1. Intro

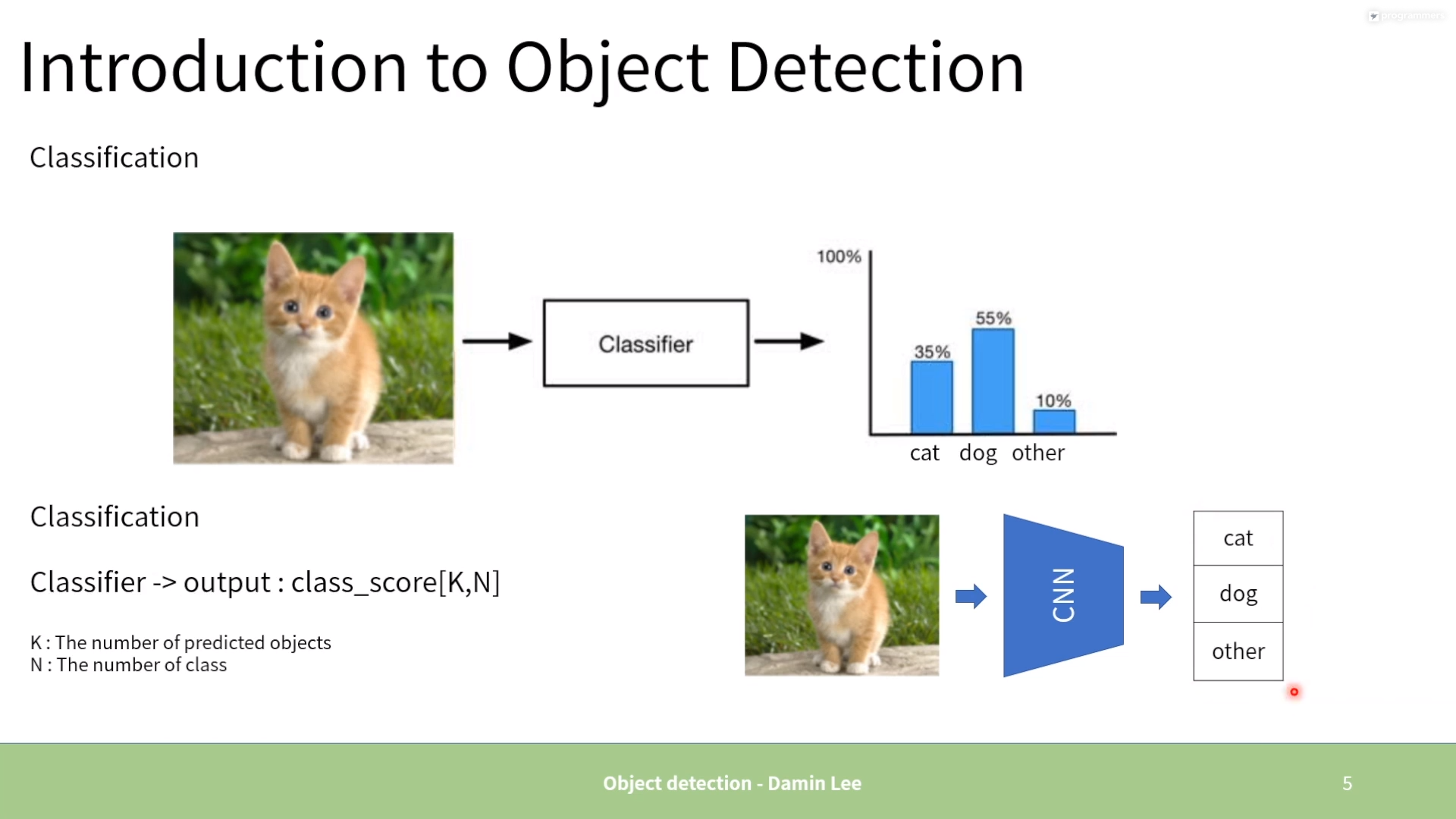
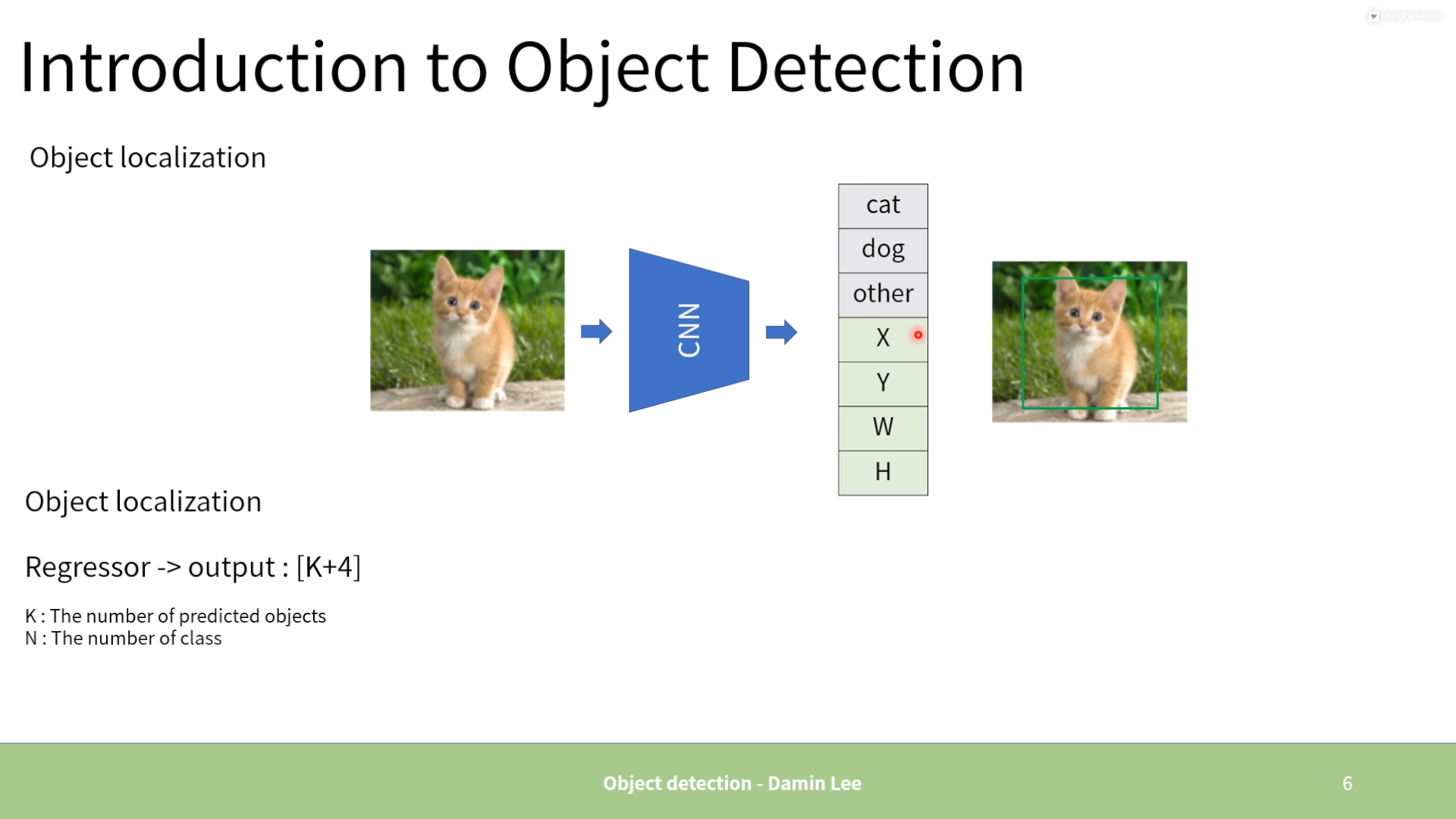
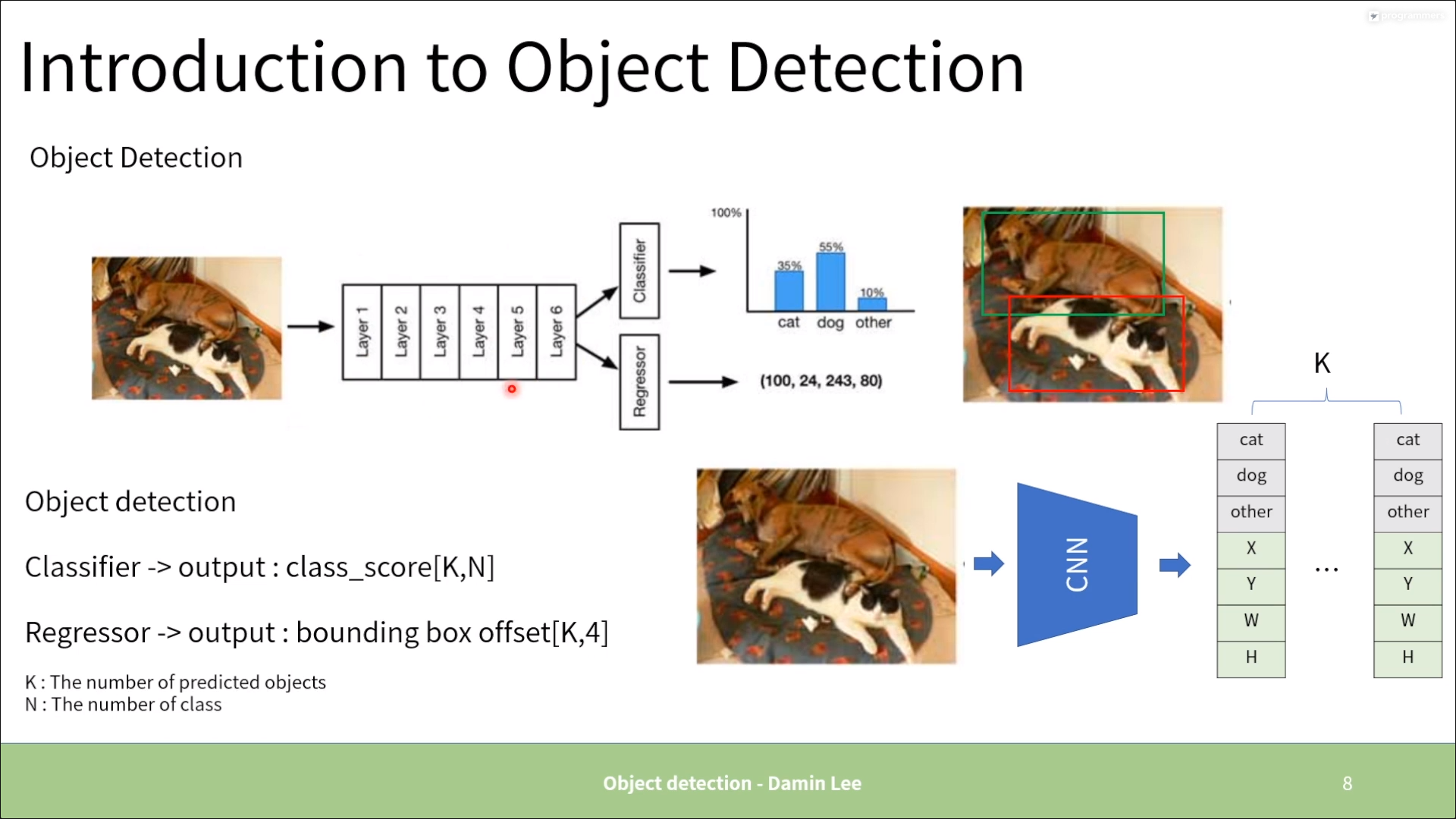
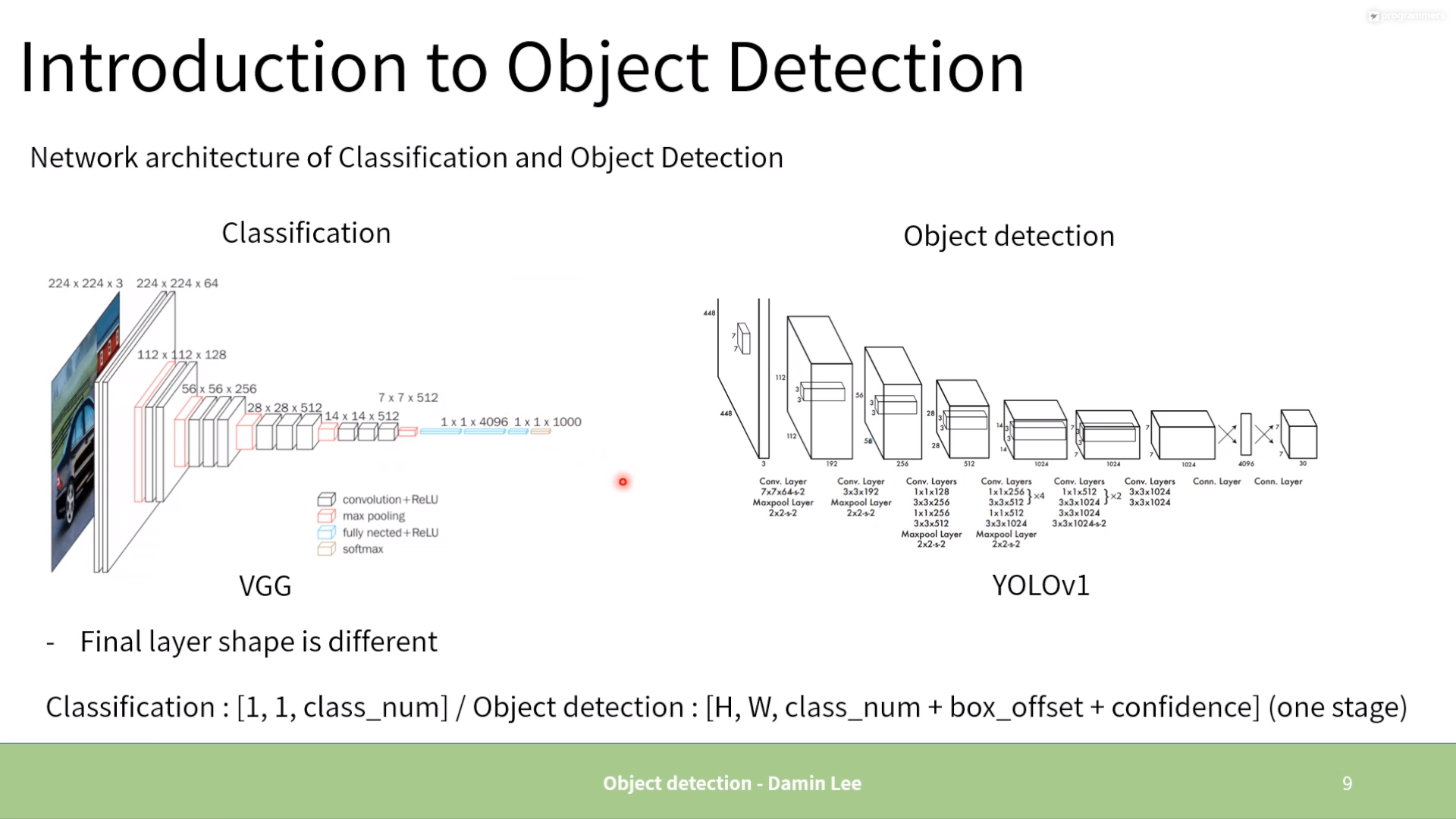
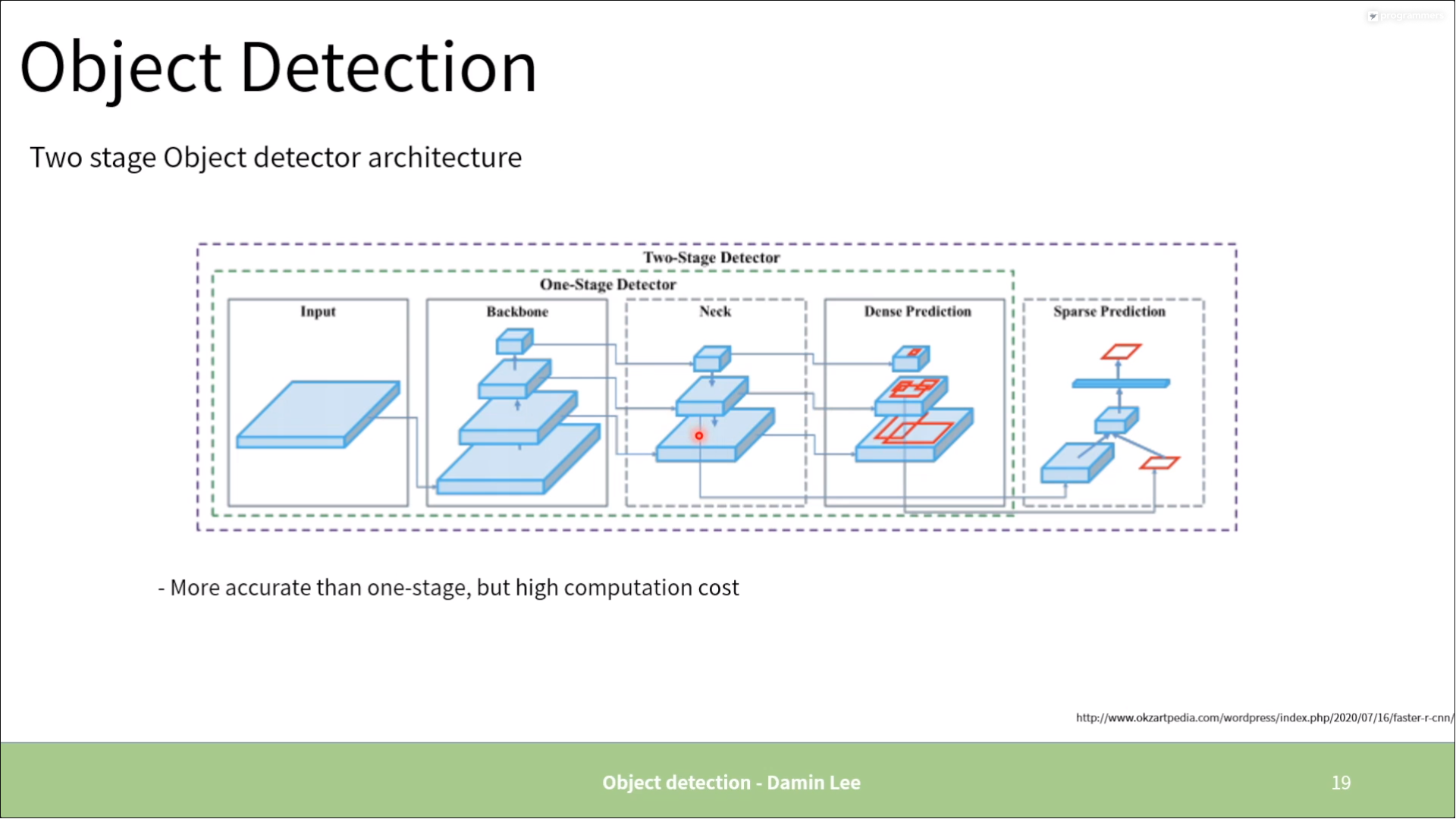
2. One stage vs. Two stage

-
One stage
