데이터 과학 기초
1.데이터과학 기초-(1)데이터 과학이란?

첫글은 현재 수강하고 있는 데이터 과학 기초 수업에 대해 정리해 보겠다. 머신러닝이나 딥러닝을 다루기 전에 이러한 데이터 관련 기본 지식을 쌓고 가는 것이 좋을 것이라 개인적으로 생각한다ㅎㅎ 데이터 과학이 뭐길래 데이터 과학이란? 데이터(data)는 어떤 변수에
2.데이터과학 기초-(2)데이터 과학을 위한 도구

저번 포스팅에서 언급했듯이, 이번 데이터 과학 공부는 이해를 목적으로 이루어지는 수업이기에 orange 3 data mining 프로그램을 사용해서 간단하게 데이터 과학을 학습할 것이다.이번 시간에는 아주 유명한 고흐의 붓꽃 문제에 대해서 알아보자.문제정의: 위의 그림
3.데이터과학 기초-(3)탐색적 데이터
오늘은 탐색적 데이터 분석 Exploratory Data Analysis에 대해 살펴보자탐색적 데이터 분석(Exploratory Data Analysis)은 데이터에 대한 기본적인 이해를 하기 위한 탐색과 분석과정을 말한다. 이러한 EDA는 데이터의 기본적인 유형,구조
4.데이터과학 기초-(4)데이터 전처리
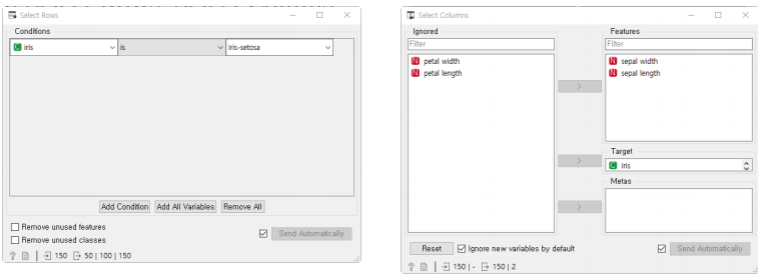
4번째 포스팅이다,, 앞으로 개념이 점점 어려워지는 것같지만 이해만 하고 수식 계산은 다루지않기 때문에,,ㅎㅎ 어렵다고 징징대는 것도 좀 ㅎ~ 데이터 전처리란 무엇일까? Data Preprocessing
5.데이터과학 기초-(5)선형회귀
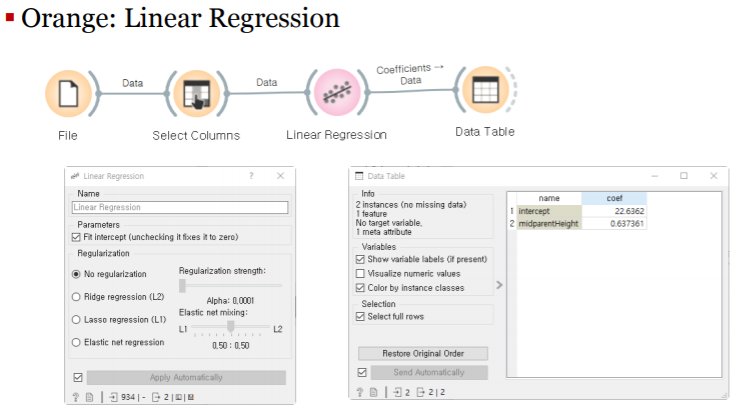
'회귀'의 사전적 의미: 되돌아 가다.회귀라는 용어의 유래: 프래시스 골턴의 연구에서 처음으로 사용골턴의 연구 주제: 부모의 키와 자녀의 키는 유전적으로 상관 관계가 있는가?galton데이터 셋을 이용해서 값을 살펴보자:Galton.csvchildHeight: 종속 변
6.데이터과학 기초-(6)이진분류
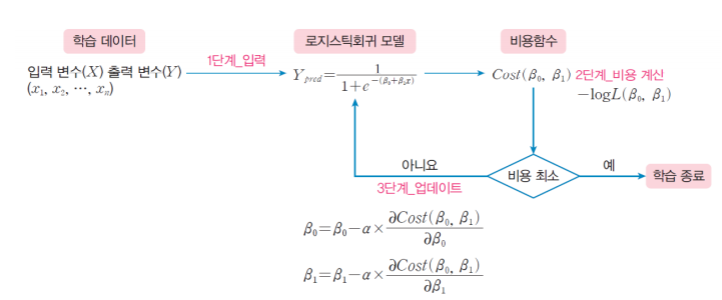
이진 분류와 로지스틱 회귀 분류와 군집화:Classification vs Clustering 분류:지도 학습: 정답이 있는 데이터셋을 분류하는 것 > EX) iris데이터 셋에서 품종의 분류, titanic 데이터셋에서 생존 여부를 예측 군집화 :비지도 학습:정답이
7.데이터과학 기초-(7)군집 분석
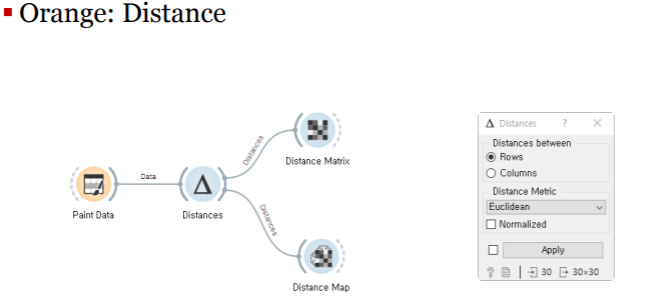
데이터를 서로 비슷하거나, 서로 가까운 것들끼리 묶어서 나누는 것비지도 학습이다!: 정답(라벨)이 없음. 유사도와 거리로 판단\-유사도(similarity):두 데이터가 얼마나 가까운 가를 나타내는 척도\-거리(distance):두 데이터 사이의 거리\-s=1-d,s=
8.데이터과학기초-(9)인공신경망의 이해
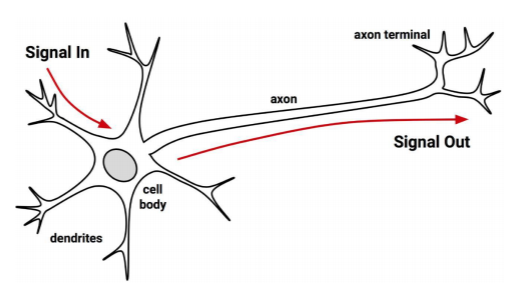
사람의 뇌가 동작하는 방식을 그대로 흉내내어 만든 수학적 모델뉴런과 시냅스: neuron and synapse\-사람의 뇌는 뉴런(신경세포)들이 서로 연결되어 다른 뉴런들과 상호작용\-입력으로 받은 전기 신호를 적당히 처리하여 다른 뉴런에 전달\-신호를 전달하려면 입력
9.데이터과학 기초-(10)다층 퍼셉트론과 딥 러닝
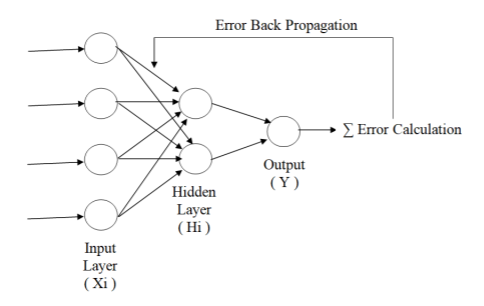
\-행동(action)에 따른 보상(reward)을 줌으로써,\-보상을 극대화하기 위해 동적으로 학습을 하며 행동을 조정함\-DNN(Deep Neural Network)을 이용한 강화 학습 방법\-DNN = MLP + Backpropagation출력값과 실제값의 오차를
10.데이터과학 기초-(11)비정형 데이터와 자연어 처리

