군집 분석을 위한 유사도와 거리
군집화:Clustering
데이터를 서로 비슷하거나, 서로 가까운 것들끼리 묶어서 나누는 것
비지도 학습이다!: 정답(라벨)이 없음. 유사도와 거리로 판단
-유사도(similarity):두 데이터가 얼마나 가까운 가를 나타내는 척도
-거리(distance):두 데이터 사이의 거리
-s=1-d,s=similarity, d=distance
유클리드 거리: Euclidean Distance
두 점 사이의 거리를 계산하는 가장 일반적인 방법
유클리드 공간에서 두 점 사이의 거리
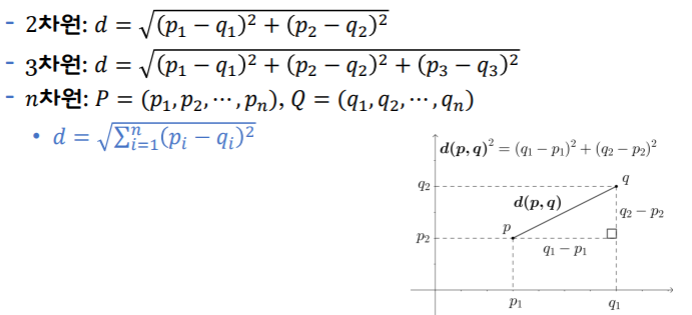
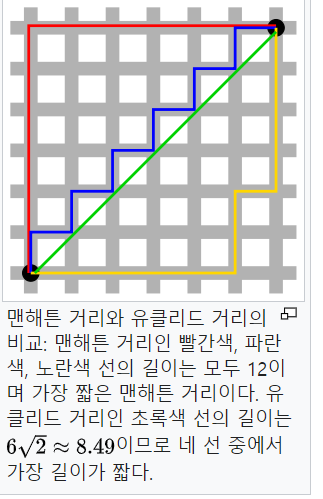
맨하탄 거리: Manhattan Distance
택시 거리라고도 함: 맨하탄에서 택시타고 가는 거리
두 점 사이의 데카르트 좌표게에서의 거리차의 절대값의 총합
코사인 유사도: Cosine Similarity
내적 공간에서 두 벡터의 방향이 이루는 각의 코사인 값:[0,1]
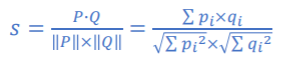
코사인 거리:Cosine Distance
d=1-s
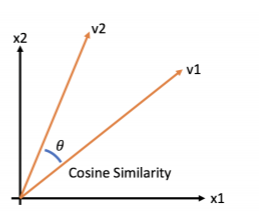
자카드 유사도:Jaccard Similarity
두 집합 사이의 유사도를 측정하는 대표정인 방법
-페이스북에서 친구 추천할 때, 넷플릭스에서 영화 추천할 때.
전체 집합의 크기와 교집합의 크기로 유사도 측정
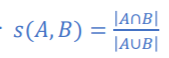
기타 유사도/거리 측정을 위한 지표: Distance Metrics
피어슨 거리, 스피어먼 거리, 해밍 거리, 마할라노비스 거리, 바타차야 거리, 체비셰프 거리
계층적 군집화와 실루엣 점수
