베이즈 정리와 나이브 베이지안
나이브 베이지안 분류기:Naive Bayesian Classifier
특징 변수(feature)가 서로 독립사건이라는 순진한 가정하에
-베이즈 정리를 적용하여 확률적으로 목적변수(target)을 추론하는 분류기
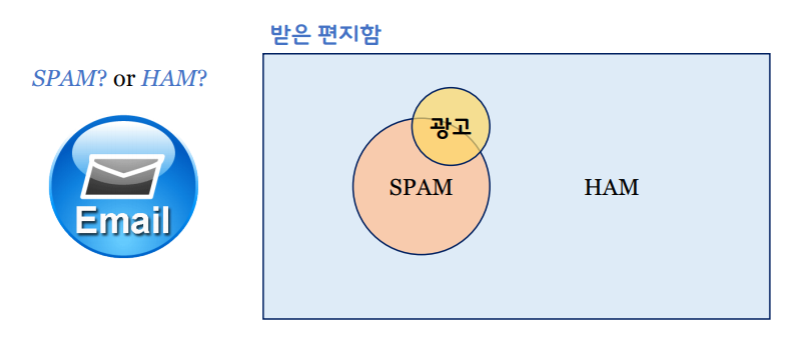
예) 스팸 메일 분류기, 암 진단
확률: Probability
시행, 사건, 확률: tial, event, and probability
-시행=동전 던지기, 사건의 집합: S={ H, T }
-확률: P(H)= 동전 던지기를 했을 때, 앞면(H)이 나올 확률
-사건: 상호배타적이고 포괄적(mutually exclusive and exhaustive)
결합 확률: JOINT Probability
P(A교B):두 사건 A와 B가 동시에 일어날 확률
독립 사건:Independent Events
-사건 A가 일어나는 것과 무관하게 사건 B가 일어나는 경우
예) A:동전의 앞면이 나오는 사건, B: 주사위의 짝수가 나오는 사건
종속 사건:Dependent Events
-두 사건 A와 B가 독립사건이 아닌 경우
-예) A:주사위의 홀수가 나오는 사건, B:주사위의 소수가 나오는 사건
두 사건 A,B가 독립사건일 경우:
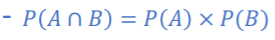
조건부 확률:Conditional Probability
P(A|B): 사건 B가 발생한 경우, 사건 A가 발생할 확률
