query가 효과적임
-
높은 write throughput 보장
-
B-Trees
-
B-Tree는 가장 보편적으로 쓰이는 indexing structure이다.
- 많은 relational database와 nonrelational database에서 standard index implementation으로 B-Tree를 사용한다.
-
SST처럼 key를 기준으로 정렬된 key-value쌍을 가지기 때문에 key-value 검색과 range query에서 효율적이다.
-
log structured index는 database를 variable size를 가진 segment로 나누고 항상 sequential하게 segment를 기록한다. 하지만, B-Tree는 4KB의 고정된 크기 block이나 page로 나누고 한 번에 하나의 페이지에 write/read를 한다.
-
B-Tree index에서 key를 검색
- 아래 그림처럼 각 page는 address나 location를 이용해서 식별되며, 하나의 page가 다른 page를 참조할 수 있다. ref 사이의 key들은 해당 range boundary를 나타낸다. (아래 그림에서 긴 배열이 한 page를 의미한다.)
- 한 page는 B-Tree의
root로 지정되기 때문에 index에서 key를 찾으려면 root에서 시작해야 한다. 최종적으로는leaf page를 포함하는 page에 도달한다. 이 leaf page는 각 key의 value를 포함하거나 값을 찾을 수 있는 page의 reference를 포함한다. - B-tree의 한 page에서 하위 page를 참조하는 수를
branching factor라고 한다. 보통 한 page의 branching factor는 수백 개이다. - B-tree에서 특정 key의 value를 update 하고 싶으면
- 해당 key를 포함하는 leaf page를 찾는다.
- leaf page에서 value를 바꾼 다음 page를 disk에 다시 기록한다.
- B-tree에서 특정 key를 추가하려면
- 해당 key를 포함하는 범위의 page를 찾는다.
- 해당 page에 keu와 value를 추가한다. (추가 할 공간이 없으면 해당 page를 반으로 나눈다.)
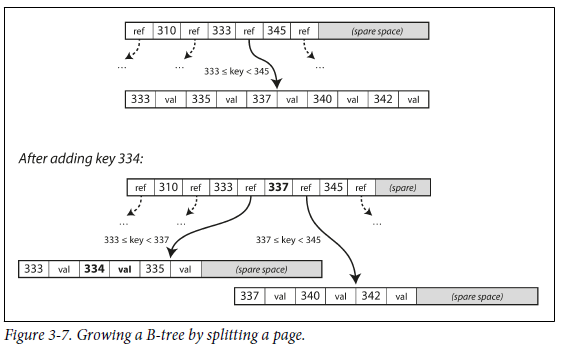
- B-tree의 알고리즘은
balance를 유지한다. n개의 key를 갖는 B-tree의 depth는 항상 O(logn)이다. 보통 database의 B-tree depth는 3이나 4이면 충분하다.
Making B-trees reliable
- B-tree의 기본적인 write는 새로운 data를 disk의 page에 덮어쓰는 것이다. 즉, page를 가르키는 모든 reference는 여전히 유지된다.
- 그런데 만약 overwrite 하는 과정에서 database가 고장난다면 index가 훼손되어
orphan page(어떤 page와도 부모 관계가 없는 page)가 발생할 수 있다. - 이를 위해
write-ahead log 혹은 redo log를 추가해서 스스로 복구되게 끔 한다.- write-ahead log file은 append-only로, tree page에 변경된 내용을 적용하기 전에 모든 B-Tree의 변경 사항을 기록하는 파일이다.
- 만약, multiple thread가 동시에 B-tree에 access 하면 concurrency 처리를 해줘야 한다.
latch (lightweight lock)으로 해결할 수 있다.
- 그런데 만약 overwrite 하는 과정에서 database가 고장난다면 index가 훼손되어
B-tree optimizations
-
page를 overwrite하고, WAL을 유지하는 대신 copy-on-write scheme을 사용한다.
-
전체 key를 저장하지 않고 key를 축약해서 저장한다. 이때 tree 내부 page에서 key range 사이의 경계에 대한 충분한 정보를 제공할 수 있는 정도이면 된다. 혹은 branching factor 수를 늘려서 tree의 depth를 낮춘다.
-
leaf page를 disk 상에 연속된 순서로 나타날 수 있게 배치한다. 하지만 tree가 커지면 순서를 유지하기 어렵다.