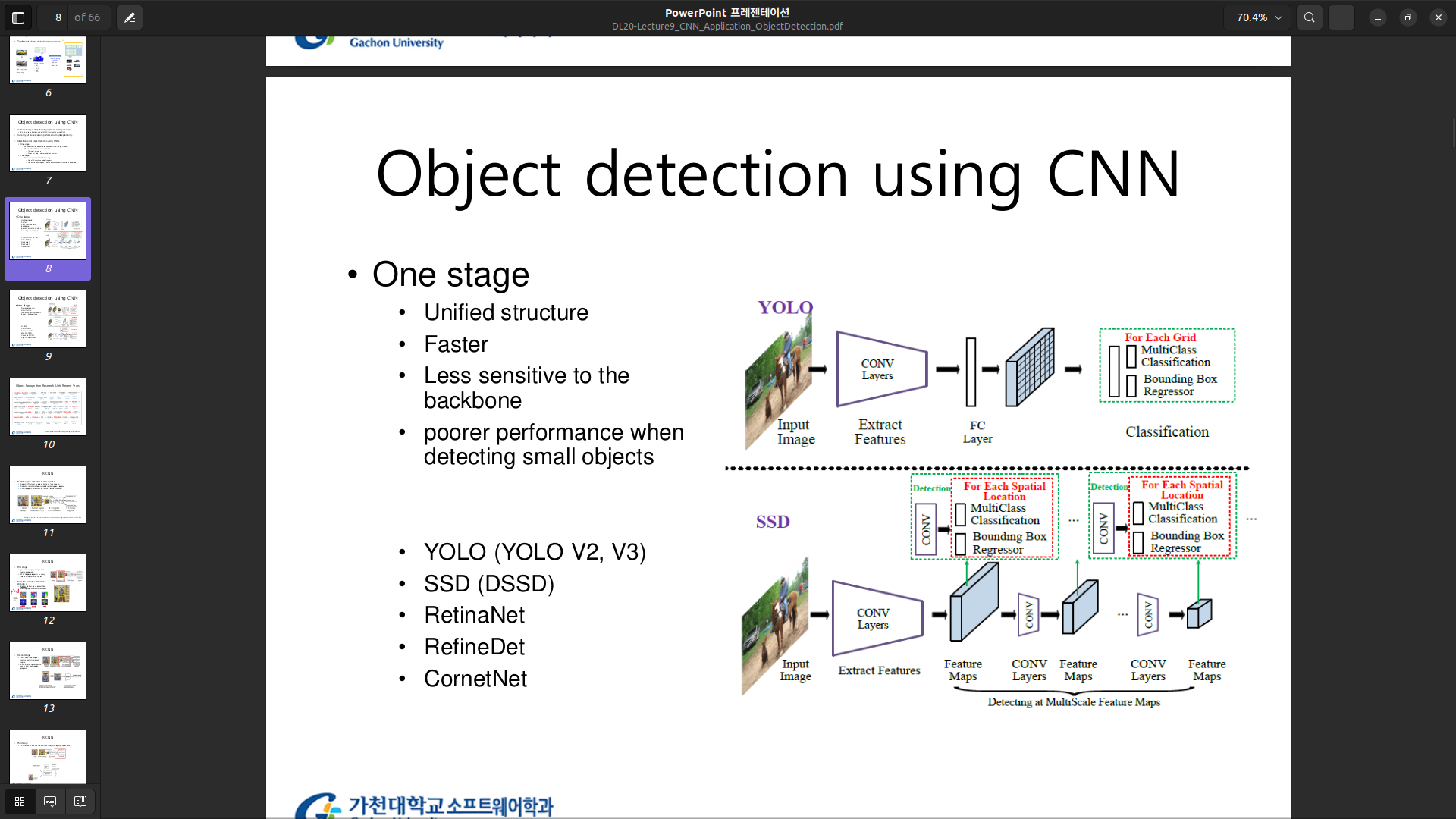
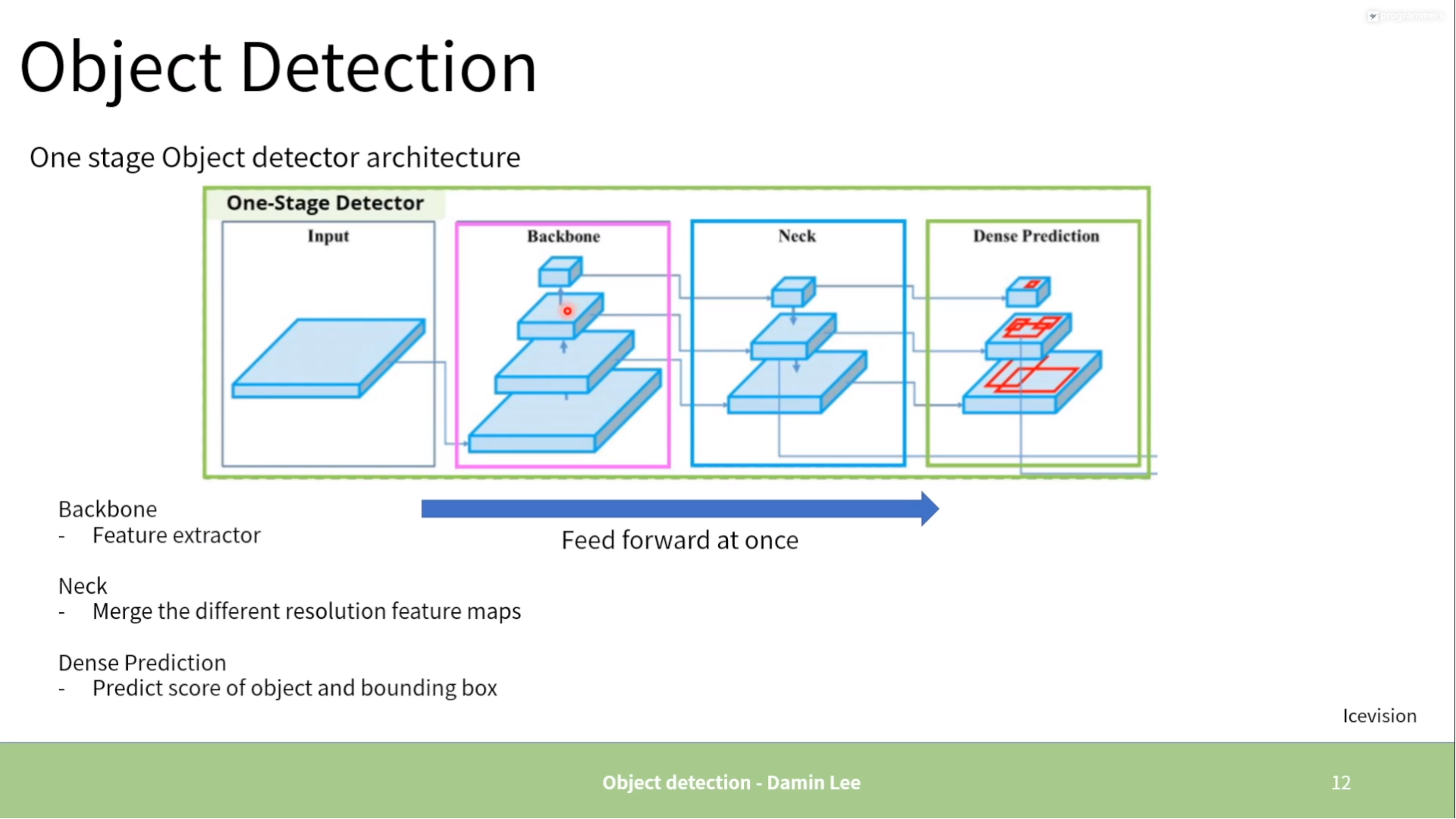
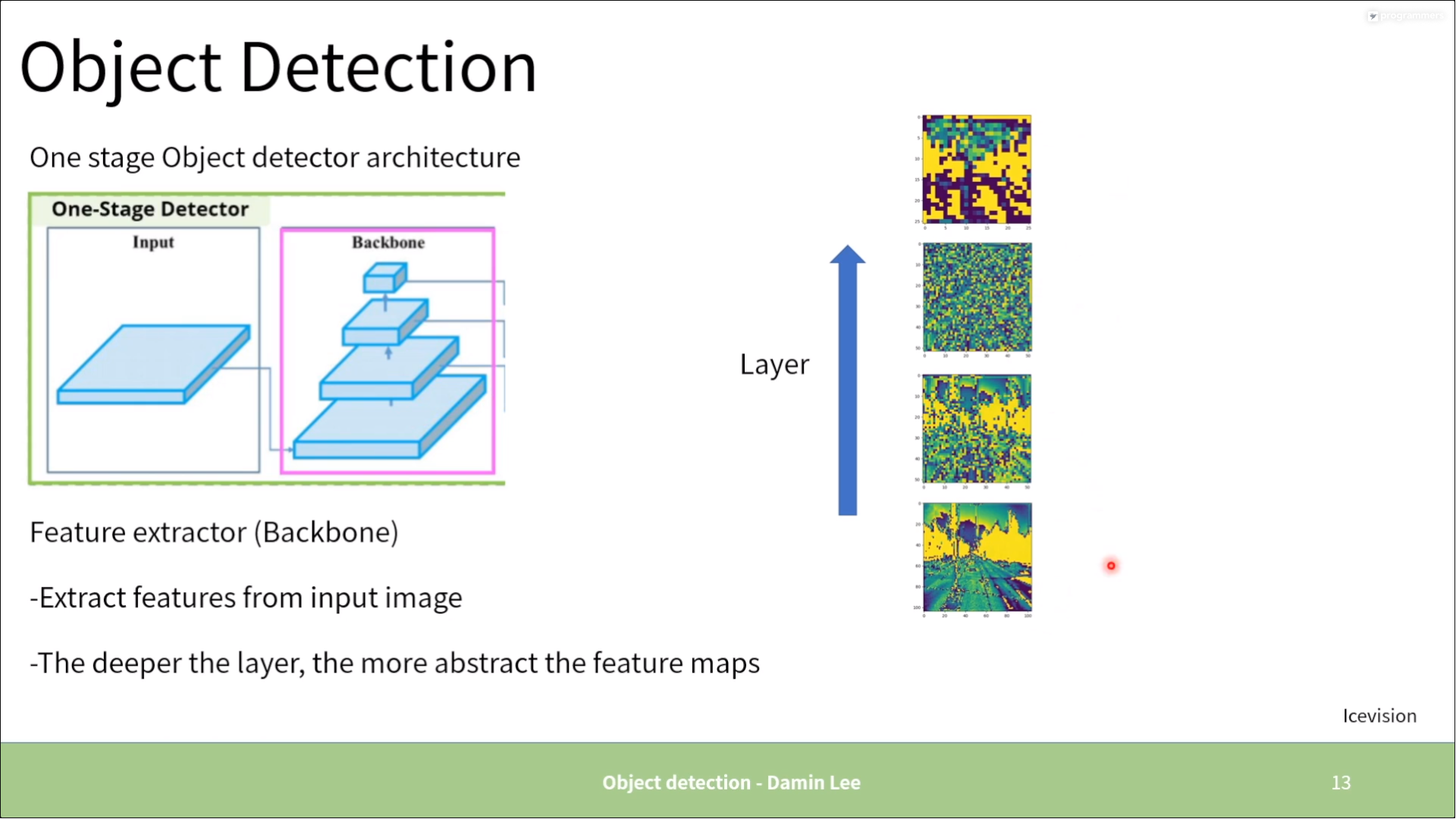
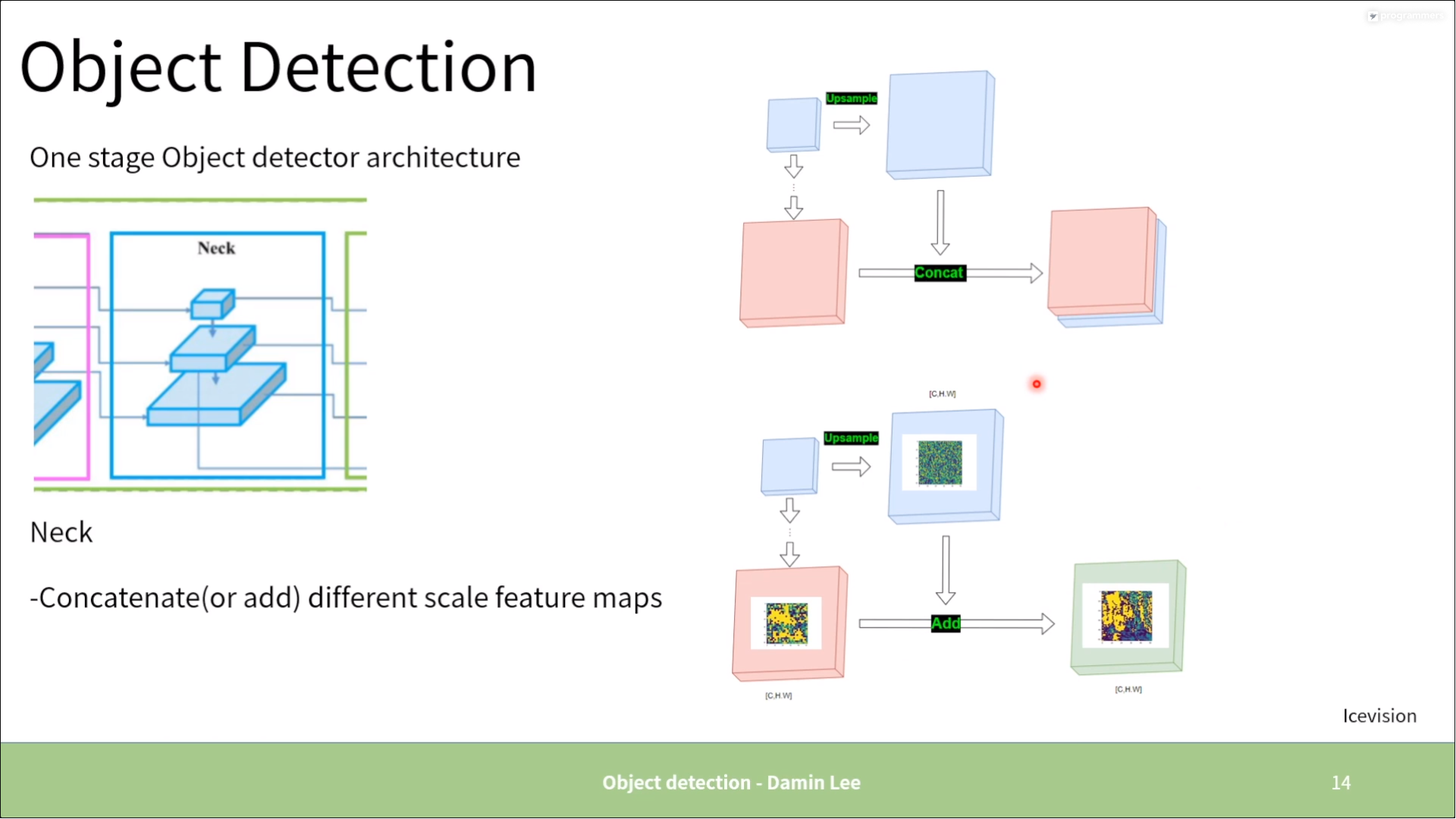
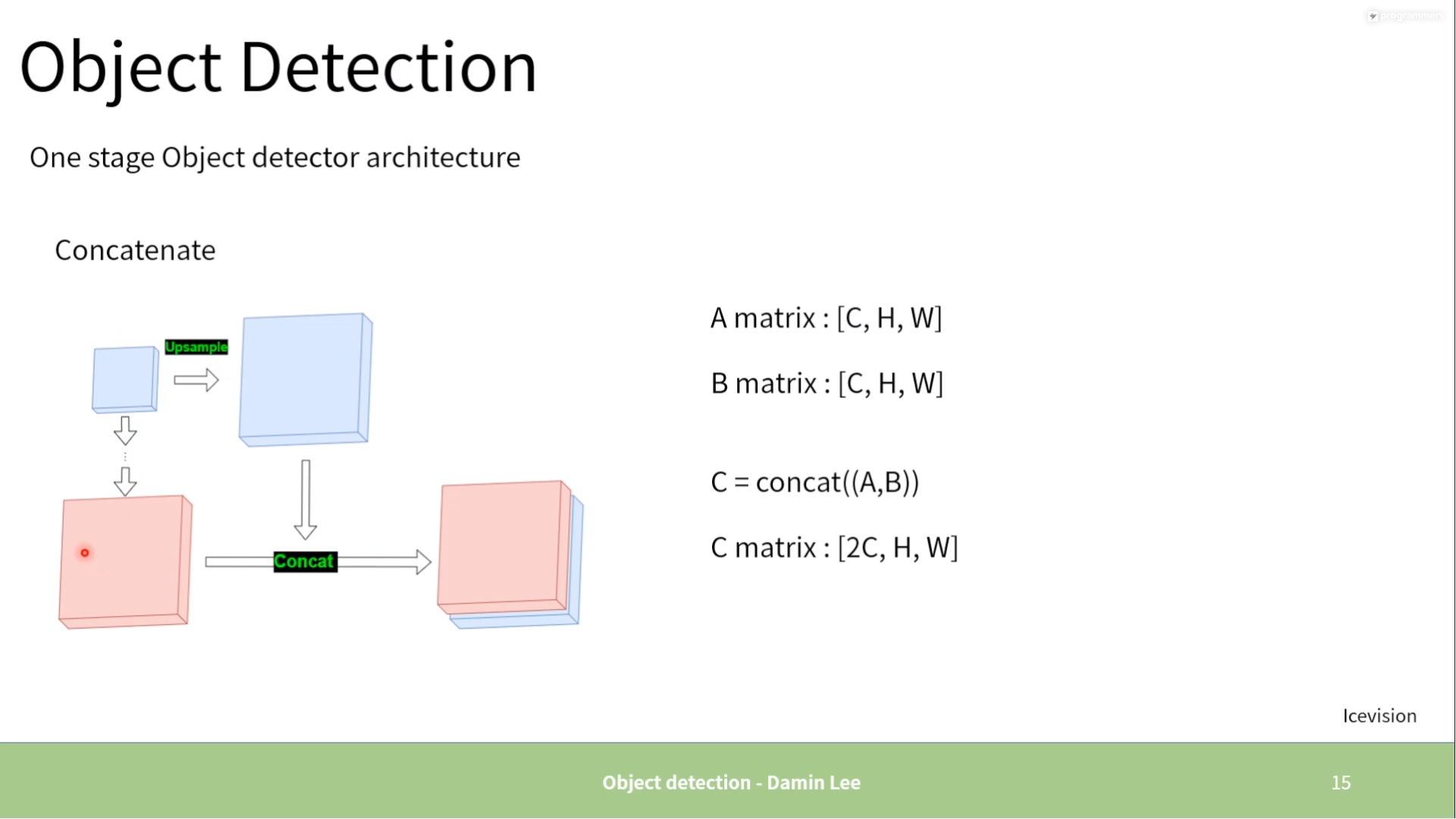
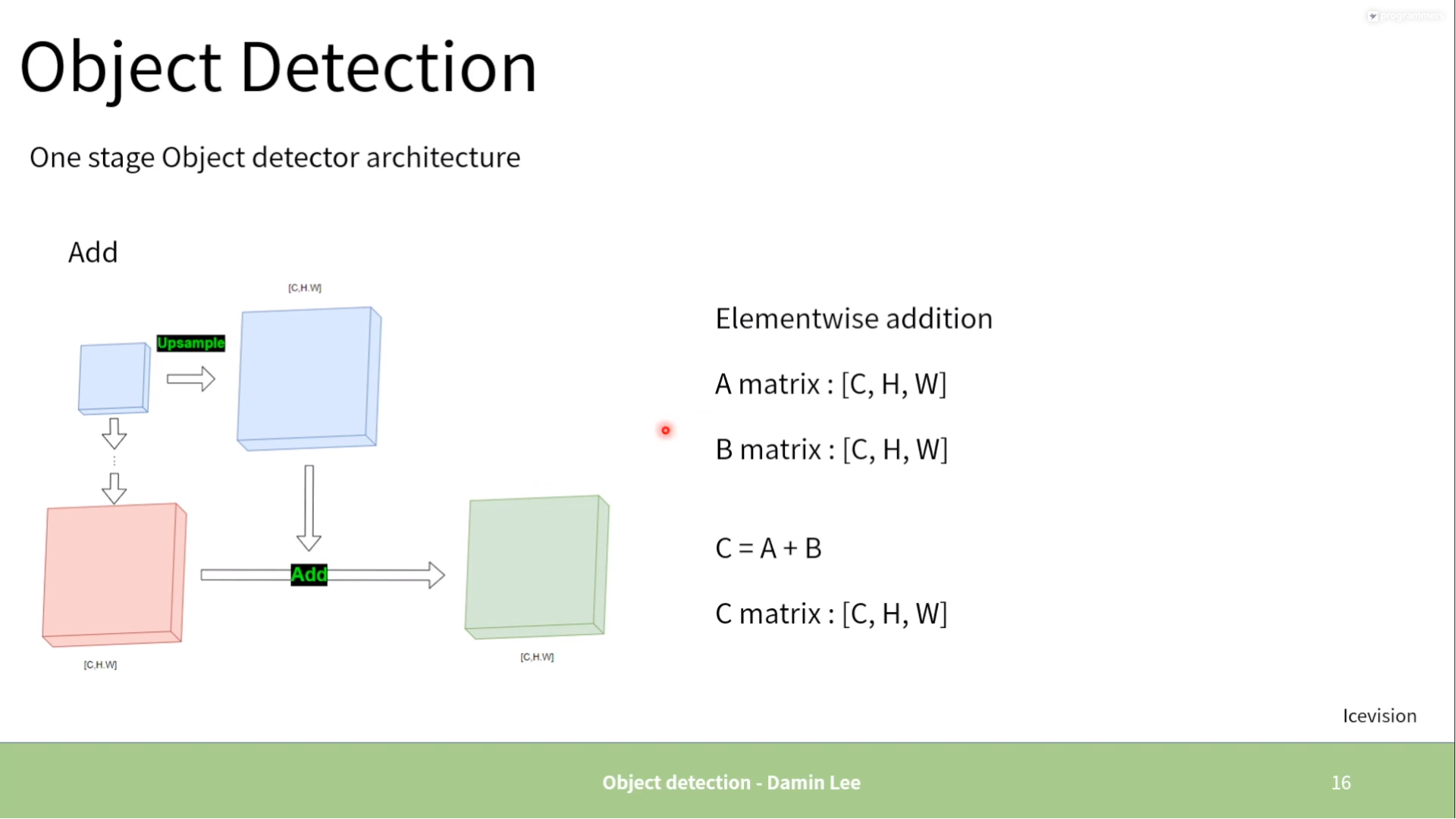
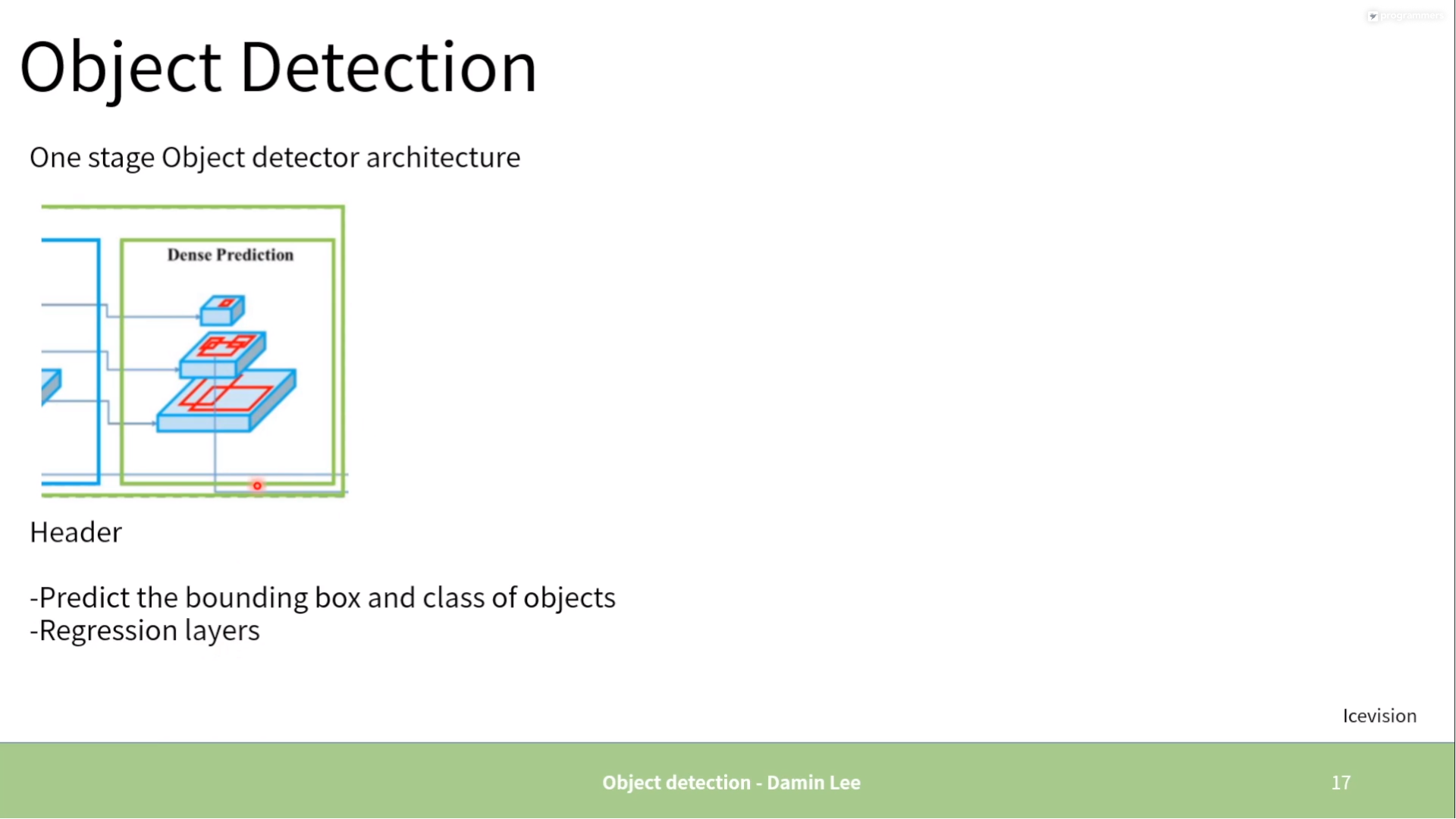
