The Kalman filter assumes variables are random and Gaussian distributed. Each variable has a mean value , which is the center of the random distribution (and its most likely state), and a variance , which is the uncertainty.
State
- predict the next state (at time ) by using the current state (at time ):
- : prediction matrix
Adding external influence
- : external influence (e.g. acceleration)
- : control matrix
- : control vector
Adding external uncertainty
-
Prediction step:
- : external uncertainty (noise covariance)
- The new estimate is a prediction made from previous best estimate, plus a correction for known external influences.
- The new uncertainty is predicted from the old uncertainty, with some additional uncertainty from the environment.
-
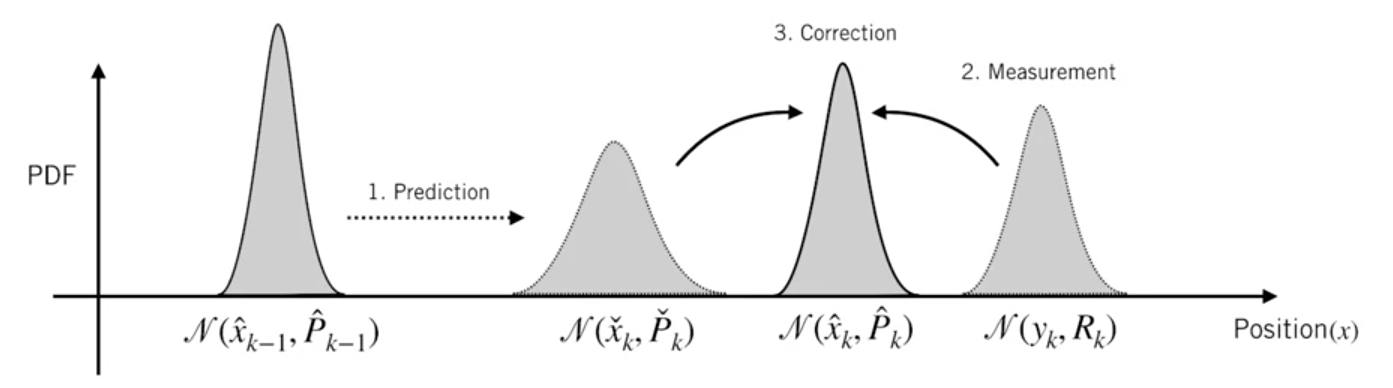
Now, we have a fuzzy estimate of where our system might be, given by and . What happens when we get some data from our sensors?
Refining the estimate with measurements
-
Notice that the units and scale of the reading might not be the same as the units and scale of the state we’re keeping track of. You might be able to guess where this is going: We’ll model the sensors with a matrix, .
-
We can figure out the distribution of sensor readings we'd expect to see in the usual way:
-
We’ll call the covariance of the sensor noise (uncertainty) . The distribution has a mean equal to the reading we observed, which we’ll call .
-
So now we have two Gaussian blobs: One surrounding the mean of our transformed prediction, and one surrounding the actual sensor reading we got. We must try to reconcile our guess about the readings we’d see based on the predicted state (pink) with a different guess based on our sensor readings (green) that we actually observed:
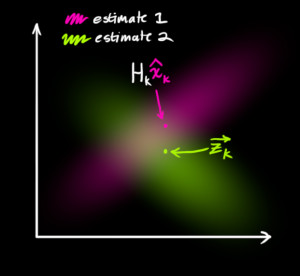
-
The Product of Two Univariate Gaussian PDFs is a scaled Gaussian PDF.
- We can simplify by factoring out a little piece and calling it :
- We can extend this formula to matrix version.
- is called the Kalman gain.
- As a result, we can take our previous estimate and add something to make a new estimate.
- We can simplify by factoring out a little piece and calling it :
Update step
-
We have two distributions: The predicted measurement with , and the observed measurement with .
-
Plug these into above formula.
- where the Kalman gain is:
- where the Kalman gain is:
-
We can knock an and an off the front and the end of terms properly.
-
is our new best estimate. We can go on and feed it (along with ) back into another round of predict or update as many times as we like.
Of all the math above, all we need to implement are equations , , and .
📙 참고
