딥러닝
1.[딥러닝] Sigmoid function, Cost function of Logistic regression
binary 사건 Y의 발생 확률 p → 성공 확률과 실패 확률의 비율 odds → odds의 log 변환인 logit → logit에 선형 회귀를 적용한 logistic regression → sigmoid function
2.[딥러닝] 기계학습, 다층 퍼셉트론

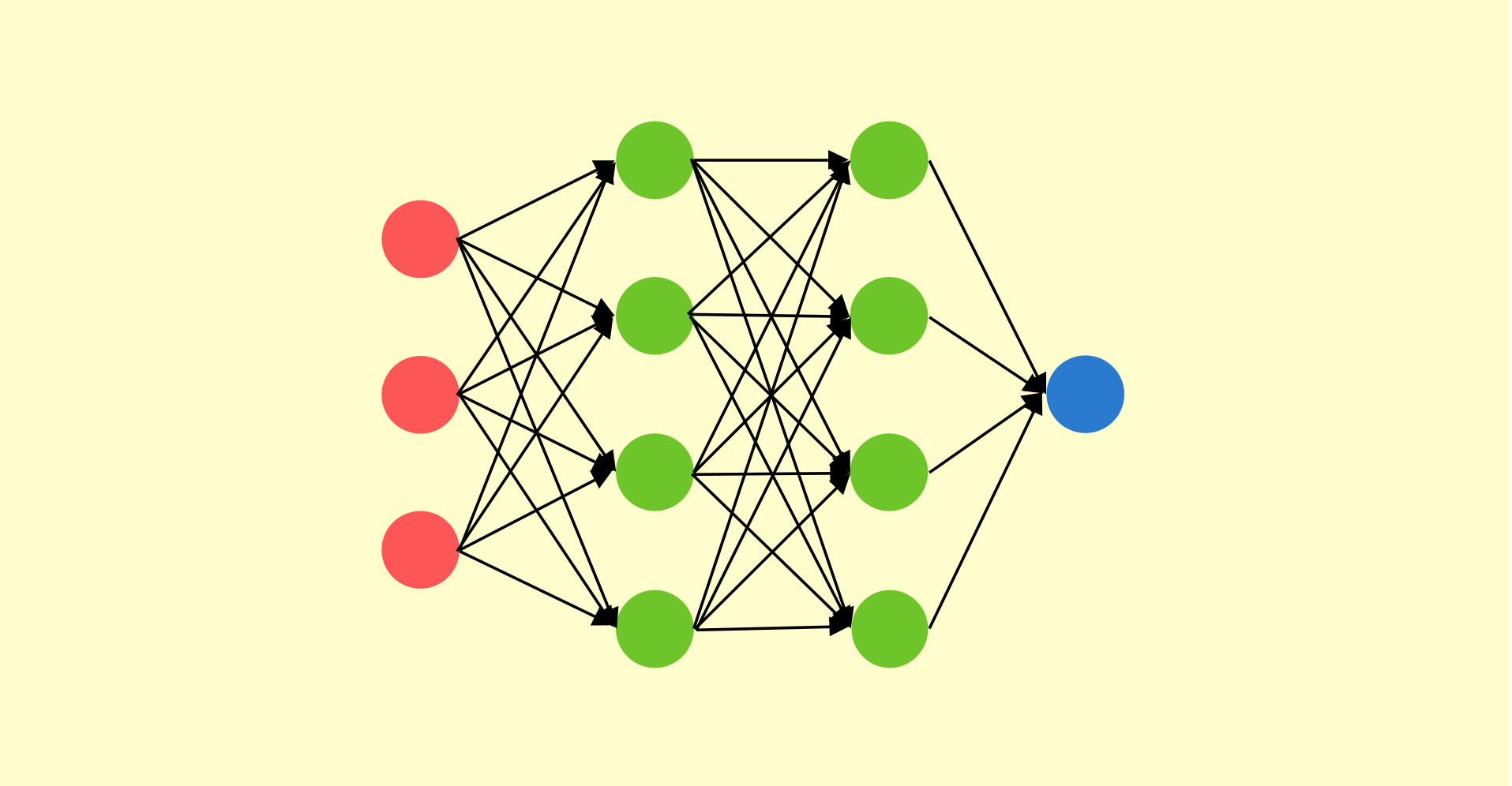
기계학습과 다층 퍼셉트론의 개요
3.[딥러닝] Handling Tensors with PyTorch
sum, subtract, multiply, view, transpose, slicing, transform numpy, concatenate, stak, transpose, permute