-
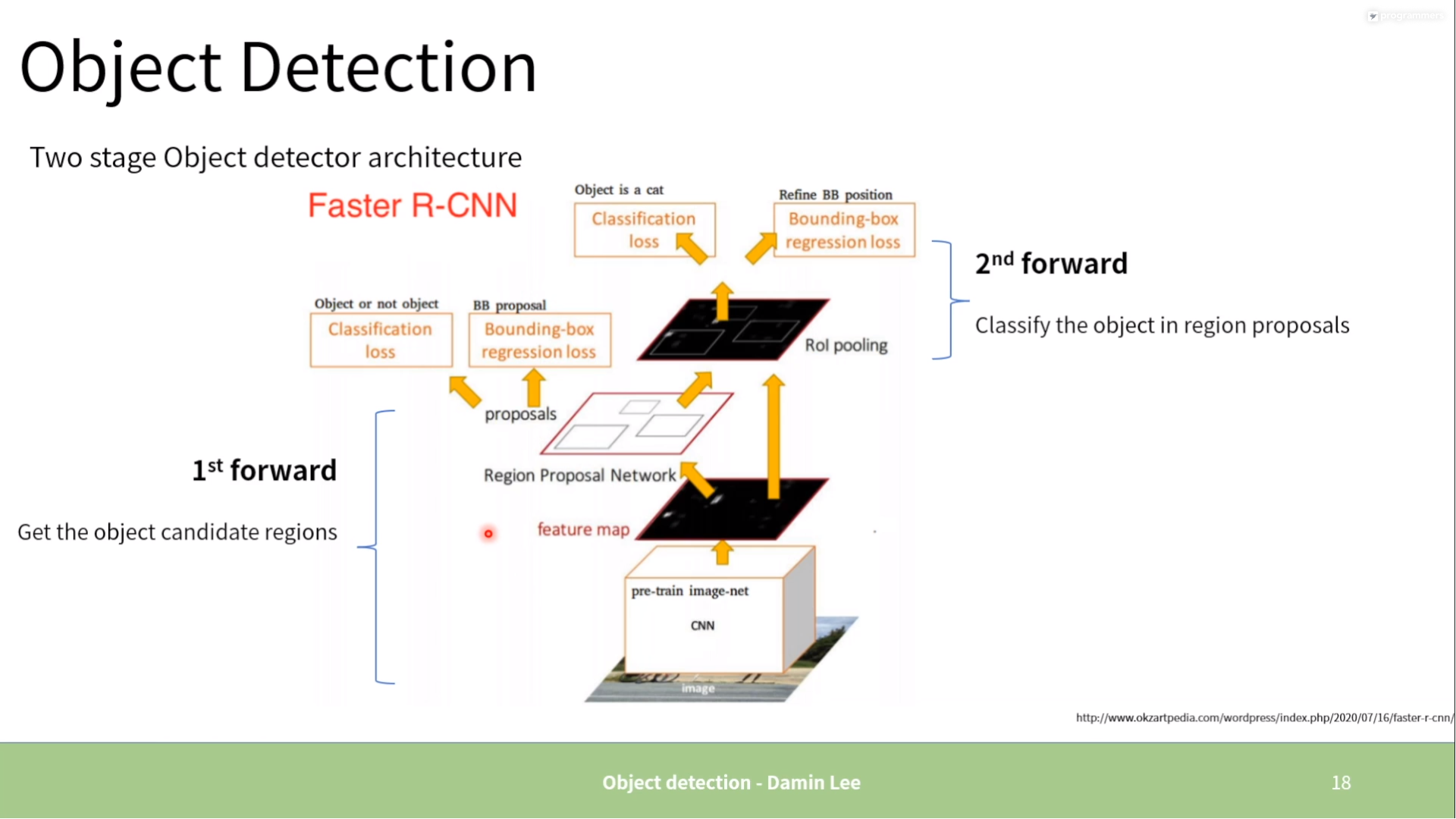
Two stage
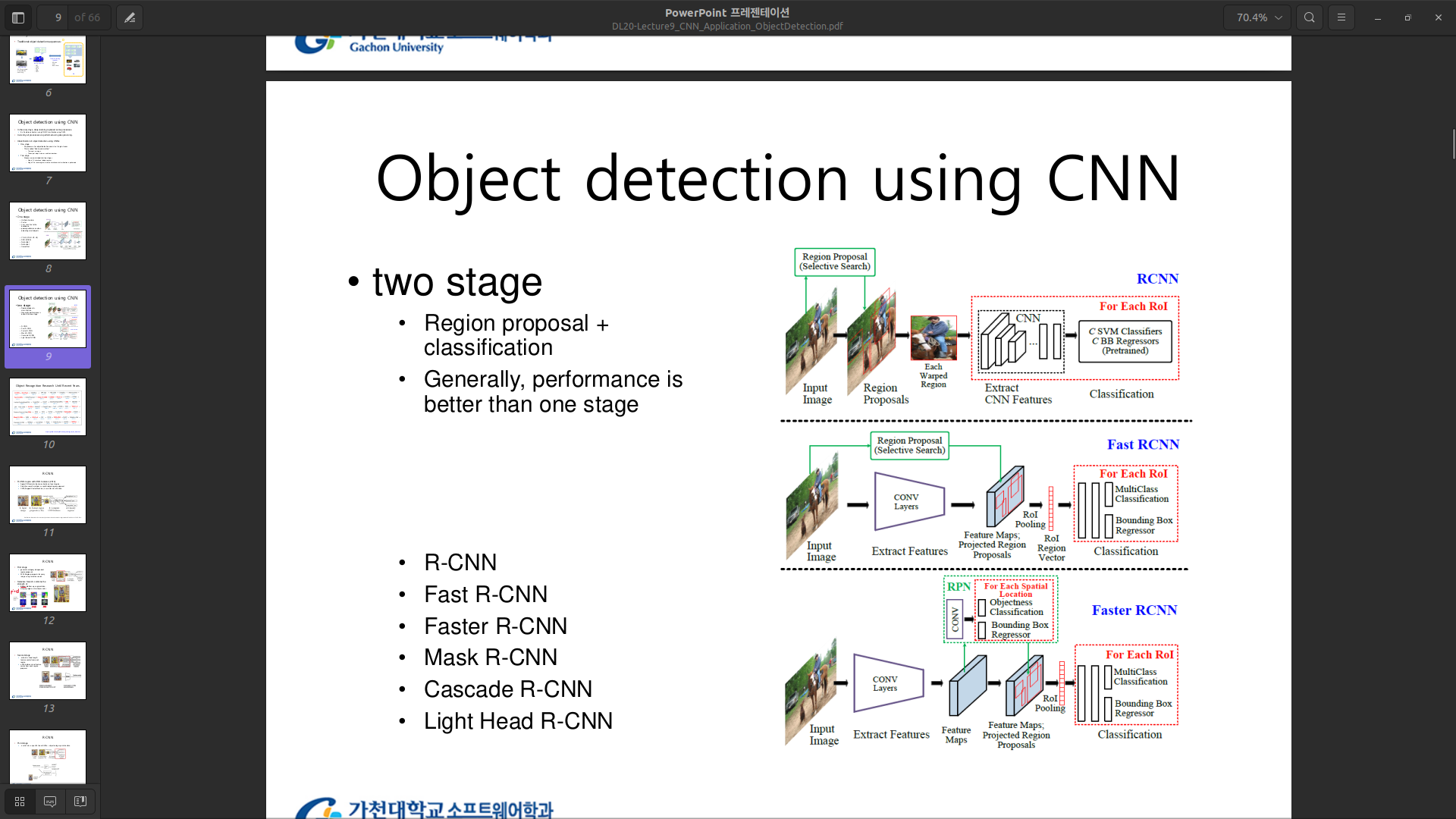
3. Idea
3.1. Target Y
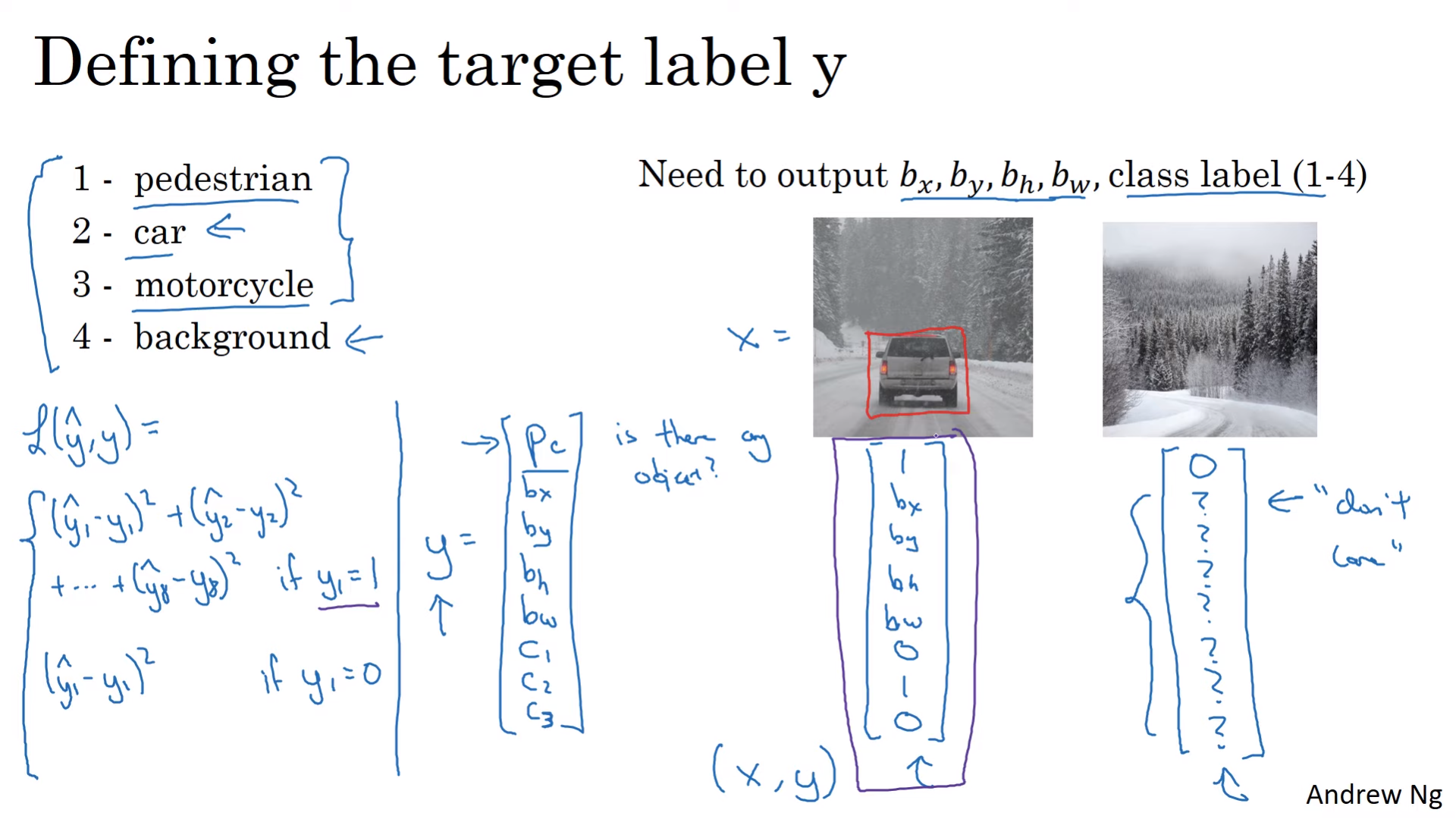
-
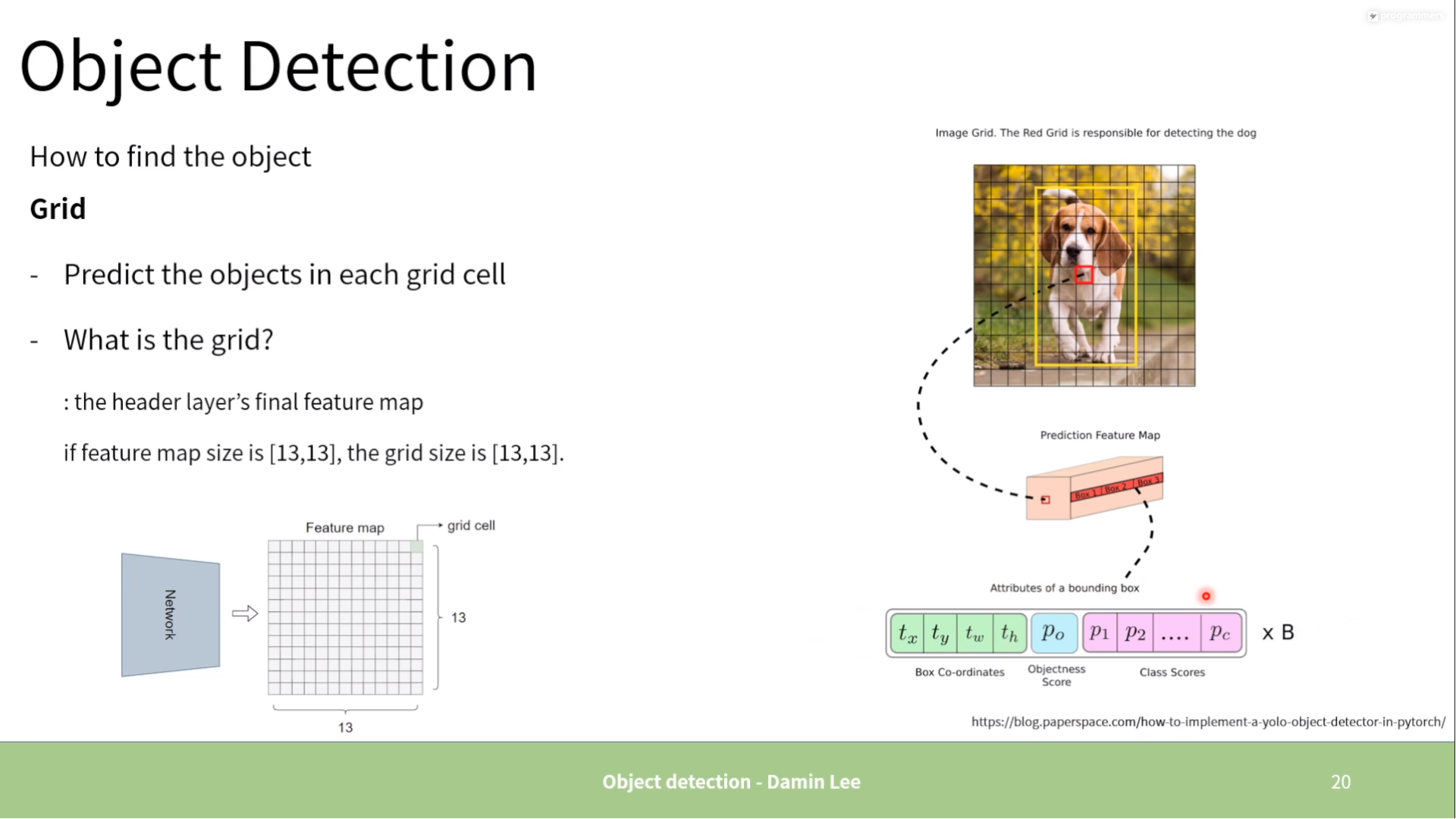
YOLO v1 output:
- : grid
- : bounding boxes (, confidence)
