본 게시글은 데이터 과학 기초 수업을 듣고 정리한 글로, 참고 용도 정도로만 이용하시면 좋을 것 같습니다.
저번 포스팅에서 언급했듯이, 이번 데이터 과학 공부는 이해를 목적으로 이루어지는 수업이기에 orange 3 data mining 프로그램을 사용해서 간단하게 데이터 과학을 학습할 것이다.
이번 시간에는 아주 유명한 고흐의 붓꽃 문제에 대해서 알아보자.
고흐의 붓꽃

문제정의: 위의 그림에서 고흐가 그린 붓꽃(iris)는 어떤 품종일까?
데이터 수집: 고흐 그림의 붓꽃 데이터, Fisher의 IRIS dataset(유명한 문제라 이미 기본 내장 데이터셋이 있다)
데이터 전처리: 결측치, 이상치 등의 유무
데이터 탐색: 탐색적 데이터 분석
데이터 모델링: 붓꽃 품종 분류기를 학습시켜보자
데이터 분석: 고흐의 붓꽃 데이터를 분류해보자
문제에 대해 살펴보기전에, 붓꽃에 대해 간단하게 알아보자.

붓꽃에는 세 가지 종류가 있다.
setosa,versicolor,virginica
이러한 종류는 꽃받침(Separ)의 길이와 너비,꽃잎(Petal)의 길이와 너비로 구분 가능하다.
orange에 Fisher의 IRIS 데이터 셋으로 kNN(이부분은 이후에 살펴보자)을 학습하고
prediction을 통해 값을 예측 할 수 있다.
전체 워크플로우는 다음과 같다.
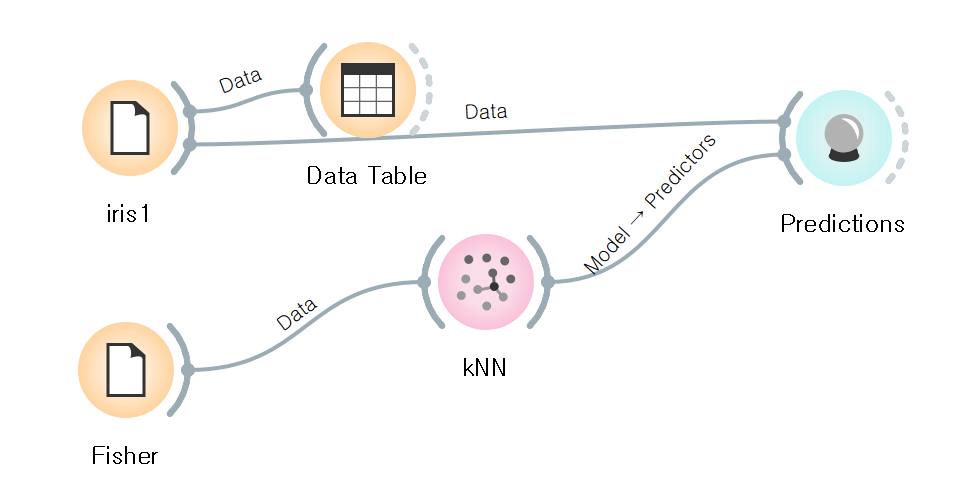
문제는 다음과 같은 data table을 가진 iris1 값에 대해 예측 값은 무엇인가?이다.
위와 같이 워크플로우를 작성하면 prediction을 통해 붓꽃의 종류가 무엇인지 예측 가능하다.
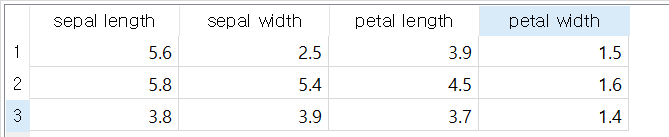
prediction을 클릭해보면? 다음과 같이 kNN의 예측 값이 3개지 데이터에 대해 모두 versicolor라는 것을 예측할 수 있다.

오늘 포스팅은 간단하게 여기까지만 하겠다. 사실 매우 쉬운 과정이지만 데이터 과학이 이러한 과정으로 이루어진다는 것을 비주얼 프로그래밍으로 살펴 볼 수 있다는 부분에서 orange가 좋은 것 같다.