4.[딥러닝] Image Classification Models and Dataset
LeNet5, AlexNet, VGGNet, GoogLeNet, ResNet
5.[딥러닝] IM2COL & GEMM으로 Convolution 연산 구현
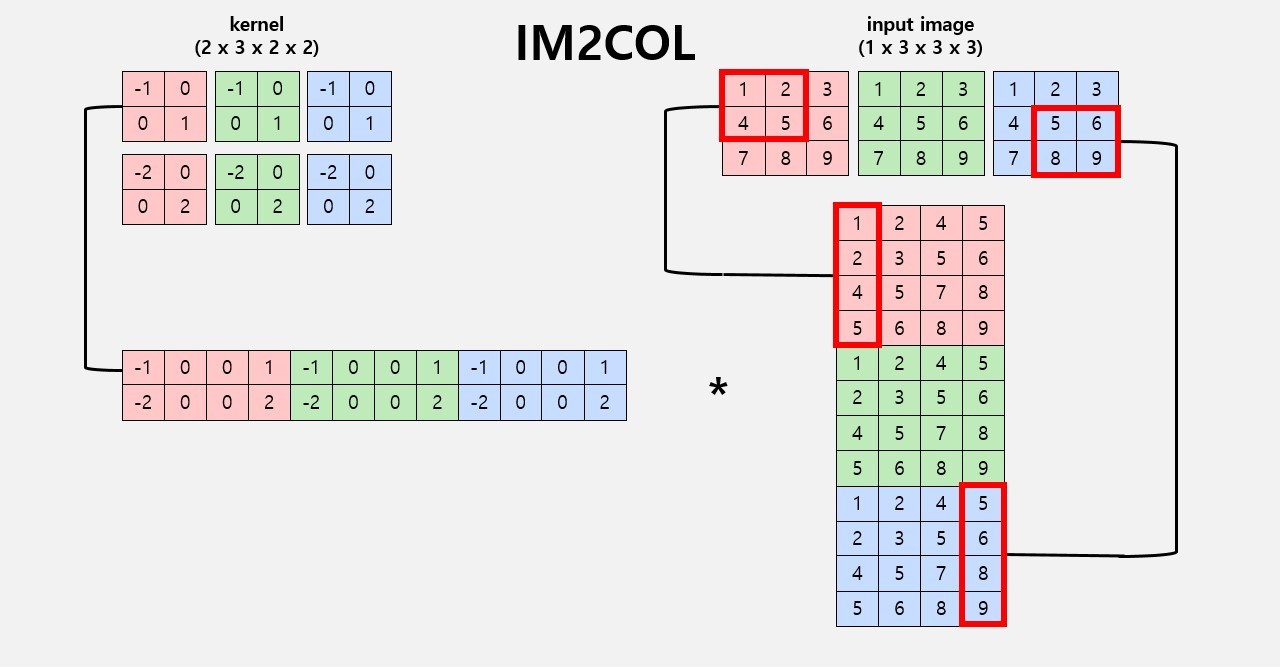
Naive Convolution 연산은 Loop를 7번 돌기 때문에 비효율적이다. n차원을 2D로 변환하는 IM2COL과 일반적인 행렬 곱인 GEMM을 이용해 이를 개선할 수 있다. 연산 속도 비교 결과 PyTorch > IM2COL & GEMM >>>>> Naive
6.[딥러닝] Activation, Pooling, Fully Connected layers 구현
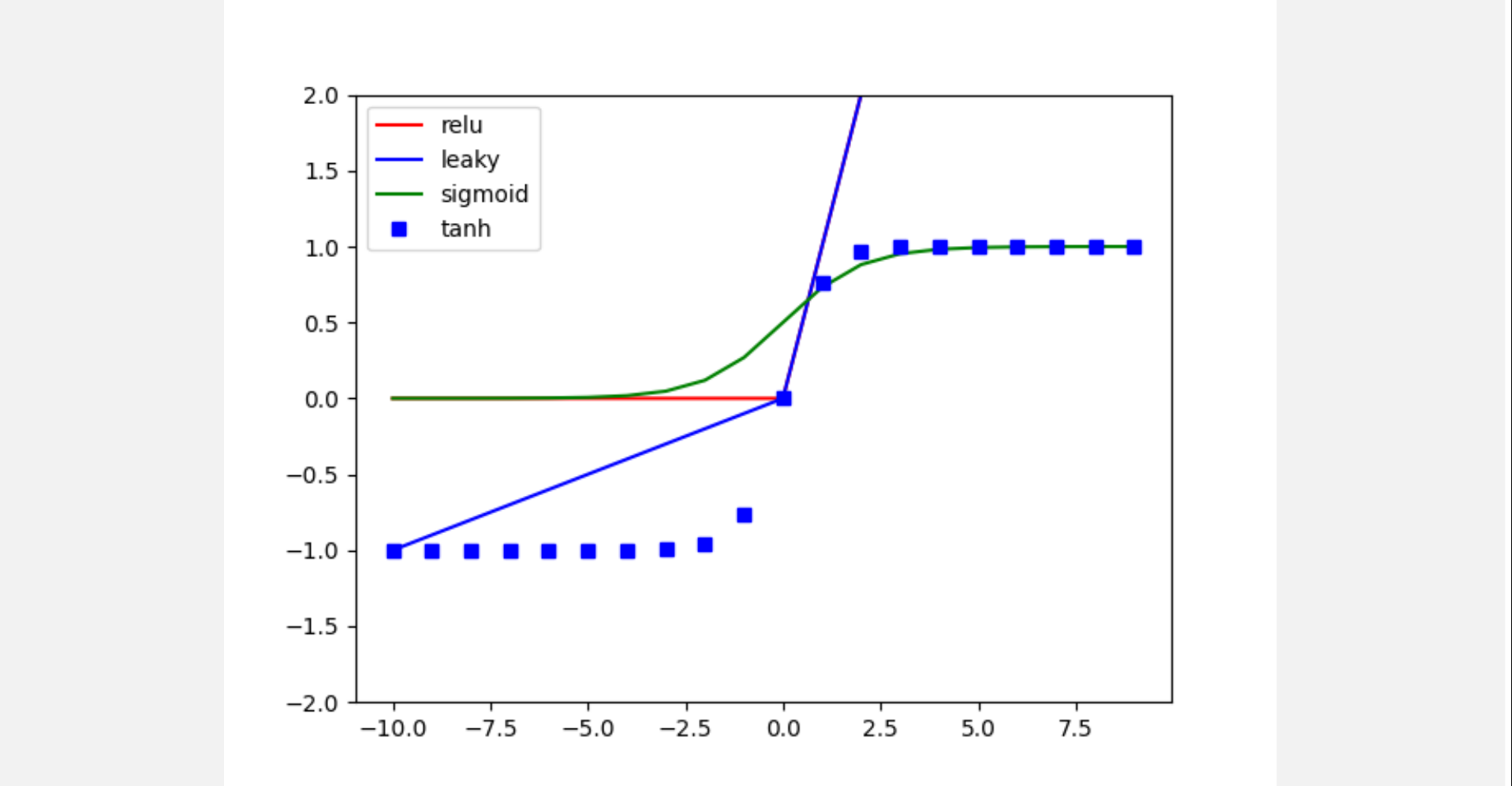
