1. Tuning Process
-
Andrew Ng's recommendation
- 1순위
- 2순위
- of Momentum
- # of hidden units
- mini-batch size
- 3순위
- # of layers
- learning rate decay
- Never tune
- of Adam optimizer
- 1순위
1.1. Grid
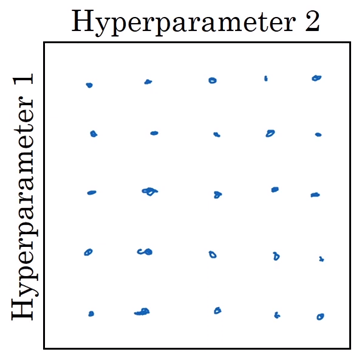
- If # of hyperparmeter is small, this is ok.
- 5개의 Hyperparameter1만 확인할 수 있다.
1.2. Random

- Grid에 비해 더 다양한 Hyperparameter1을 확인할 수 있다.
1.3. Coarse to fine
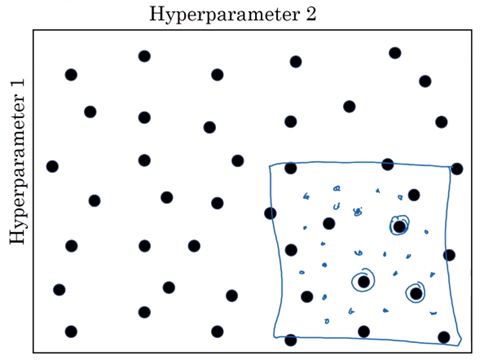
- 1.2.의 random으로 좋은 hyperparameter 조합을 찾은 뒤, 다시 그 조합 부근에서 더욱 미세한 hyperparameter들의 random 조합을 만들어 그중 가장 좋은 조합을 찾는다.
2. Using an Appropriate Scale
# of hidden units나 # of layers를 선택할 때는 random이나 격자점을 사용해도 문제없다. 그러나 모든 hyperparameter가 이렇지는 않다.
2.1. Learning rate
0.0001~1까지를 탐색하는 경우 random하게 설정하게 되면, 0.1~1에 90%를 할당하고 0.0001~0.1까지 나머지 10%를 할당한다. 이 비합리적인 선형적 방법 대신 합리적인 Log 방법을 사용하는 것이 좋다.
2.2. of Momentum
0.9~0.999에서 탐색하는 경우는 2.1.과 비슷하지만 여기서는 반대로 exp를 이용하는 것이 좋다. 이러한 방법이 선형적인 방법보다 더 합리적인 이유를 이해해보자면, 에서 로 바뀌는 경우 지난 10개의 평균을 이용하게 되는 셈이지만, 에서 로 바뀌는 경우 지난 1000개의 평균을 이용하는 것에서 지난 2000개의 평균을 이용하는 것이 된다. 따라서 가 1에 가까워질수록 작은 변화에도 민감하게 반응하기 때문에 가 1과 가까운 곳에서 조금 더 조밀하게 탐색해야 한다.
📙 참고

JUST DO IT.