Emerging Properties in Self-Supervised Vision Transformers
-
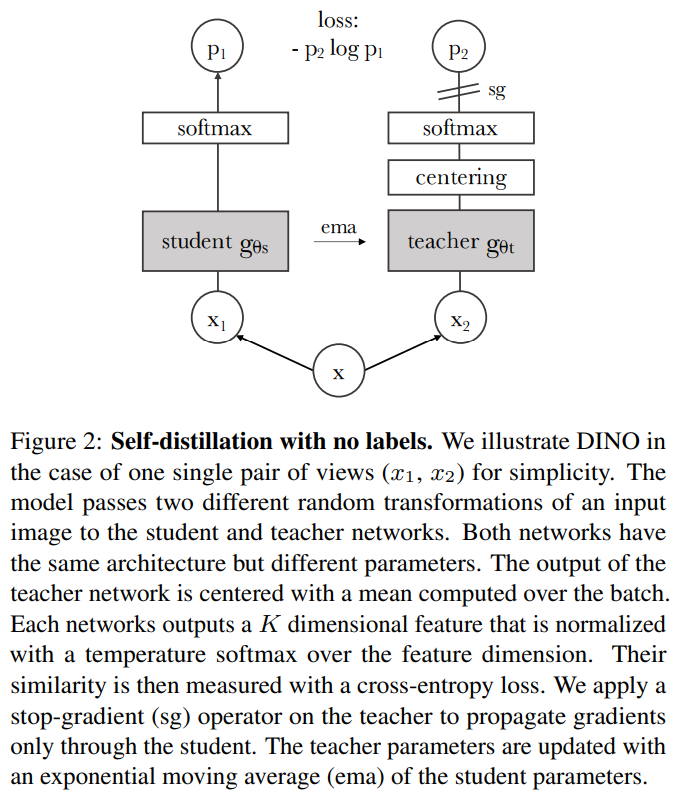
-
multi-crop trainig
- two global views → teacher network의 input
- several local views → student network의 input
-
distillation 과정
- student, teacher 모두 초기화된 parameter들로 의미 없는 softmatx값을 출력함. 이때 각 softmax 결과는 gt label 없이 네트워크가 self-supervised로 학습하여 예측한 일종의 cluster가 되어 갈 것임. (고양이 이미지들은 0에, 강아지 이미지들은 1에, ...)
- student network update
student network는 augmentation, local view를 input으로 받음. student의 softmax 출력을 teacher의 softmax 출력과 cross-entropy로 비교하여 parameter를 update함. (초기에는 teacher의 softmax가 의미 없긴 하지만...) - teacher network update
loss로 update하지 않고, student의 parameter를 EMA하여 update함. EMA를 이용해 안정적으로 update하게 함. - 반복
반복함으로써 self-supervised 방식으로 이미지의 본질적인 feature를 점진적으로 잘 clustering할 수 있게 됨.
-
Visualization





JUST DO IT.