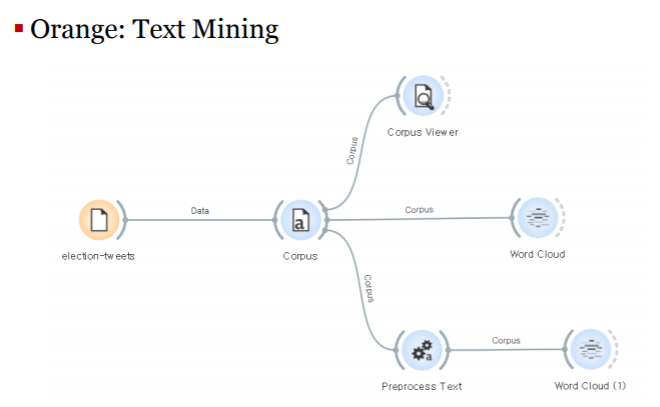
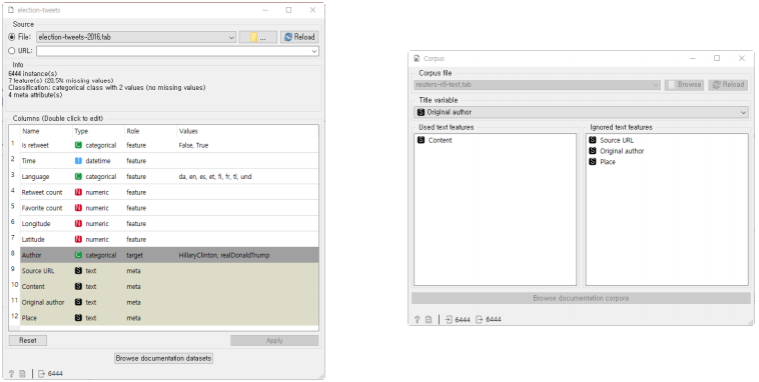
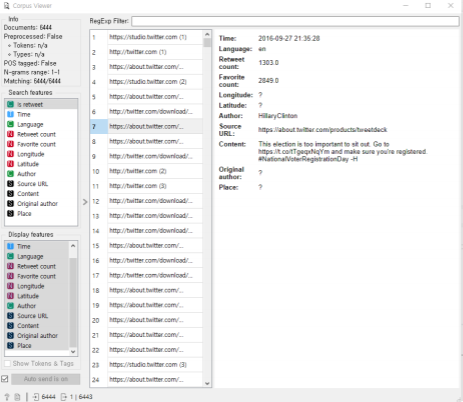
비정형 데이터와 자연어 처리
비정형 데이터: Unstructured Data
미리 정의된 데이터 모델이 없거나, 미리 정의된 방식으로 정리되지 않은 정보
ex)이미지 텍스트 사운드 동영상 기타 등등
비정형 데이터의 처리: Embedding
- 비정형 데이터의 특징을 추출하여 정형 데이터로 바꾸기
- 이미지 임베딩: ImageNet
- 텍스트 임베딩: Bag of Words, Word2Vec
자연어 처리: NLP, Natural Language Processing
자연어: 사람이 일상 생활에서 사용하는 언어
자연어 처리: 번역, 요약, 분류, 감성 분석, 챗봇, 기타 등등
자연어의 구성: 문서, 문장, 단어
-문서: 문장들의 집합. Document
-문장: 단어들의 집합
-단어: 텍스트 분석의 기본 단위. Word = Term
텍스트 전처리: Text Preprocessing
코퍼스(Corpus): 말뭉치, 텍스트 분석을 위한 데이터셋.
텍스트 분석을 위한 전처리 과정:
-변환: Transformation
-토큰화: Tokenization
-정규화: Normalization
-필터링: Filtering
-N그램:N-grams Range
-품사 태깅: POS Tagger
변환: Transformation
Test Cleansing: 텍스트에서 불필요한 요소를 제거하고 수정

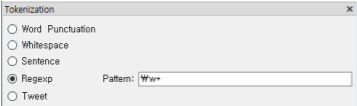
토큰화: Tokenization
문서에서 문장을 분리, 또는, 문장에서 단어를 분리
정규 표현식: Regular Expression
-규칙을 기반으로 토큰을 분리할 수 있음
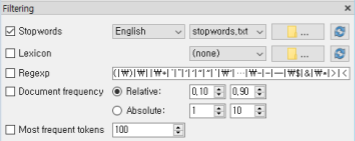
필터링: Filtering
불용어(Stopwords) 처리: 분석에 필요하지 않은 단어를 제거
출현 빈도수가 높은 단어만 선택
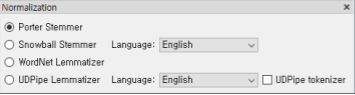
정규화: Normalization
형태소 분석: 같은 의미지만 서로 다른 단어들을 하나의 단어로 일반화
-어간 추출: Stemming
-표제어 추출: Lemmatization
N-그램: N grams Range
분석 결과의 단위를 연속적인 N개의 토큰으로 구성

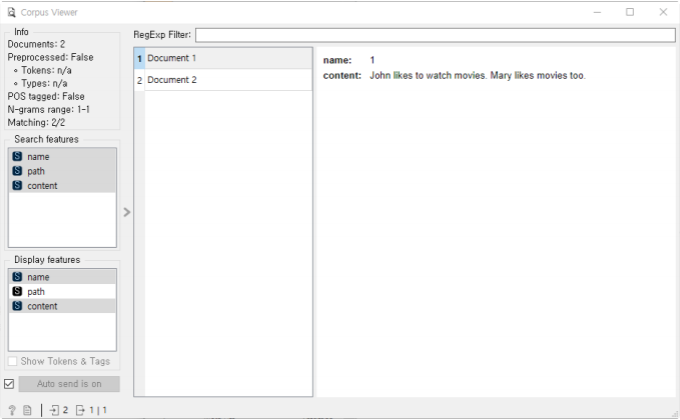
How are you? Fine, thank you. And you?