Activation, Pooling, Fully-Connected layer 구현
7.[딥러닝] Backpropagation in CNN
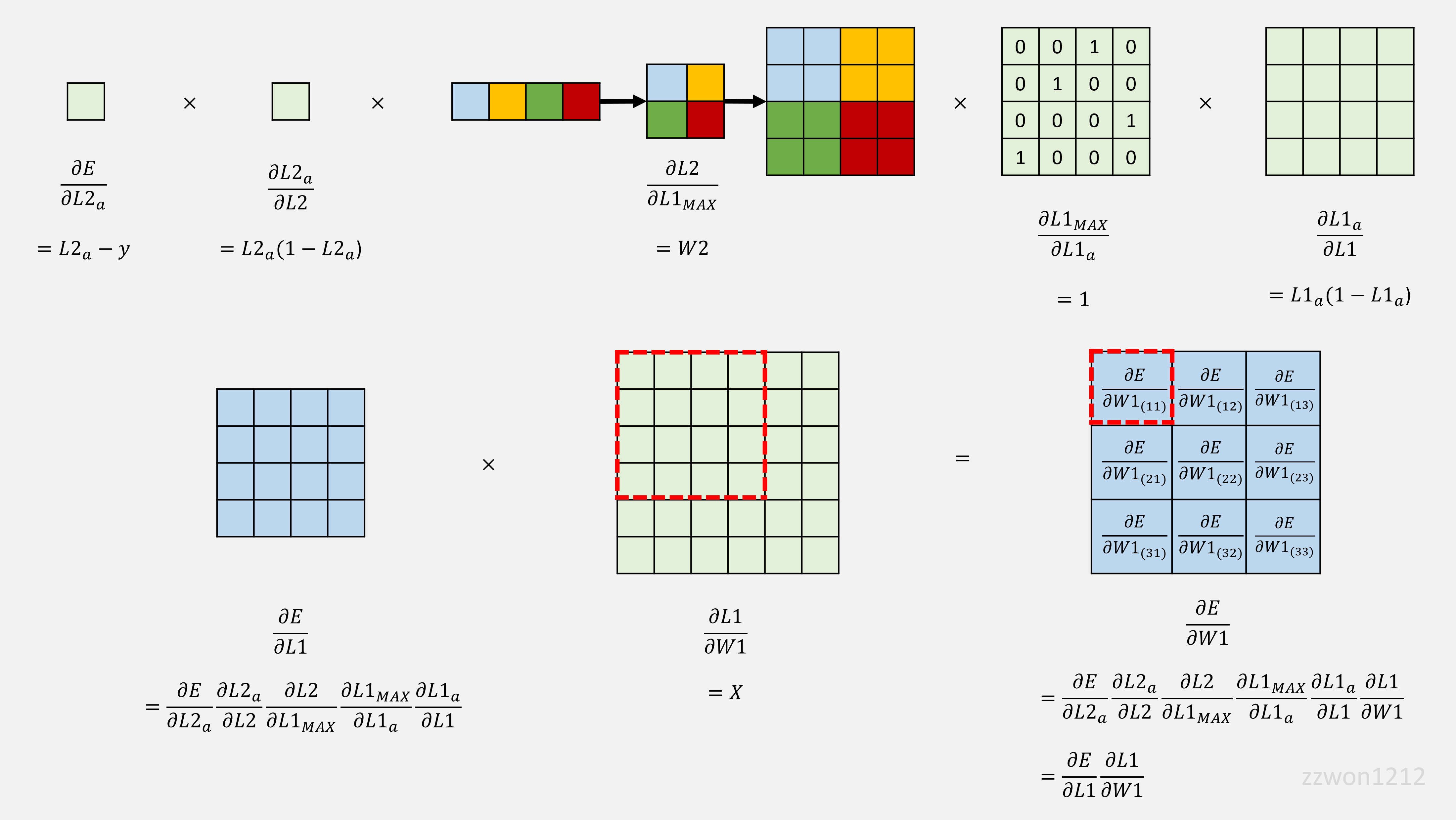
Logistic Regression과 CNN의 Backpropagation 과정을 살펴보았다. CNN의 역전파에 독특한 과정들이 있었다.(FC layer의 weight 크기 맞추기, Max Pooling의 gradients 계산, 역전파에서 Convolution 연산)
8.[딥러닝] Optimizer
SGD: 랜덤 데이터로 업데이트, MSGD: 미니 배치로 업데이트, Momentum: 이전 업데이트 고려, AdaGrad: 각 매개변수에 다른 학습률, RMSprop: 제곱된 그래디언트의 이동평균, Adam: Momentum과 RMSprop을 결합한 최적화 알고리즘
9.[딥러닝] L2 Regularization
Overfitting이 의심된다면 가장 먼저 Regularization을 적용해보기. L2 regularization이 Weight Decay라고 불리는 이유. Regularization이 Overfitting을 방지할 수 있는 이유.
10.[딥러닝] Dropout
Dropout
11.[딥러닝] Tuning Hyperparameter
좋은 hyperparameter random 조합을 찾고, 그 조합 부근에서 더 미세한 hyperparameter들의 random 조합을 만들어 그중 가장 좋은 조합을 찾는다. 한편, hyperparameter의 특성에 맞게 적절한 scale을 고려하여 탐색해야 한다.