- : class probabilities (PASCAL VOC has labelled 20 classes)
3.2. Grid
3.3. Anchor Boxes
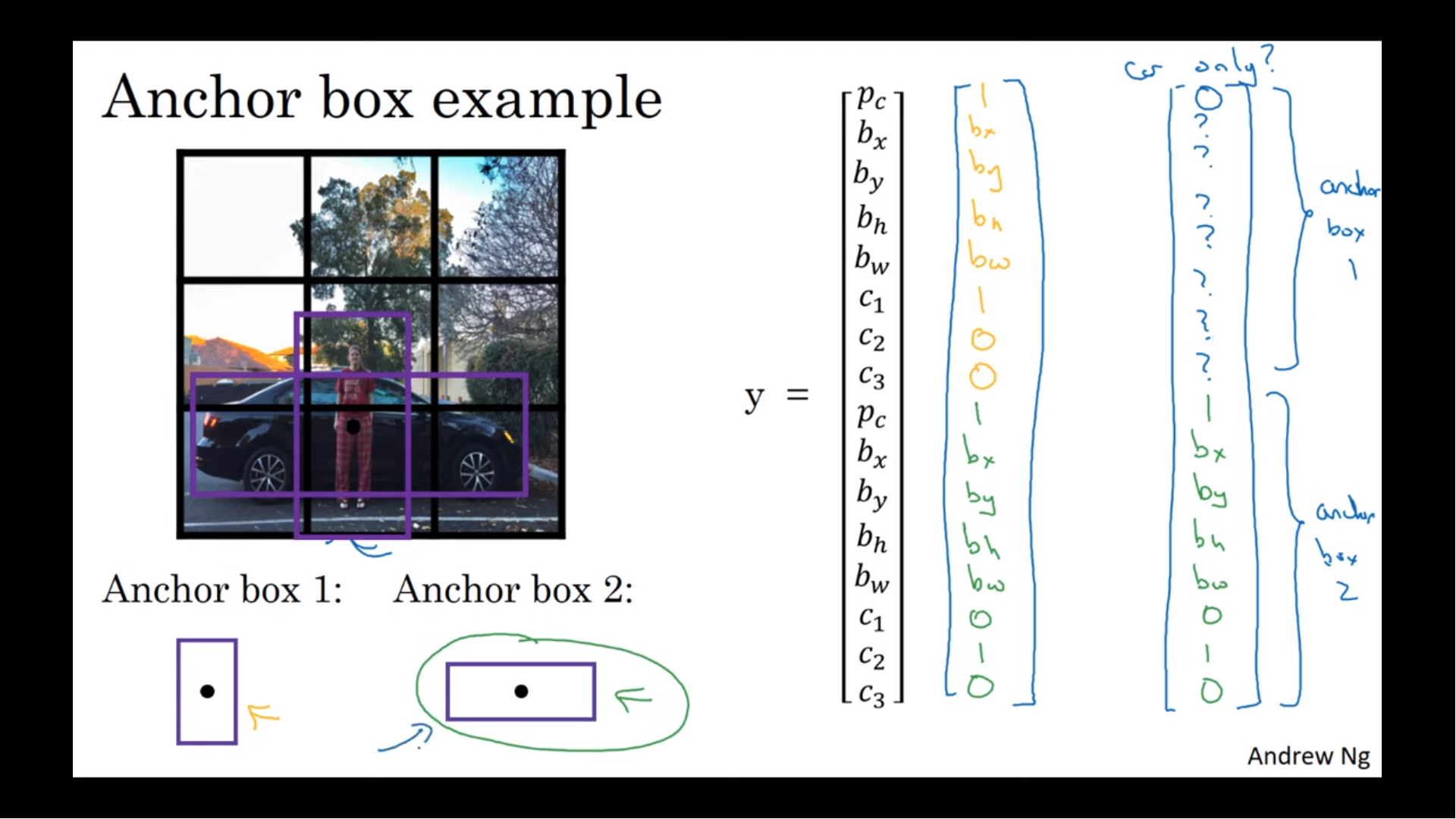
- Andrew Ng - C4W3L08 Anchor Boxes
YOLO v2는 anchor box를 K-means를 이용해 정의한다. (?K로 anchor의 개수를 정해주면 그 모양과 크기를 결정해준다.? 확인 필요)

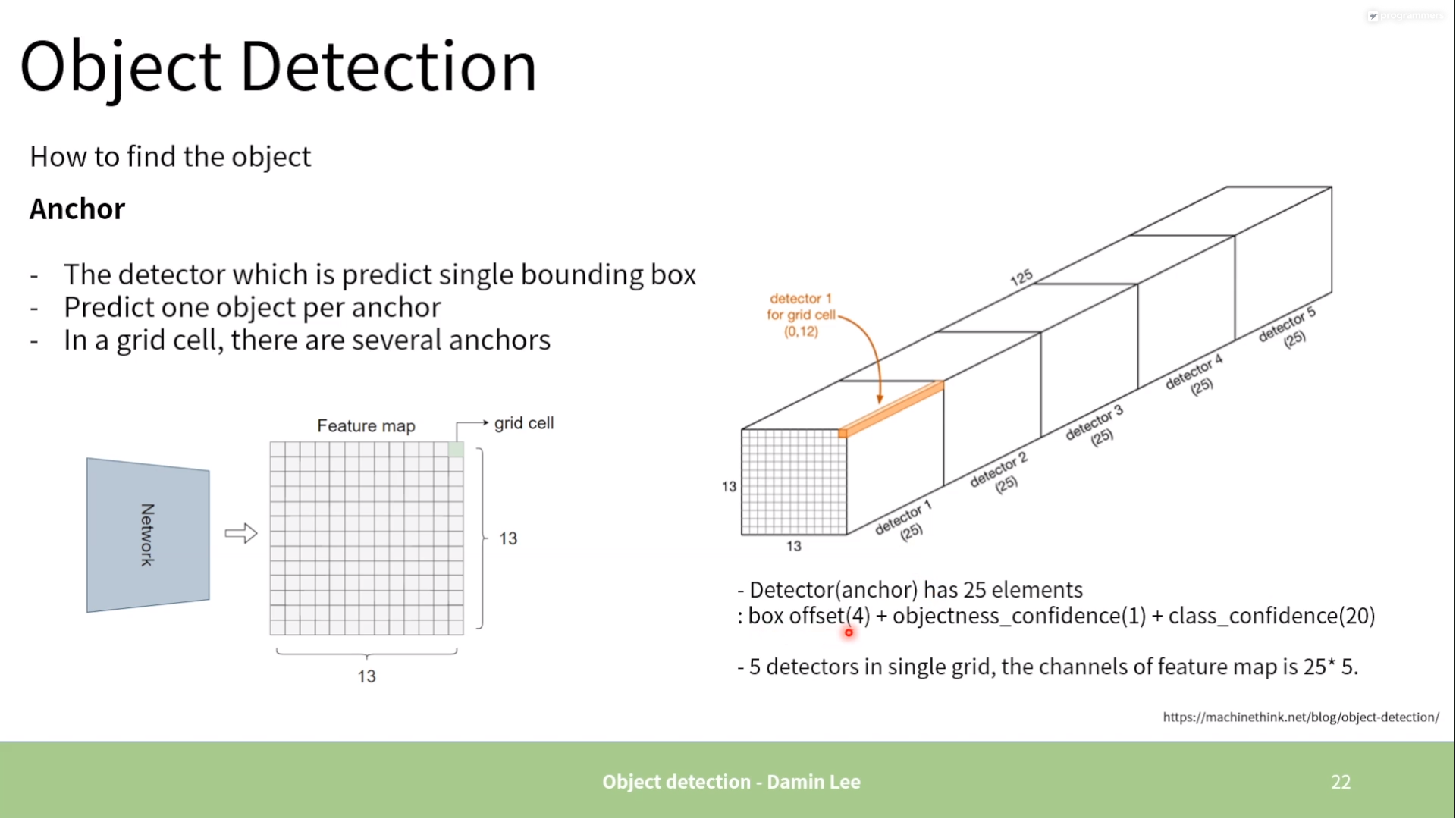