-
leaf page에서 각 양쪽 sibling page에 대한 refernce를 가지는 등의 pointer를 추가한다. -> 상위 page로 이동하지 않고 순서대로 스캔 가능
-
fractal tree: log structure 개념을 일부 도입한 B-tree 변형
Comparing B-Trees and LSM-Trees
- write 속도 : B-Tree < LSM-Tree & read 속도 : B-Tree > LSM-Tree
- LSM-Tree에서는 각 compaction 단계에 있는 여러 가지 data structure와 SST를 확인해야 하기 때문이다.
- 실제로 측정할 때는 workload를 가지고 테스트하는 것이 정확하다.
- LSM-Tree의 장점 (B-Tree의 단점)
- B-Tree index는 모든 data piece를 2번(+page를 분할해야 할 경우엔 총 3번) 기록해야 한다. (write 전 log에서 한 번, tree page에서 한 번) 그리고 page가 몇 byte만 바뀌어도 한 번에 전체 페이지를 write 해야 할 수도 있다 :
write amplification(<- 이것은 SSD의 수명과 밀접한 연관) - SSTable에서도 write amplification이 있다.
- 순서대로 compact된 SST에 write를 하기 때문에 write throughput이 B-Tree 보다 높다.
- 압축률이 좋기 때문에 B-Tree 보다 disk에 더 적은 file을 생성한다.
- B-Tree는 page를 나누거나 row가 기존 page에 맞지 않을 때 생긴 일부 쓰지 않는 disk 공간이 생긴다.
- LSM-Tree는 주기적으로 fraction을 없애기 위해 SST를 update 한다.
- 낮은 write amplification과 fragmentation 감소는 SSD의 경우 많은 이점이 있다.
- B-Tree index는 모든 data piece를 2번(+page를 분할해야 할 경우엔 총 3번) 기록해야 한다. (write 전 log에서 한 번, tree page에서 한 번) 그리고 page가 몇 byte만 바뀌어도 한 번에 전체 페이지를 write 해야 할 수도 있다 :
- LSM-Tree의 단점 (B-Tree의 장점)
- disk의 resource 한계 때문에 compaction 과정을 수행할 때 read/write 성능에 영향을 미칠 수도 있다.
- 이 경우, 1장에서 설명했던 higher-percentiles의 query response time이 꽤 길게 측정된다.
- database가 커질 수록 compaction 과정의 높은 write throughput에서 write bandwidth가 부족할 수 있다.
- disk의 write bandwidth는 유한한데, initial write( memtable에서 disk로의 logging과 flushing)와 compaction thread가 이 bandwidth를 공유해야 한다.
- compaction이 incoming write 속도를 따라가지 못해서 read 속도가 느려질 수도 있다.
- B-tree는 그리덕분에 B-tree는 강력한 transaction semantic을 제공할 수 있다.
- disk의 resource 한계 때문에 compaction 과정을 수행할 때 read/write 성능에 영향을 미칠 수도 있다.
Other Indexing Structures
key-index의 예시를 살펴보자.
primary key- relational database - table의 row
- document database - one document
- graph database - one vertex
- key는 위 3개들을 고유하게 식별
- database의 record는 primary key로 row, document, vertex를 참조할 수 있으며, index는 참조를 찾을 때 사용됨
secondary index- relational database -
CREATE INDEX명령어를 사용하여 같은 테이블에 대한 secondary index를 여러 개 생성할 수 있다. - join을 효율적으로 하는데 중요한 역할을 한다.
- primary key와 비교했을 때, secondary index는 key가 unique 하지 않다. 2가지 solution 존재.
- index의 각 value에 일치하는 row identifier를 만듦.
- row identifier를 만들어서 각 key를 unique하게 만듦.
- relational database -
Storing values within the index
- index에서 key는 query가 검색하려는 대상이지만, value는 아래 둘 중 하나이다.
- 실제 row
- 다른 곳에 저장된 row를 가리키는 reference
- row가 저장되어 있는 곳을
heap file(append only)이라고 한다. - 여러 secondary index가 존재할 때 데이터의 duplication을 피할 수 있다.