12.[딥러닝] Batch Normalization
BN은 한 배치에서 층별, 은닉 유닛별 연산 결과를 활성화 함수 이전에 정규화. 값들이 다양한 분포를 가지도록 하는 scale과 shift를 학습을 통해 업데이트. 학습 속도 향상, 내부 공변량 변화 감소, 약간의 정규화 효과. test의 평균과 분산은 EMA를 활용.
13.[딥러닝] Object Detection
One stage & Two stage, Grid, Anchor box, Confidence score, Nonmax suppression
14.[딥러닝] Evaluation Metric
Confusion Matrix, Accuracy, Precision, Recall, F1 Score, PR Curve, Multi Class Confusion Matrix
15.[딥러닝] Applying the CenterPoint (3D Object Detection algorithm) to the nuScenes dataset
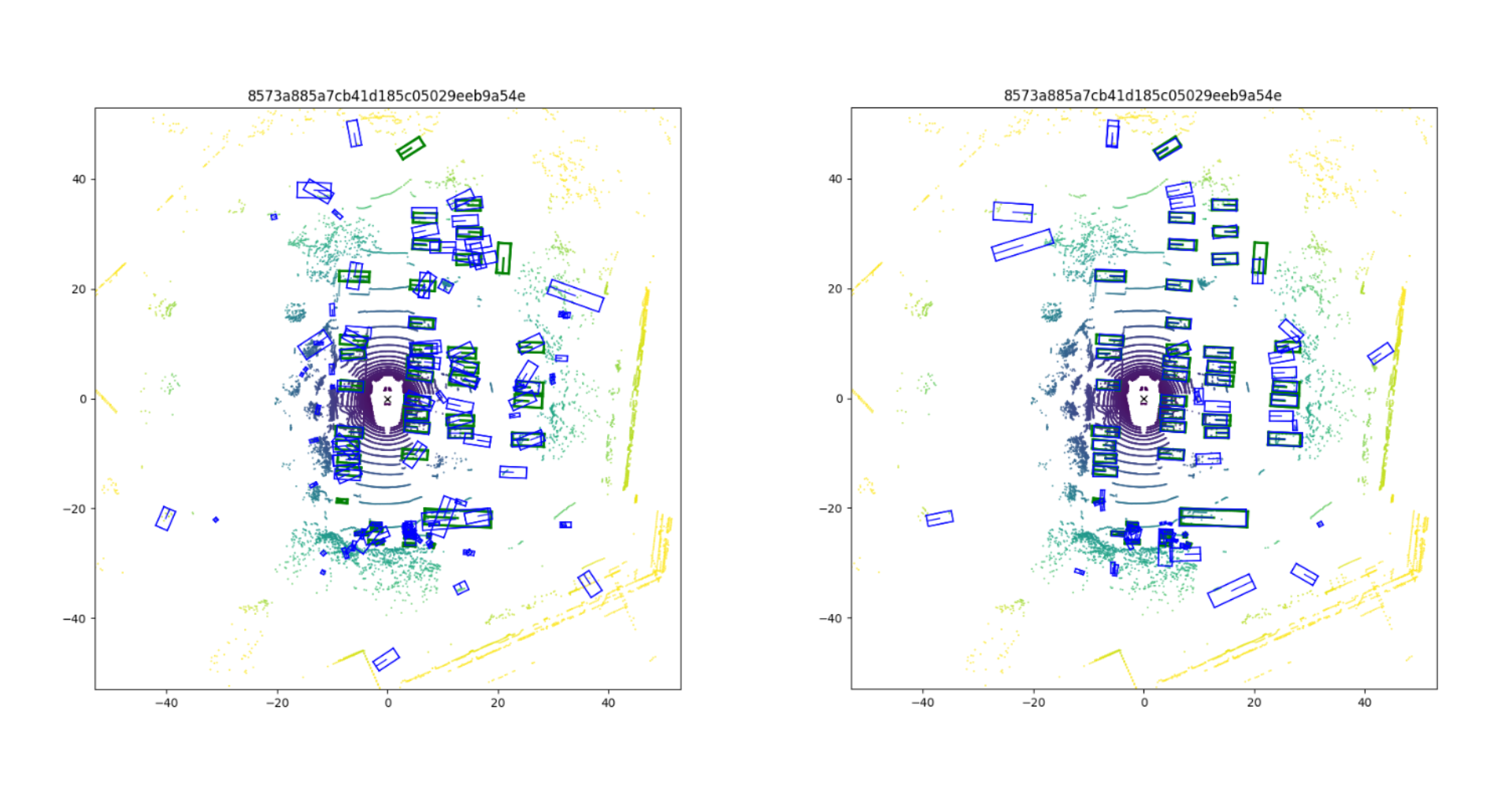
nuScenes dataset에 CenterPoint 알고리즘 적용하여 3D Object Detection하기
16.[딥러닝] AWS EC2 이용하기 (Amazon Web Services)

MFA를 설정한다. Launch instances로 instance를 생성한다. Start Instance로 생성된 instance를 실행한다. 이후 ssh를 이용해 Local에서 AWS에 접속한다. scp로 Local과 AWS 간 파일 전송이 가능하다.