1-gram =[ How,are,you,...]
2-gram=[(How,are),(are,you)...]
품사 태깅: POS(Part-Of-Speech) Tagger
각 단어의 품사를 태그하여 단어의 의미 파악

I believe I can fly. Because I am a fly.
같은 fly여도 전자는 동사 후자는 명사
Stemming ->(바나나,를,먹,으면,나,한테,반,하나,?)
N-gram-> {(바나나,먹),(먹,나),(나,반)}
POS-tagging->(바나나명사,먹다동사,나명사,반하다동사)
텍스트 임베딩과 단어 가방
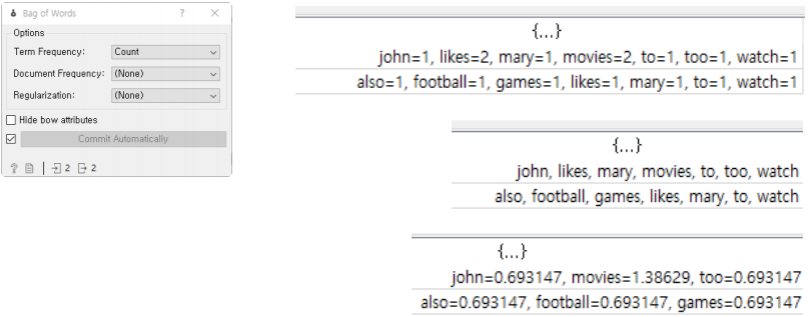
단어 가방: Bag of Words, BoW
문서(Document)에 포함되어 있는 단어(Word)의 빈도 수로 특징 추출
순서나 문맥을 무시하고 가방에 단어를 담기 때문에 처리가 간단함
->가방에 순서를 무시하고 담아서 문서의 특성을 벡터화할 수 있는 기법
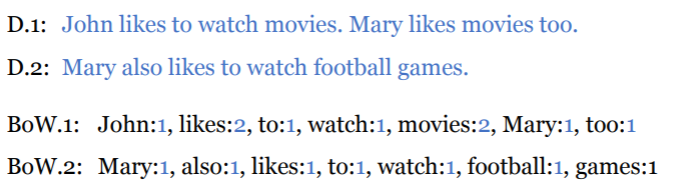
단어 빈도: TF, Term Frequency
특정 단어가 문서 내에서 얼마나 자주 등장하는가?
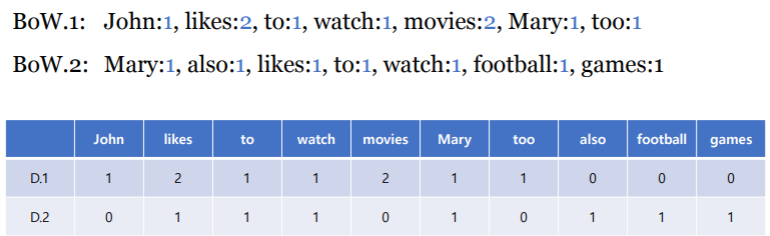
문서 단어 행렬: DTM, Document-Term Matrix
각 문서별로 해당 단어가 몇 번 나타나는가를 표시한 행렬
Term Frequency:
-Count: 단어가 나타나는 횟수로 만드는 경우
-Binary: 단순하게 단어가 포함되어 있는가의 여부
-Sublinear: 단어-빈도(TF)의 로그값
문서 빈도: DF, Document Frequency
단어의 빈도 수만으로 벡터화를 할 경우, 단어의 중요성을 간과하게 됨
예) The anatomy of a large-scale hypertextual web search engine.