- key를 변경하지 않고 값을 update 할 때 효율적이다. (새로운 값이 이전 값보다 많은 공간을 필요로 하지 않을 경우)
- row가 저장되어 있는 곳을
- index 안에 바로 indexed row를 저장하는 방법 :
clustered index- MySQL의 InnoDB의 경우, primary key는 항상 clustered index이고, secondary index는 primary key를 참조한다.
- clustered index (index 안에 모둔 row data를 저장) 과 nonclustred index (index 안에 data의 reference 만 저장) 의 절충안 :
covering index혹은index with included columns- index 안에 table의 column 일부를 저장 -> index만 사용해 일부 query에 응답이 가능하다. (이 경우를 "index가 query를
cover했다" 라고 함.)
- index 안에 table의 column 일부를 저장 -> index만 사용해 일부 query에 응답이 가능하다. (이 경우를 "index가 query를
- clustered index와 covering index는 read 성능은 높일 수 있지만, 추가적인 저장소가 필요하고, write 성능이 낮다.
Multi-column indexes
-
multiple column에 대해 query할 때는
concatenated index를 사용해야 한다.- concatenated index : 여러 field를 하나의 key로 합친다.
-
한 번에 여러 column에 대해 query할 때 일반적으로 쓰이는 방법이 multi-dimensional index이다.
- 주로 지리 공간 데이터에서 사용된다.
- 예를 들어, 지도의 특정 범위 안에 있는 식당을 찾으려고 할 때, 경도와 위도를 둘 다 고려해야 하는데, B-Tree나 LSM-Tree에서는 둘 중 하나에 대해서는 가능하지만 둘 다를 고려하지는 못한다. (space-filling curve를 이용해서 위도와 경도를 하나의 숫자로 만들어서 처리해도 되긴 함.)
- 이런 경우엔 R-tree가 흔히 쓰인다. ex) PostGIS
Full-text search and fuzzy indexes
- spelling이 틀린 data와 같이
similarkey에 대해서 query를 날리는 것을fuzzyquery라고 말한다.- full-text search engine에서는 input 단어에 대해 동의어로 확장하여 query를 날리거나, 언어학적으로 텍스트를 분석해서 query를 날리는 등의 기능을 제공한다.
- Lucene은 문서나 단어의 오타를 해결하기 위해 특정 edit distance를 사용하여 단어를 검색한다.
- 외에도 fuzzy search 기술은 문서 분류 및 ML 분야에서 연구된다.
Keeping everything in memory
- 이번 장에서 나온 모든 data structure는 disk의 한계에 대한 solution이다.
- 굳이 disk를 사용하는 이유는, disk의 durable, a lower cost per gigabyte than RAM이기 때문이다.
- 하지만 RAM이 점점 저렴해지면서, 메모리에 데이터 전체를 보관하거나, 여러 장비 간에 분산해서 보관하기도 한다. 이런 이유로
inmemory database가 개발되었다.- 일부 in-memory key-value 저장소는 캐시용도로만 사용되거나, 지속성만을 목표로 한다.
- in-memory db의 장점
- disk에서 읽지 않아도 된다 + disk에 기록하기 위한 형태로 encoding 하는 overhead를 피할 수 있다 : delay 없음
- disk based index에서 구현하기 어려운 data model을 사용할 수 있다.
- disk-centric architecture에서 발생하는 overhead 없이 가용 메모리보다 더 큰 dataset을 사용할 수 있다.
Transaction Processing or Analytics?
-
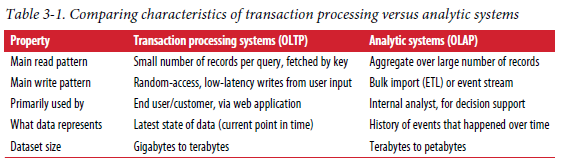
transcation이라는 용어는 logical unit으로서 read와 write 그룹을 나타내고 있다.- 일반적으로 transaction은 ACID 속성을 가져야 한다고 하는데,
transaction processing은 클라이언트가 low latency read/write를 가능하게 한다는 뜻이다. 즉, 반드시 ACID 속성을 가질 필요는 없다. - 보통 application은 index를 사용해서 일부 key에 대한 "적은 수의 " record를 찾는다. record는 user input을 기반으로 update 되거나 insert 되기 때문에 interactive 하다고 볼 수 있다 :
online transaction processing(OLTP)
- 일반적으로 transaction은 ACID 속성을 가져야 한다고 하는데,
-
database는
data analytics에서도 많이 사용되고 있다.- analytic query는 엄청나게 많은 record를 scan 해야 하고, record 당 일부 column만 읽어서 통계를 계산해야 한다. (분석)
- analytic query의 결과를 활용해서 더 나은 의사결정을 할 수 있게 도움을 얻는다 :
online analytic processing (OLAP)
-
OLTP 시스템들은 분석 목적으로 사용되지 않고 개별 database에서 분석을 수행할 때 사용되는 경향을 보인다. 여기서 개별 database를
data warehouse라고 한다.