미리 정의된 데이터 모델이 없거나, 미리 정의된 방식으로 정리되지 않은 정보ex)이미지 텍스트 사운드 동영상 기타 등등비정형 데이터의 처리: Embedding비정형 데이터의 특징을 추출하여 정형 데이터로 바꾸기이미지 임베딩: ImageNet텍스트 임베딩: Bag of
11.데이터과학 기초-(12)베이즈 정리
베이즈 정리와 나이브 베이지안 나이브 베이지안 분류기:Naive Bayesian Classifier 특징 변수(feature)가 서로 독립사건이라는 순진한 가정하에 -베이즈 정리를 적용하여 확률적으로 목적변수(target)을 추론하는 분류기 예) 스팸 메일 분류기,
12.데이터과학 기초-(13)그래프 이론
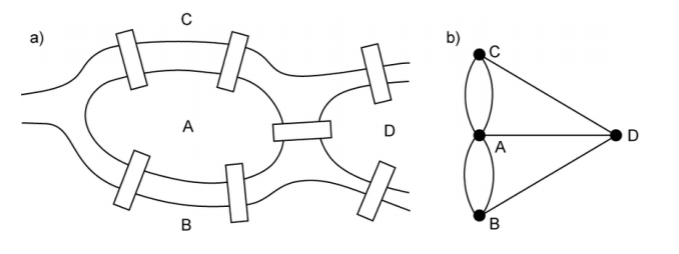
정점의 집합과 간선의 집합으로 구성된 그래프를 연구하는 수학의 한 분야그래프: G=(V,E)\-V:정점의 집합, E:간선의 집합다양한 학문 분야에 펼쳐져 있던 복잡계의 연구 대상들이\-'네트워크'라는 하나의 주제로 통일되면서 발생한 학제간 연구 분야복잡계 네트워크: C
13.데이터과학 기초-(14)네트워크의 유사도와 군집도

그래프 내부의 인접한 두 정점 간의 유사도를 측정하려면?\-두 노드의 이웃이 얼마나 겹치는 지를 평가유사도 척도를 0,1 구간의 값으로 정규화 하는 방법자카드 유사도:Jaccard Similarity코사인 유사도:Cosine Similarity전이적 연결: Transi