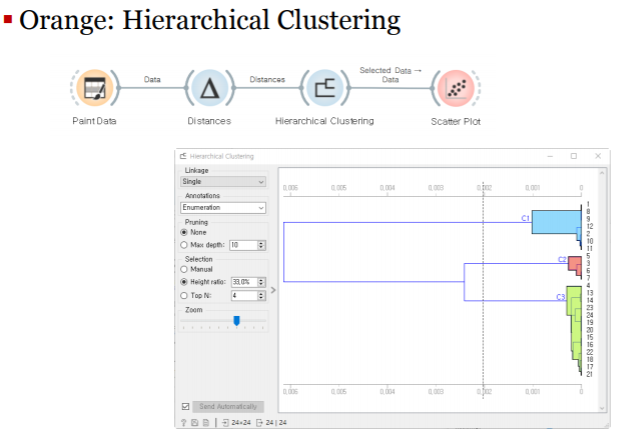
계층적 군집화:Hierarchical Clustering
군집간의 거리를 이용하여 계층적으로 군집을 분석하는 방법
-병합적 방법:agglomerative, bottom-up approach
-분할적 방법:divisive(partitioning),top-down approach
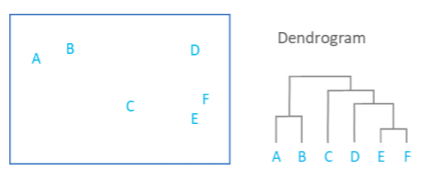
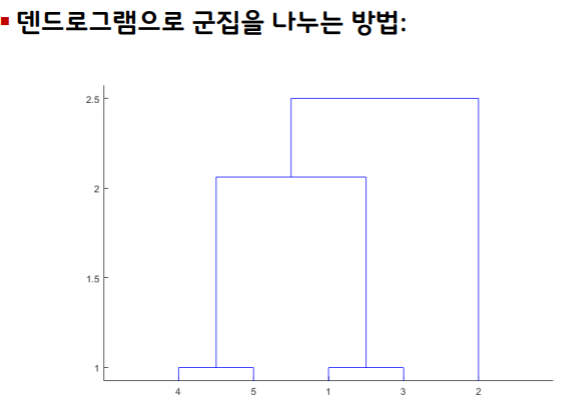
덴드로그램:Dendrogram
-군집의 계층적 구조를 그림으로 보여주는 방법
군집 간의 거리를 측정하는 방법: Linkage Method
최단 연결법: Single Linkage
-두 군집에 속하는 데이터 중에서 가장 가까운 데이터 간의 거리로 연결
최장 연결법: Complete Linkage
-두 군집에 속하는 데이터 중에서 가장 먼 데이터 간의 거리로 연결
평균 연결법: Average Linkage
-두 군집에 속하는 모든 데이터 간의 거리의 평균 거리로 연결
중심 연결법: Centroid Linkage
- 두 군집에서의 중심점(centroid)을 찾아서 두 중심점의 거리로 연결
Ward의 연결법: Ward Linkage - 두 군집을 합쳤을 때의 분산이 최소화 되는 군집을 합치는 방법
군집 모델의 평가: Cluster Evaluation
비지도 학습: 군집이 얼마나 서로 잘 구분이 되었는 지로 평가
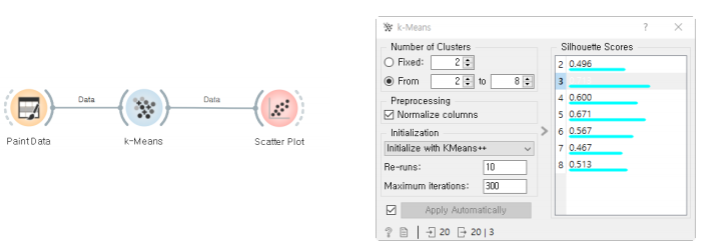
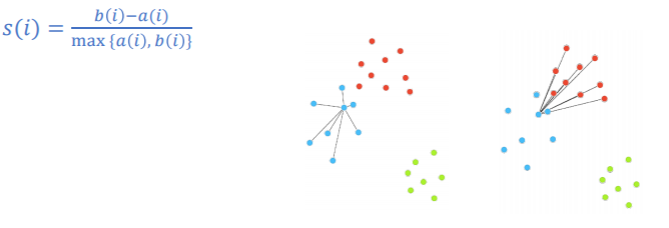
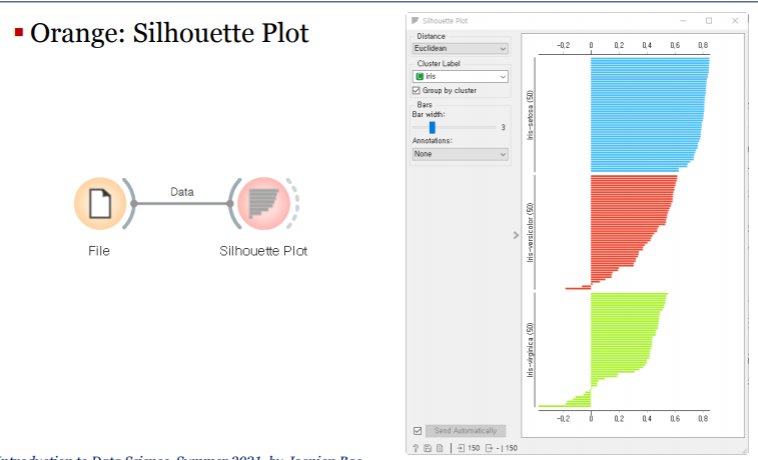
실루엣 점수: Silhouette Score
- 같은 군집의 데이터와는 가깝고, 다른 군집 데이터와의 거리는 멀수록 좋다.