Data Warehousing
-
OLTP는 대개 사업 운영에 중요하기 때문에 높은 가용성과 낮은 지연 시간의 transaction process를 기대한다. 하지만 데이터베이스 관리자는 OLTP database에 ad hoc analytic query를 실행하는 것을 꺼려한다.
- ad hoc analytic query는 cost 가 비싸고, dataset의 많은 부분을 scanning 해야 하기 때문에 transaction의 성능이 저하 될 수 있다.
-
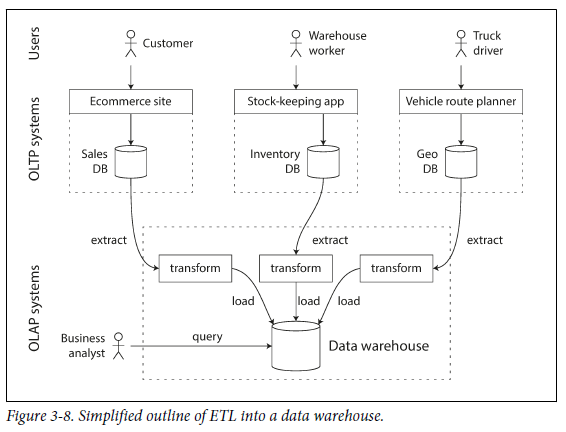
data warehouse는 OLTP 작업에 영향을 주지 않고 마음대로 query를 날릴 수 있는 개별 database이다.-
data warehouse는 회사의 모든 다양한 OLTP 시스템의 read-only 복사본이다.
-
데이터는 아래 그림처럼 OLTP 데이터베이스에서 추출되고, 분석 친화적인 schema로 변환된 뒤, 깨끗하게 정리되어 data warehouse에 load된다.
- 추출하는 과정을
Extract-Transform-Load(ETL)이라고 한다.
- 추출하는 과정을
-
- 이전 section에서 설명했던 indexing algorithm은 OLTP에서 잘 작동하지만, analytic query에서는 별로 좋지 않다.
The divergence between OLTP databases and data warehouses
- SQL은 analytic query에 적합하기 때문에 주로 data warehouse의 data model은 관계형이다.
- 표면적으로 봤을 때, data warehouse와 relational OLTP database는 SQL query interface를 가지기 때문에 비슷해 보이지만, 각각 매우 다른 query pattern에 맞게 최적화됐기 때문에 내부 시스템은 다르다.
- 많은 database vendor들은 transaction processing이나 analytics workload 둘 중 하나에 초점을 맞춘다.
- Microsoft SQL server와 SAP HANA와 같은 database는 동일한 제품에서 transaction processing과 data warehousing을 지원한다.
- 많은 database vendor들은 transaction processing이나 analytics workload 둘 중 하나에 초점을 맞춘다.
Stars and Snowflakes: Schemas for Analytics
-
transaction processing에는 다양한 data model이 있지만, analytics에는 data model의 다양성이 적다.
-
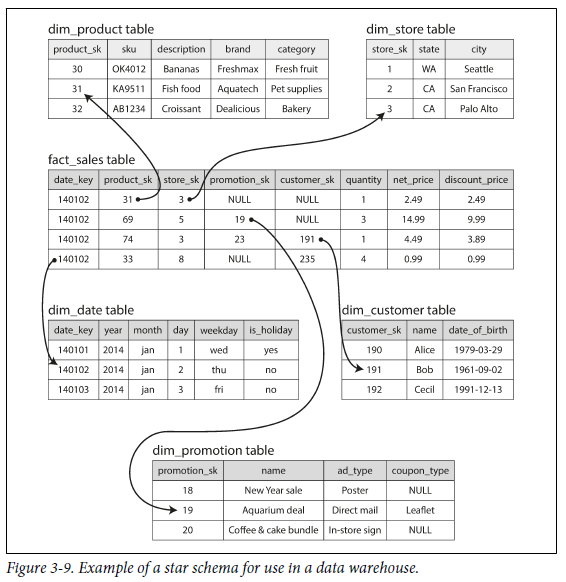
많은 data warehouse는
dimensional modeling이라고 불리는star schema를 많이 사용한다.-
schema 중심에는 특정한 시간에 발생한 이벤트를 난타내는
fact table이 있다. (아래 그림에서의 fact_sales table) -
보통 fact는 개별 event를 나타낸다. 분석의 유연성을 극대화할 수 있기 때문이다.