두 사건 A와 B가 독립사건이라면,
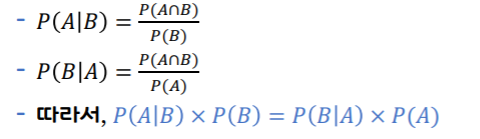
베이즈 정리: Bayes Theorem
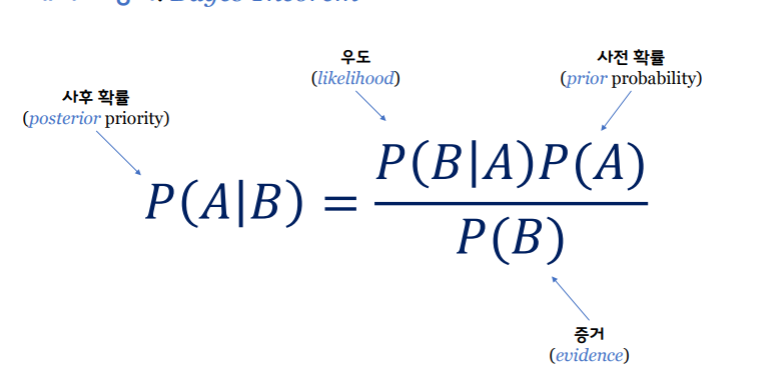
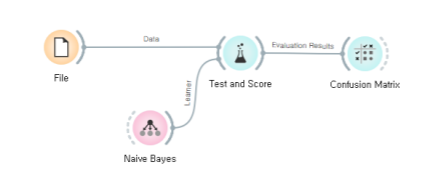
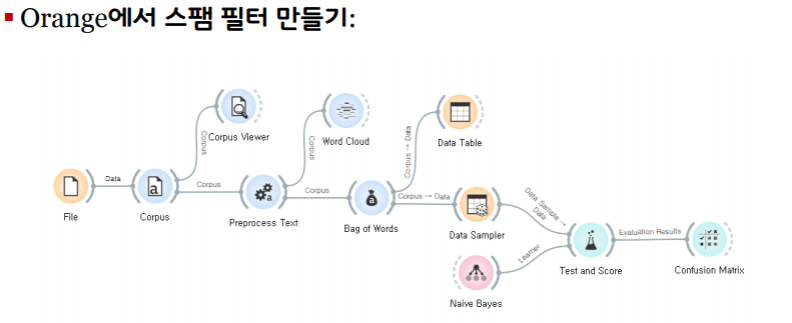
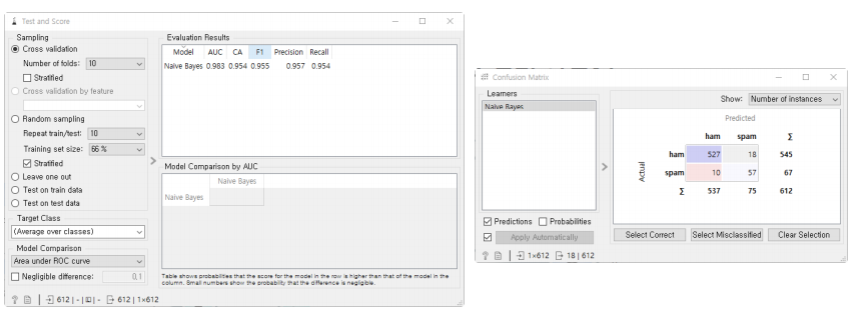
스팸 메일 분류기 만들기:
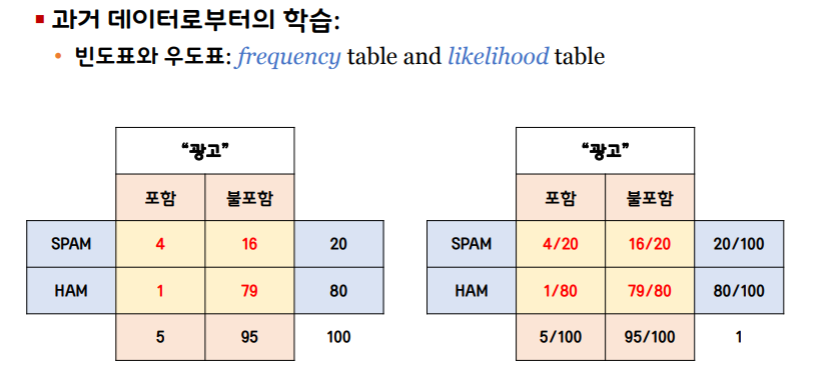

나이브 베이지안 알고리즘:
매우 순진한 가정: 사전 확률을 구성하는 사건은 모두 독립사건이다.
만약, 내가 받은 이메일에 다음과 같은 단어들이 포함되었다면?

나이브 베이지안 분류기:
사후 확률을 통해서 해당 사건이 발생한 것인지 여부를 예측
예) 스팸 메일일 확률이 90%, 암 환자일 확률이 98%
순진하고, 때로는 잘몬된 가정을 했음에도 불구하고 우수한 성능을 보임
스팸 메일 분류기 만들기
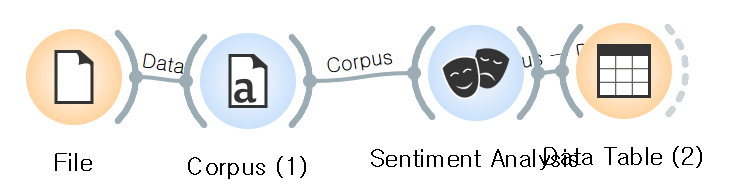
오피니언 마이닝과 감성 분석
오피니언 마이닝과 감성 분석
문서의 감정을 긍정/중립/부정 등으로 파악하기 위한 방법
소설 미디어, 온라인 리뷰, 영화 댓글 분석 등에 다양하게 활용
감성 분석을 위한 지도 학습:
학습 데이터에 긍정/부정/중립 등의 라벨이 포함되어 있음
기존의 텍스트 기반 분류 알고리즘과 동일한 방법으로 분석 가능함.