17.[딥러닝] GoogLeNet (1 x 1 convolution and Inception network)
1 x 1 Convolution으로 채널 수를 조절할 수 있으며, 비선형성을 추가하여 복잡한 함수를 학습할 수 있다. Inception module은 다양한 크기의 필터를 사용하여 성능을 높이며, 이때 계산 비용을 줄이기 위해 bottleneck layer를 사용한다.
18.[논문 리뷰] YOLO v1 (You Only Look Once: Unified, Real-Time Object Detection)
YOLO v1은 전체 이미지를 grid로 나눈 후, 각 grid에서 객체의 bbox와 confidence, 클래스를 예측한다. Inference 시에는 Non-max suppression으로 수많은 bbox들 중 최적의 bbox들만을 남긴다.
19.[딥러닝] ResNet (Residual block and Skip connection)
residual block은 활성화 함수 출력값을 main path와 shortcut으로 전달하고, 이 skip connection을 통해 기울기 소실 문제를 해결하고 더 깊은 네트워크를 학습할 수 있게 해준다. ResNet은 이 block을 쌓아 만든 네트워크이다.
20.[딥러닝] 논문 모음
Convolutional Neural Network, Object Detection
21.[딥러닝] Focal Loss
One-stage detector의 정확도가 낮은 주요 이유는 객체와 배경의 클래스 불균형이다. Focal Loss는 easy example의 loss를 낮추어 모델이 informative한 hard example에 집중하도록 돕는다.
22.[논문 리뷰] ResNet (Deep Residual Learning for Image Recognition)
K He. Deep Residual Learning for Image Recognition. CVPR 2016.
23.[논문 리뷰] R-CNN (Rich feature hierarchies for accurate object detection and semantic segmentation)
R Girshick. Rich feature hierarchies for accurate object detection and semantic segmentation. CVPR 2014.
24.[논문 리뷰] Fast R-CNN
R Girshick. Fast R-CNN. ICCV 2015.
25.Neural Network - 시각적 이해를 위한 머신러닝 1
Loss Functions, Optimization, Neural Networks, Backpropagation, Training
26.CNN - 시각적 이해를 위한 머신러닝 2
CNN Case Studies, Video Classification, Two-Stream Models, 3D Convolution
27.RNN, Attention - 시각적 이해를 위한 머신러닝 3
RNN, LSTM, RNN-based Video Models, Attention Mechanism, Attention-based Video Models
28.Transformer - 시각적 이해를 위한 머신러닝 4
Transformers, Self-attention, Multi-head Self-attention, Masked Multi-head Self-attention, Positional Encoding, BERT
29.Transformer for Image - 시각적 이해를 위한 머신러닝 5
Transformer-based Image Models, ViT, DeiT, Swin Transformer, CvT, Transformer-based Video Models, ViViT, TimeSFormer, MViT
30.Object Detection - 시각적 이해를 위한 머신러닝 6
Object Detection, Two-stage model, One-stage model, DETR (Detection Transformer)
31.Segmentation - 시각적 이해를 위한 머신러닝 7
Semantic Segmentation, Deconvolution Network, U-Net, Instance Segmentation, Mask R-CNN, Segmentation with Transformers, Segmenter, DPT
32.Metric Learning - 시각적 이해를 위한 머신러닝 8
Metric Learning, Learning to Rank, NDCG, Triplet Loss, Contrastive Learning, Pairwise Loss, Negative Sampling, SimCLR, NCE
33.Multimodal Learning - 시각적 이해를 위한 머신러닝 9
Multimodal Learning, Image / Video Captioning, Transformer-based Image / Video-text Models, Audio Modeling, Multimodal Metric Learning, CLIP
34.DINO
DINO 학습 과정, Visualization