-
fact table의 일부 column은 property 이다. (아래 그림에서의 제품 가격, 공급자가 지불한 비용 ....)
-
어떤 column들은
dimension table이라고 불리는 다른 table을 참조하는 foreign key이다. -
fact table의 각 row는 이벤트를 나타내고, dimension은 이벤트의 속성인
who, when, where, what, how, why를 나타낸다.
-
star schema라는 이름은 dimension table을 사용해 표현한다. (dimension table을 사용해서 분석이 가능함 ex. 휴일과 평일의 판매 차이)
-
-
star schema의 변형이
snowflake schema이며, 차원이 더 세분화된다.
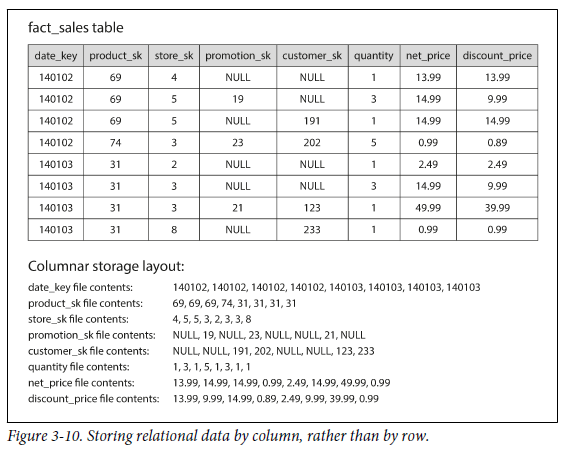
Column-Oriented Storage
-
fact table에 row와 data의 개수가 많을 때 효율적으로 query를 날리고 data를 저장하는 방법
-
대부분의 OLTP database에서 storage는
row-oriented방식으로 data를 배치한다.- row-oriented : table의 하나의 row를 기준으로, 모든 value는 인접하게 배치
- 하지만 row-oriented 방식을 사용하면, 많은 row를 access하면서 소수의 column에 대해서만 query를 사용해야하는 경우에 불필요하게 모든 row를 disk에서 memory로 load 해야하기 때문에 오랜 시간이 걸린다.
-
대신
column-oriented storage방법을 사용한다.-
column-oriented storage : 모든 value를 하나의 row에 저장하지 않고, 각 column을 개별 파일에 저장하고 query에 사용되는 column만 읽음.
-
아래 사진은 그림3-9의 예제를 column-oriented storage로 구성한 것이다. 각 column file에 포함된 row가 모두 같은 순서로 배치되어 있다.
-
-
Column Compression
-
그림 3-10을 보면 각 column에서 같은 값이 반복해서 나온다. 이럴 경우 compression을 하여 disk throughput을 줄일 수 있다. compression 기법은 data에 따라 다양한다.
-
bitmap encoding기법 : n개의 distinct value를 가지고 와서 n개의 bitmap으로 만든다. distinct value 하나가 bitmap이고, 각 row는 한 bit를 가진다. 만약 row가 해당 값을 가지면 bit는 1이고, 그렇지 않으면 0이다.

- 만약 n이 매우 작으면, row 당 하나의 bit로 저장할 수 있다. - 만약 n이 크면 (`sparse`), bitmap을 추가적으로 run-length encoding 한다. (위 사진의 하단)
-
Memory bandwidth and vectorized processing
- data warehouse query에서는 수만개의 row를 읽어야 하는데, 이것은 disk에서 memory로 데이터를 가지고 오는데 bandwidth bottleneck이 큰 작업이다.