3.4. Confidence Scroe
Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts. Formally we define confidence as Pr(Object) ∗ IOUtruth pred . If no
object exists in that cell, the confidence scores should be zero. Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box and the ground truth.
Each bounding box consists of 5 predictions: x, y, w, h, and confidence. The (x, y) coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally the confidence prediction represents the IOU between the predicted box and any ground truth box.
-
- grid cell에 객체가 존재하지 않으면 가 0이므로 는 0이 된다.
- grid cell에 객체가 존재한다면 가 1이므로 는 가 된다.
-
Andrew Ng - C4W3L06 Intersection Over Union

- threshold는 관례적으로 0.5를 사용한다.
3.5. Nonmax Suppression
- Andrew Ng - C4W3L07 Nonmax Suppression

① confidence score가 threshold(e.g. 0.6) 이하인 박스를 제거한다.
② confidence score가 가장 큰 값인 0.9의 박스를 고른다.
③ 그 박스와 IOU가 큰 박스를 제거한다. (위 그림에서는 오른쪽 부분의 어두운 두 박스를 제거)
④ 남은 박스 중 가장 큰 값인 0.8의 박스를 고른다.
⑤ 그 박스와 IOU가 큰 박스를 제거한다. (위 그림에서는 왼쪽 부분의 어두운 박스 하나)
⑥ 각 클래스별 결과에 대해 독립적으로 위처럼 Nonmax suppression을 진행한다.

Data annotation



📙 참고