- a(i): 같은 군집의 데이터와의 거리의 평균값
- b(i): 가장 가까운 다른 군집의 데이터와의 거리의 평균값
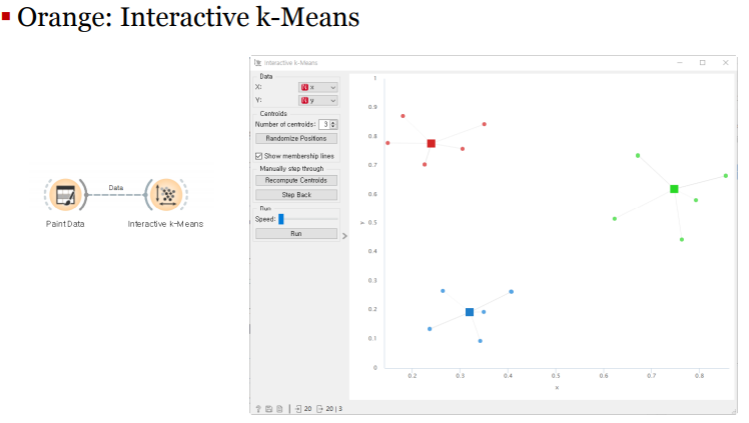
k-평균 군집화 알고리즘
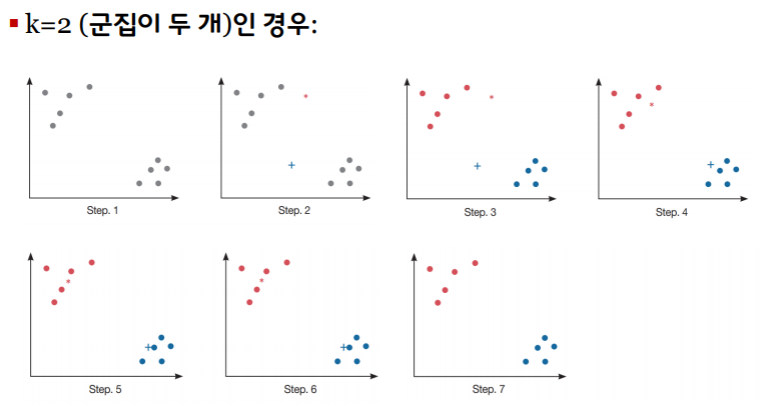
k-평균 군집화: k-means clustering
가장 일반적으로 널리 사용되는 군집화 알고리즘
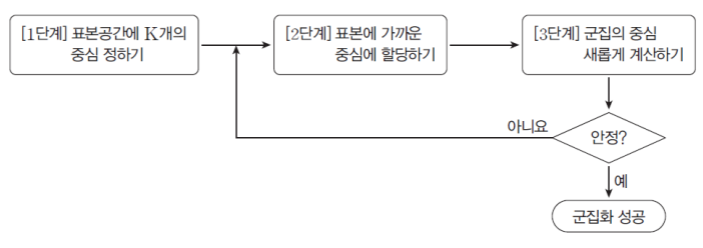
먼저 찾고자 하는 클러스터의 개수 k를 지정한다
k개의 중심점(centroid)위치를 임의로 지정한다.
각 데이터들을 가장 가까운 중심점에 속하는 군집으로 결정한다.
군집이 결정된 데이터들로 다시 중심점을 찾는다.
다시, 각 데이터들을 가장 가까운 중심점에 속하는 군집으로 재편한다.
중심점 이동이 없을 때까지 (혹은, 임계값 이하가 될 때까지) 반복한다.
알고리즘의 동작이 멈추었을 때의 군집을 각 데이터의 군집으로 분류한다.
적절한 클러스터의 개수 k를 어떻게 선택할까?
-> 실루엣 점수가 가장 높아지는 k를 선택하기