- analytical database 개발에서는 main memory -> CPU cache로 가는 bandwidth를 효율적으로 사용해야 한다. 또한, CPU instruction processing pipeline에서의 branch misprediction과 bubble을 피해야 한다.
- 최신 CPU에서는 single-insturction-multi-data (SIMD) 를 사용해야 한다.
- column-oriented storage layout은 CPU cycle을 효율적으로 사용해야 한다.
- column compression을 사용하면 효율성이 높아진다.
vectorized processing: bit AND와 OR 연산을 압축된 column data chunck에 바로 연산하는 기법
Sort Order in Colum Storage
- column storage에 row를 삽입할 때 order를 도입하여 indexing mechanism을 사용할 수 있다. (원래는 순서가 중요하지 않음)
- 주의해야 할 점은, 각 column을 독립적으로 정렬할 수 없다는 것이다. (한 column의 k번째 item은 다른 k번째 column과 같은 row에 속하기 때문)
- column 별로 저장됐을지라도, 한번에 전체 row를 정렬해야 한다. 즉, 여러 column 중 기준이 되는 column 하나를 정해서 같은 k번째 column들도 같이 정렬을 해야한다는 뜻이다.
- 기본 sort column에 distinct value가 적다면 연속해서 같은 값이 길게 반복될 것이다. 이런 경우 run length encoding을 이용해서 압축하면 효율적이다.
Several different sort orders
- 같은 data를
several differen way로 정렬해서 복제해두자! -> query를 처리할 때 qeury pattern에 가장 적합한 버전을 사용할 수 있다.- row-oriented store의 multiple secondary index와 비슷하다.
- row-oriented store : 한 곳 (heap file이나 clustred index)에 모든 row를 유지
- multiple secondary index : 일치하는 row를 가리키는 pointer만 포함
- column store : 일반적으로 data를 가리키는 pointer가 없고 단지 값을 포함한 column만 존재
- row-oriented store의 multiple secondary index와 비슷하다.
Writing to Column-Oriented Storage
-
column-oritented storage, compression, sorting은 read query에는 적합하지만, write를 어렵게 만든다.
-
정렬된 table의 중간 row에 insert를 하려면 모든 column file을 재작성해야 한다.
-
LSM tree를 이용해서 해결할 수 있다 : 모든 write는 in-memory store로 이동해 sorted structure에 추가되고, disk에 쓸 준비를 한다. write가 충분하게 모였으면, disk의 column file에 merge하고 대량으로 새로운 file에 기록한다.
Vertica가 위와 같은 방법을 사용한다.
-
Aggregation : Data Cubes and Materialized Views
-
data warehouse query에는 aggregate function이 있다 :
COUNT,SUM,AVG,MIN,MAX- 같은 aggregate를 많은 다양한 query에서 사용한다면 매번 raw data를 사용하는 것은 낭비이다.
materialized view를 사용해서 query가 자주 사용하는COUNT나SUM을 cache 해보자!
-
relational data model에서는 이런 것을 standard (virtual) view라고 정의한다.
-
materialized view는 디스크에 기록된 query result의 복사본이다.
-
원본 data를 변경하면 materialized view를 update 해야 한다. (update 과정은 cost가 비싸기 때문에 OLTP DB에서는 자주 사용하지 않는다.)
-
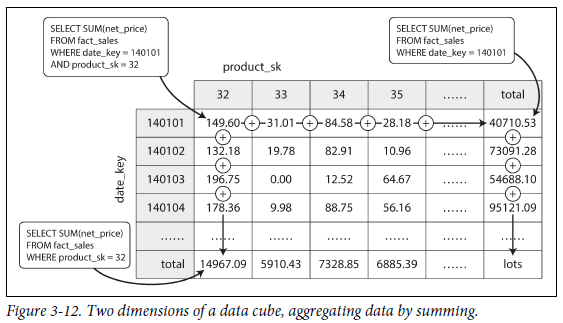
materialized view를 사용한 것이
data cube혹은OLAP cube이다.
-
materialized data cube의 장점은 특정 query를 미리 계산했기 때문에 해당 query를 수행할 때 매우 빠르다는 것이다.
-
단점은 유연성이 없다는 것이다.
-
따라서 대부분의 data warehouse는 가능한 한 많은 raw data를 유지하려고 하며, 특정 query에 대한 성능 향상에만 사용한다.
-