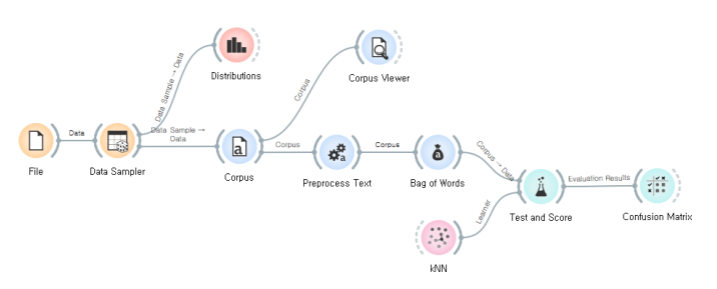
IMDB 영화 리뷰 데이터 셋
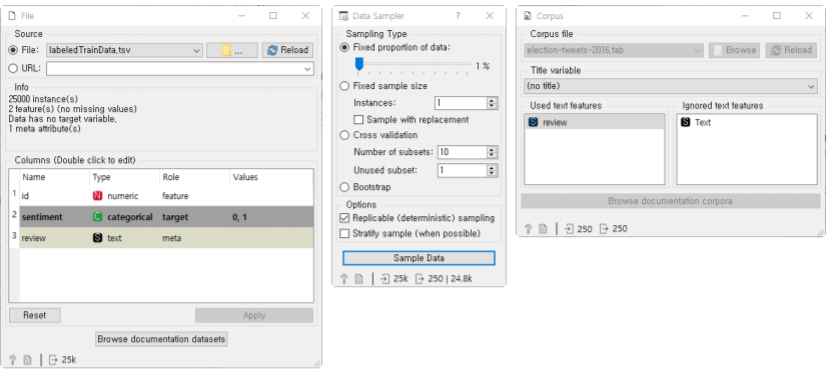
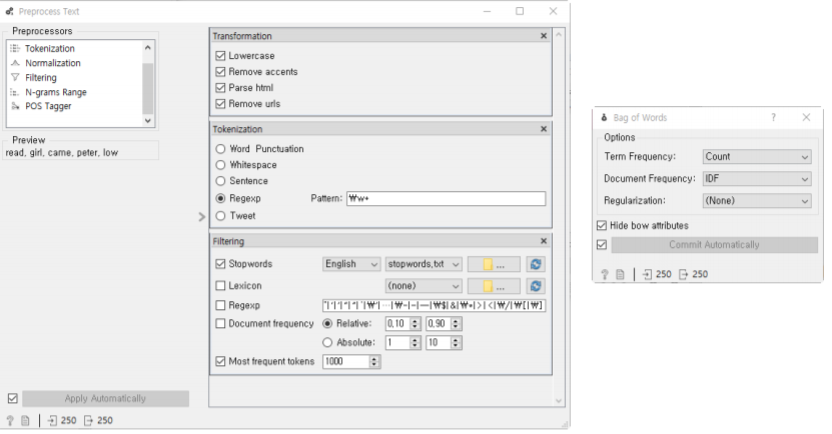
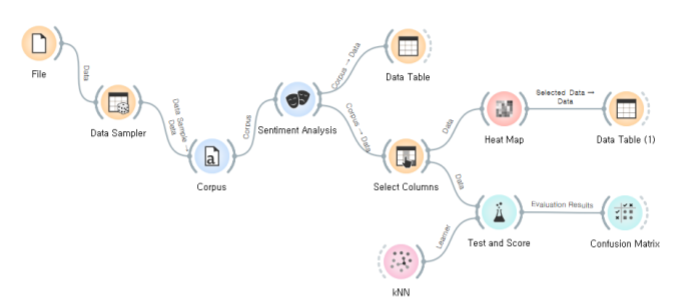
감성 분석을 위한 비지도 학습
어휘사전(Lexicon)을 기반으로 텍스트의 감성을 분석
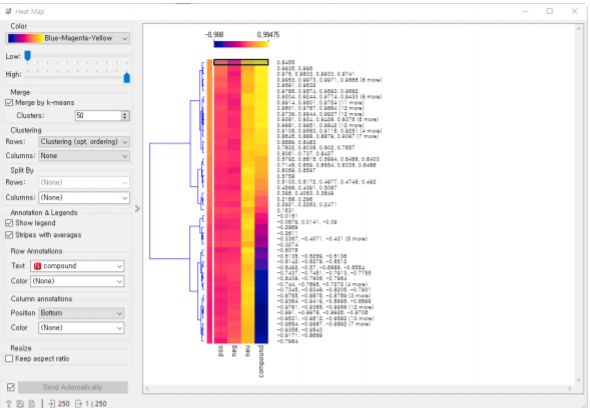
감성 지수(극성 점수):Polarity Score
-부정(-1)에서 긍정(+1)까지, 감성의 정도를 의미하는 점수 1<=x<=1 ex) good=0.8