특별한 단어에 가중치를 주는 방법: 단어의 희소성을 고려
- 개별 문서에 자주 나타나는 단어는 높은 가중치를 주되,
- 모든 문서에 전반적으로 자주 나타나는 단어에 대해서는 페널티를 부여
Document Frequency:
-IDF: Inverse Document Frequency
-Smooth IDF: Divide-by-Zero 방지를 위해 DF에 1을 더한 값을 사용
TF-IDF: Term Frequency - Inverse Document Frequency
텍스트 마이닝과 정보 검색에서 많이 이용하는 가중치 부여 방법
TF-IDF는 단어 빈도(TF)와 역 문서 빈도(IDF)를 곱한 값=TFIDF
-전체 문서를 D, 문서를 d, 단어를 t라 할때
-TFIDF(t,d,D)= TF(t,d) IDF(t,D)
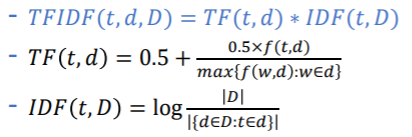
단어 가방의 한계:
희소 행렬: Sparse Matrix
-많은 문서에서 많은 단어를 추출하면 단어 집합의 크기가 커지고, 각 문서에 포함된 단어의 수는 일정하므로, 매우 큰 희소 행렬이 됨
-희소 행렬의 연산에 적절한 행렬 처리가 필요함
문맥과 의미: Contexts and Semantics
- BoW는 단어의 순서를 고려하지 않으므로 문맥적 의미를 무시함
- 단어와 문장의 순서를 고려하여 문맥과 의미를 반영할 필요가 있음
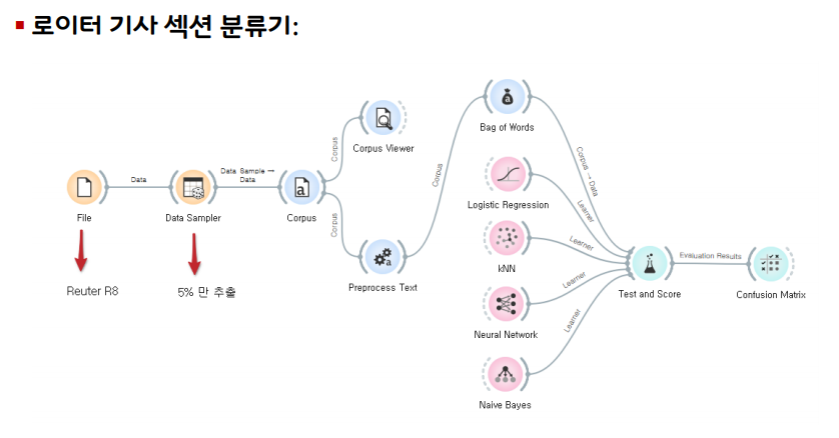
텍스트 분석과 텍스트 분류
텍스트 분류: Text Classification
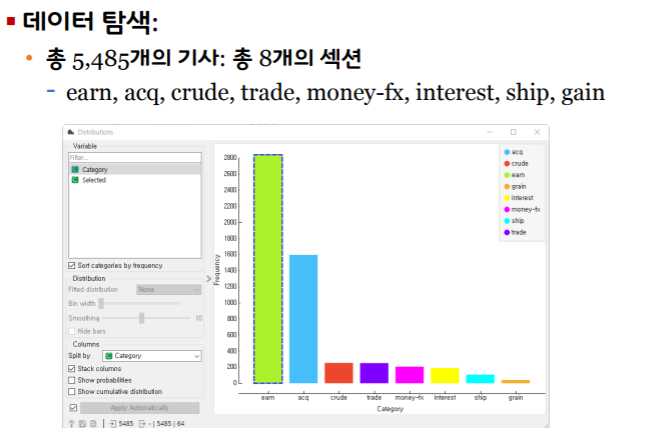
주어진 문서를 특정 카테고리로 분류하는 기법
ex) 뉴스 기사 자동 분류, 스팸 메일 필터링.
reuter-r8-train.tab
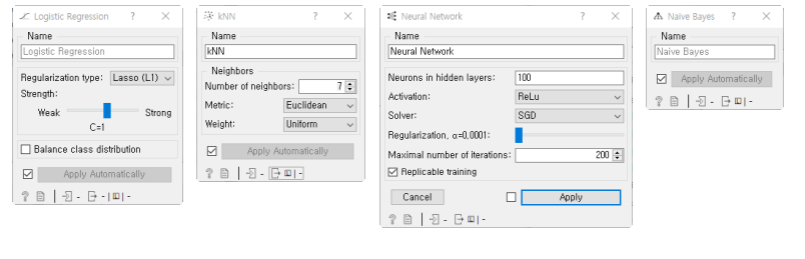
아버지를 아버지라 "아버지"의tf-idf값은? cosine distance값은?