-단어의 위치, 주변 단어, 문맥, 품사(POS)등을 고려해서 점수 부여
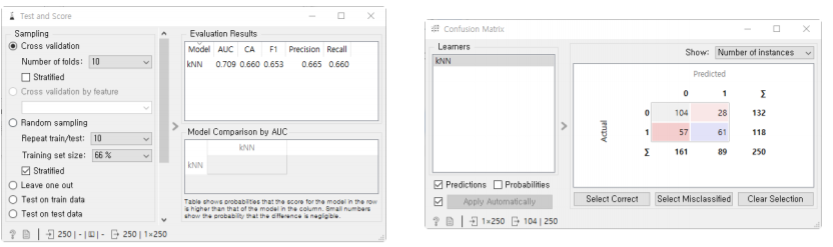
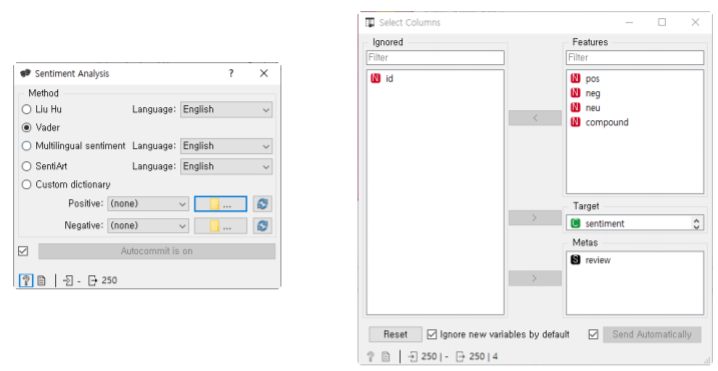
감성 분석을 위한 라이브러리:
-LIU-HU:NLTK에 포함된 Lexicon 기반의 감성 분석 모듈
-VADER: 소셜 미디어의 텍스트에 특화된 감성 분석 모듈
-SentiArt:VSM(Vector Space Model) 기반의 감성 분석 모듈
연속형 변수를 베이즈 정리로 적용하기위해 여러 구간으로 나눔 나이브 베이지안은 4개이 구간으로 나누어 처리한다.
어휘사전을 이용하는 감성 분석 방법을 Lexicon-based Opinion Mining이라고 한다.
->